
Rumah >Peranti teknologi >AI >Penilaian LeCun: Penilaian meta ConvNet dan Transformer, yang manakah lebih kuat?
Penilaian LeCun: Penilaian meta ConvNet dan Transformer, yang manakah lebih kuat?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-18 14:15:05778semak imbas
Bagaimana untuk memilih model visual berdasarkan keperluan khusus?
Bagaimanakah model ConvNet/ViT dan diselia/CLIP membandingkan antara satu sama lain pada penunjuk selain ImageNet?
Penyelidikan terkini yang diterbitkan oleh penyelidik dari MABZUAI dan Meta secara komprehensif membandingkan model visual biasa pada penunjuk "tidak standard".

Alamat kertas: https://arxiv.org/pdf/2311.09215.pdf
LeCun sangat memuji penyelidikan ini dan menggelarnya sebagai penyelidikan yang sangat baik. Kajian ini membandingkan seni bina ConvNext dan VIT yang bersaiz sama, memberikan perbandingan komprehensif pelbagai sifat apabila dilatih dalam mod diselia dan menggunakan kaedah CLIP.

Melebihi ketepatan ImageNet
Lanskap model penglihatan komputer menjadi semakin pelbagai dan kompleks.
Dari ConvNets awal hingga evolusi Vision Transformers, jenis model yang tersedia sentiasa berkembang.
Begitu juga, paradigma latihan telah berkembang daripada latihan diselia pada ImageNet kepada pembelajaran penyeliaan sendiri dan latihan pasangan teks imej seperti CLIP.

Semasa menandakan kemajuan, ledakan pilihan ini menimbulkan cabaran utama kepada pengamal: Bagaimanakah anda memilih model sasaran yang sesuai untuk anda?
