
Rumah >Peranti teknologi >AI >Model besar berbilang modal Kuaishou dan Beida: imej adalah bahasa asing, setanding dengan kejayaan DALLE-3
Model besar berbilang modal Kuaishou dan Beida: imej adalah bahasa asing, setanding dengan kejayaan DALLE-3

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-30 16:36:28883semak imbas
Segmentasi perkataan visual dinamik, perwakilan grafik dan teks bersatu, Kuaishou dan Universiti Peking bekerjasama untuk mencadangkan model asas LaVIT untuk meneliti senarai tugasan pemahaman dan penjanaan pelbagai mod.
Model bahasa berskala besar semasa seperti GPT, LLaMA, dll. telah mencapai kemajuan yang ketara dalam bidang pemprosesan bahasa semula jadi, dan mereka dapat memahami serta menjana kandungan teks yang kompleks. Walau bagaimanapun, adakah kita telah mempertimbangkan untuk memindahkan pemahaman dan keupayaan penjanaan yang berkuasa ini kepada data multimodal? Ini akan membolehkan kami dengan mudah memahami sejumlah besar imej dan video dan mencipta kandungan bergambar yang kaya. Untuk merealisasikan visi ini, Kuaishou dan Universiti Peking baru-baru ini bekerjasama untuk membangunkan model besar berbilang modal baharu yang dipanggil LaVIT. LaVIT secara beransur-ansur mengubah idea ini menjadi realiti, dan kami menantikan perkembangan selanjutnya.

Tajuk kertas: Unified Language-Vision Pralatihan dalam LLM dengan Dynamic Discrete Visual Tokenization
Alamat kertas: https://arxiv.org/abs/2309.0466 //github.com/jy0205/LaVIT
- Gambaran Keseluruhan Model
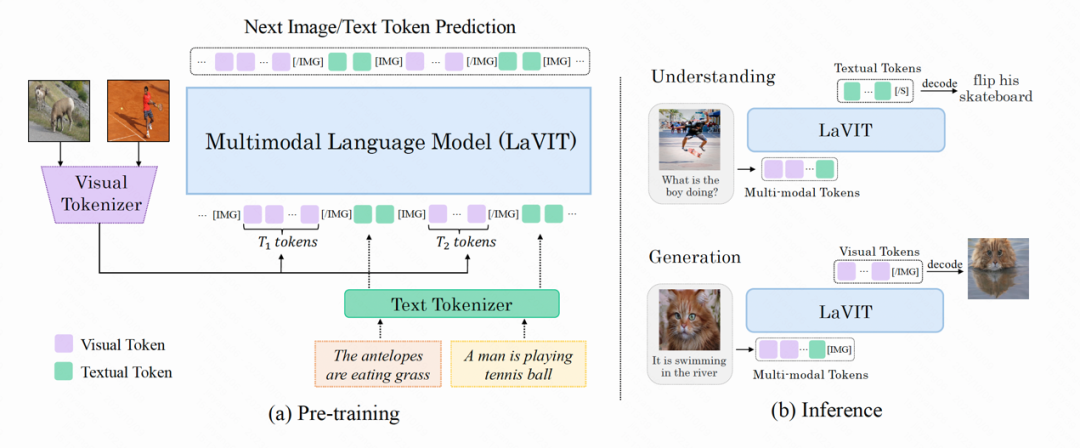
LaVIT ialah model asas pelbagai mod am baharu, serupa dengan model bahasa, yang boleh memahami dan menjana kandungan visual. Paradigma latihan LaVIT menggunakan pengalaman kejayaan model bahasa yang besar dan menggunakan pendekatan autoregresif untuk meramalkan imej atau token teks seterusnya. Selepas latihan, LaVIT boleh berfungsi sebagai antara muka universal berbilang mod yang boleh melaksanakan tugas pemahaman dan penjanaan pelbagai mod tanpa penalaan lebih lanjut. Sebagai contoh, LaVIT mempunyai keupayaan berikut: LaVIT ialah model penjanaan imej lanjutan yang boleh menjana nisbah aspek berbilang aspek berkualiti tinggi dan imej estetik tinggi berdasarkan gesaan teks. Keupayaan penjanaan imej LaVIT lebih baik dibandingkan dengan model penjanaan imej terkini seperti Parti, SDXL dan DALLE-3. Ia boleh mencapai penjanaan teks ke imej berkualiti tinggi dengan berkesan, memberikan pengguna lebih banyak pilihan dan pengalaman visual yang lebih baik.
