
Rumah >Peranti teknologi >AI >Model besar Yi-VL ialah sumber terbuka dan menduduki tempat pertama dalam MMMU dan CMMMU
Model besar Yi-VL ialah sumber terbuka dan menduduki tempat pertama dalam MMMU dan CMMMU

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-22 21:30:21557semak imbas
https://huggingface.co/01-ai https://www.modelscope.cn/organization/01ai
Dengan keupayaan pemahaman imej dan teks dan penjanaan dialog yang sangat baik, model Yi-VL telah mencapai keputusan utama pada set data Inggeris MMMU dan set data Cina CMMMU, menunjukkan kekuatannya yang kukuh dalam tugas antara disiplin yang kompleks.
MMMU (nama penuh Massive Multi-discipline Multi-modal Understanding & Reasoning) set data mengandungi 11,500 data daripada enam disiplin teras (seni dan reka bentuk, perniagaan, sains, Kesihatan dan perubatan, kemanusiaan dan sains sosial, serta teknologi dan kejuruteraan) masalah yang melibatkan jenis imej yang sangat heterogen dan maklumat teks-imej yang berjalin memerlukan permintaan yang sangat tinggi terhadap persepsi lanjutan dan keupayaan penaakulan. Pada set ujian ini,
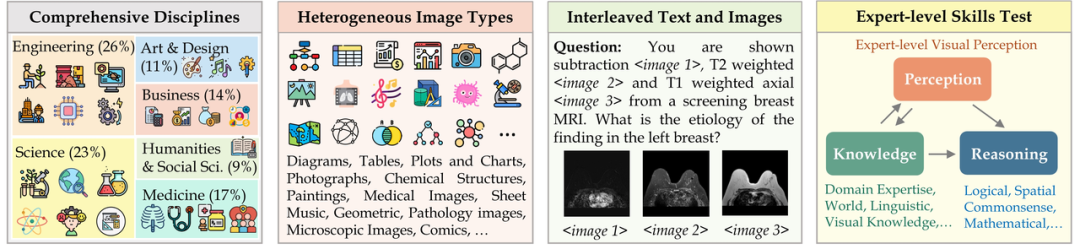
Mari kita lihat dua contoh dahulu: 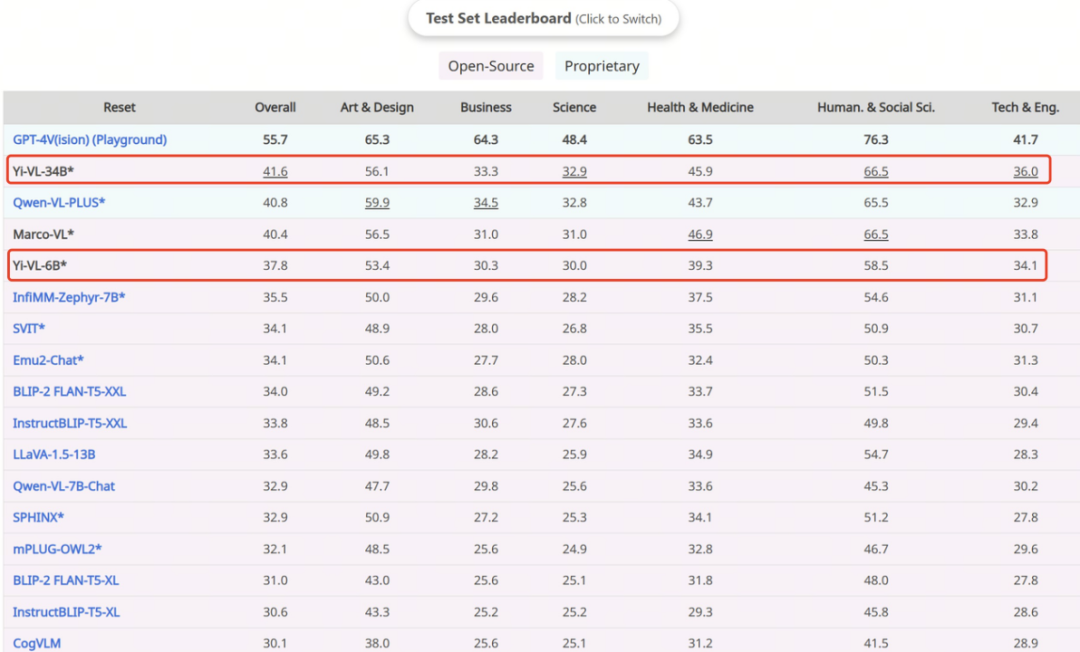
- digunakan untuk Transformer pendek) untuk pengekodan imej, menggunakan Model OpenClip ViT-H/14 sumber terbuka memulakan parameter boleh dilatih dan belajar mengekstrak ciri daripada pasangan "teks imej" berskala besar, memberikan model keupayaan untuk memproses dan memahami imej.
