
Rumah >Peranti teknologi >AI >Penanda aras terkini CMMMU sesuai untuk fizikal LMM Cina: termasuk lebih daripada 30 subbahagian dan 12K soalan peringkat pakar
Penanda aras terkini CMMMU sesuai untuk fizikal LMM Cina: termasuk lebih daripada 30 subbahagian dan 12K soalan peringkat pakar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-29 09:24:251320semak imbas
Memandangkan model besar multimodal (LMM) terus maju, keperluan untuk menilai prestasi LMM juga semakin meningkat. Terutamanya dalam persekitaran Cina, menjadi lebih penting untuk menilai pengetahuan lanjutan dan keupayaan penaakulan LMM.
Dalam konteks ini, untuk menilai keupayaan pemahaman pelbagai mod peringkat pakar bagi model asas dalam pelbagai tugas dalam bahasa Cina, komuniti sumber terbuka M-A-P, Universiti Sains dan Teknologi Hong Kong, Universiti Waterloo dan Zero One Thing bersama-sama melancarkan penanda aras CMMMU (Chinese Massive Multi-discipline Multimodal Understanding and Reasoning). Penanda aras ini bertujuan untuk menyediakan platform penilaian yang komprehensif untuk pemahaman dan penaakulan pelbagai mod berskala besar pelbagai disiplin dalam bahasa Cina. Penanda aras membolehkan penyelidik menguji model pada pelbagai tugas dan membandingkan keupayaan pemahaman pelbagai mod mereka kepada tahap profesional. Matlamat projek bersama ini adalah untuk menggalakkan pembangunan bidang pemahaman dan penaakulan multimodal Cina dan menyediakan rujukan piawai untuk penyelidikan berkaitan.
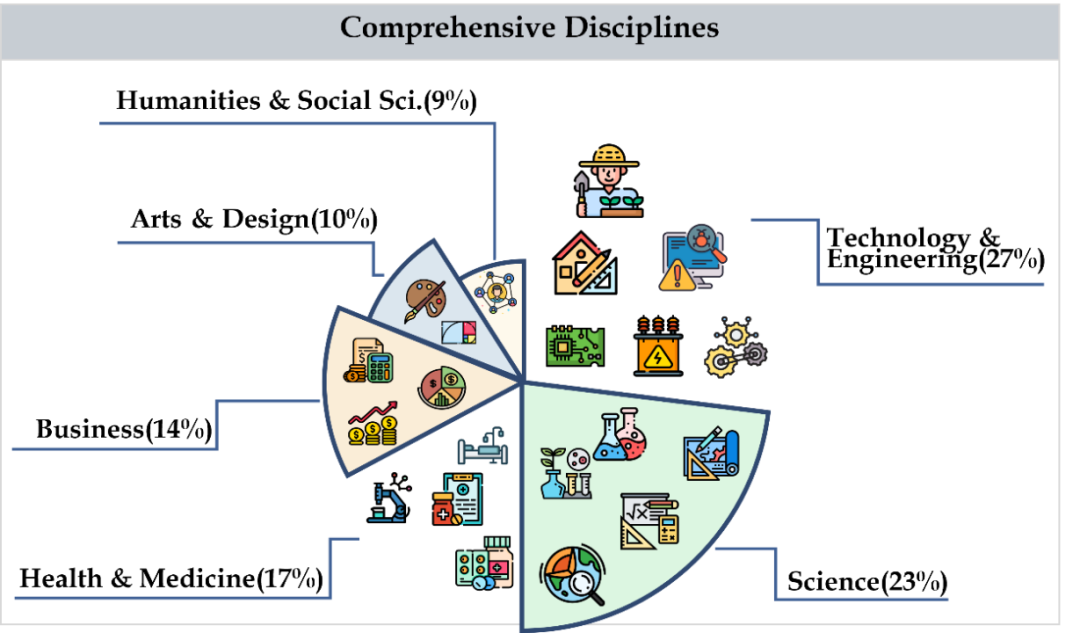
CMMMU merangkumi enam kategori utama mata pelajaran, termasuk seni, perniagaan, kesihatan dan perubatan, sains, kemanusiaan dan sains sosial, teknologi dan kejuruteraan, yang melibatkan lebih daripada 30 subbahagian. Rajah di bawah menunjukkan contoh soalan bagi setiap subjek subbidang. CMMMU ialah salah satu penanda aras berbilang modal pertama dalam konteks Cina dan salah satu daripada beberapa penanda aras berbilang modal yang mengkaji keupayaan pemahaman dan penaakulan yang kompleks bagi LMM.

