
Rumah >Peranti teknologi >AI >Data adalah raja! Bagaimana untuk membina algoritma pemanduan autonomi yang cekap langkah demi langkah melalui data?
Data adalah raja! Bagaimana untuk membina algoritma pemanduan autonomi yang cekap langkah demi langkah melalui data?

- PHPzke hadapan
- 2024-02-02 12:03:14835semak imbas
Ditulis di atas & pemahaman peribadi pengarang
Generasi teknologi pemanduan autonomi seterusnya dijangka bergantung pada penyepaduan dan interaksi khusus antara persepsi pintar, ramalan, perancangan dan kawalan peringkat rendah. Selalu ada kesesakan yang besar dalam had atas prestasi algoritma pemanduan autonomi Ahli akademik dan industri bersetuju bahawa kunci untuk mengatasi kesesakan itu terletak pada teknologi pemanduan autonomi yang mengutamakan data. Simulasi AD, latihan model gelung tertutup dan enjin data besar AD baru-baru ini memperoleh beberapa pengalaman berharga. Walau bagaimanapun, terdapat kekurangan pengetahuan sistematik dan pemahaman mendalam tentang cara membina teknologi AD yang berpusatkan data yang cekap untuk merealisasikan evolusi kendiri algoritma AD dan pengumpulan data besar AD yang lebih baik. Untuk mengisi jurang penyelidikan ini, di sini kami akan memberi perhatian yang teliti kepada teknologi pemanduan autonomi terdorong data terkini, memfokuskan pada klasifikasi komprehensif set data pemanduan autonomi, terutamanya termasuk pencapaian, ciri utama, tetapan pengumpulan data, dsb. Selain itu, kami menjalankan semakan sistematik terhadap saluran paip data besar AD gelung tertutup penanda aras sedia ada dari sempadan industri, termasuk proses, teknologi utama dan penyelidikan empirikal rangka kerja gelung tertutup. Akhir sekali, hala tuju pembangunan masa depan, aplikasi yang berpotensi, had dan kebimbangan dibincangkan untuk mendapatkan usaha bersama daripada ahli akademik dan industri untuk menggalakkan pembangunan selanjutnya pemanduan autonomi.
Ringkasnya, sumbangan utama adalah seperti berikut:
- Memperkenalkan taksonomi komprehensif pertama set data pemanduan autonomi yang diklasifikasikan mengikut generasi penting, tugas modular, suite sensor dan fungsi utama
- Berdasarkan pembelajaran mendalam dan model kecerdasan buatan generatif; semakan sistematik saluran paip pemacu autonomi dipacu data gelung tertutup yang paling maju dan teknologi utama yang berkaitan
- memberikan kajian empirikal tentang cara pacuan data besar gelung tertutup berfungsi dalam aplikasi industri pemanduan autonomi; semasa Kebaikan dan keburukan saluran paip dan penyelesaian, serta arahan penyelidikan masa depan pemanduan autonomi berpusatkan data.
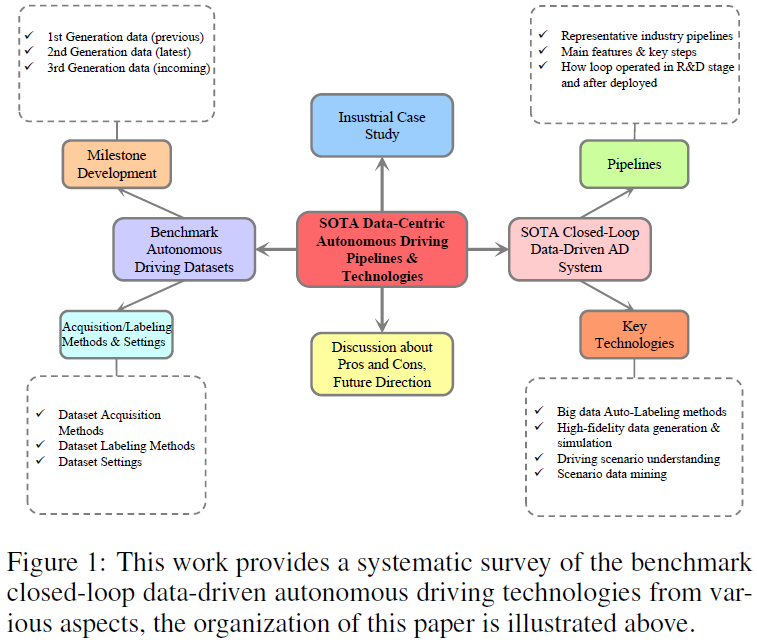 Set Data Pemanduan Autonomi SOTA: Klasifikasi dan Evolusi
Set Data Pemanduan Autonomi SOTA: Klasifikasi dan Evolusi
Evolusi set data pemanduan autonomi mencerminkan kemajuan teknologi dan cita-cita yang semakin meningkat dalam bidang itu. Penyelidikan awal AVT di Institut Kemajuan dan program PATH di University of California, Berkeley, pada penghujung abad ke-20 meletakkan asas untuk data sensor asas, tetapi dihadkan oleh tahap teknologi era itu. Dua dekad yang lalu telah menyaksikan lonjakan yang ketara ke hadapan, didorong oleh kemajuan dalam teknologi penderia, kuasa pengkomputeran dan algoritma pembelajaran mesin yang canggih. Pada 2014, Persatuan Jurutera Automotif (SAE) mengumumkan kepada orang ramai sistem pemanduan autonomi enam peringkat (L0-L5) yang sistematik, yang telah diiktiraf secara meluas oleh kemajuan penyelidikan dan pembangunan pemanduan autonomi. Didorong oleh pembelajaran mendalam, kaedah berasaskan penglihatan komputer telah mendominasi persepsi pintar. Pembelajaran pengukuhan mendalam dan variannya memberikan penambahbaikan penting dalam perancangan pintar dan membuat keputusan. Baru-baru ini, model bahasa besar (LLM) dan model bahasa visual (VLM) telah menunjukkan pemahaman adegan yang berkuasa, penaakulan dan ramalan tingkah laku pemanduan, dan keupayaan membuat keputusan yang bijak, membuka kemungkinan baharu untuk pembangunan pemanduan autonomi masa hadapan.
