
Rumah >Peranti teknologi >AI >Netizen mendedahkan teknologi benam yang digunakan dalam model baharu OpenAI
Netizen mendedahkan teknologi benam yang digunakan dalam model baharu OpenAI

- 王林ke hadapan
- 2024-01-29 09:03:29885semak imbas
Beberapa hari lalu, OpenAI datang dengan gelombang kemas kini utama, mengumumkan 5 model baharu sekaligus, termasuk dua model pembenaman teks baharu.
Benam ialah penggunaan jujukan berangka untuk mewakili konsep dalam bahasa semula jadi, kod, dsb. Mereka membantu model pembelajaran mesin dan algoritma lain lebih memahami perhubungan antara kandungan dan memudahkan untuk melaksanakan tugas seperti pengelompokan atau pengambilan semula.
Secara amnya, menggunakan model benam yang lebih besar (seperti disimpan dalam memori vektor untuk mendapatkan semula) menggunakan lebih banyak kos, kuasa pengkomputeran, memori dan sumber storan. Walau bagaimanapun, dua model pembenaman teks yang dilancarkan oleh OpenAI menawarkan pilihan yang berbeza. Pertama, model text-embedding-3-small ialah model yang lebih kecil tetapi cekap. Ia boleh digunakan dalam persekitaran terhad sumber dan berfungsi dengan baik apabila mengendalikan tugasan pembenaman teks. Sebaliknya, model text-embedding-3-large lebih besar dan lebih berkuasa. Model ini boleh mengendalikan tugas pembenaman teks yang lebih kompleks dan memberikan perwakilan pembenaman yang lebih tepat dan terperinci. Walau bagaimanapun, menggunakan model ini memerlukan lebih banyak sumber pengkomputeran dan ruang storan. Oleh itu, bergantung kepada keperluan khusus dan kekangan sumber, model yang sesuai boleh dipilih untuk mengimbangi hubungan antara kos dan prestasi.
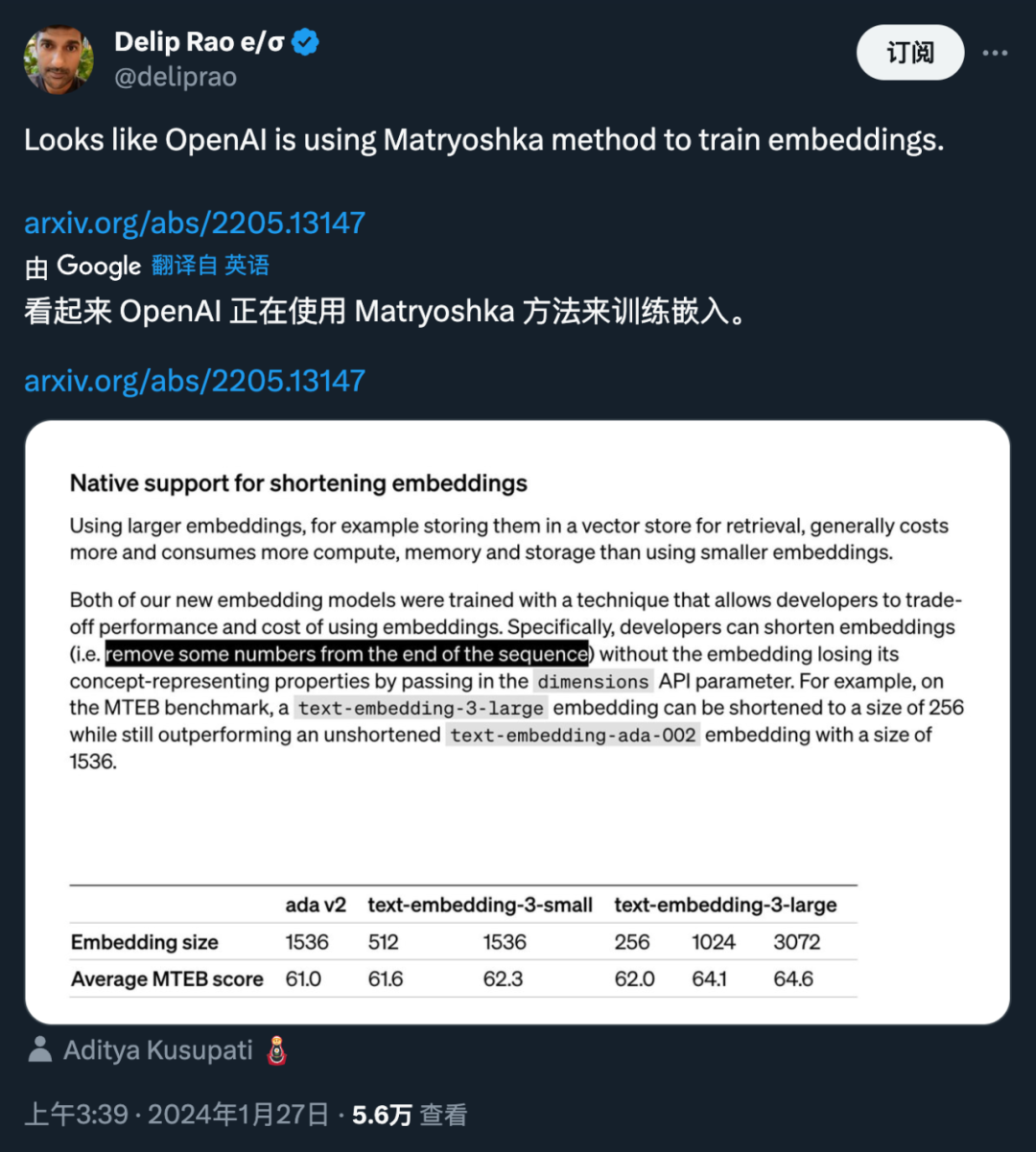
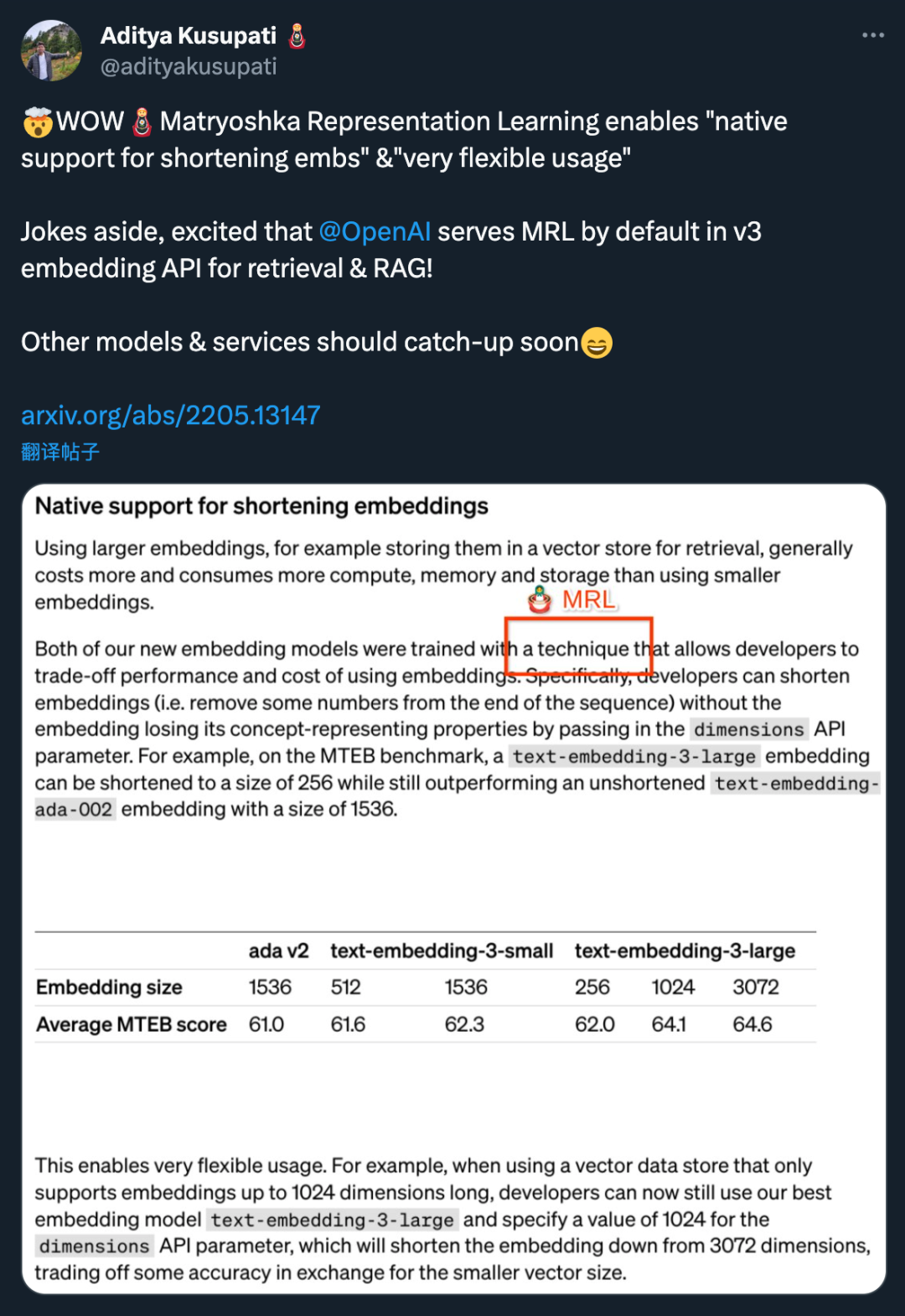
Kedua-dua model benam baharu dilakukan menggunakan teknik latihan yang membolehkan pembangun menukar prestasi dan kos pembenaman. Khususnya, pembangun boleh memendekkan saiz pembenaman tanpa kehilangan sifat perwakilan konsepnya dengan menghantar pembenaman dalam parameter API dimensi. Sebagai contoh, pada penanda aras MTEB, text-embedding-3-large boleh dipendekkan kepada saiz 256 tetapi masih mengatasi