
Rumah >Peranti teknologi >AI >Potensi VLM sumber terbuka dilepaskan oleh rangka kerja RoboFlamingo
Potensi VLM sumber terbuka dilepaskan oleh rangka kerja RoboFlamingo

- PHPzke hadapan
- 2024-01-17 14:12:24766semak imbas
Dalam beberapa tahun kebelakangan ini, penyelidikan ke atas model besar telah dipercepatkan, dan ia secara beransur-ansur menunjukkan pemahaman pelbagai mod dan keupayaan penaakulan temporal dan ruang dalam pelbagai tugas. Pelbagai tugas pengendalian robot secara semula jadi mempunyai keperluan yang tinggi untuk pemahaman arahan bahasa, persepsi pemandangan, dan perancangan spatio-temporal Ini secara semula jadi membawa kepada persoalan: Bolehkah keupayaan model besar digunakan sepenuhnya dan berhijrah ke bidang robotik? secara langsung merancang urutan tindakan asas?
ByteDance Research menggunakan model besar penglihatan bahasa berbilang mod sumber terbuka OpenFlamingo untuk membangunkan model operasi robot RoboFlamingo yang mudah digunakan yang hanya memerlukan latihan mesin tunggal. VLM boleh ditukar menjadi VLM Robotik melalui penalaan halus yang mudah, yang sesuai untuk tugas pengendalian robot interaksi bahasa.
Disahkan oleh OpenFlamingo pada set data operasi robot CALVIN. Keputusan eksperimen menunjukkan bahawa RoboFlamingo hanya menggunakan 1% daripada data dengan anotasi bahasa dan mencapai prestasi SOTA dalam satu siri tugas pengendalian robot. Dengan pembukaan set data RT-X, RoboFlamingo, yang telah dilatih pada data sumber terbuka, dan diperhalusi untuk platform robot yang berbeza, dijangka menjadi proses model robot berskala besar yang mudah dan berkesan. Kertas kerja itu juga menguji prestasi penalaan halus VLM dengan ketua strategi yang berbeza, paradigma latihan yang berbeza dan struktur Flamingo yang berbeza pada tugas robot, dan membuat beberapa kesimpulan yang menarik.

- Laman utama projek: https://roboflamingo.github.io
- Alamat kod: https://github.com/RoboFlamingo
- Alamat kertas: https://arxiv.org/abs/2311.01378
Latar belakang penyelidikan
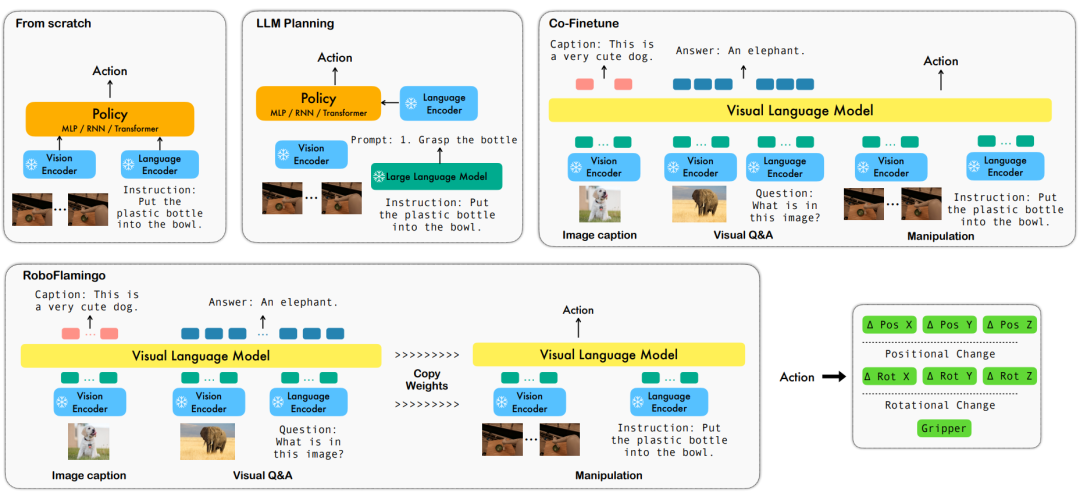
Pengendalian robot berasaskan berbilang bahasa adalah aplikasi penting dalam bidang perisikan berasaskan data yang melibatkan pelbagai maklumat dalam operasi robot berbilang dalam dan pemprosesan, termasuk penglihatan, bahasa dan kawalan. Dalam beberapa tahun kebelakangan ini, model berasaskan bahasa visual (VLM) telah mencapai kemajuan yang ketara dalam bidang seperti penerangan imej, jawapan soalan visual dan penjanaan imej. Walau bagaimanapun, menggunakan model ini pada operasi robot masih menghadapi cabaran, seperti cara mengintegrasikan maklumat visual dan bahasa serta cara mengendalikan urutan temporal operasi robot. Menyelesaikan cabaran ini memerlukan penambahbaikan dalam pelbagai aspek, seperti menambah baik keupayaan perwakilan berbilang mod model, mereka bentuk mekanisme gabungan model yang lebih berkesan dan memperkenalkan struktur model dan algoritma yang menyesuaikan diri dengan sifat berurutan operasi robot. Selain itu, terdapat keperluan untuk membangunkan set data robotik yang lebih kaya untuk melatih dan menilai model ini. Melalui penyelidikan dan inovasi berterusan, operasi robot berasaskan bahasa dijangka memainkan peranan yang lebih besar dalam aplikasi praktikal dan menyediakan perkhidmatan yang lebih pintar dan mudah kepada manusia.