Pembinaan set data
Pengumpulan data
Pengumpulan data dibahagikan kepada tiga peringkat. Pertama, penyelidik mengumpul sumber soalan untuk setiap subjek yang memenuhi keperluan pelesenan hak cipta, termasuk halaman web atau buku. Semasa proses ini, mereka bekerja keras untuk mengelakkan pertindihan sumber soalan untuk memastikan kepelbagaian dan ketepatan data. Kedua, penyelidik memajukan sumber soalan kepada anotasi sumber ramai untuk penjelasan lanjut. Semua annotator adalah individu yang mempunyai ijazah sarjana muda atau lebih tinggi untuk memastikan mereka boleh mengesahkan soalan beranotasi dan penjelasan yang berkaitan. Semasa proses anotasi, penyelidik memerlukan anotasi untuk mematuhi prinsip anotasi dengan ketat. Contohnya, tapis soalan yang tidak memerlukan gambar untuk dijawab, tapis soalan yang menggunakan imej yang sama apabila boleh dan tapis soalan yang tidak memerlukan pengetahuan pakar untuk menjawab. Akhir sekali, untuk mengimbangi bilangan soalan dalam setiap subjek dalam set data, penyelidik secara khusus menambah subjek dengan soalan yang lebih sedikit. Melakukannya memastikan kesempurnaan dan keterwakilan set data, membolehkan analisis dan penyelidikan seterusnya menjadi lebih tepat dan komprehensif.
Pembersihan Set Data