Penjanaan imej berdasarkan gesaan berbilang modal: Memandangkan dalam LaVIT, imej dan teks diwakili secara seragam sebagai token diskret, ia boleh menerima gabungan berbilang modal (seperti teks, imej + teks, imej + imej) sebagai gesaan untuk menjana imej yang sepadan tanpa sebarang penalaan halus.
 Fasa 1 : Tokenizer Visual Dinamik
Fasa 1 : Tokenizer Visual Dinamik

Discretization: Token visual harus diwakili sebagai bentuk diskret seperti teks. Ini menggunakan borang perwakilan bersatu untuk dua modaliti, yang kondusif untuk LaVIT menggunakan kehilangan klasifikasi yang sama untuk pengoptimuman pemodelan pelbagai mod di bawah rangka kerja latihan generatif autoregresif bersatu.
 Dynamic
Dynamic
ifikasi: Tidak seperti token teks, patch imej mempunyai kesalingbergantungan yang ketara antara mereka, menjadikannya agak mudah untuk membuat kesimpulan satu patch daripada yang lain. Oleh itu, pergantungan ini mengurangkan keberkesanan matlamat pengoptimuman ramalan token seterusnya LLM asal. LaVIT bercadang untuk mengurangkan lebihan antara patch visual dengan menggunakan penggabungan token, yang mengekodkan nombor dinamik token visual berdasarkan kerumitan semantik yang berbeza bagi imej yang berbeza. Dengan cara ini, untuk imej kerumitan yang berbeza, penggunaan pengekodan token dinamik meningkatkan lagi kecekapan pra-latihan dan mengelakkan pengiraan token berlebihan.
Angka berikut ialah struktur pembahagian kata visual yang dicadangkan oleh LaVIT: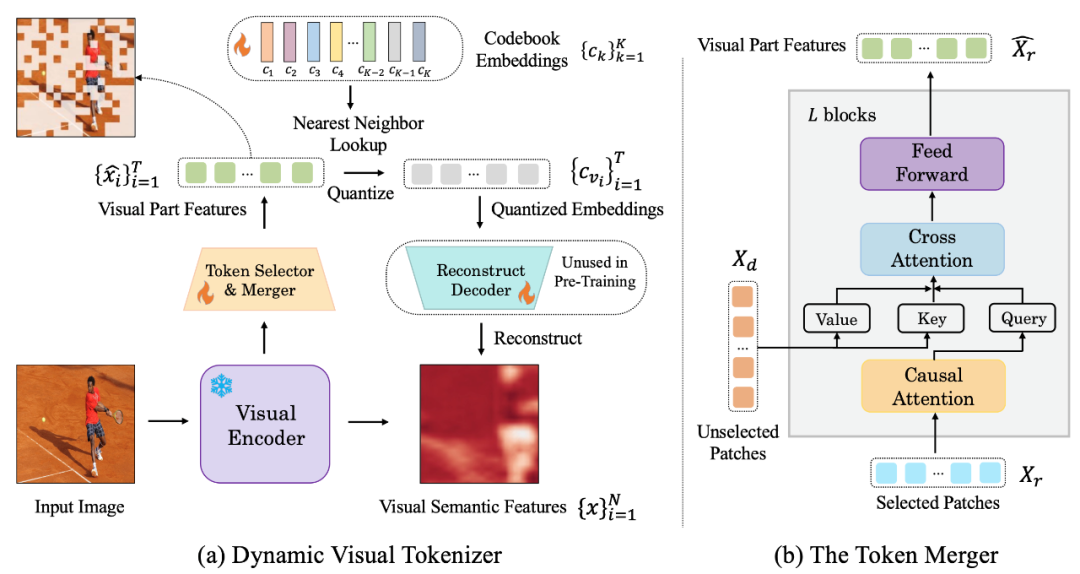
Rajah: (a) Penjana token visual dinamik (b) penggabung token
Tokenizer visual dinamik termasuk pemilih token dan penggabung token. Seperti yang ditunjukkan dalam rajah, pemilih token digunakan untuk memilih blok imej yang paling bermaklumat, manakala penggabungan token memampatkan maklumat blok visual tidak bermaklumat tersebut ke dalam token yang disimpan untuk mencapai penggabungan token berlebihan. Keseluruhan pembahagian perkataan visual dinamik dilatih dengan memaksimumkan pembinaan semula semantik imej input.
