




Kemas kini berat dalam rangkaian saraf adalah untuk melaraskan berat sambungan antara neuron dalam rangkaian melalui kaedah seperti algoritma perambatan belakang untuk meningkatkan prestasi rangkaian. Artikel ini akan memperkenalkan konsep dan kaedah kemas kini berat untuk membantu pembaca lebih memahami proses latihan rangkaian saraf.
1. Konsep
Berat dalam rangkaian saraf ialah parameter yang menghubungkan neuron yang berbeza dan menentukan kekuatan penghantaran isyarat. Setiap neuron menerima isyarat daripada lapisan sebelumnya, mendarabkannya dengan berat sambungan, menambah istilah bias, dan akhirnya diaktifkan melalui fungsi pengaktifan dan diteruskan ke lapisan seterusnya. Oleh itu, saiz berat secara langsung mempengaruhi kekuatan dan arah isyarat, yang seterusnya mempengaruhi output rangkaian saraf.
Tujuan kemas kini berat badan adalah untuk mengoptimumkan prestasi rangkaian saraf. Semasa proses latihan, rangkaian saraf menyesuaikan diri dengan data latihan dengan melaraskan pemberat antara neuron secara berterusan untuk meningkatkan keupayaan ramalan pada data ujian. Dengan melaraskan pemberat, rangkaian saraf boleh memuatkan data latihan dengan lebih baik, dengan itu meningkatkan ketepatan ramalan. Dengan cara ini, rangkaian saraf boleh meramalkan dengan lebih tepat keputusan data yang tidak diketahui, mencapai prestasi yang lebih baik.
2. Kaedah
Kaedah kemas kini berat yang biasa digunakan dalam rangkaian saraf termasuk keturunan kecerunan, keturunan kecerunan stokastik dan keturunan kecerunan kelompok.
Kaedah turun kecerunan
Kaedah turun kecerunan ialah salah satu kaedah kemas kini berat yang paling asas adalah untuk mengemas kini berat dengan mengira kecerunan fungsi kehilangan kepada berat (iaitu terbitan bagi. fungsi kehilangan kepada berat), supaya meminimumkan fungsi kehilangan. Secara khusus, langkah-langkah kaedah penurunan kecerunan adalah seperti berikut:
Pertama, kita perlu mentakrifkan fungsi kehilangan untuk mengukur prestasi rangkaian saraf pada data latihan. Biasanya, kami akan memilih ralat min kuasa dua (MSE) sebagai fungsi kehilangan, yang ditakrifkan seperti berikut:
MSE=frac{1}{n}sum_{i=1}^{n}(y_i-hat {y_i })^2
di mana, y_i mewakili nilai sebenar sampel ke-i, hat{y_i} mewakili nilai ramalan sampel ke-i oleh rangkaian saraf, dan n mewakili jumlah bilangan sampel.
Kemudian, kita perlu mengira derivatif fungsi kehilangan berkenaan dengan berat, iaitu kecerunan. Khususnya, bagi setiap berat w_{ij} dalam rangkaian saraf, kecerunannya boleh dikira dengan formula berikut:
frac{partial MSE}{partial w_{ij}}=frac{2}{n}sum_ { k=1}^{n}(y_k-hat{y_k})cdot f'(sum_{j=1}^{m}w_{ij}x_{kj})cdot x_{ki}
di mana , n mewakili jumlah bilangan sampel, m mewakili saiz lapisan input rangkaian saraf, x_{kj} mewakili ciri input ke-j bagi sampel ke-k, f(cdot) mewakili fungsi pengaktifan, dan f'( cdot) mewakili terbitan fungsi pengaktifan. . Kadar, mengawal saiz langkah kemas kini berat.
Kaedah turunan kecerunan stokastik
Kaedah turunan kecerunan stokastik ialah varian kaedah keturunan kecerunan. Idea asasnya ialah memilih sampel secara rawak setiap kali untuk mengira kecerunan dan mengemas kini pemberat. Berbanding dengan kaedah keturunan kecerunan, kaedah keturunan kecerunan stokastik boleh menumpu lebih cepat dan lebih cekap apabila memproses set data berskala besar. Secara khusus, langkah-langkah kaedah penurunan kecerunan stokastik adalah seperti berikut:
Pertama, kita perlu mengocok data latihan dan memilih sampel x_k secara rawak untuk mengira kecerunan. Kemudian, kita boleh mengira derivatif fungsi kehilangan berkenaan dengan berat dengan formula berikut:
frac{partial MSE}{partial w_{ij}}=2(y_k-hat{y_k})cdot f' (jumlah_{j= 1}^{m}w_{ij}x_{kj})cdot x_{ki}
di mana, y_k mewakili nilai sebenar sampel ke-k, dan hat{y_k} mewakili ramalan sampel k-th dengan nilai rangkaian saraf. . Kadar, mengawal saiz langkah kemas kini berat.