Untuk meningkatkan lagi kualiti data CMMMU, penyelidik mengikut protokol kawalan kualiti data yang ketat. Pertama, setiap soalan disahkan secara peribadi oleh sekurang-kurangnya seorang pengarang kertas itu. Kedua, untuk mengelakkan masalah pencemaran data, mereka juga menapis soalan yang boleh dijawab oleh beberapa LLM tanpa menggunakan teknologi OCR. Langkah-langkah ini memastikan kebolehpercayaan dan ketepatan data CMMMU.
Tinjauan Keseluruhan Set Data
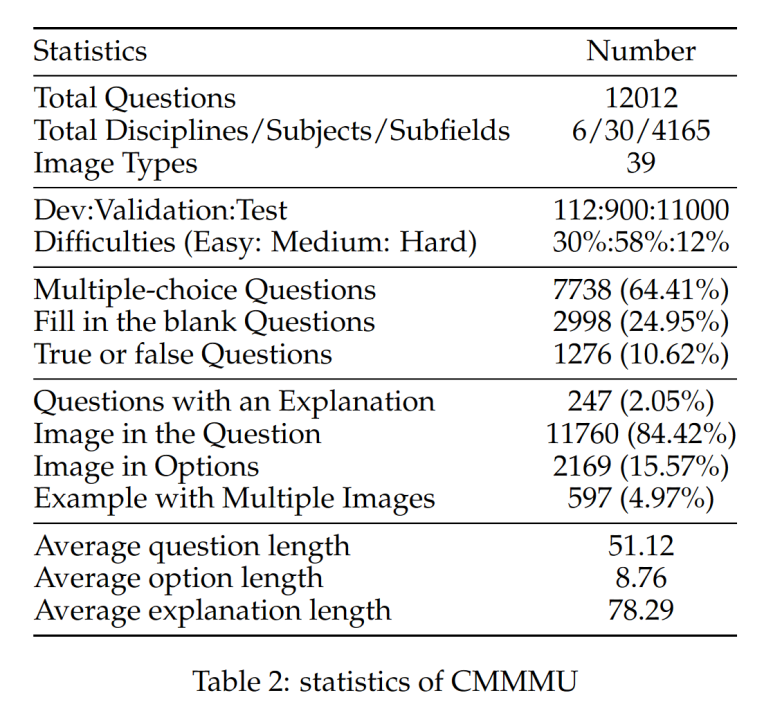
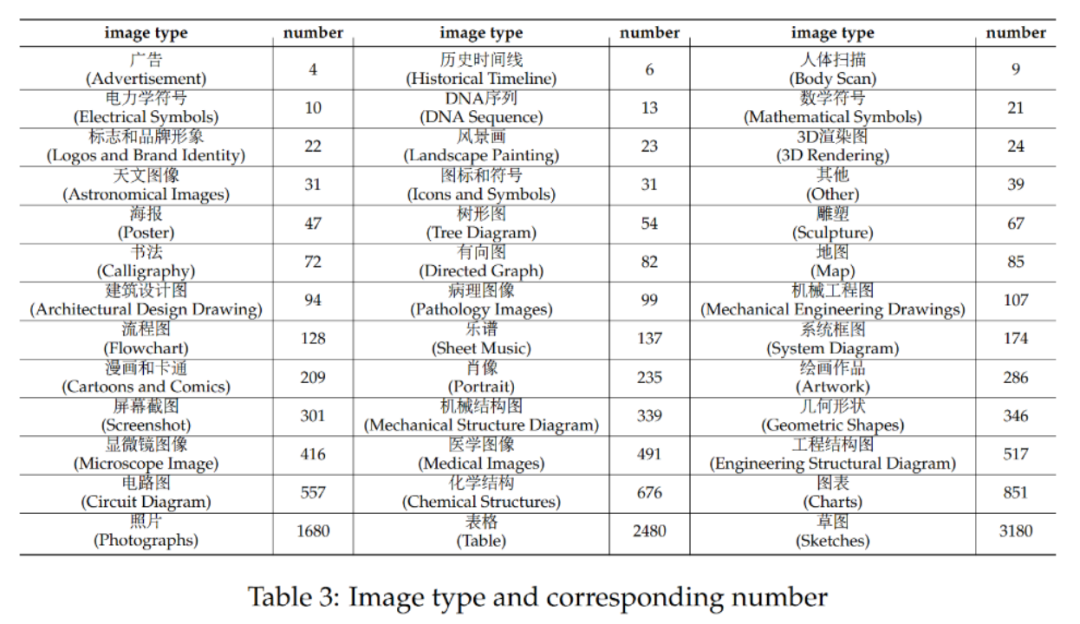
CMMMU mempunyai sejumlah 12K soalan, yang dibahagikan kepada beberapa set pembangunan sampel, set pengesahan dan set ujian. Set pembangunan beberapa sampel mengandungi kira-kira 5 soalan untuk setiap subjek, set pengesahan mempunyai 900 soalan, dan set ujian mempunyai 11K soalan. Soalan merangkumi 39 jenis gambar, termasuk gambar rajah patologi, gambar rajah notasi muzik, gambar rajah litar, gambar rajah struktur kimia, dsb. Soalan dibahagikan kepada tiga aras kesukaran: mudah (30%), sederhana (58%) dan sukar (12%) berdasarkan kesukaran logik dan bukannya kesukaran intelek. Lebih banyak statistik soalan boleh didapati dalam Jadual 2 dan Jadual 3. Pasukan ini menguji prestasi pelbagai LMM dwibahasa Cina dan Inggeris arus perdana dan beberapa LLM di CMMMU. Kedua-dua model sumber tertutup dan sumber terbuka disertakan. Proses penilaian menggunakan tetapan sifar tangkapan dan bukannya tetapan penalaan halus atau beberapa tangkapan untuk menyemak keupayaan mentah model. LLM juga menambah eksperimen yang mana hasil OCR imej + teks digunakan sebagai input. Semua eksperimen dilakukan pada pemproses grafik NVIDIA A100.
