
Rumah >Peranti teknologi >AI >Kumpulan Ant mengeluarkan algoritma baharu yang boleh mempercepatkan inferens model besar sebanyak 2-6 kali
Kumpulan Ant mengeluarkan algoritma baharu yang boleh mempercepatkan inferens model besar sebanyak 2-6 kali

- 王林ke hadapan
- 2024-01-17 21:33:05945semak imbas
Baru-baru ini, Ant Group telah membuka satu set algoritma baharu yang boleh membantu model besar mempercepatkan inferens sebanyak 2 hingga 6 kali ganda, menarik perhatian dalam industri.
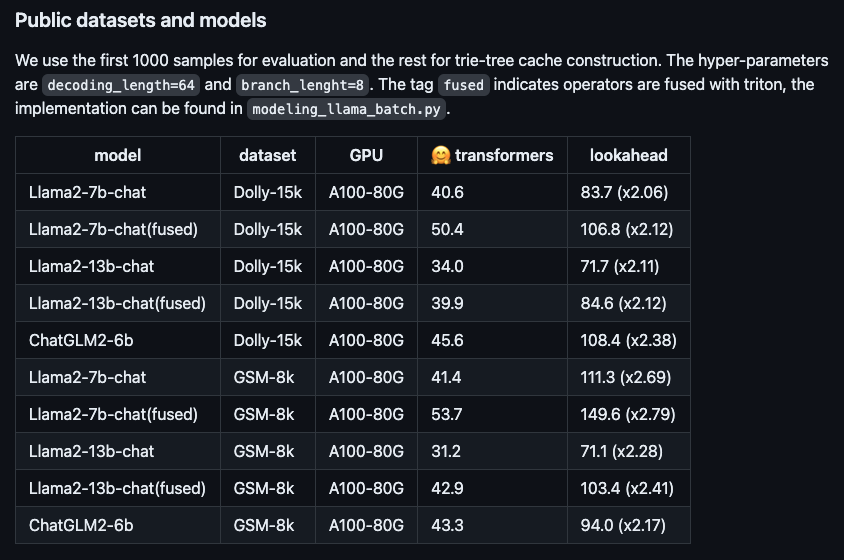
Gambar: Prestasi mempercepatkan algoritma baharu pada model besar sumber terbuka yang berbeza. .
Mengambil model sembang Llama2-7B dan set data Dolly sebagai contoh, kami menjalankan pengukuran sebenar dan mendapati kelajuan penjanaan token meningkat daripada 48.2/saat kepada 112.9/saat, peningkatan kelajuan sebanyak 2.34 kali. Pada set data dalaman RAG (Retrieval Enhanced Generation) Ant, nisbah pecutan versi 10B model besar Bailing AntGLM mencapai 5.36. Pada masa yang sama, peningkatan dalam ingatan video dan penggunaan memori hampir boleh diabaikan.Model berskala besar semasa biasanya berdasarkan penyahkodan autoregresif dan hanya menjana satu token pada satu masa. Kaedah ini bukan sahaja membazirkan kuasa pemprosesan selari GPU, tetapi juga mengakibatkan kelewatan pengalaman pengguna yang berlebihan, menjejaskan kelancaran. Untuk memperbaiki masalah ini, anda boleh cuba menggunakan penyahkodan selari untuk menjana berbilang token pada masa yang sama untuk meningkatkan kecekapan dan pengalaman pengguna.
Sebagai contoh, proses penjanaan token asal boleh dibandingkan dengan kaedah input awal bahasa Cina Pengguna perlu mengetik papan kekunci perkataan demi perkataan untuk memasukkan teks. Walau bagaimanapun, selepas menggunakan algoritma pecutan Ant, proses penjanaan token adalah seperti kaedah input Lenovo moden, dan keseluruhan ayat boleh terus muncul melalui fungsi Lenovo. Penambahbaikan sedemikian sangat meningkatkan kelajuan dan kecekapan input.
Beberapa algoritma pengoptimuman telah muncul dalam industri sebelum ini, terutamanya memfokuskan pada kaedah menjana draf kualiti yang lebih baik (iaitu meneka dan menjana jujukan token). Walau bagaimanapun, ia telah dibuktikan dalam amalan bahawa apabila panjang draf melebihi 30 token, kecekapan penaakulan hujung ke hujung tidak dapat dipertingkatkan lagi. Jelas sekali, panjang ini tidak menggunakan sepenuhnya kuasa pengkomputeran GPU.Untuk meningkatkan lagi prestasi perkakasan, algoritma pecutan inferens Ant Lookahead menggunakan strategi berbilang cawangan. Ini bermakna jujukan draf tidak lagi mempunyai satu cabang sahaja, tetapi mengandungi berbilang cabang selari yang boleh disahkan serentak. Dengan cara ini, bilangan token yang dijana oleh proses ke hadapan boleh ditingkatkan sambil mengekalkan penggunaan masa proses ke hadapan pada dasarnya tidak berubah.
Algoritma pecutan inferens Ant Lookahead meningkatkan lagi kecekapan pengkomputeran dengan menggunakan pepohon cuba untuk menyimpan dan mendapatkan jujukan token, dan menggabungkan nod induk yang sama dalam berbilang draf. Untuk meningkatkan kemudahan penggunaan, pembinaan pokok trie bagi algoritma ini tidak bergantung pada model draf tambahan, tetapi hanya menggunakan gesaan dan jawapan yang dijana semasa proses penaakulan untuk pembinaan dinamik, dengan itu mengurangkan kos akses pengguna. Algoritma kini adalah sumber terbuka di GitHub (https://www.php.cn/link/51200d29d1fc15f5a71c1dab4bb54f7c
), dan kertas berkaitan diterbitkan dalam ARXIV (https://www.php84c2a/97a/97a 1 3b3d
) .Atas ialah kandungan terperinci Kumpulan Ant mengeluarkan algoritma baharu yang boleh mempercepatkan inferens model besar sebanyak 2-6 kali. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 世界vr产业大会地址在哪
- Kepintaran buatan menyuntik momentum baharu ke dalam industri farmaseutikal negara saya
- Skala industri pengkomputeran negara saya mencecah 2.6 trilion yuan, dengan lebih daripada 20.91 juta pelayan tujuan am dan 820,000 pelayan AI dihantar dalam tempoh enam tahun yang lalu.
- Ahli CPPCC Daerah Xuhui menganjurkan aktiviti pemeriksaan intensif dan memberi perhatian kepada pembangunan industri kecerdasan buatan
- Kumpulan 360 memenangi anugerah 'Industri Perisikan Data China AI Large Model Pioneer Enterprise' berdasarkan 360 Intelligent Brain