Pembangunan penting set data pemanduan autonomi
Rajah 2 menunjukkan perkembangan penting set data pemanduan autonomi sumber terbuka dalam susunan kronologi. Kemajuan yang ketara telah membawa kepada klasifikasi set data arus perdana kepada tiga generasi, dicirikan oleh lonjakan ketara dalam kerumitan set data, volum, kepelbagaian pemandangan dan kebutiran anotasi, mendorong bidang ke sempadan baharu kematangan teknologi. Khususnya, paksi mendatar mewakili garis masa pembangunan. Pengepala setiap baris termasuk nama set data, modaliti penderia, tugas yang sesuai, lokasi pengumpulan data dan cabaran yang berkaitan. Untuk membandingkan lebih lanjut set data merentas generasi, kami menggunakan carta bar berwarna berbeza untuk menggambarkan saiz set data yang dilihat dan diramal/dirancang. Peringkat awal, generasi pertama bermula pada 2012, diketuai oleh KITTI dan Cityscapes, menyediakan imej resolusi tinggi untuk tugasan persepsi dan merupakan asas untuk kemajuan penanda aras dalam algoritma penglihatan. Memajukan kepada generasi kedua, NuScenes, Waymo, Argoverse 1 dan set data lain telah memperkenalkan kaedah berbilang sensor, menyepadukan data daripada kamera kenderaan, peta berketepatan tinggi (Peta HD), lidar, radar, GPS, IMU, trajektori, dan objek sekeliling Disepadukan bersama, ini penting untuk pemodelan persekitaran pemanduan yang komprehensif dan proses membuat keputusan. Baru-baru ini, NuPlan, Argoverse 2 dan Lyft L5 telah meningkatkan tahap impak dengan ketara, menyampaikan skala data yang tidak pernah berlaku sebelum ini dan memupuk ekosistem yang kondusif untuk penyelidikan canggih. Dicirikan oleh saiz besar dan penyepaduan penderia berbilang mod, set data ini telah memainkan peranan penting dalam membangunkan algoritma untuk tugas pengesanan, ramalan dan perancangan, membuka jalan kepada model pemanduan End2End atau hibrid autonomi termaju. Pada tahun 2024, kami akan memperkenalkan set data pemanduan autonomi generasi ketiga. Disokong oleh VLM, LLM dan teknologi kecerdasan buatan generasi ketiga yang lain, set data generasi ketiga menyerlahkan komitmen industri untuk menangani cabaran pemanduan autonomi yang semakin kompleks, seperti masalah pengedaran ekor panjang data, pengesanan luar pengedaran, analisis kes sudut, dsb.
Pemerolehan set data, persediaan dan ciri utama
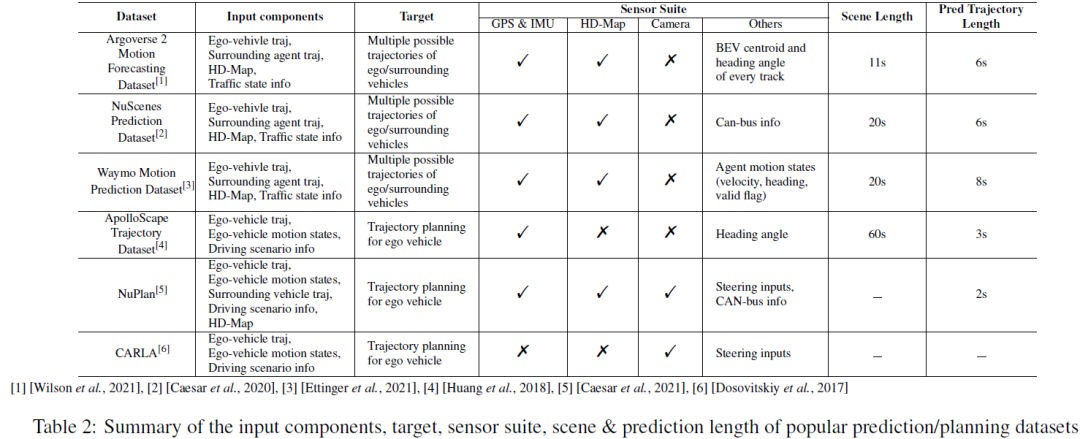
Jadual 1 meringkaskan pemerolehan data dan tetapan anotasi bagi set data persepsi yang sangat berpengaruh, termasuk senario pemanduan, suite sensor dan anotasi Kami melaporkan cuaca/ Jumlah bilangan masa/keadaan pemanduan , di mana cuaca lazimnya termasuk cerah/mendung/kabus/hujan/salji/lain-lain (keadaan melampau dalam sehari biasanya termasuk keadaan pemanduan pagi, petang dan petang biasanya termasuk jalan bandar, jalan arteri, jalan tepi, kawasan luar bandar, lebuh raya; , terowong, tempat letak kereta, dsb. Lebih pelbagai senario, lebih berkuasa set