
Rumah >Peranti teknologi >AI >Model besar tanpa perhatian Eagle7B: Berdasarkan RWKV, kos inferens dikurangkan sebanyak 10-100 kali ganda
Model besar tanpa perhatian Eagle7B: Berdasarkan RWKV, kos inferens dikurangkan sebanyak 10-100 kali ganda

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-01 14:39:461234semak imbas
Model besar tanpa perhatian Eagle7B: Berdasarkan RWKV, kos inferens dikurangkan sebanyak 10-100 kali ganda
Dalam trek AI , model kecil telah menarik banyak perhatian baru-baru ini, berbanding model dengan ratusan bilion parameter. Sebagai contoh, model Mistral-7B yang dikeluarkan oleh pemula AI Perancis mengatasi Llama 2 sebanyak 13B dalam setiap penanda aras dan mengatasi Llama 1 sebanyak 34B dalam kod, matematik dan inferens.
Berbanding dengan model besar, model kecil mempunyai banyak kelebihan, seperti keperluan kuasa pengkomputeran yang rendah dan keupayaan untuk berjalan pada sisi peranti.
Baru-baru ini, model bahasa baharu telah muncul, iaitu parameter 7.52B Eagle 7B, daripada organisasi bukan untung sumber terbuka RWKV, yang mempunyai ciri-ciri berikut:

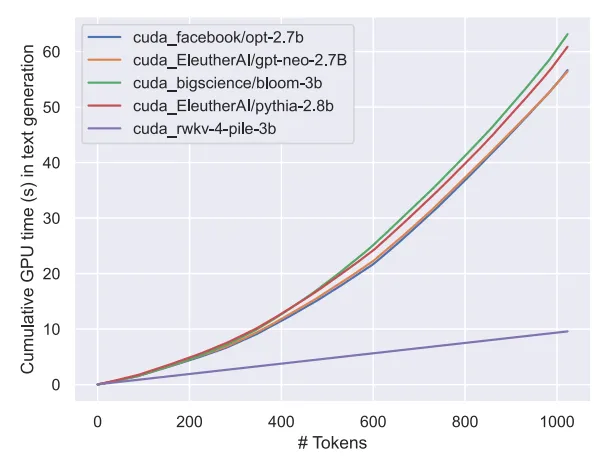
- di RWKV -v5 Pembinaan seni bina, kos inferens seni bina ini adalah rendah (RWKV ialah pengubah linear, kos inferens dikurangkan lebih daripada 10-100 kali ganda); ;
- Mengungguli semua model kelas 7B dalam penanda aras berbilang bahasa; - dalam penilaian Bahasa Inggeris 7B (1T) Cukup;
- Eagle 7B dibina berdasarkan seni bina RWKV-v5. RWKV (Receptance Weighted Key Value) ialah seni bina novel yang menggabungkan kelebihan RNN dan Transformer dan mengelakkan kekurangannya. Ia direka dengan sangat baik dan boleh mengurangkan kesesakan memori dan pengembangan Transformer dan mencapai pengembangan linear yang lebih berkesan. Pada masa yang sama, RWKV juga mengekalkan beberapa sifat yang menjadikan Transformer dominan dalam bidang tersebut.
- Pada masa ini RWKV telah diulang kepada generasi keenam RWKV-6, dengan prestasi dan saiz yang serupa dengan Transformer. Penyelidik akan datang boleh menggunakan seni bina ini untuk mencipta model yang lebih cekap.