Kaedah keturunan kecerunan kelompok
Kaedah keturunan kecerunan kelompok ialah satu lagi varian kaedah keturunan kecerunan Idea asasnya ialah menggunakan sekumpulan kecil sampel setiap kali untuk mengira kecerunan dan mengemas kini pemberat. Berbanding dengan kaedah keturunan kecerunan dan kaedah keturunan kecerunan stokastik, kaedah keturunan kecerunan kelompok boleh menumpu dengan lebih stabil dan lebih cekap apabila memproses set data berskala kecil. Secara khusus, langkah-langkah kaedah penurunan kecerunan kelompok adalah seperti berikut:
Pertama, kita perlu membahagikan data latihan kepada beberapa kelompok mini yang sama saiz, setiap kelompok mini mengandungi sampel b. Kami kemudiannya boleh mengira kecerunan purata fungsi kehilangan terhadap pemberat pada setiap kelompok mini, iaitu:
frac{1}{b}sum_{k=1}^{b}frac{partial MSE}{ separa w_ {ij}}
di mana, b mewakili saiz kumpulan mini. Akhir sekali, kita boleh mengemas kini pemberat melalui formula berikut:
w_{ij}=w_{ij}-alphacdotfrac{1}{b}sum_{k=1}^{b}frac{partial MSE}{partial w_ {ij}}
Antaranya, alpha mewakili kadar pembelajaran, yang mengawal saiz langkah kemas kini berat.
Atas ialah kandungan terperinci Teori dan teknik kemas kini berat dalam rangkaian saraf. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 解析二元神经网络的功能和原理Jan 22, 2024 pm 03:00 PM
解析二元神经网络的功能和原理Jan 22, 2024 pm 03:00 PM二元神经网络(BinaryNeuralNetworks,BNN)是一种神经网络,其神经元仅具有两个状态,即0或1。相对于传统的浮点数神经网络,BNN具有许多优点。首先,BNN可以利用二进制算术和逻辑运算,加快训练和推理速度。其次,BNN减少了内存和计算资源的需求,因为二进制数相对于浮点数来说需要更少的位数来表示。此外,BNN还具有提高模型的安全性和隐私性的潜力。由于BNN的权重和激活值仅为0或1,其模型参数更难以被攻击者分析和逆向工程。因此,BNN在一些对数据隐私和模型安全性有较高要求的应用中具
 探究RNN、LSTM和GRU的概念、区别和优劣Jan 22, 2024 pm 07:51 PM
探究RNN、LSTM和GRU的概念、区别和优劣Jan 22, 2024 pm 07:51 PM在时间序列数据中,观察之间存在依赖关系,因此它们不是相互独立的。然而,传统的神经网络将每个观察看作是独立的,这限制了模型对时间序列数据的建模能力。为了解决这个问题,循环神经网络(RNN)被引入,它引入了记忆的概念,通过在网络中建立数据点之间的依赖关系来捕捉时间序列数据的动态特性。通过循环连接,RNN可以将之前的信息传递到当前观察中,从而更好地预测未来的值。这使得RNN成为处理时间序列数据任务的强大工具。但是RNN是如何实现这种记忆的呢?RNN通过神经网络中的反馈回路实现记忆,这是RNN与传统神经
 计算神经网络的浮点操作数(FLOPS)Jan 22, 2024 pm 07:21 PM