prestasi text-embedding-ada-002 yang tidak dipendekkan (bersaiz 1536). Dengan cara ini, pembangun boleh memilih model benam yang sesuai berdasarkan keperluan khusus, yang bukan sahaja dapat memenuhi keperluan prestasi tetapi juga mengawal kos.

Aplikasi teknologi ini sangat fleksibel. Sebagai contoh, apabila menggunakan stor data vektor yang hanya menyokong pembenaman sehingga 1024 dimensi, pembangun boleh memilih model pembenaman terbaik text-embedding-3-large dan menukar dimensi pembenaman daripada 3072 dengan menentukan nilai 1024 untuk API dimensi parameter dipendekkan kepada 1024. Walaupun beberapa ketepatan boleh dikorbankan dengan melakukan ini, saiz vektor yang lebih kecil boleh diperolehi.
Kaedah "pembenaman dipendekkan" yang digunakan oleh OpenAI kemudiannya menarik perhatian meluas daripada penyelidik.
Didapati kaedah ini adalah sama dengan kaedah "Matryoshka Representation Learning" yang dicadangkan dalam kertas kerja pada Mei 2022.
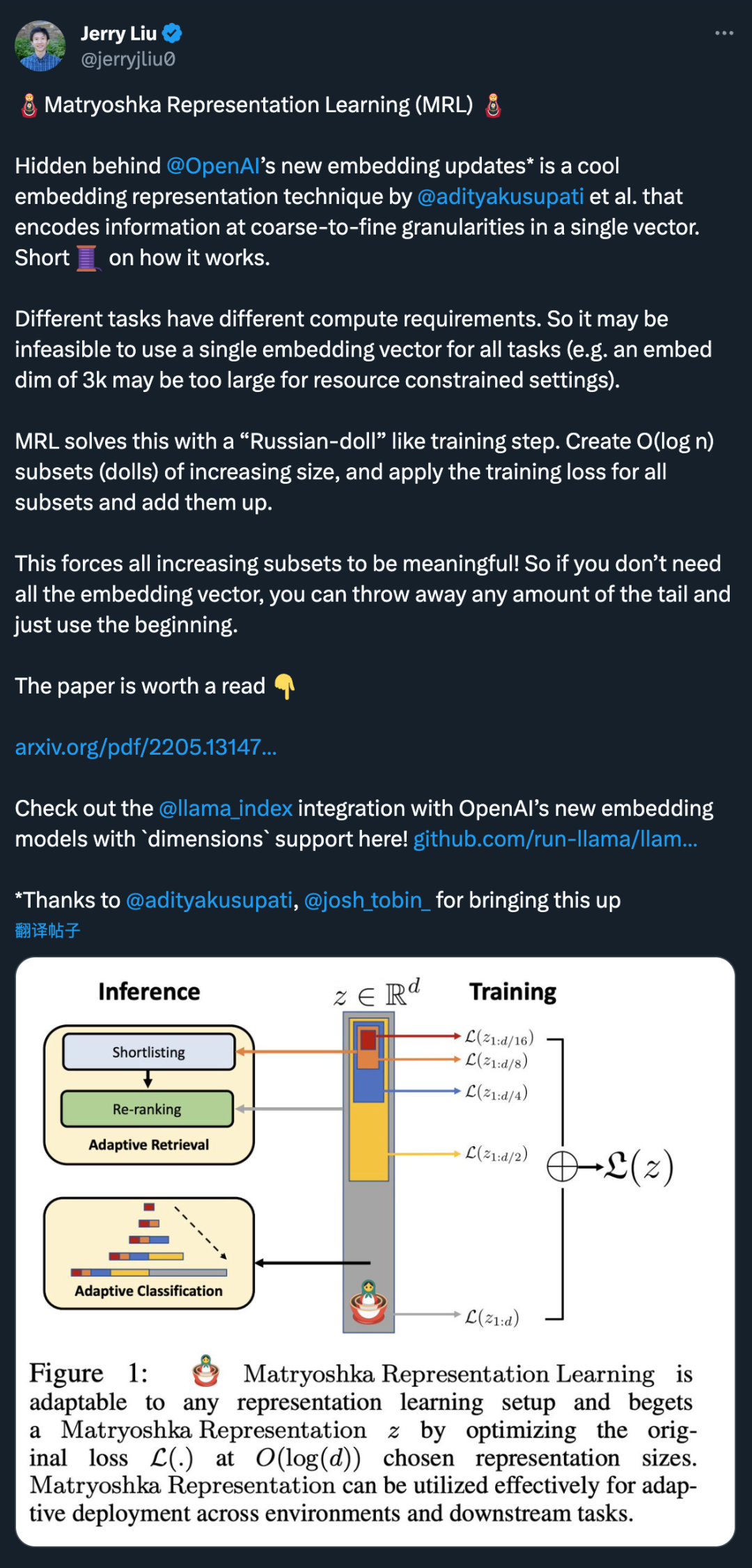