data. Kami juga melaporkan rantau tempat set data dikumpulkan, dilambangkan sebagai (Asia), EU (Eropah), NA (Amerika Utara), SA (Amerika Selatan), AU (Australia), AF (Afrika). Perlu diingat bahawa Mapillary dikumpul melalui AS/EU/NA/SA/AF/AF, dan DAWN dikumpul daripada enjin carian imej Google dan Bing. Untuk suite sensor, kami melihat kamera, lidar, GPS dan IMU, dsb. FV dan SV dalam Jadual 1 masing-masing adalah singkatan bagi kamera pandangan hadapan dan kamera pandangan jalan. Persediaan kamera panoramik 360° biasanya terdiri daripada berbilang kamera pandangan hadapan, kamera pandangan jarang dan kamera pandangan sisi. Kita dapat memerhatikan bahawa dengan perkembangan teknologi AD, jenis dan bilangan penderia yang disertakan dalam set data semakin meningkat, dan corak data menjadi semakin pelbagai. Mengenai anotasi set data, set data awal biasanya menggunakan kaedah anotasi manual, manakala NuPlan, Argoverse 2 dan DriveLM baru-baru ini telah menggunakan teknologi anotasi automatik untuk data besar AD. Kami percaya bahawa peralihan daripada anotasi manual tradisional kepada anotasi automatik ialah arah aliran utama dalam pemanduan autonomi tertumpu data pada masa hadapan.
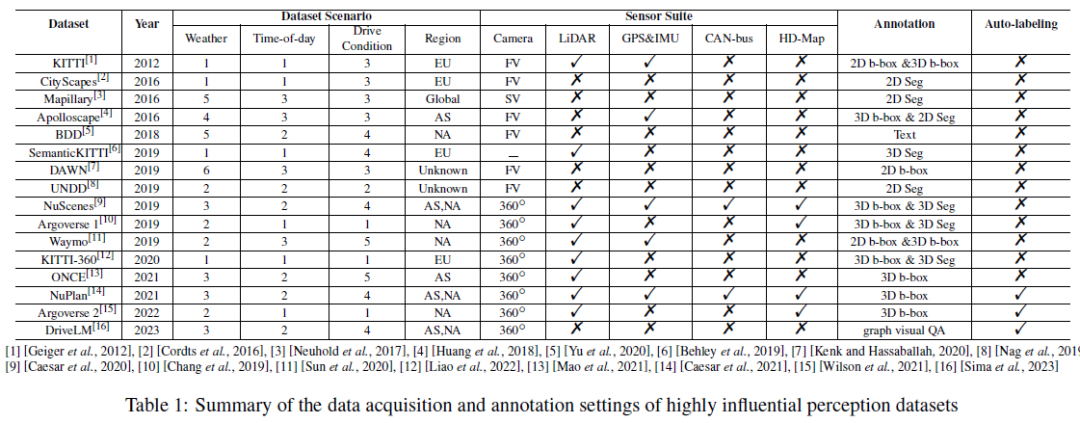
Untuk tugasan ramalan dan perancangan, kami meringkaskan komponen input/output, suite sensor, panjang pemandangan dan panjang ramalan set data arus perdana dalam Jadual 2. Untuk tugas ramalan/ramalan gerakan, komponen input biasanya termasuk trajektori sejarah kenderaan sendiri, trajektori sejarah ejen sekitar, peta ketepatan tinggi dan maklumat status trafik (iaitu, status isyarat lalu lintas, ID jalan, tanda henti, dsb. ). Output sasaran ialah beberapa trajektori yang berkemungkinan besar (seperti 5 teratas atau 10 trajektori teratas) bagi kenderaan sendiri dan/atau subjek di sekelilingnya dalam tempoh yang singkat. Tugas ramalan gerakan biasanya menggunakan tetapan tetingkap masa gelongsor untuk membahagikan keseluruhan adegan kepada beberapa tetingkap masa yang lebih pendek. Contohnya, NuScenes menggunakan 2 saat lalu data GT dan peta berketepatan tinggi untuk meramalkan trajektori 6 saat seterusnya, manakala Argoverse 2 menggunakan sejarah 5 saat kebenaran tanah dan peta berketepatan tinggi untuk meramalkan trajektori 6 saat seterusnya detik. NuPlan, CARLA dan ApoloScape ialah set data tugas perancangan yang paling popular. Komponen input termasuk trajektori sejarah kenderaan sendiri/sekitar, keadaan pergerakan kenderaan sendiri dan perwakilan pemandangan memandu. Walaupun NuPlan dan ApoloScape diperoleh di dunia nyata, CARLA ialah set data simulasi. CARLA mengandungi imej jalan yang diambil semasa pemanduan simulasi di bandar yang berbeza. Setiap imej jalan dikaitkan dengan sudut stereng, yang mewakili pelarasan yang diperlukan untuk memastikan kenderaan bergerak dengan betul. Panjang ramalan pelan boleh berbeza-beza mengikut keperluan algoritma yang berbeza.