Untuk menyelesaikan masalah ini, pasukan penyelidik robotik ByteDance Research memperhalusi VLM (Model Bahasa Visual) sumber terbuka sedia ada - OpenFlamingo, dan mereka bentuk rangka kerja manipulasi bahasa visual baharu yang dipanggil RoboFlamingo. Ciri rangka kerja ini ialah ia menggunakan VLM untuk mencapai pemahaman bahasa visual satu langkah dan memproses maklumat sejarah melalui modul kepala dasar tambahan. Melalui kaedah penalaan halus yang mudah, RoboFlamingo boleh disesuaikan dengan tugasan operasi robot berasaskan bahasa. Pengenalan rangka kerja ini dijangka dapat menyelesaikan satu siri masalah yang wujud dalam operasi robot semasa.
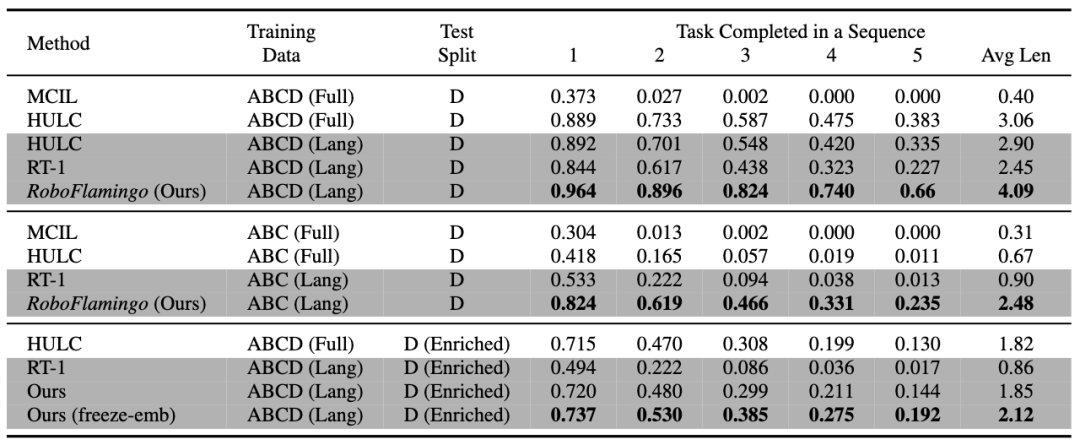
RoboFlamingo telah disahkan pada set data operasi robot berasaskan bahasa CALVIN Keputusan eksperimen menunjukkan bahawa RoboFlamingo hanya menggunakan 1% daripada data beranotasi bahasa dan mencapai prestasi SOTA (lebih daripada 10%) pada satu siri operasi robot. tugasan. Kadar kejayaan jujukan tugasan pembelajaran tugasan ialah 66%, purata bilangan penyiapan tugasan ialah 4.09, kaedah garis dasar ialah 38%, purata bilangan penyiapan tugasan ialah 3.06 kadar kejayaan tugasan sifar ialah 24; %, purata bilangan penyiapan tugas ialah 2.48, garis dasar Kaedahnya ialah 1%, purata bilangan tugasan yang diselesaikan ialah 0.67), dan boleh mencapai tindak balas masa nyata melalui kawalan gelung terbuka, dan boleh digunakan secara fleksibel pada bahagian bawah- platform prestasi. Keputusan ini menunjukkan bahawa RoboFlamingo ialah kaedah manipulasi robot yang berkesan dan boleh memberikan rujukan berguna untuk aplikasi robot pada masa hadapan.
