
Rumah >Peranti teknologi >AI >Model Transformer berjaya mempelajari dunia fizikal menggunakan 2 bilion mata data dalam penjanaan video cabaran
Model Transformer berjaya mempelajari dunia fizikal menggunakan 2 bilion mata data dalam penjanaan video cabaran

- 王林ke hadapan
- 2024-01-29 09:09:261304semak imbas
Membina model dunia yang boleh membuat video juga boleh dicapai melalui Transformer!
Penyelidik dari Universiti Tsinghua dan Teknologi Jiji telah bergabung tenaga untuk melancarkan model dunia universal baharu untuk penjanaan video - WorldDreamer.
Ia boleh menyelesaikan pelbagai tugas penjanaan video, termasuk adegan semula jadi dan adegan pemanduan autonomi, seperti video Vincent, video gambar, penyuntingan video, video urutan tindakan, dsb.

Menurut pasukan itu, WorldDreamer adalah yang pertama dalam industri membina model dunia senario universal dengan meramalkan Token.
Ia menukar penjanaan video kepada tugas ramalan jujukan, yang boleh mempelajari sepenuhnya perubahan dan corak pergerakan dunia fizikal.
Percubaan visual telah membuktikan bahawa WorldDreamer mempunyai pemahaman yang mendalam tentang perubahan dinamik dunia umum.
Jadi, apakah tugasan video yang boleh disiapkan, dan sejauh manakah keberkesanannya?
Menyokong berbilang tugasan video
Imej ke Video (Imej ke Video)
WorldDreamer boleh meramalkan bingkai masa hadapan berdasarkan satu imej.
Hanya imej pertama dimasukkan, WorldDreamer menganggap baki bingkai video sebagai token visual bertopeng dan meramalkan token ini.
Seperti yang ditunjukkan dalam gambar di bawah, WorldDreamer mempunyai keupayaan untuk menjana video peringkat filem berkualiti tinggi.
Video yang terhasil mempamerkan gerakan bingkai demi bingkai yang lancar, sama seperti pergerakan kamera yang lancar dalam filem sebenar.
Selain itu, video ini mematuhi kekangan imej asal, memastikan konsistensi yang luar biasa dalam komposisi bingkai.

Teks ke Video
WorldDreamer juga boleh menjana video berdasarkan teks.
Hanya diberikan input teks bahasa, WorldDreamer menganggap semua bingkai video sebagai token visual bertopeng dan meramalkan token ini.
Imej di bawah menunjukkan keupayaan WorldDreamer untuk menjana video daripada teks di bawah pelbagai paradigma gaya.
Video yang dijana sesuai dengan lancar dengan bahasa input, di mana input bahasa oleh pengguna boleh membentuk kandungan video, gaya dan pergerakan kamera.

Video Inpainting
WorldDreamer boleh merealisasikan lagi tugas melukis video.
Secara khusus, diberikan video, pengguna boleh menentukan kawasan topeng, dan kemudian kandungan video kawasan bertopeng boleh diubah mengikut input bahasa.
Seperti yang ditunjukkan dalam gambar di bawah, WorldDreamer boleh menggantikan obor-obor dengan beruang, atau biawak dengan monyet, dan video yang digantikan sangat konsisten dengan penerangan bahasa pengguna.

Penggayaan Video
Selain itu, WorldDreamer boleh menggayakan video.
Seperti yang ditunjukkan dalam gambar di bawah, masukkan segmen video yang mana piksel tertentu bertopeng secara rawak dan WorldDreamer boleh menukar gaya video, seperti mencipta kesan tema musim luruh berdasarkan bahasa input.

Berdasarkan video sintesis tindakan (Tindakan ke Video)
WorldDreamer juga boleh menjana aksi memandu ke video dalam senario pemanduan autonomi.
Seperti yang ditunjukkan dalam rajah di bawah, memandangkan bingkai awal yang sama dan strategi pemanduan yang berbeza (seperti belok kiri, belok kanan), WorldDreamer boleh menjana video yang sangat mematuhi kekangan bingkai pertama dan strategi pemanduan.