Perlu dinyatakan bahawa RWKV-v5 Eagle 7B boleh digunakan untuk kegunaan peribadi atau komersial tanpa sekatan.
Hasil ujian pada 23 bahasa
Prestasi model yang berbeza pada berbilang bahasa adalah seperti berikut Penanda aras ujian termasuk xLAMBDA, xStoryCloze, xWinograd, xCopa.
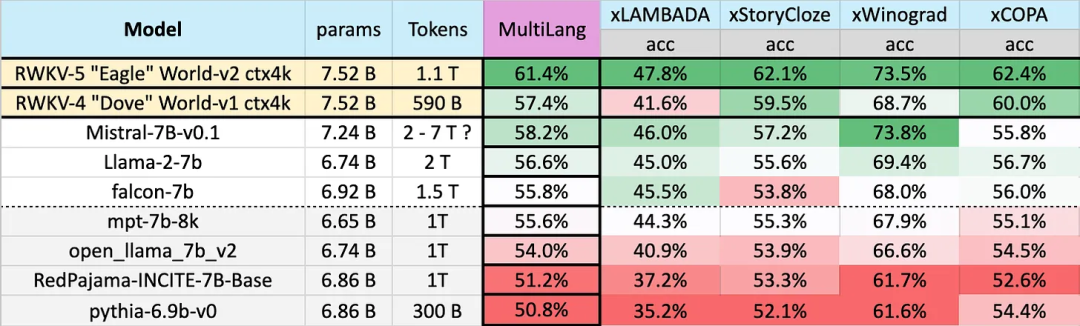
Tanda aras ini termasuk kebanyakan penaakulan RW-languK yang besar, yang menunjukkan prestasi akal fikiran yang besar. kepada v5. Walau bagaimanapun, disebabkan kekurangan tanda aras berbilang bahasa, kajian itu hanya boleh menguji keupayaannya dalam 23 bahasa yang lebih biasa digunakan, dan keupayaan dalam baki 75 atau lebih bahasa masih tidak diketahui. 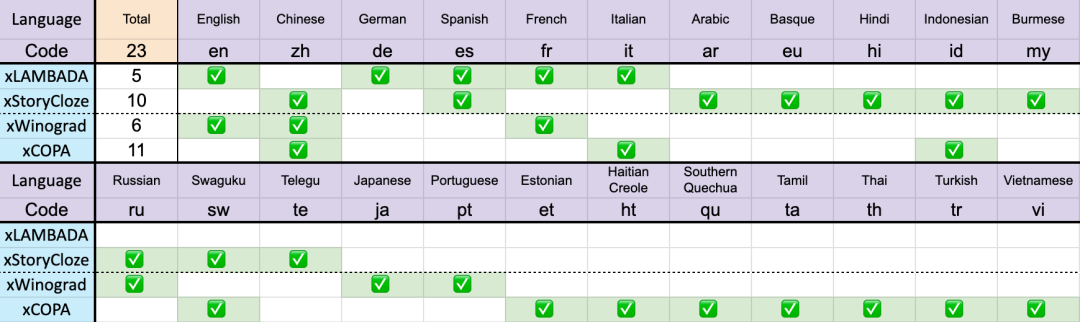
Prestasi Bahasa Inggeris
Prestasi model berbeza dalam bahasa Inggeris dinilai melalui 12 penanda aras, termasuk penaakulan akal dan pengetahuan dunia.
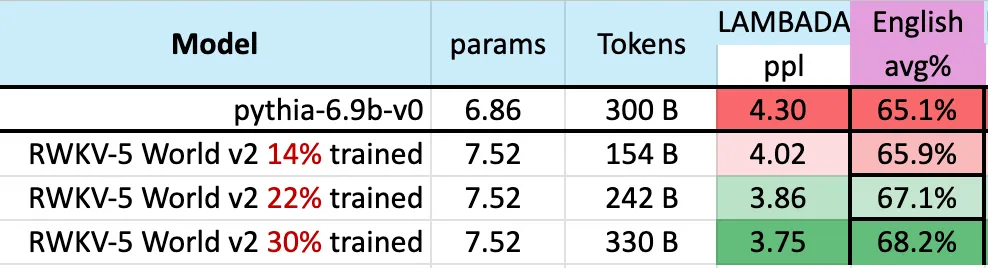
Daripada hasilnya, kita sekali lagi dapat melihat lonjakan besar RWKV daripada seni bina v4 kepada v5. v4 sebelum ini kalah kepada token 1T MPT-7b, tetapi v5 telah mula mengejar ujian penanda aras Dalam sesetengah kes (walaupun pada beberapa ujian penanda aras LAMBADA, StoryCloze16, WinoGrande, HeadQA_en, Sciq) ia boleh mengatasi Falcon , atau llama2.
Selain itu, prestasi v5 mula sejajar dengan tahap prestasi Transformer yang dijangkakan berdasarkan anggaran statistik latihan token. Sebelum ini, Mistral-7B menggunakan kaedah latihan 2-7 trilion Token untuk mengekalkan pendahulunya dalam model skala 7B. Kajian ini berharap dapat merapatkan jurang ini supaya RWKV-v5 Eagle 7B mengatasi prestasi llama2 dan mencapai tahap Mistral. Rajah di bawah menunjukkan bahawa pusat pemeriksaan RWKV-v5 Eagle 7B berhampiran 300 bilion mata token menunjukkan prestasi yang serupa dengan pythia-6.9b: Ini adalah konsisten dengan kerja-kerja eksperimen RWKV4 sebelum ini perjanjian berasaskan cerucuk) ialah transformer linear seperti RWKV adalah serupa dalam tahap prestasi dengan transformer dan dilatih dengan bilangan token yang sama. Dapat diramalkan, kemunculan model ini menandakan kedatangan transformer linear terkuat (dari segi penanda aras penilaian) setakat ini. 
Atas ialah kandungan terperinci Model besar tanpa perhatian Eagle7B: Berdasarkan RWKV, kos inferens dikurangkan sebanyak 10-100 kali ganda. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!