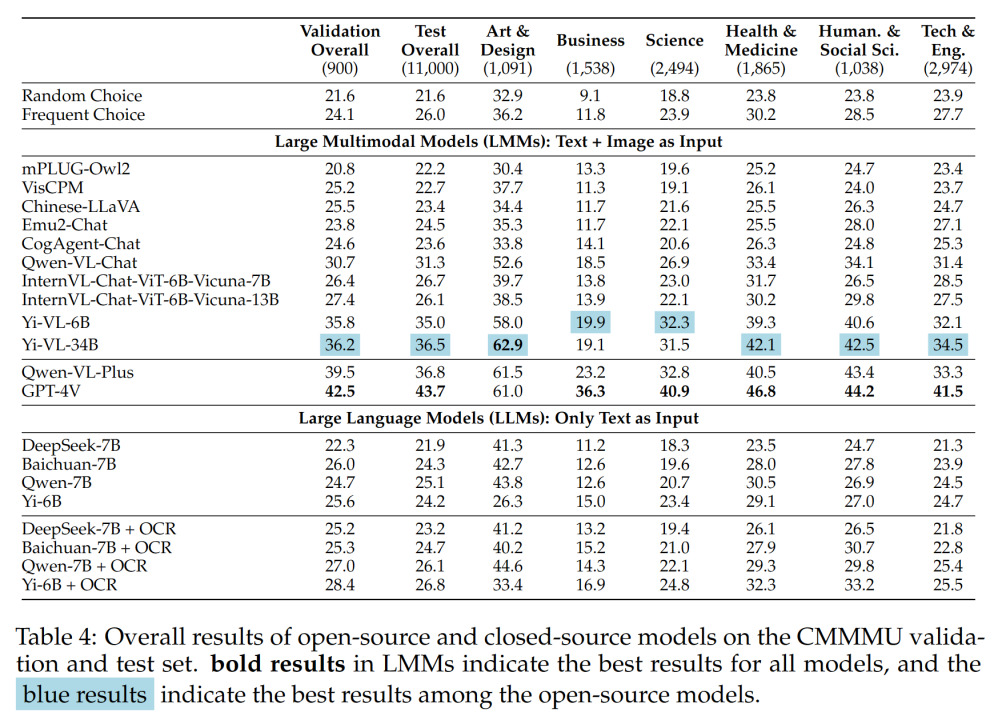
 Jadual 4 menunjukkan keputusan eksperimen:
Jadual 4 menunjukkan keputusan eksperimen:
Beberapa penemuan penting termasuk:
- CMMMU lebih mencabar daripada MMMU, dan ini adalah atas premis bahawa MMMU sudah sangat mencabar.
Ketepatan GPT-4V dalam konteks Cina hanya 41.7%, manakala ketepatannya dalam konteks Inggeris ialah 55.7%. Ini menunjukkan bahawa kaedah generalisasi merentas bahasa sedia ada tidak cukup baik walaupun untuk LMM sumber tertutup yang terkini.
- Berbanding dengan MMMU, jurang antara model sumber terbuka wakil domestik dan GPT-4V adalah agak kecil.
Perbezaan antara Qwen-VL-Chat dan GPT-4V pada MMMU ialah 13.3%, manakala perbezaan antara BLIP2-FLAN-T5-XXL dan GPT-4V pada MMMU ialah 21.9%. Yang menghairankan, Yi-VL-34B malah mengecilkan jurang antara LMM dwibahasa sumber terbuka dan GPT-4V pada CMMMU kepada 7.5%, yang bermaksud bahawa dalam persekitaran Cina, LMM dwibahasa sumber terbuka adalah bersamaan dengan GPT-4V, iaitu This merupakan perkembangan yang menjanjikan dalam komuniti sumber terbuka.