Jadi, bagaimanakah WorldDreamer mencapai fungsi ini?
Membina model dunia dengan Transformer
Penyelidik percaya bahawa kaedah penjanaan video yang paling maju terbahagi terutamanya kepada dua kategori - kaedah berasaskan Transformer dan kaedah berasaskan model penyebaran.
Menggunakan Transformer untuk ramalan token boleh mempelajari maklumat dinamik isyarat video dengan cekap dan menggunakan semula pengalaman komuniti model bahasa yang besar Oleh itu, penyelesaian berasaskan Transformer ialah cara yang berkesan untuk mempelajari model dunia umum.
Kaedah berdasarkan model resapan sukar untuk menyepadukan berbilang mod dalam satu model dan sukar untuk dikembangkan kepada parameter yang lebih besar, jadi sukar untuk mempelajari perubahan dan undang-undang pergerakan dunia umum.
Penyelidikan model dunia semasa tertumpu terutamanya dalam bidang permainan, robot dan pemanduan autonomi, dan tidak mempunyai keupayaan untuk menangkap secara menyeluruh perubahan dunia dan corak gerakan.
Jadi, pasukan penyelidik mencadangkan WorldDreamer untuk meningkatkan pembelajaran dan pemahaman tentang perubahan dan corak pergerakan di dunia umum, dengan itu meningkatkan keupayaan penjanaan video dengan ketara.
Berdasarkan pengalaman kejayaan model bahasa berskala besar, WorldDreamer mengguna pakai seni bina Transformer untuk menukar rangka kerja pemodelan model dunia kepada masalah ramalan token visual tanpa pengawasan.
Struktur model khusus ditunjukkan dalam rajah di bawah:
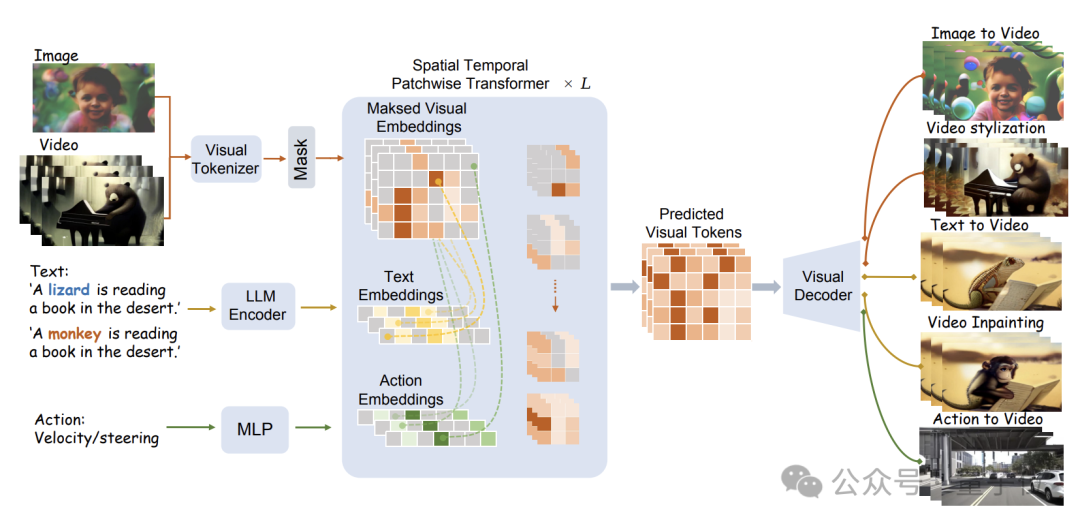
WorldDreamer mula-mula menggunakan Tokenizer visual untuk mengekod isyarat visual (imej dan video) ke dalam Token diskret.
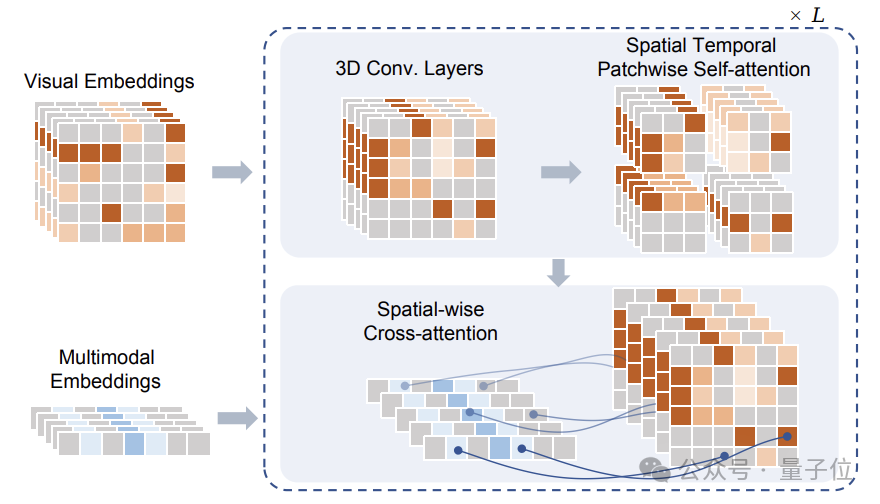
Selepas menutup, Token ini adalah input kepada modul Sptial Temporal Patchwuse Transformer (STPT) yang dicadangkan oleh pasukan penyelidik.