Ketepatan ImageNet sentiasa menjadi penunjuk utama untuk menilai prestasi model. Sejak mencetuskan revolusi pembelajaran mendalam, ia telah memacu kemajuan yang ketara dalam bidang kecerdasan buatan.
Walau bagaimanapun, ia tidak dapat mengukur nuansa model yang terhasil daripada seni bina, paradigma latihan dan data yang berbeza.
Jika dinilai semata-mata oleh ketepatan ImageNet, model dengan sifat yang berbeza mungkin kelihatan serupa (Rajah 1). Had ini menjadi lebih jelas apabila model mula mengatasi ciri ImageNet dan mencapai ketepuan dalam ketepatan.
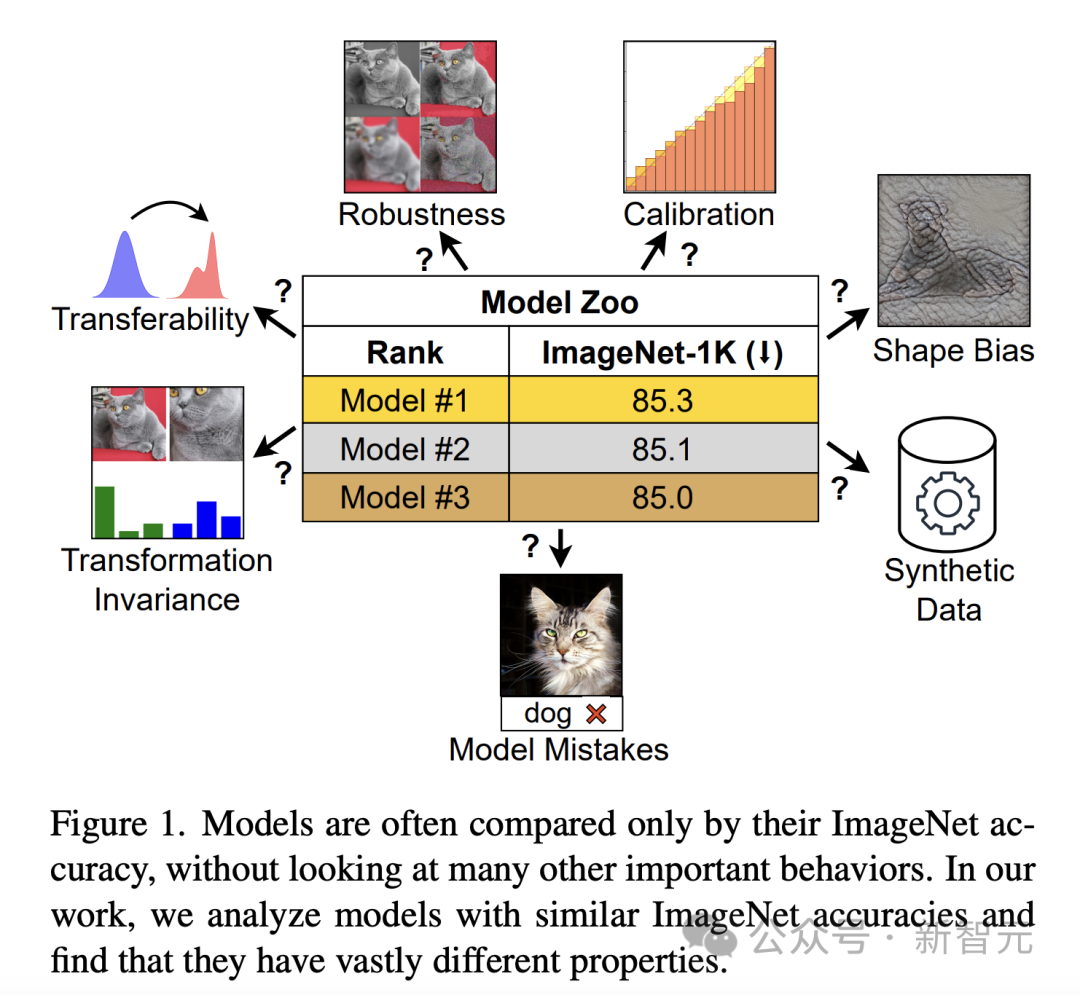
Untuk merapatkan jurang, penyelidik menjalankan penerokaan mendalam tentang tingkah laku model di luar ketepatan ImageNet.
Untuk mengkaji kesan seni bina dan objektif latihan terhadap prestasi model, Vision Transformer (ViT) dan ConvNeXt telah dibandingkan secara khusus. Ketepatan pengesahan ImageNet-1K dan keperluan pengiraan kedua-dua seni bina moden ini adalah setanding.
Selain itu, kajian membandingkan model diselia yang diwakili oleh DeiT3-Base/16 dan ConvNeXt-Base, serta pengekod visual OpenCLIP berdasarkan model CLIP.

Analisis Keputusan
Analisis penyelidik direka untuk mengkaji tingkah laku model yang boleh dinilai tanpa latihan lanjut atau penalaan halus.
Pendekatan ini amat penting untuk pengamal yang mempunyai sumber pengkomputeran terhad, kerana mereka sering bergantung pada model pra-latihan.