- Dalam komuniti sumber terbuka, permainan mengejar kecerdasan am buatan (AGI) multimodal pakar China baru sahaja bermula. Pasukan
menegaskan bahawa, kecuali Qwen-VL-Chat, Yi-VL-6B dan Yi-VL-34B yang dikeluarkan baru-baru ini, semua LMM dwibahasa daripada komuniti sumber terbuka hanya boleh mencapai ketepatan yang setanding dengan kekerapan CMMMU. pilihan. . berbeza dalam keupayaan mereka menjawab soalan aneka pilihan.
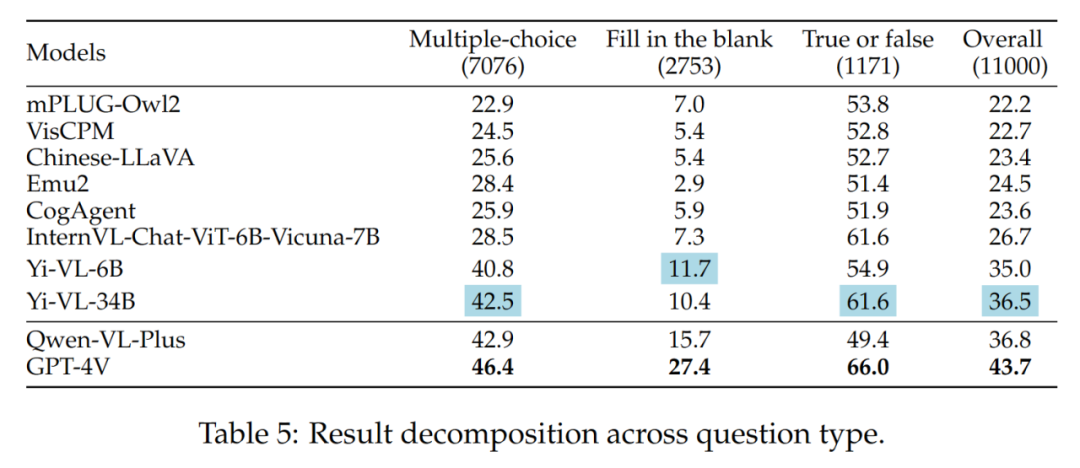
Keputusan jenis soalan yang berbeza ditunjukkan dalam Jadual 5:
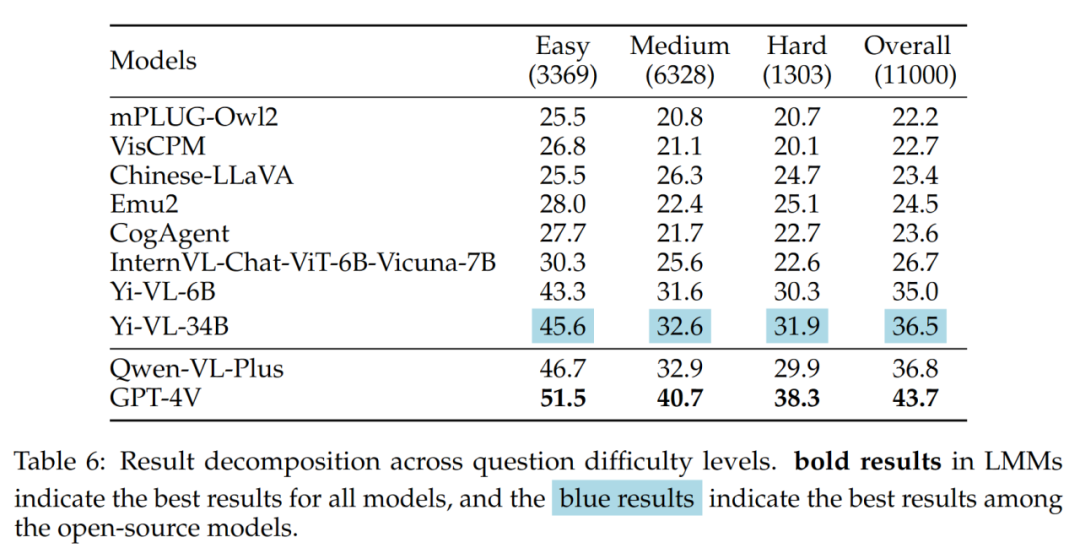
- Kesukaran soalan yang berbeza
Apa yang patut diberi perhatian dalam sumber terbuka Y. -VL- 34B) dan GPT-4V mempunyai jurang yang besar apabila menghadapi masalah sederhana dan sukar. Ini adalah bukti kukuh lagi bahawa perbezaan utama antara LMM sumber terbuka dan GPT-4V ialah keupayaan untuk mengira dan menaakul di bawah keadaan yang kompleks.