Sistem pemanduan autonomi dipacu data gelung tertutup
Kami kini beralih daripada era pemanduan autonomi yang ditakrifkan oleh perisian dan algoritma sebelum ini kepada era inspirasi baharu model kolaboratif autonomi dipacu data besar dan pintar . Sistem dipacu data gelung tertutup bertujuan untuk merapatkan jurang antara latihan algoritma AD dan aplikasi/pengerahan dunia sebenarnya. Tidak seperti pendekatan gelung terbuka tradisional, di mana model dilatih secara pasif pada set data yang dikumpulkan daripada pemanduan pelanggan manusia atau ujian jalan raya, sistem gelung tertutup berinteraksi secara dinamik dengan persekitaran sebenar. Pendekatan ini menangani cabaran variasi pengedaran—tingkah laku yang dipelajari daripada set data statik mungkin tidak diterjemahkan kepada sifat dinamik senario pemanduan dunia sebenar. Sistem gelung tertutup membolehkan AV belajar daripada interaksi dan menyesuaikan diri dengan situasi baharu, bertambah baik melalui kitaran tindakan dan maklum balas berulang.
Walau bagaimanapun, membina sistem AD gelung tertutup berpusatkan data dunia sebenar masih mencabar kerana beberapa isu utama: Isu pertama adalah berkaitan dengan pengumpulan data AD. Dalam pengumpulan data dunia sebenar, kebanyakan sampel data adalah senario pemanduan biasa/biasa, manakala data tentang selekoh dan senario pemanduan tidak normal hampir mustahil untuk dikumpulkan. Kedua, usaha lanjut diperlukan untuk meneroka kaedah anotasi automatik yang tepat dan cekap untuk data AD. Ketiga, untuk mengurangkan masalah prestasi model AD yang lemah dalam adegan tertentu dalam persekitaran bandar, perlombongan data adegan dan pemahaman adegan harus dititikberatkan.
Pipapan pemanduan autonomi gelung tertutup SOTA
Industri pemanduan autonomi sedang giat membina platform data besar bersepadu untuk menghadapi cabaran yang dibawa oleh pengumpulan sejumlah besar data AD. Ini sesuai boleh dipanggil infrastruktur baharu untuk era pemanduan autonomi dipacu data. Dalam tinjauan kami terhadap sistem gelung tertutup dipacu data yang dibangunkan oleh syarikat AD/institut penyelidikan terkemuka, kami menemui beberapa persamaan:
- Ini saluran paip biasanya mengikut kitaran aliran kerja, termasuk: (I) pemerolehan data, (II) penyimpanan data, (III) pemilihan dan prapemprosesan data, (IV) anotasi data, (V) Latihan model AD, ( VI) pengesahan simulasi/ujian, dan (VII) penggunaan dunia sebenar.
- Untuk reka bentuk gelung tertutup dalam sistem, penyelesaian sedia ada sama ada memilih untuk menyediakan "gelung tertutup data" dan "gelung tertutup model" secara berasingan, atau menyediakan peringkat kitaran yang berbeza: "Gelung tertutup peringkat R&D" dan "peringkat penyebaran gelung tertutup".
- Selain itu, industri juga mengetengahkan isu pengedaran jangka panjang bagi set data AD dunia sebenar dan cabaran dalam mengendalikan kes sudut. Tesla dan Nvidia adalah perintis industri dalam bidang ini, dan seni bina sistem data mereka menyediakan rujukan penting untuk pembangunan bidang ini.
NVIDIA MagLev AV platform Rajah 3 (kiri)) mengikuti "Kumpul → Pilih → Label → Latih Naga" sebagai program, yang merupakan aliran kerja yang boleh direplikasi yang boleh mencapai pembelajaran aktif SDC dan melaksanakan anotasi pintar dalam gelung . MagLev terutamanya merangkumi dua gelung tertutup talian paip. Kitaran pertama tertumpu pada data pemanduan autonomi, bermula daripada pengingesan data dan pemilihan pintar, melalui anotasi dan anotasi, dan kemudian carian model dan latihan. Model terlatih kemudiannya dinilai, dinyahpepijat, dan akhirnya digunakan ke dunia nyata. Gelung tertutup kedua ialah sistem sokongan infrastruktur platform, termasuk tulang belakang pusat data dan infrastruktur perkakasan. Gelung ini termasuk pemprosesan data selamat, DNN berskala dan KPI sistem, papan pemuka untuk penjejakan dan penyahpepijatan. Ia menyokong kitaran penuh pembangunan AV, memastikan peningkatan berterusan dan penyepaduan data dunia sebenar dan maklum balas simulasi semasa proses pembangunan.