Kaedah
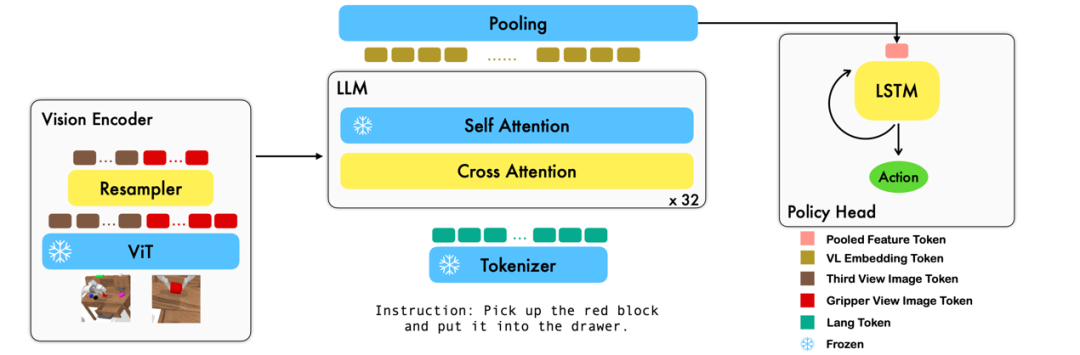
Kerja ini menggunakan model asas bahasa visual sedia ada berdasarkan pasangan teks-imej untuk menjana tindakan relatif setiap langkah robot melalui latihan secara hujung ke hujung. Model ini terdiri daripada tiga modul utama: Pengekod penglihatan, Penyahkod gabungan ciri dan Ketua polisi. Dalam modul pengekod Visi, pemerhatian visual semasa adalah pertama kali dimasukkan ke dalam ViT, dan kemudian keluaran token oleh ViT diturunkan sampel melalui resampler. Langkah ini membantu mengurangkan dimensi input model, dengan itu meningkatkan kecekapan latihan. Modul penyahkod gabungan ciri mengambil token teks sebagai input dan menggunakan output pengekod visual sebagai pertanyaan melalui mekanisme perhatian silang, mencapai gabungan ciri visual dan bahasa. Dalam setiap lapisan, penyahkod gabungan ciri mula-mula melakukan operasi perhatian silang dan kemudian melakukan operasi perhatian kendiri. Operasi ini membantu mengekstrak korelasi antara bahasa dan ciri visual untuk menjana tindakan robot dengan lebih baik. Berdasarkan output jujukan token semasa dan sejarah oleh penyahkod gabungan Ciri, kepala Polisi secara langsung mengeluarkan 7 tindakan relatif DoF semasa, termasuk pose hujung lengan robot 6 malap dan pencengkam 1 malap buka/tutup. Akhir sekali, lakukan pengumpulan maksimum pada penyahkod gabungan ciri dan hantarkannya ke kepala Dasar untuk menjana tindakan relatif. Dengan cara ini, model kami dapat menggabungkan maklumat visual dan linguistik secara berkesan bersama-sama untuk menjana pergerakan robot yang tepat. Ini mempunyai prospek aplikasi yang luas dalam bidang seperti kawalan robot dan navigasi autonomi.
Semasa proses latihan, RoboFlamingo menggunakan parameter ViT, LLM dan Cross Attention yang telah dilatih dan hanya memperhalusi parameter resampler, cross attention dan kepala polisi. . Berbanding dengan set data tugas visual-linguistik sedia ada, tugas CALVIN adalah lebih kompleks dari segi panjang jujukan, ruang tindakan dan bahasa serta menyokong spesifikasi fleksibel input sensor. CALVIN dibahagikan kepada empat pembahagian ABCD, setiap pemisahan sepadan dengan konteks dan reka letak yang berbeza.