Tersembunyi di sebalik kemas kini model pembenaman baharu OpenAI ialah teknik perwakilan pembenaman hebat yang dicadangkan oleh @adityakusupati et al.
Dan Aditya Kusupati, salah seorang pengarang MRL, juga berkata: "OpenAI menggunakan MRL secara lalai dalam API terbenam v3 untuk mendapatkan semula dan RAG! Model dan perkhidmatan lain akan segera menyusul
Jadi MRL Apa sebenarnya? Sejauh mana keberkesanannya? Semuanya ada dalam kertas 2022 di bawah.
MRL Pengenalan Kertas

- Tajuk kertas: Matryoshka Representation Learning
- link.pdf
Persoalan yang dikemukakan oleh penyelidik ialah: Bolehkah kaedah perwakilan yang fleksibel direka bentuk untuk menyesuaikan diri dengan pelbagai tugas hiliran dengan sumber pengkomputeran yang berbeza?
MRL mempelajari perwakilan kapasiti yang berbeza dalam vektor dimensi tinggi yang sama dengan mengoptimumkan secara eksplisit O (log (d)) vektor dimensi rendah secara bersarang, maka dinamakan Matryoshka. MRL boleh disesuaikan dengan mana-mana saluran paip perwakilan sedia ada dan boleh diperluaskan dengan mudah kepada banyak tugas standard dalam penglihatan komputer dan pemprosesan bahasa semula jadi.