Pemilih token
Pemilih token menerima N ciri peringkat blok imej sebagai input adalah untuk menilai kepentingan setiap blok imej dan memilih blok dengan jumlah maklumat tertinggi untuk mewakili keseluruhan imej. Untuk mencapai matlamat ini, modul ringan yang terdiri daripada berbilang lapisan MLP digunakan untuk meramalkan taburan π. Dengan pensampelan daripada taburan π, topeng keputusan binari dijana yang menunjukkan sama ada untuk menyimpan tampung imej yang sepadan.
Penggabung token
Penggabung token membahagikan N blok imej kepada dua kumpulan: kekalkan X_r dan buang X_d mengikut topeng keputusan yang dihasilkan. Tidak seperti membuang X_d secara langsung, penggabung token boleh mengekalkan semantik terperinci imej input ke tahap maksimum. Penggabung token terdiri daripada blok bertindan L, setiap satunya termasuk lapisan perhatian kendiri sebab, lapisan perhatian silang dan lapisan ke hadapan. Dalam lapisan perhatian kendiri sebab, setiap token dalam X_r hanya memberi perhatian kepada token sebelumnya untuk memastikan konsistensi dengan bentuk token teks dalam LLM. Strategi ini berprestasi lebih baik berbanding dengan perhatian diri dua arah. Lapisan perhatian silang mengambil token yang disimpan X_r sebagai pertanyaan dan menggabungkan token dalam X_d berdasarkan persamaan semantiknya.
Fasa 2: Pra-latihan generatif bersatu
Token visual yang diproses oleh pembahagian perkataan visual disambungkan dengan token teks untuk membentuk urutan berbilang modal sebagai input semasa latihan. Untuk membezakan kedua-dua modaliti, pengarang memasukkan token khas pada permulaan dan penghujung jujukan token imej: [IMG] dan [/IMG], yang digunakan untuk menunjukkan permulaan dan akhir kandungan visual. Untuk dapat menjana teks dan imej, LaVIT menggunakan dua bentuk sambungan imej-teks: [imej, teks] dan [teks;
Untuk jujukan input berbilang modal ini, LaVIT menggunakan pendekatan bersatu dan autoregresif untuk memaksimumkan secara langsung kemungkinan setiap jujukan berbilang modal untuk pra-latihan. Penyatuan lengkap ruang perwakilan dan kaedah latihan ini membantu LLM mempelajari interaksi dan penjajaran pelbagai mod dengan lebih baik. Selepas pra-latihan selesai, LaVIT mempunyai keupayaan untuk melihat imej dan boleh memahami serta menjana imej seperti teks.
Eksperimen
Pemahaman multimodal sifar tangkapan
LaVIT telah mencapai hasil terkini pada tugas pemahaman multimodal tangkapan sifar seperti penjanaan kapsyen imej (NoCaps, Flickr30k (VQA) menjawab soalan visual , OKVQA, GQA, VizWiz) Prestasi terkemuka. . mempunyai keupayaan untuk mensintesis imej dengan menjana token visual seperti teks melalui autoregresi. Penulis menjalankan penilaian kuantitatif prestasi sintesis imej model di bawah keadaan teks sampel sifar, dan keputusan perbandingan ditunjukkan dalam Jadual 2.