Analisis kuantitatif:
RoboFlamingo mempunyai prestasi terbaik dalam semua tetapan dan penunjuk, yang menunjukkan bahawa ia mempunyai keupayaan meniru yang kuat, keupayaan generalisasi visual dan keupayaan generalisasi bahasa. Penuh dan Lang menunjukkan sama ada model telah dilatih menggunakan data visual yang tidak berpasangan (iaitu data visual tanpa gandingan bahasa); . Antaranya, MLP tanpa sejarah secara langsung meramalkan sejarah berdasarkan pemerhatian semasa, dan prestasinya adalah yang paling teruk dengan pemerhatian sejarah di hujung pengekod penglihatan dan meramalkan tindakan, dan prestasinya dipertingkatkan dengan jelas di ketua polisi , secara tersirat mengekalkan maklumat sejarah, dan prestasinya adalah yang terbaik, yang menggambarkan keberkesanan gabungan maklumat sejarah melalui ketua polisi. 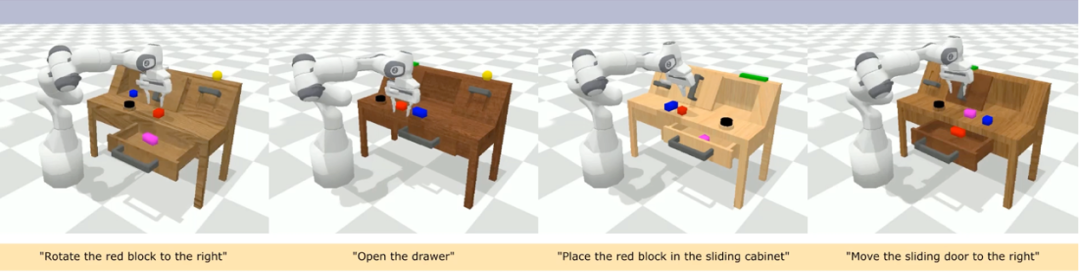
Impak pra-latihan bahasa visual:
Pra-latihan memainkan peranan penting dalam meningkatkan prestasi RoboFlamingo. Eksperimen menunjukkan bahawa RoboFlamingo berprestasi lebih baik pada tugas robotik dengan pra-latihan pada set data visual-linguistik yang besar. .
 Impak penalaan halus arahan:
Impak penalaan halus arahan:
Penalaan halus arahan ialah teknik yang berkuasa, dan keputusan percubaan menunjukkan bahawa ia boleh meningkatkan lagi prestasi model.
Hasil kualitatif
Berbanding dengan kaedah garis dasar, RoboFlamingo bukan sahaja melaksanakan sepenuhnya 5 subtugas berturut-turut, tetapi juga mengambil langkah yang jauh lebih sedikit untuk dua subtugas pertama yang berjaya melaksanakan halaman garis dasar.
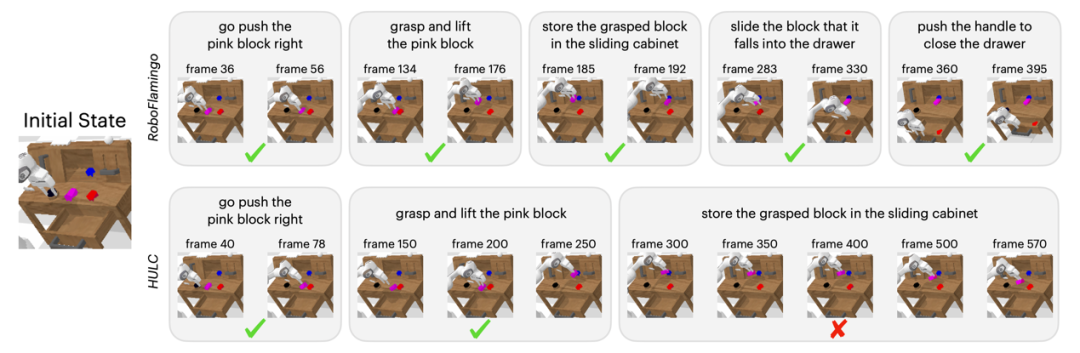
Ringkasan
Kerja ini menyediakan rangka kerja baru berdasarkan VLM sumber terbuka sedia ada untuk strategi pengendalian robot interaktif bahasa, yang boleh mencapai hasil yang cemerlang dengan penalaan halus yang mudah. RoboFlamingo menyediakan penyelidik robotik dengan rangka kerja sumber terbuka yang berkuasa yang memudahkan untuk merealisasikan potensi VLM sumber terbuka. Hasil eksperimen yang kaya dalam kerja mungkin memberikan pengalaman dan data berharga untuk aplikasi praktikal robotik dan menyumbang kepada penyelidikan dan pembangunan teknologi masa depan.
Atas ialah kandungan terperinci Potensi VLM sumber terbuka dilepaskan oleh rangka kerja RoboFlamingo. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!