Rajah 1 menunjukkan idea teras MRL dan tetapan penggunaan suai bagi perwakilan Matryoshka yang dipelajari:
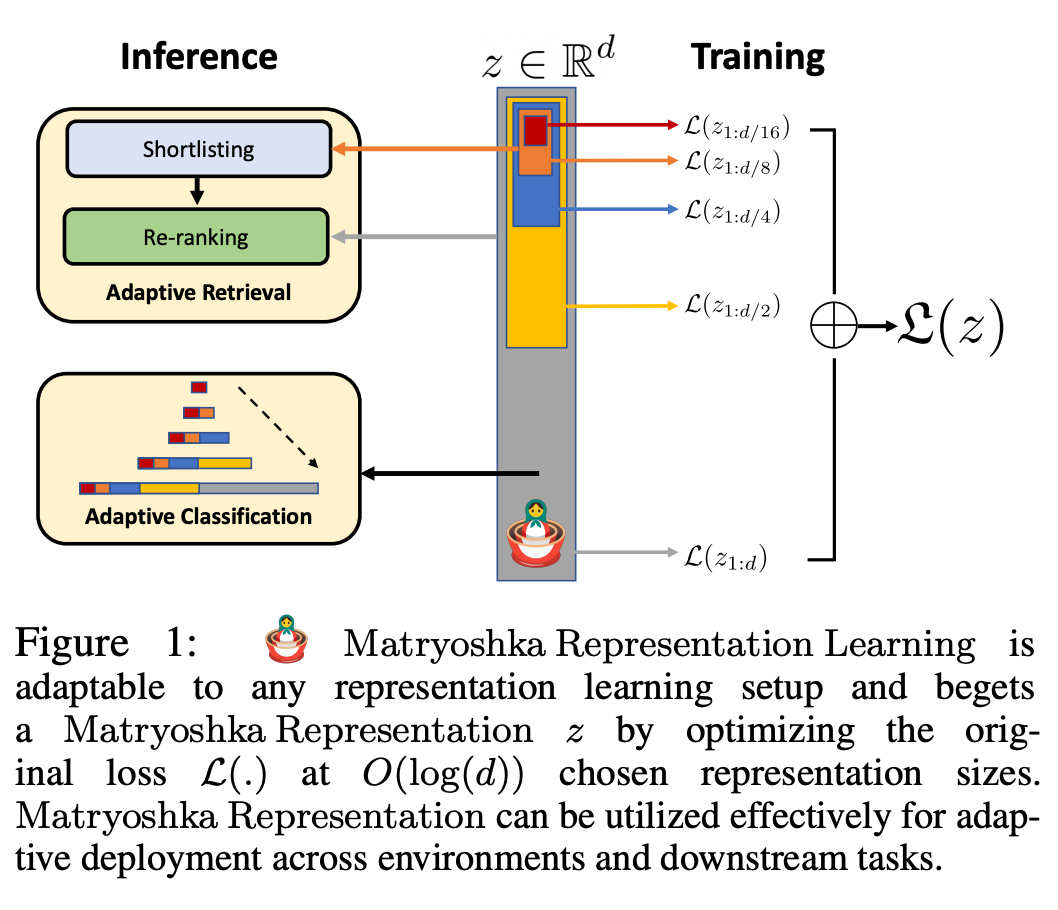
Dimensi-m pertama (m∈[d]) bagi perwakilan maklumat-Matryoshka ialah vektor dimensi rendah yang kaya, tiada kos latihan tambahan diperlukan, dan ketepatannya tidak kurang daripada kaedah perwakilan m-dimensi terlatih secara bebas. Kandungan maklumat perwakilan Matryoshka meningkat dengan peningkatan dimensi, membentuk perwakilan kasar hingga halus tanpa memerlukan latihan yang meluas atau overhed penggunaan tambahan. MRL menyediakan fleksibiliti dan pelbagai kesetiaan yang diperlukan untuk mencirikan vektor, memastikan pertukaran hampir optimum antara ketepatan dan usaha pengiraan. Dengan kelebihan ini, MRL boleh digunakan secara adaptif berdasarkan ketepatan dan kekangan pengiraan.
Dalam kerja ini, penyelidik menumpukan pada dua blok binaan utama sistem ML dunia sebenar: pengelasan dan perolehan berskala besar.
Untuk pengelasan, penyelidik menggunakan lata penyesuaian dan menggunakan perwakilan saiz berubah-ubah yang dihasilkan oleh model yang dilatih oleh MRL, sekali gus mengurangkan purata dimensi terbenam yang diperlukan untuk mencapai ketepatan tertentu. Contohnya, pada ImageNet-1K, klasifikasi penyesuaian MRL + menghasilkan pengurangan saiz perwakilan sehingga 14x dengan ketepatan yang sama seperti garis dasar.