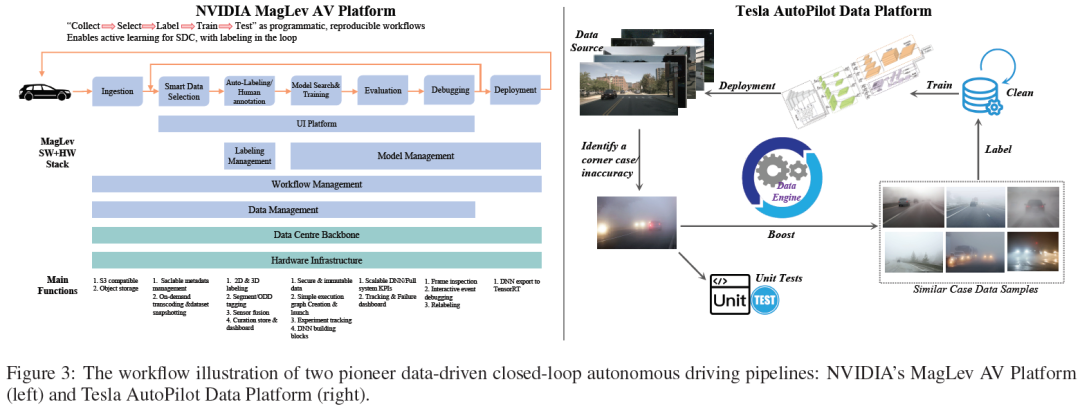
Platform Data Pemanduan Autonomi Tesla (Rajah 3 (kanan)) ialah satu lagi platform AD yang mewakili, yang menekankan penggunaan gelung tertutup talian paip dipacu data besar untuk meningkatkan prestasi model pemanduan autonomi dengan ketara. saluran paipBermula dengan pengumpulan data sumber, biasanya daripada pembelajaran armada Tesla, pengumpulan data sisi kenderaan yang dicetuskan oleh peristiwa dan mod bayangan. Data yang dikumpul akan disimpan, diurus dan disemak oleh algoritma platform data atau pakar manusia. Setiap kali kes sudut/ketidaktepatan ditemui, enjin data akan mengambil dan memadankan sampel data yang sangat serupa dengan kes sudut/ketidaktepatan daripada pangkalan data sedia ada. Pada masa yang sama, ujian unit akan dibangunkan untuk meniru senario dan menguji tindak balas sistem dengan teliti. Sampel data yang diambil kemudian diberi anotasi oleh algoritma anotasi automatik atau pakar manusia. Data yang dianotasi dengan baik kemudiannya akan dihantar semula ke pangkalan data AD, yang akan dikemas kini untuk menjana versi baharu set data latihan untuk model penderiaan/ramalan/perancangan/kawalan AD. Selepas latihan model, pengesahan, simulasi dan ujian dunia sebenar, model AD baharu dengan prestasi lebih tinggi akan dikeluarkan dan digunakan.
Penjanaan dan simulasi data AD kesetiaan tinggi berdasarkan Generatif AI
Kebanyakan sampel data AD yang dikumpul dari dunia sebenar adalah senario pemanduan biasa/biasa, yang mana kami sudah mempunyai sejumlah besar sampel serupa dalam pangkalan data. Walau bagaimanapun, untuk mengumpul beberapa jenis sampel data AD daripada pemerolehan dunia sebenar, kami perlu memandu untuk masa yang lama secara eksponen, yang tidak boleh dilaksanakan dalam aplikasi perindustrian. Oleh itu, kaedah penjanaan data pemacuan autonomi tinggi dan kaedah simulasi telah menarik perhatian besar daripada komuniti akademik. CARLA ialah simulator sumber terbuka untuk penyelidikan pemanduan autonomi yang boleh menjana data pemanduan autonomi di bawah pelbagai tetapan khusus pengguna. Kekuatan CARLA ialah fleksibilitinya, membolehkan pengguna mencipta keadaan jalan raya yang berbeza, senario trafik dan dinamik cuaca, yang memudahkan latihan dan ujian model yang komprehensif. Walau bagaimanapun, sebagai simulator, kelemahan utamanya ialah jurang domain. Data AD yang dijana oleh CARLA tidak dapat mensimulasikan sepenuhnya kesan fizikal dan visual dunia sebenar, ciri dinamik dan kompleks persekitaran pemanduan sebenar juga tidak diwakili.
Baru-baru ini, model dunia telah digunakan untuk penjanaan data AD kesetiaan tinggi dengan konsep intrinsik yang lebih maju dan prestasi yang lebih menjanjikan. Model dunia boleh ditakrifkan sebagai sistem kecerdasan buatan yang membina perwakilan dalaman persekitaran yang dilihatnya dan menggunakan perwakilan yang dipelajari untuk mensimulasikan data atau peristiwa dalam persekitaran. Matlamat model dunia umum adalah untuk mewakili dan mensimulasikan situasi dan interaksi sama seperti manusia matang menghadapinya di dunia nyata. Dalam bidang pemanduan autonomi, GAIA-1 dan DriveDreamer adalah karya agung penjanaan data berdasarkan model dunia. GAIA-1 ialah model kecerdasan buatan generatif yang mencapai penjanaan imej/video-ke-imej/video dengan mengambil imej/video mentah sebagai input bersama teks dan gesaan tindakan. Modaliti input GAIA-1 dikodkan ke dalam urutan token bersatu. Anotasi ini diproses oleh pengubah autoregresif dalam model dunia untuk meramalkan anotasi imej seterusnya. Penyahkod video kemudiannya membina semula anotasi ini menjadi output video yang koheren dengan peleraian temporal yang dipertingkatkan, membolehkan penjanaan kandungan visual yang dinamik dan kaya konteks. DriveDreamer secara inovatif menggunakan model resapan dalam seni binanya, memfokuskan pada menangkap kerumitan persekitaran pemanduan dunia sebenar. Saluran paip latihan dua peringkat mula-mula membolehkan model mempelajari kekangan trafik berstruktur dan kemudian meramalkan keadaan masa hadapan, memastikan pemahaman alam sekitar yang kukuh disesuaikan untuk aplikasi pemanduan autonomi.