Dalam analisis khusus, walaupun pengarang mengiktiraf nilai tugas hiliran seperti pengesanan objek, tumpuannya adalah pada ciri yang memberikan cerapan dengan keperluan pengiraan yang minimum dan mencerminkan gelagat yang penting untuk aplikasi dunia sebenar. .
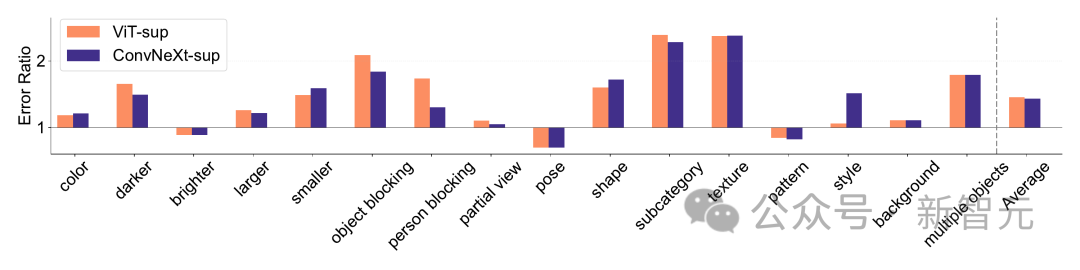
Ia menggunakan kadar ralat (lebih rendah adalah lebih baik) untuk mengukur prestasi model pada faktor tertentu berbanding dengan ketepatan keseluruhan, membolehkan analisis ralat model bernuansa. Hasil pada ImageNet-X menunjukkan:
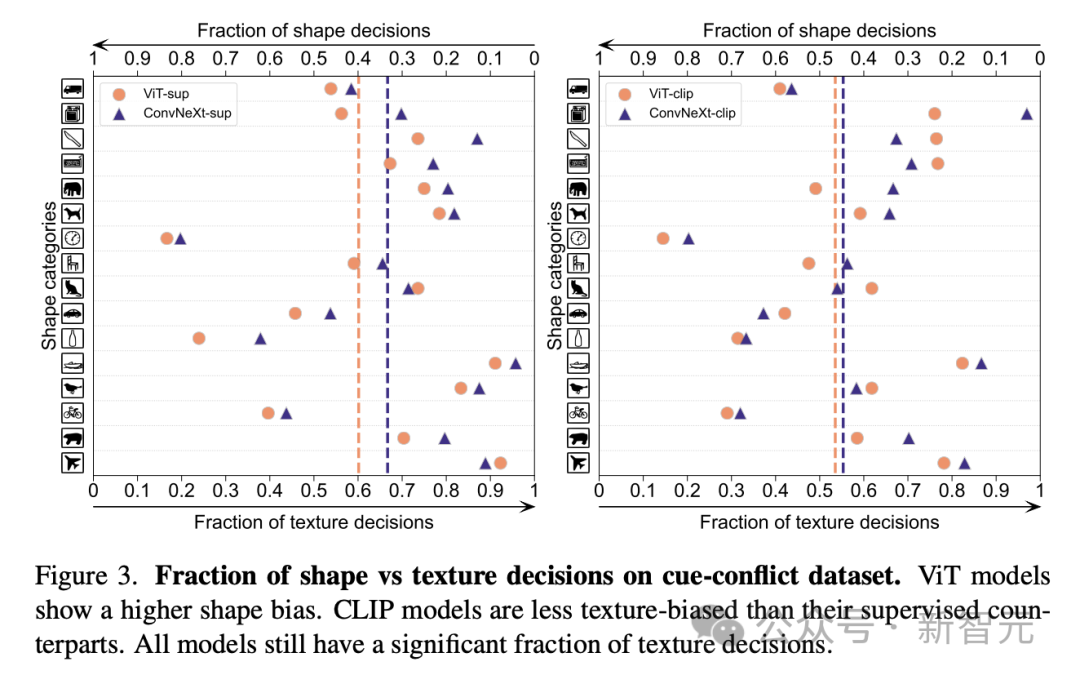
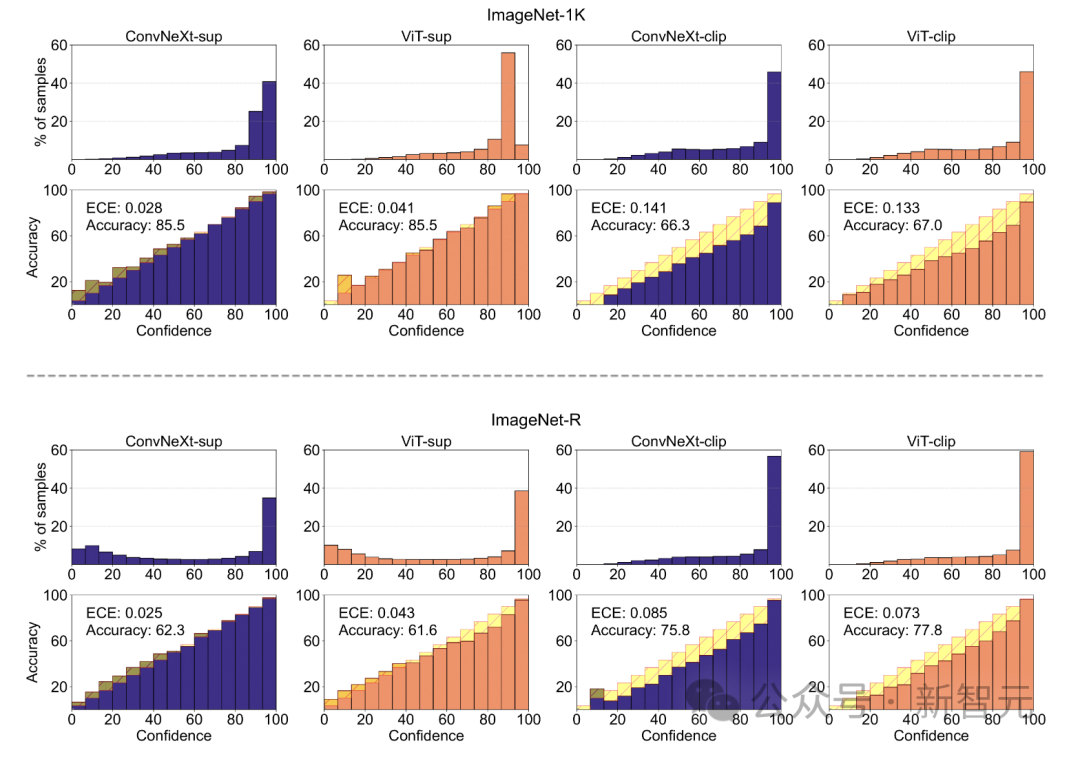
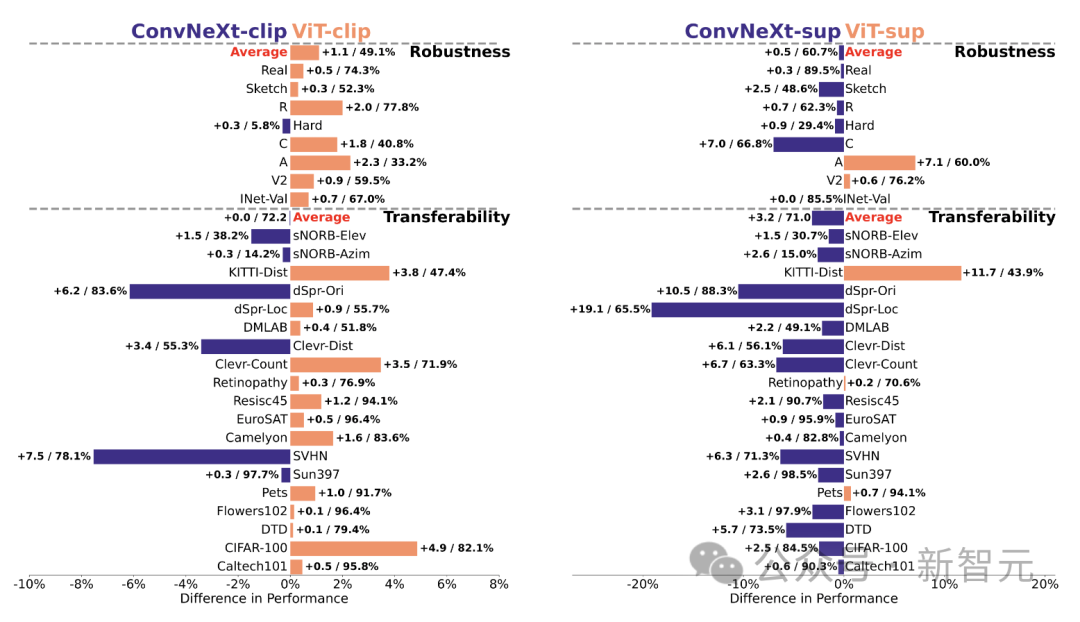
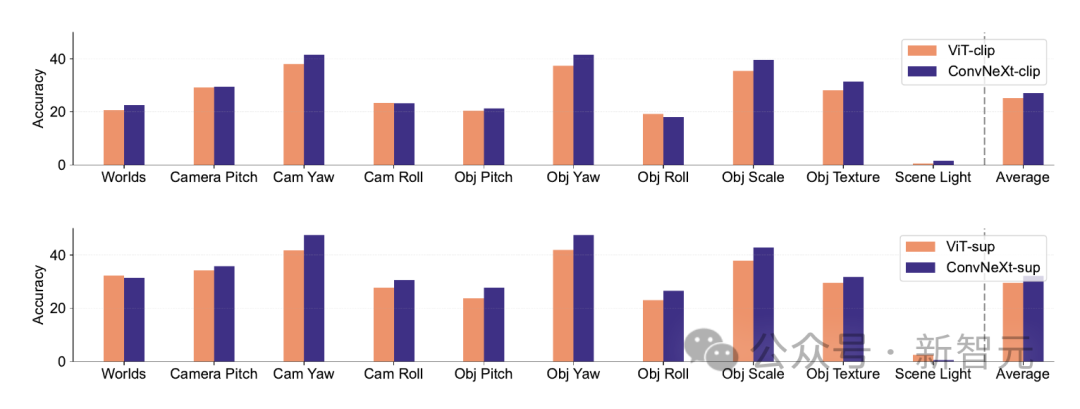
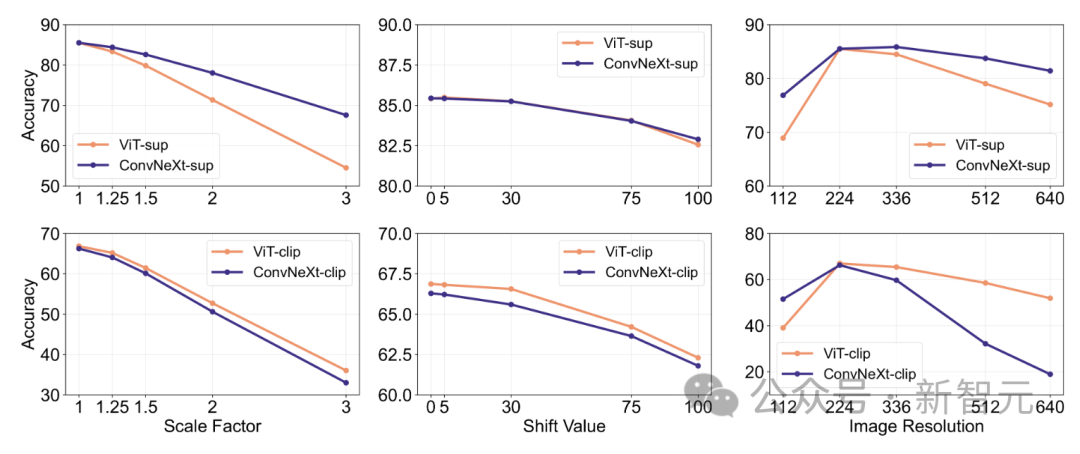
1 Berbanding dengan ketepatan ImageNetnya, model CLIP membuat ralat yang lebih sedikit daripada model yang diselia.2. Semua model dipengaruhi terutamanya oleh faktor kompleks seperti oklusi. 3. Tekstur adalah faktor yang paling mencabar bagi semua model. Shape/Tekstur Bias Shape/Tekstur Bias menyemak sama ada model bergantung pada pintasan bentuk tekstur lanjutan. Bias ini boleh dikaji dengan menggabungkan imej bercanggah kiu bagi kategori bentuk dan tekstur yang berbeza. Pendekatan ini membantu memahami sejauh mana keputusan model berdasarkan bentuk berbanding tekstur. Para penyelidik menilai bias bentuk-tekstur pada set data konflik kiu dan mendapati bahawa bias tekstur model CLIP adalah lebih kecil daripada model diselia, manakala