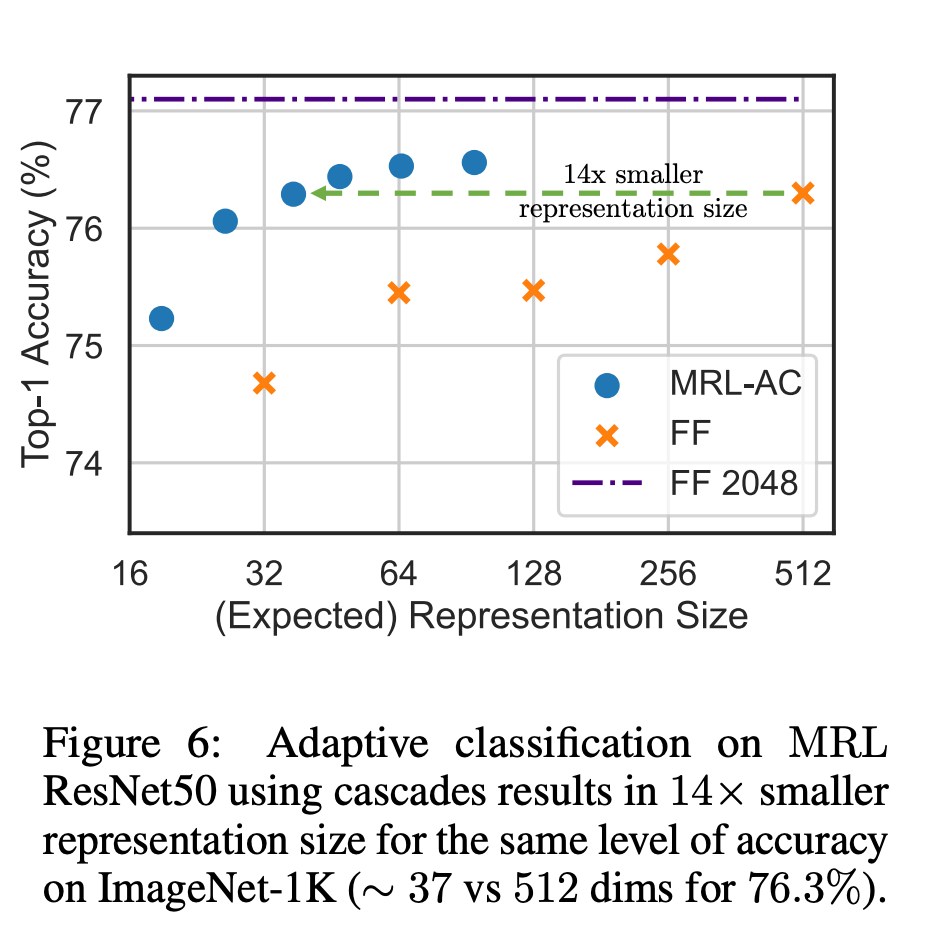
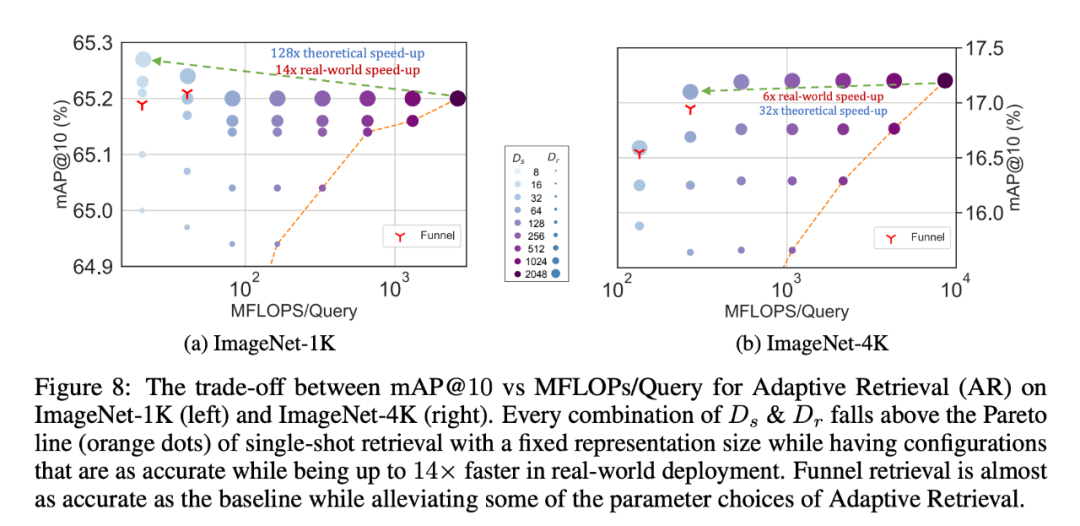
Begitu juga, penyelidik juga telah menggunakan MRL dalam sistem capaian adaptif. Memandangkan pertanyaan, beberapa dimensi pertama pembenaman pertanyaan digunakan untuk menapis calon dapatan semula, dan kemudian berturut-turut lebih banyak dimensi digunakan untuk menyusun semula set dapatan semula. Pelaksanaan mudah pendekatan ini mencapai 128x kelajuan teori dalam FLOPS dan 14x masa jam dinding berbanding dengan sistem perolehan semula tunggal menggunakan vektor benam standard adalah penting untuk ambil perhatian bahawa ketepatan pengambilan semula MRL Setanding dengan ketepatan pengambilan tunggal (; Bahagian 4.3.1).