Pada masa yang sama, isyarat teks dan tindakan masing-masing dikodkan ke dalam vektor ciri yang sepadan untuk dimasukkan ke STPT sebagai ciri berbilang modal.
STPT secara interaktif sepenuhnya mempelajari visual, bahasa, tindakan dan ciri-ciri lain secara dalaman, dan boleh meramalkan token visual bahagian bertopeng.
Akhirnya, token visual yang diramalkan ini boleh digunakan untuk menyelesaikan pelbagai tugas penjanaan video dan penyuntingan video.
Perlu diperhatikan bahawa semasa melatih WorldDreamer, pasukan penyelidik juga membina tiga kali ganda data Visual-Text-Action (visual-text-action), dan fungsi kehilangan semasa latihan hanya melibatkan ramalan Token penglihatan bertopeng, tiada isyarat penyeliaan tambahan.
Dalam triplet data yang dicadangkan oleh pasukan, hanya maklumat visual diperlukan, yang bermaksud bahawa latihan WorldDreamer masih boleh dilakukan walaupun tanpa teks atau data tindakan.
Mod ini bukan sahaja mengurangkan kesukaran pengumpulan data, tetapi juga membolehkan WorldDreamer menyokong penyiapan tugas penjanaan video tanpa diketahui atau hanya satu syarat.
Pasukan penyelidik menggunakan sejumlah besar data untuk melatih WorldDreamer, termasuk 2 bilion data imej yang dibersihkan, 10 juta video adegan biasa, 500,000 video beranotasi bahasa berkualiti tinggi dan hampir seribu video adegan pemanduan autonomi.
Pasukan menjalankan berjuta-juta latihan berulang pada 1 bilion tahap parameter yang boleh dipelajari Selepas penumpuan, WorldDreamer secara beransur-ansur memahami perubahan dan corak pergerakan dunia fizikal, dan mempunyai pelbagai keupayaan penjanaan video dan penyuntingan video.
Alamat kertas: https://arxiv.org/abs/2401.09985
Laman utama projek: https://world-dreamer.github.io/
Atas ialah kandungan terperinci Model Transformer berjaya mempelajari dunia fizikal menggunakan 2 bilion mata data dalam penjanaan video cabaran. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!