bias bentuk model ViT lebih tinggi daripada ConvNets. . Penentukuran model Penentukuran mengukur sama ada keyakinan ramalan model konsisten dengan ketepatan sebenar. Ini boleh dinilai melalui metrik seperti ralat penentukuran jangkaan (ECE), serta alat visualisasi seperti plot kebolehpercayaan dan histogram keyakinan. Para penyelidik menilai penentukuran pada ImageNet-1K dan ImageNet-R, mengklasifikasikan ramalan kepada 15 tahap. Dalam eksperimen, perkara berikut diperhatikan: - Model CLIP mempunyai keyakinan yang tinggi, manakala model yang diselia sedikit tidak mencukupi. - ConvNeXt yang diselia lebih baik ditentukur daripada ViT yang diselia. Keteguhan dan mudah alih Keteguhan dan mudah alih model adalah kunci untuk menyesuaikan diri dengan perubahan dalam pengedaran data dan tugasan baharu. Para penyelidik menilai kekukuhan menggunakan varian ImageNet yang berbeza dan mendapati bahawa walaupun model ViT dan ConvNeXt mempunyai prestasi purata yang sama, kecuali untuk ImageNet-R dan ImageNet-Sketch, model yang diselia secara umumnya mengatasi prestasi dari segi CLIP. Dari segi kemudahalihan, dinilai pada 19 set data menggunakan penanda aras VTAB, ConvNeXt yang diselia mengatasi prestasi ViT dan hampir setanding dengan prestasi model CLIP. Data sintetik Data data sintetik seperti PUG-ImageNet, yang boleh mengawal dengan tepat faktor seperti sudut kamera dan tekstur, telah menjadi saluran analisis data penyelidik prestasi yang