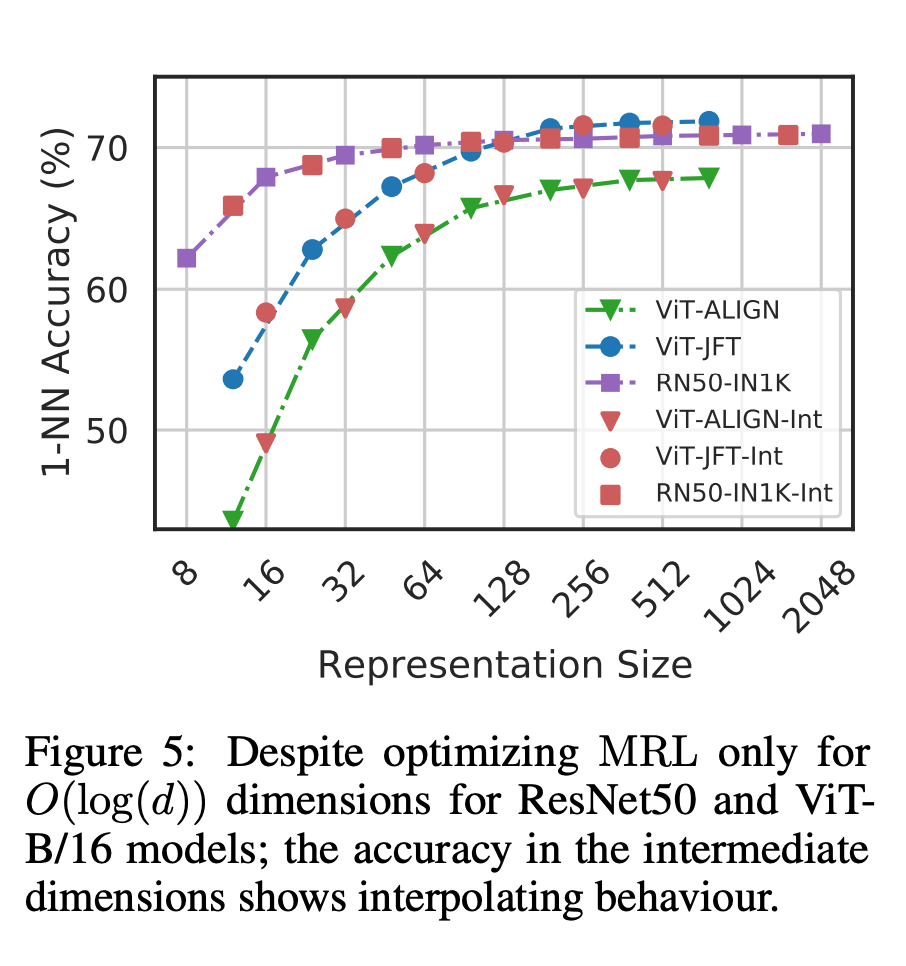
Akhir sekali, memandangkan MRL secara eksplisit mempelajari vektor perwakilan daripada kasar kepada halus, secara intuitif, ia sepatutnya berkongsi lebih banyak maklumat semantik merentas dimensi yang berbeza (Rajah 5). Ini dicerminkan dalam tetapan pembelajaran berterusan ekor panjang, yang boleh meningkatkan ketepatan sehingga 2% sambil teguh seperti benam asal. Di samping itu, disebabkan sifat MRL berbutir kasar hingga halus, ia juga boleh digunakan sebagai kaedah untuk menganalisis kemudahan pengelasan contoh dan kesesakan maklumat.
Untuk butiran penyelidikan lanjut, sila rujuk teks asal kertas itu.
Atas ialah kandungan terperinci Netizen mendedahkan teknologi benam yang digunakan dalam model baharu OpenAI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!