- Modul Unjuran membawa keupayaan untuk menjajarkan ciri imej secara ruang dengan ciri teks kepada model. Modul ini terdiri daripada Multilayer Perceptron (MLP) yang mengandungi normalisasi lapisan. Reka bentuk ini membolehkan model menggabungkan dan memproses maklumat visual dan teks dengan lebih berkesan, meningkatkan ketepatan pemahaman dan penjanaan pelbagai mod.
, proses latihan model Yi-VL dibahagikan kepada tiga peringkat yang direka dengan teliti, bertujuan untuk meningkatkan keupayaan pemprosesan visual dan bahasa model secara menyeluruh.
- Fasa 1: Zero One Wish menggunakan 100 juta set data berganding "teks imej" untuk melatih modul ViT dan Unjuran. Pada peringkat ini, resolusi imej ditetapkan kepada 224x224 untuk meningkatkan keupayaan pemerolehan pengetahuan ViT dalam seni bina tertentu sambil mendayakan penjajaran yang cekap dengan model bahasa yang besar.
- Peringkat kedua: Zero One Thing meningkatkan resolusi imej ViT kepada 448x448 Penambahbaikan ini menjadikan model lebih baik dalam mengenali butiran visual yang kompleks. Peringkat ini menggunakan kira-kira 25 juta pasangan teks imej.
Pasukan teknikal Zero-One Everything juga mengesahkan bahawa ia boleh berdasarkan pemahaman bahasa yang berkuasa dan keupayaan penjanaan model bahasa Yi, dan menggunakan kaedah latihan pelbagai mod lain seperti BLIP, Flamingo, EVA , dsb. untuk cepat melatih model yang boleh melaksanakan model teks grafik Multimodal yang cekap untuk pemahaman imej dan dialog teks grafik yang lancar. Model siri Yi boleh digunakan sebagai model bahasa asas untuk model multimodal, menyediakan pilihan baharu untuk komuniti sumber terbuka.
Atas ialah kandungan terperinci Model besar Yi-VL ialah sumber terbuka dan menduduki tempat pertama dalam MMMU dan CMMMU. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:
Artikel ini dikembalikan pada:jiqizhixin.com. Jika ada pelanggaran, sila hubungi admin@php.cn Padam
Artikel sebelumnya:Cara mengatur projek pembelajaran mesin: Aplikasi Crisp-DMArtikel seterusnya:Cara mengatur projek pembelajaran mesin: Aplikasi Crisp-DM
Artikel berkaitan
Lihat lagi- Perikatan industri 5G RedCap pertama di dunia ditubuhkan untuk mempercepatkan pembangunan teknologi 5G
- Artikel panjang 10,000 perkataan丨Menyahbina rantaian industri keselamatan AI, penyelesaian dan peluang keusahawanan
- Eksekutif Audi: Kekurangan semikonduktor telah menyebabkan industri automotif Jerman memasuki tempoh kesesakan yang akan berterusan selama beberapa tahun
- Bagaimanakah robot kolaboratif boleh memperkasakan pembuatan dan peningkatan pintar industri kimia harian? Dengar apa yang pakar katakan
- Syarikat AI Kai-Fu Lee 'Zero One Thousand Things' sumber terbuka model besar Yi dituduh plagiarisme LLaMA