Hasil kesukaran soalan yang berbeza ditunjukkan dalam Jadual 6:
Analisis ralat
Para penyelidik GPT-4V menganalisis dengan teliti jawapan yang salah Seperti yang ditunjukkan dalam rajah di bawah, jenis kesilapan utama ialah kesilapan persepsi, kekurangan pengetahuan, kesilapan penaakulan, keengganan untuk menjawab, dan kesilapan anotasi. Menganalisis jenis ralat ini adalah kunci untuk memahami keupayaan dan had LMM semasa dan juga boleh membimbing reka bentuk dan penambahbaikan model latihan pada masa hadapan.
Ralat persepsi adalah salah satu sebab utama GPT-4V menghasilkan contoh yang salah. Di satu pihak, apabila model tidak dapat memahami imej, ia memperkenalkan kecenderungan kepada persepsi asas imej, yang membawa kepada tindak balas yang salah. Sebaliknya, apabila model menghadapi kekaburan dalam pengetahuan khusus domain, makna tersirat atau formula yang tidak jelas, ia sering mempamerkan ralat persepsi khusus domain. Dalam kes ini, GPT-4V cenderung untuk lebih bergantung pada jawapan berasaskan maklumat tekstual (iaitu soalan dan pilihan), mengutamakan maklumat tekstual berbanding input visual, mengakibatkan berat sebelah dalam memahami data berbilang modal.
- Ralat Inferens (26%) :
Ralat inferens merupakan satu lagi faktor utama dalam GPT-4V menghasilkan contoh yang salah. Walaupun model memahami dengan betul maksud yang disampaikan oleh imej dan teks, ralat masih boleh berlaku semasa penaakulan apabila menyelesaikan masalah yang memerlukan penaakulan logik dan matematik yang kompleks. Biasanya, ralat ini disebabkan oleh keupayaan penaakulan logik dan matematik model yang lemah. 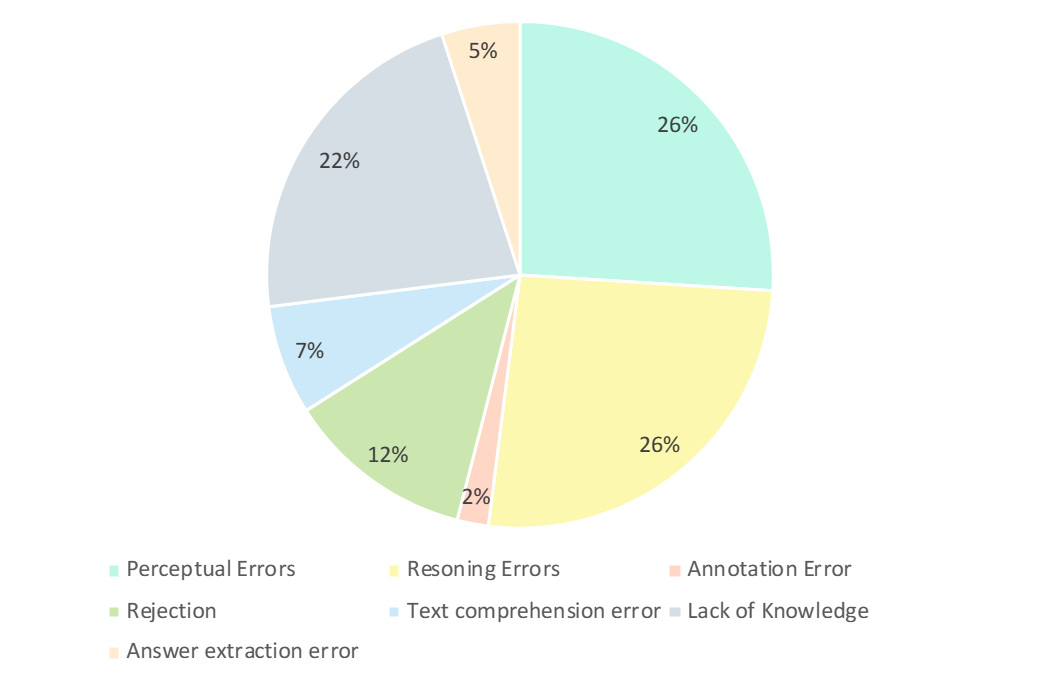