Kaedah pelabelan automatik untuk set data pemanduan autonomi
Pelabelan data berkualiti tinggi adalah penting untuk kejayaan dan kebolehpercayaan. Setakat ini, anotasi datasaluran paip boleh dibahagikan kepada tiga jenis, bermula daripada anotasi manual tradisional kepada anotasi separa automatik kepada kaedah anotasi automatik sepenuhnya yang terkini, seperti yang ditunjukkan dalam Rajah 4. Anotasi data AD biasanya dianggap sebagai tugas khusus /Model. Aliran kerja bermula dengan penyediaan teliti keperluan untuk tugasan anotasi dan set data asal. Kemudian, langkah seterusnya ialah menjana hasil anotasi awal menggunakan pakar manusia, algoritma anotasi automatik atau model besar End2End. Selepas itu, kualiti anotasi disemak oleh pakar manusia atau algoritma semakan kualiti automatik berdasarkan keperluan yang telah ditetapkan. Jika hasil anotasi pusingan ini gagal dalam semakan kualiti, ia akan dihantar semula ke kitaran anotasi sekali lagi dan kerja anotasi ini diulang sehingga memenuhi keperluan yang telah ditetapkan. Akhir sekali, kita boleh mendapatkan set data AD berlabel siap sedia.

yang dicadangkan oleh Uber meneroka penanda sedar AD pada skala spatiotemporal buat kali pertama. Dalam bidang pemanduan autonomi, penandaan kotak sempadan sasaran 3D dalam skala spatial dan penandaan cap waktu 1D yang sepadan dalam skala masa dipanggil penandaan 4D. Saluran paip Auto4D bermula dengan awan titik lidar berterusan untuk mewujudkan trajektori objek awal. Trajektori diperhalusi oleh cawangan saiz sasaran, yang mengekod dan menyahkod saiz sasaran menggunakan pemerhatian sasaran. Pada masa yang sama, cawangan laluan gerakan mengekod pemerhatian laluan dan gerakan, membenarkan penyahkod laluan untuk memperhalusi trajektori dengan saiz sasaran yang tetap.
Pelabelan automatik pemandangan statik 3D boleh dianggap sebagai penjanaan HDMap, di mana lorong, sempadan jalan, persimpangan jalan, lampu isyarat dan elemen lain yang berkaitan dalam adegan pemanduan harus dilabelkan. Di bawah topik ini, terdapat beberapa kerja penyelidikan yang menarik: kaedah berasaskan penglihatan, seperti kaedah berasaskan MVMap, NeMO, seperti kaedah pembinaan semula pemandangan 3D yang telah dilatih, seperti OccBEV, OccNet/ADPT, ALO ; VMA ialah kerja yang dicadangkan baru-baru ini untuk pelabelan automatik adegan statik 3D. Rangka kerja VMA menggunakan awan titik lidar terkumpul berbilang perjalanan untuk membina semula pemandangan statik dan membahagikannya kepada unit untuk diproses. Anotasi unit berasaskan MapTR mengekod input mentah ke dalam peta ciri melalui pertanyaan dan penyahkodan, menjana jujukan titik ditaip secara semantik. Output VMA ialah peta bervektor, yang akan diperhalusi melalui anotasi gelung tertutup dan pengesahan manual untuk menyediakan peta ketepatan tinggi yang memuaskan untuk pemanduan autonomi.
Kajian Empirikal
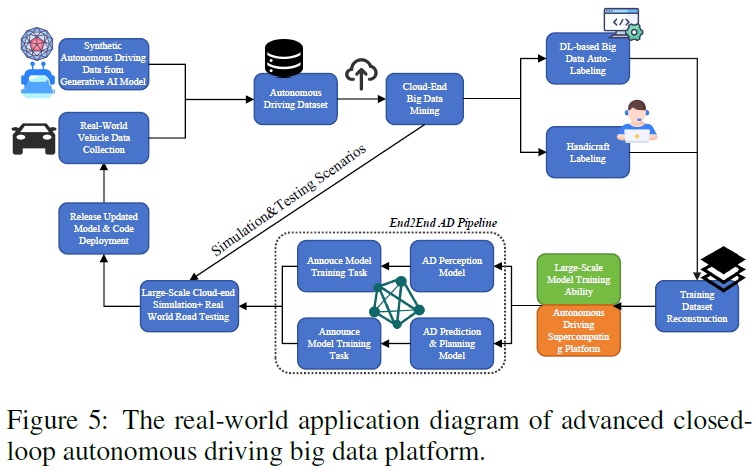
Kami menyediakan kajian empirikal untuk menggambarkan dengan lebih baik platform data AD gelung tertutup lanjutan yang disebut dalam artikel ini. Keseluruhan rajah proses ditunjukkan dalam Rajah 5. Dalam kes ini, matlamat penyelidik adalah untuk membangunkan gelung tertutup talian paip data besar AD berdasarkan Generatif AI dan pelbagai algoritma berasaskan pembelajaran mendalam, dengan itu membolehkan fasa pembangunan algoritma pemanduan autonomi dan fasa naik taraf OTA (selepas dunia sebenar penempatan ) untuk mencapai gelung tertutup data. Secara khusus, model kecerdasan buatan yang dijana digunakan untuk (1) menjana data AD kesetiaan tinggi untuk senario tertentu berdasarkan gesaan teks yang disediakan oleh jurutera. (2) Pelabelan automatik data besar AD untuk menyediakan label kebenaran tanah dengan berkesan.