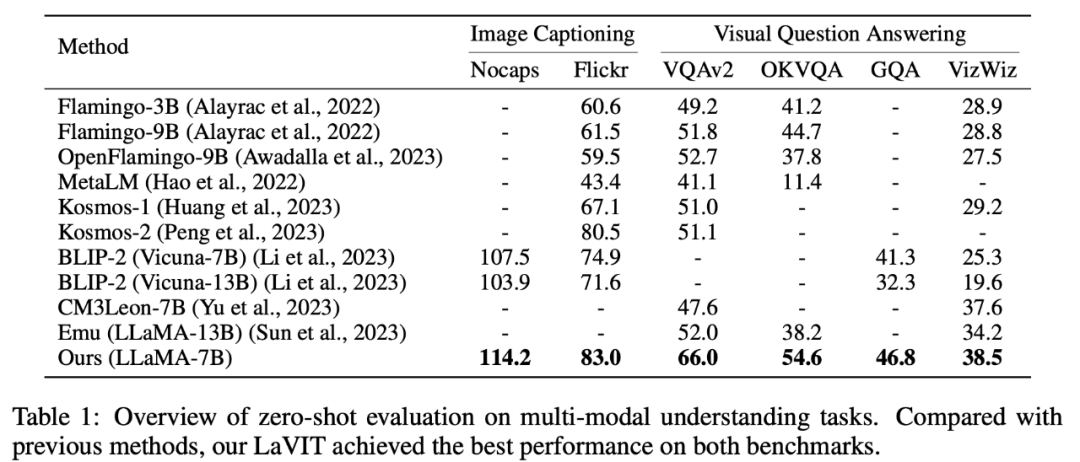
Jadual 2 Teks tangkapan sifar kepada prestasi penjanaan imej model berbeza
Seperti yang dapat dilihat daripada jadual, LaVIT mengatasi semua model bahasa berbilang mod yang lain. Berbanding dengan Emu, LaVIT mencapai peningkatan selanjutnya pada model LLM yang lebih kecil, menunjukkan keupayaan penjajaran visual-verbal yang sangat baik. Tambahan pula, LaVIT mencapai prestasi yang setanding dengan Parti pakar teks-ke-imej terkini sambil menggunakan kurang data latihan.
Penjanaan imej gesaan berbilang modalLaVIT mampu menerima dengan lancar berbilang kombinasi modal sebagai gesaan dan menjana imej yang sepadan tanpa sebarang penalaan halus. LaVIT menjana imej yang menggambarkan dengan tepat gaya dan semantik isyarat multimodal tertentu. Dan ia boleh mengubah suai imej input asal dengan isyarat multi-modal input. Model penjanaan imej tradisional seperti Stable Diffusion tidak dapat mencapai keupayaan ini tanpa data hiliran tambahan yang diperhalusi. 
Contoh hasil penjanaan imej pelbagai modal
Analisis kualitatif
Seperti yang ditunjukkan dalam rajah di bawah, tokenizer dinamik LaVIT boleh memilih blok imej yang paling bermaklumat secara dinamik berdasarkan kandungan imej, dan kod yang dipelajari boleh menghasilkan pengekodan visual dengan semantik peringkat tinggi.

Visualisasi tokenizer visual dinamik (kiri) dan buku kod yang dipelajari (kanan)
Ringkasan
Kemunculan paradigma pelbagai tugasan yang berjaya menyediakan proses inovatif yang berjaya. paradigma pembelajaran generatif autoregresif LLM dengan menggunakan tokenizer visual dinamik untuk mewakili penglihatan dan bahasa ke dalam perwakilan token diskret bersatu. Dengan mengoptimumkan di bawah matlamat penjanaan bersatu, LaVIT boleh menganggap imej sebagai bahasa asing, memahami dan menjananya seperti teks. Kejayaan kaedah ini memberikan inspirasi baharu untuk hala tuju pembangunan penyelidikan multimodal masa depan, menggunakan keupayaan penaakulan berkuasa LLM untuk membuka kemungkinan baharu bagi pemahaman dan penjanaan multimodal yang lebih bijak dan komprehensif.
Atas ialah kandungan terperinci Model besar berbilang modal Kuaishou dan Beida: imej adalah bahasa asing, setanding dengan kejayaan DALLE-3. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 世界vr产业大会地址在哪
- Taman perindustrian peringkat kampung Foshan dilahirkan semula: tangga naik dan turun di bandar pembuatan pintar robot adalah hulu dan hilir, dan taman perindustrian ialah rantaian industri
- Artikel ciri|Permintaan untuk kuasa pengkomputeran meletup di bawah ledakan model besar AI: Lingang mahu membina industri berpuluh-puluh bilion, dan SenseTime akan menjadi 'tuan rantai'
- Perikatan industri antara muka otak-komputer mengeluarkan sepuluh teknologi antara muka otak-komputer utama
- Persidangan Pengkomputeran Kecerdasan Buatan 2023 AICC telah diadakan di Beijing, memfokuskan pada perbincangan hangat industri mengenai model berskala besar dan kuasa pengkomputeran pintar