- Kurang pengetahuan (22%): Kurang kepakaran juga merupakan salah satu punca jawapan yang salah kepada GPT-4V. Memandangkan CMMMU ialah penanda aras untuk menilai AGI pakar LMM, pengetahuan peringkat pakar dalam pelbagai disiplin dan subbidang diperlukan. Oleh itu, menyuntik ilmu peringkat pakar ke dalam LMM juga merupakan salah satu hala tuju yang boleh diusahakan.
- Enggan menjawab (12%): Ia juga merupakan fenomena biasa bagi model yang enggan menjawab. Melalui analisis, mereka menunjukkan beberapa sebab mengapa model itu enggan menjawab soalan: (1) Model gagal melihat maklumat daripada imej; (2) Ia adalah soalan yang melibatkan isu agama atau maklumat kehidupan sebenar peribadi, dan model; akan secara aktif mengelakkannya; (3) Apabila soalan melibatkan jantina dan faktor subjektif, model mengelak daripada memberikan jawapan langsung.
- Ralatnya: Ralat selebihnya termasuk ralat pemahaman teks (7%), ralat anotasi (2%) dan ralat pengekstrakan jawapan (5%). Ralat ini disebabkan oleh pelbagai faktor seperti keupayaan penjejakan struktur kompleks, pemahaman logik teks yang kompleks, had dalam penjanaan respons, ralat dalam anotasi data dan masalah yang dihadapi dalam pengekstrakan padanan jawapan.
Kesimpulan
Tanda aras CMMMU menandakan kemajuan ketara dalam pembangunan Kepintaran Buatan Am Lanjutan (AGI). CMMMU direka bentuk untuk menilai dengan teliti model multimodal besar (LMM) terkini dan menguji kemahiran persepsi asas, penaakulan logik yang kompleks dan kepakaran mendalam dalam domain tertentu. Kajian ini menunjukkan perbezaan dengan membandingkan keupayaan penaakulan LMM dalam konteks dwibahasa Cina dan Inggeris. Penilaian terperinci ini adalah penting dalam menentukan sejauh mana model dibandingkan dengan kecekapan profesional berpengalaman dalam setiap bidang.
Atas ialah kandungan terperinci Penanda aras terkini CMMMU sesuai untuk fizikal LMM Cina: termasuk lebih daripada 30 subbahagian dan 12K soalan peringkat pakar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!