Rajah menunjukkan dua gelung tertutup. Salah satu peringkat yang lebih besar ialah fasa pembangunan algoritma pemanduan autonomi, yang bermula dengan pengumpulan data data pemanduan autonomi sintetik untuk menjana model kecerdasan buatan dan sampel data yang diperoleh daripada pemanduan dunia sebenar. Kedua-dua sumber data ini disepadukan ke dalam set data pandu kendiri dan dilombong dalam awan untuk mendapatkan cerapan berharga. Selepas itu, set data memasuki laluan pelabelan dwi: pelabelan automatik berdasarkan pembelajaran mendalam atau pelabelan manual manual, memastikan kelajuan dan ketepatan anotasi. Data berlabel kemudiannya digunakan untuk melatih model pada platform pengkomputeran pemanduan autonomi berkapasiti tinggi. Model ini diuji pada simulasi dan jalan dunia sebenar untuk menilai keberkesanannya, yang membawa kepada keluaran dan penggunaan model pemanduan autonomi yang seterusnya. Yang lebih kecil adalah untuk fasa peningkatan OTA selepas penggunaan dunia sebenar, yang melibatkan simulasi awan berskala besar dan ujian dunia sebenar untuk mengumpul ketidaktepatan/kes sudut algoritma AD. Ketidaktepatan/kes sudut yang dikenal pasti digunakan untuk memaklumkan ujian dan kemas kini model lelaran seterusnya. Sebagai contoh, katakan kami mendapati bahawa algoritma AD kami berprestasi buruk dalam senario pemanduan terowong. Lengkung pemanduan terowong yang dikenal pasti akan diumumkan ke gelanggang serta-merta dan dikemas kini dalam lelaran seterusnya. Model kecerdasan buatan generatif menggunakan perihalan berkaitan adegan pemanduan terowong sebagai gesaan teks untuk menjana sampel data pemanduan terowong berskala besar. Data yang dijana dan set data mentah akan dimasukkan ke dalam simulasi, ujian dan kemas kini model. Sifat berulang proses ini adalah penting untuk mengoptimumkan model untuk menyesuaikan diri dengan persekitaran yang mencabar dan data baharu, mengekalkan ketepatan tinggi dan kebolehpercayaan keupayaan pemanduan autonomi.
Bincangkan
set data pemanduan autonomi baharu generasi ketiga dan seterusnya. Walaupun model asas seperti LLM/VLM telah mencapai kejayaan dalam pemahaman bahasa dan penglihatan komputer, masih mencabar untuk menggunakannya secara langsung dalam pemanduan autonomi. Terdapat dua sebab untuk ini: Di satu pihak, LLM/VLM ini mesti mempunyai keupayaan untuk menyepadukan sepenuhnya dan memahami data besar AD berbilang sumber (seperti imej/video FOV, titik awan lidar, peta definisi tinggi, Data GPS/IMU, dsb.), yang lebih cekap daripada Lebih sukar untuk memahami imej yang kita lihat dalam kehidupan seharian kita. Sebaliknya, skala data dan kualiti sedia ada dalam bidang pemanduan autonomi tidak setanding dengan bidang lain (seperti kewangan dan penjagaan perubatan), menjadikannya sukar untuk menyokong latihan dan pengoptimuman LLM/VLM berkapasiti lebih besar. Data besar untuk pemanduan autonomi pada masa ini terhad dalam skala dan kualiti disebabkan oleh peraturan, kebimbangan privasi dan kos. Kami percaya bahawa dengan usaha bersama semua pihak, data besar AD generasi akan datang akan dipertingkatkan dengan ketara dalam skala dan kualiti.
Sokongan perkakasan untuk algoritma pemanduan autonomi. Platform perkakasan semasa telah mencapai kemajuan yang ketara, terutamanya dengan kemunculan pemproses khusus seperti GPU dan TPU, yang menyediakan kuasa pengkomputeran selari yang besar yang penting kepada tugas pembelajaran mendalam. Sumber pengkomputeran berprestasi tinggi dalam infrastruktur on-board dan awan adalah penting untuk memproses aliran data besar-besaran yang dijana oleh penderia kenderaan dalam masa nyata. Walaupun kemajuan ini, masih terdapat batasan dalam skalabiliti, kecekapan tenaga dan kelajuan pemprosesan apabila berhadapan dengan peningkatan kerumitan algoritma pemanduan autonomi. Interaksi kenderaan pengguna berpandukan VLM/LLM ialah kes aplikasi yang sangat menjanjikan. Berdasarkan aplikasi ini, data besar tingkah laku khusus pengguna boleh dikumpulkan. Walau bagaimanapun, peranti VLM/LLM dalam kenderaan akan memerlukan sumber pengkomputeran perkakasan standard yang tinggi dan aplikasi interaktif dijangka mempunyai kependaman yang rendah. Oleh itu, mungkin terdapat beberapa model pemanduan autonomi berskala besar ringan pada masa hadapan, atau teknologi mampatan LLM/VLM akan dikaji lebih lanjut.