计算神经网络的浮点操作数(FLOPS)Jan 22, 2024 pm 07:21 PMFLOPS是计算机性能评估的标准之一,用来衡量每秒的浮点运算次数。在神经网络中,FLOPS常用于评估模型的计算复杂度和计算资源的利用率。它是一个重要的指标,用来衡量计算机的计算能力和效率。神经网络是一种复杂的模型,由多层神经元组成,用于进行数据分类、回归和聚类等任务。训练和推断神经网络需要进行大量的矩阵乘法、卷积等计算操作,因此计算复杂度非常高。FLOPS(FloatingPointOperationsperSecond)可以用来衡量神经网络的计算复杂度,从而评估模型的计算资源使用效率。FLOP
 模糊神经网络的定义和结构解析Jan 22, 2024 pm 09:09 PM
模糊神经网络的定义和结构解析Jan 22, 2024 pm 09:09 PM模糊神经网络是一种将模糊逻辑和神经网络结合的混合模型,用于解决传统神经网络难以处理的模糊或不确定性问题。它的设计受到人类认知中模糊性和不确定性的启发,因此被广泛应用于控制系统、模式识别、数据挖掘等领域。模糊神经网络的基本架构由模糊子系统和神经子系统组成。模糊子系统利用模糊逻辑对输入数据进行处理,将其转化为模糊集合,以表达输入数据的模糊性和不确定性。神经子系统则利用神经网络对模糊集合进行处理,用于分类、回归或聚类等任务。模糊子系统和神经子系统之间的相互作用使得模糊神经网络具备更强大的处理能力,能够
 改进的RMSprop算法Jan 22, 2024 pm 05:18 PM
改进的RMSprop算法Jan 22, 2024 pm 05:18 PMRMSprop是一种广泛使用的优化器,用于更新神经网络的权重。它是由GeoffreyHinton等人在2012年提出的,并且是Adam优化器的前身。RMSprop优化器的出现主要是为了解决SGD梯度下降算法中遇到的一些问题,例如梯度消失和梯度爆炸。通过使用RMSprop优化器,可以有效地调整学习速率,并且自适应地更新权重,从而提高深度学习模型的训练效果。RMSprop优化器的核心思想是对梯度进行加权平均,以使不同时间步的梯度对权重的更新产生不同的影响。具体而言,RMSprop会计算每个参数的平方
 浅层特征与深层特征的结合在实际应用中的示例Jan 22, 2024 pm 05:00 PM
浅层特征与深层特征的结合在实际应用中的示例Jan 22, 2024 pm 05:00 PM深度学习在计算机视觉领域取得了巨大成功,其中一项重要进展是使用深度卷积神经网络(CNN)进行图像分类。然而,深度CNN通常需要大量标记数据和计算资源。为了减少计算资源和标记数据的需求,研究人员开始研究如何融合浅层特征和深层特征以提高图像分类性能。这种融合方法可以利用浅层特征的高计算效率和深层特征的强表示能力。通过将两者结合,可以在保持较高分类准确性的同时降低计算成本和数据标记的要求。这种方法对于那些数据量较小或计算资源有限的应用场景尤为重要。通过深入研究浅层特征和深层特征的融合方法,我们可以进一
 蒸馏模型的基本概念Jan 22, 2024 pm 02:51 PM
蒸馏模型的基本概念Jan 22, 2024 pm 02:51 PM模型蒸馏是一种将大型复杂的神经网络模型(教师模型)的知识转移到小型简单的神经网络模型(学生模型)中的方法。通过这种方式,学生模型能够从教师模型中获得知识,并且在表现和泛化性能方面得到提升。通常情况下,大型神经网络模型(教师模型)在训练时需要消耗大量计算资源和时间。相比之下,小型神经网络模型(学生模型)具备更高的运行速度和更低的计算成本。为了提高学生模型的性能,同时保持较小的模型大小和计算成本,可以使用模型蒸馏技术将教师模型的知识转移给学生模型。这种转移过程可以通过将教师模型的输出概率分布作为学生
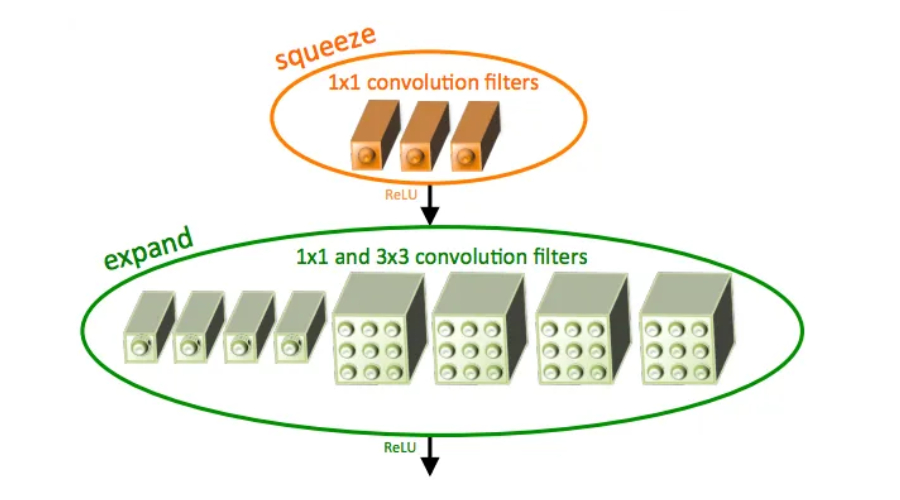 SqueezeNet简介及其特点Jan 22, 2024 pm 07:15 PM
SqueezeNet简介及其特点Jan 22, 2024 pm 07:15 PMSqueezeNet是一种小巧而精确的算法,它在高精度和低复杂度之间达到了很好的平衡,因此非常适合资源有限的移动和嵌入式系统。2016年,DeepScale、加州大学伯克利分校和斯坦福大学的研究人员提出了一种紧凑高效的卷积神经网络(CNN)——SqueezeNet。近年来,研究人员对SqueezeNet进行了多次改进,其中包括SqueezeNetv1.1和SqueezeNetv2.0。这两个版本的改进不仅提高了准确性,还降低了计算成本。SqueezeNetv1.1在ImageNet数据集上的精度


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