menjanjikan model. PUG-ImageNet mengandungi imej ImageNet fotorealistik dengan variasi sistematik dalam pencahayaan dan faktor lain, dengan prestasi diukur sebagai ketepatan tertinggi mutlak. Para penyelidik memberikan keputusan untuk faktor yang berbeza dalam PUG-ImageNet dan mendapati bahawa ConvNeXt mengatasi ViT dalam hampir semua faktor. Ini menunjukkan bahawa ConvNeXt mengatasi ViT pada data sintetik, manakala jurang model CLIP lebih kecil, kerana ketepatan model CLIP lebih rendah daripada model diselia, yang mungkin berkaitan dengan ketepatan ImageNet asal yang lebih rendah . Invarian Ciri Invarian ciri merujuk kepada keupayaan model untuk menghasilkan perwakilan yang konsisten yang tidak dipengaruhi oleh transformasi input, dengan itu mengekalkan semantik atau pergerakan. Ciri ini membolehkan model membuat generalisasi dengan baik merentas input yang berbeza tetapi serupa dari segi semantik. Pendekatan penyelidik termasuk mengubah saiz imej untuk invarian skala, mengalihkan tanaman untuk invarian kedudukan dan melaraskan peleraian model ViT menggunakan benam kedudukan terinterpolasi. ConvNeXt mengatasi prestasi ViT dalam latihan yang diselia. Secara keseluruhan, model ini lebih teguh untuk transformasi skala/resolusi daripada pergerakan. Untuk aplikasi yang memerlukan keteguhan tinggi untuk penskalaan, anjakan dan peleraian, keputusan menunjukkan bahawa ConvNeXt yang diselia mungkin merupakan pilihan terbaik. Penyelidik