Syor pemanduan autonomi diperibadikan berdasarkan data tingkah laku pengguna. Kereta pintar telah dibangunkan daripada cara pengangkutan yang mudah kepada pengembangan aplikasi terkini dalam senario terminal pintar. Oleh itu, jangkaan bagi kenderaan yang dilengkapi dengan ciri pemanduan autonomi termaju ialah mereka boleh mempelajari keutamaan tingkah laku pemandu, seperti gaya pemanduan dan pilihan laluan, daripada rekod data pemanduan sejarah. Ini akan membolehkan kereta pintar untuk lebih sejajar dengan kenderaan kegemaran pengguna pada masa hadapan kerana ia membantu pemandu dengan kawalan kenderaan, keputusan pemanduan dan perancangan laluan. Kami memanggil konsep di atas sebagai algoritma pengesyoran pemanduan autonomi yang diperibadikan. Sistem pengesyoran telah digunakan secara meluas dalam e-dagang, beli-belah dalam talian, penghantaran makanan, media sosial dan platform penstriman langsung. Walau bagaimanapun, dalam bidang pemanduan autonomi, cadangan diperibadikan masih di peringkat awal. Kami percaya bahawa dalam masa terdekat, sistem data dan mekanisme pengumpulan data yang lebih sesuai akan direka bentuk untuk mengumpul data besar tentang keutamaan tingkah laku pemanduan pengguna dengan kebenaran pengguna dan pematuhan peraturan yang berkaitan, dengan itu mencapai pengesyoran pemanduan autonomi tersuai untuk sistem .
Keselamatan data dan pemanduan autonomi yang boleh dipercayai. Jumlah besar data besar pemacu autonomi menimbulkan cabaran besar kepada keselamatan data dan perlindungan privasi pengguna. Apabila teknologi kenderaan autonomi bersambung (CAV) dan Internet of Vehicles (IoV) berkembang, kenderaan menjadi semakin bersambung, dan pengumpulan data pengguna terperinci daripada tabiat memandu kepada laluan kerap telah menimbulkan kebimbangan tentang kemungkinan penyalahgunaan maklumat peribadi. Kami mengesyorkan keperluan untuk ketelusan mengenai jenis data yang dikumpul, dasar pengekalan dan perkongsian pihak ketiga. Ia menekankan kepentingan persetujuan dan kawalan pengguna, termasuk memenuhi permintaan "jangan jejak" dan menyediakan pilihan untuk memadamkan data peribadi. Untuk industri pemanduan autonomi, melindungi data ini sambil mempromosikan inovasi memerlukan pematuhan yang ketat kepada garis panduan ini, memastikan kepercayaan pengguna dan pematuhan terhadap undang-undang privasi yang berkembang.
Selain keselamatan data dan privasi, isu lain ialah cara mencapai pemanduan autonomi yang boleh dipercayai. Dengan perkembangan hebat teknologi AD, algoritma pintar dan model kecerdasan buatan generatif (seperti LLM, VLM) akan "bertindak sebagai faktor pemacu" apabila melaksanakan keputusan dan tugas pemanduan yang semakin kompleks. Dalam bidang ini, persoalan semula jadi timbul: Bolehkah manusia mempercayai model pemanduan autonomi? Pada pandangan kami, kunci kepada kebolehpercayaan terletak pada kebolehtafsiran model pandu sendiri. Mereka sepatutnya dapat menjelaskan kepada pemandu manusia sebab-sebab sesuatu keputusan, bukan hanya melakukan tindakan pemanduan. LLM/VLM dijangka meningkatkan pemanduan autonomi yang boleh dipercayai dengan menyediakan penaakulan lanjutan dan penjelasan yang boleh difahami dalam masa nyata.
Kesimpulan
Tinjauan ini menyediakan semakan sistematik pertama evolusi berpusatkan data dalam pemanduan autonomi, termasuk sistem data besar, perlombongan data dan teknologi gelung tertutup. Dalam tinjauan ini, kami mula-mula membangunkan taksonomi set data mengikut penjanaan peristiwa penting, menyemak pembangunan set data AD merentas garis masa sejarah dan memperkenalkan pemerolehan set data, persediaan dan ciri utama. Tambahan pula, kami menghuraikan sistem pemanduan autonomi yang dipacu data gelung tertutup dari kedua-dua perspektif akademik dan perindustrian. Aliran kerjasaluran paip, proses dan teknologi utama dalam sistem gelung tertutup berpusat data dibincangkan secara terperinci. Melalui penyelidikan empirikal, kadar penggunaan dan kelebihan platform AD gelung tertutup berpusat data dalam pembangunan algoritma dan peningkatan OTA ditunjukkan. Akhir sekali, kelebihan dan kekurangan teknologi pemanduan autonomi dipacu data sedia ada dan hala tuju penyelidikan masa hadapan dibincangkan secara menyeluruh. Tumpuan adalah pada set data baharu, sokongan perkakasan, pengesyoran AD yang diperibadikan dan pemanduan autonomi yang boleh dijelaskan selepas generasi ketiga. Kami juga menyatakan kebimbangan tentang kebolehpercayaan model Generatif AI, keselamatan data dan pembangunan masa depan pemanduan autonomi.

Pautan asal: https://mp.weixin.qq.com/s/YEjWSvKk6f-TDAR91Ow2rA
Atas ialah kandungan terperinci Data adalah raja! Bagaimana untuk membina algoritma pemanduan autonomi yang cekap langkah demi langkah melalui data?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!