mendapati setiap model mempunyai kelebihan tersendiri. Ini menunjukkan bahawa pilihan model harus bergantung pada kes penggunaan sasaran, kerana metrik prestasi standard mungkin mengabaikan nuansa kritikal misi. Tambahan pula, banyak penanda aras sedia ada diperoleh daripada ImageNet, yang berat sebelah penilaian. Membangunkan penanda aras baharu dengan pengagihan data yang berbeza adalah penting untuk menilai model dalam konteks yang lebih realistik mewakili. ConvNet vs Transformer - Dalam banyak penanda aras, ConvNeXt yang diselia mempunyai prestasi yang lebih baik daripada VIT yang diselia: ia ditentukur lebih baik, invarian kepada transformasi data, menunjukkan prestasi yang lebih baik Kebolehpindahan kebaikan. - ConvNeXt mengatasi ViT pada data sintetik. - ViT mempunyai bias bentuk yang lebih tinggi. Selia lwn CLIP - Walaupun model CLIP lebih baik dari segi kebolehpindahan, ConvNeXt yang diselia menunjukkan prestasi kompetitif dalam tugasan ini. Ini menunjukkan potensi model yang diselia. - Model yang diselia lebih baik dalam penanda aras keteguhan, mungkin kerana model ini adalah varian ImageNet. - Model CLIP mempunyai bias bentuk yang lebih tinggi dan ralat pengelasan yang lebih sedikit berbanding dengan ketepatan ImageNetnya. 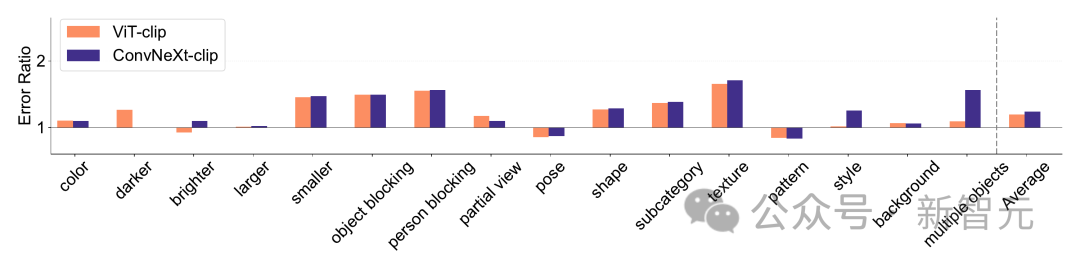
Atas ialah kandungan terperinci Penilaian LeCun: Penilaian meta ConvNet dan Transformer, yang manakah lebih kuat?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!