
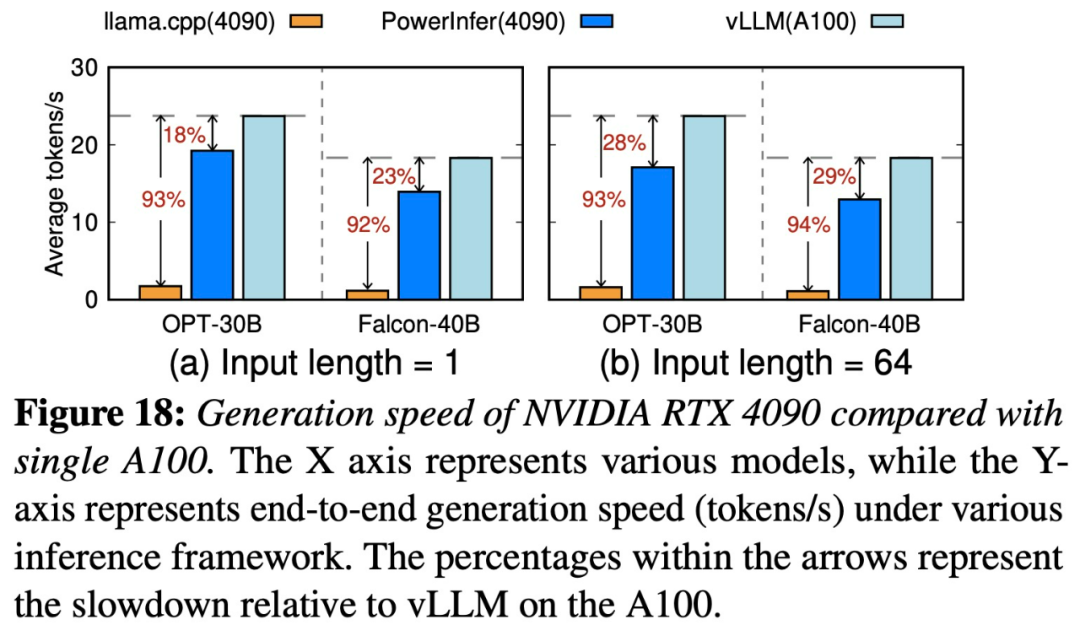
Rumah >Peranti teknologi >AI >Shanghai Jiao Tong University mengeluarkan enjin inferens PowerInfer Kadar penjanaan tokennya hanya 18% lebih rendah daripada A100. Ia mungkin menggantikan 4090 sebagai pengganti A100.
Shanghai Jiao Tong University mengeluarkan enjin inferens PowerInfer Kadar penjanaan tokennya hanya 18% lebih rendah daripada A100. Ia mungkin menggantikan 4090 sebagai pengganti A100.

- WBOYke hadapan
- 2024-01-16 21:27:051099semak imbas
Untuk menulis semula kandungan tanpa mengubah maksud asal, bahasa perlu ditulis semula ke dalam bahasa Cina, dan ayat asal tidak perlu muncul
Jabatan editorial laman web ini
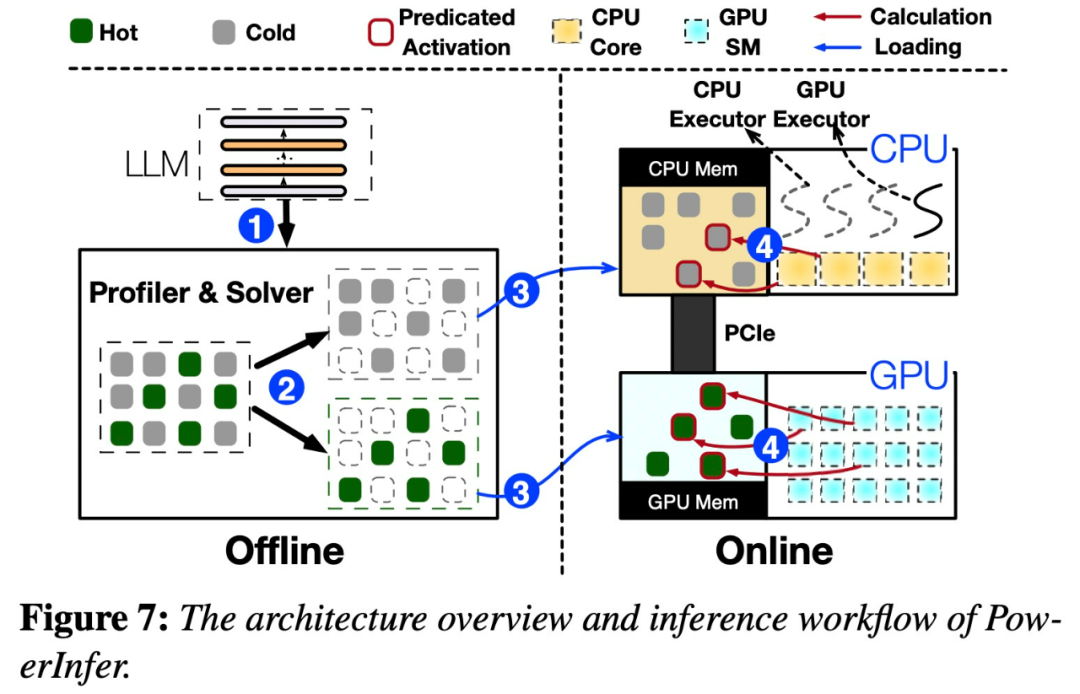
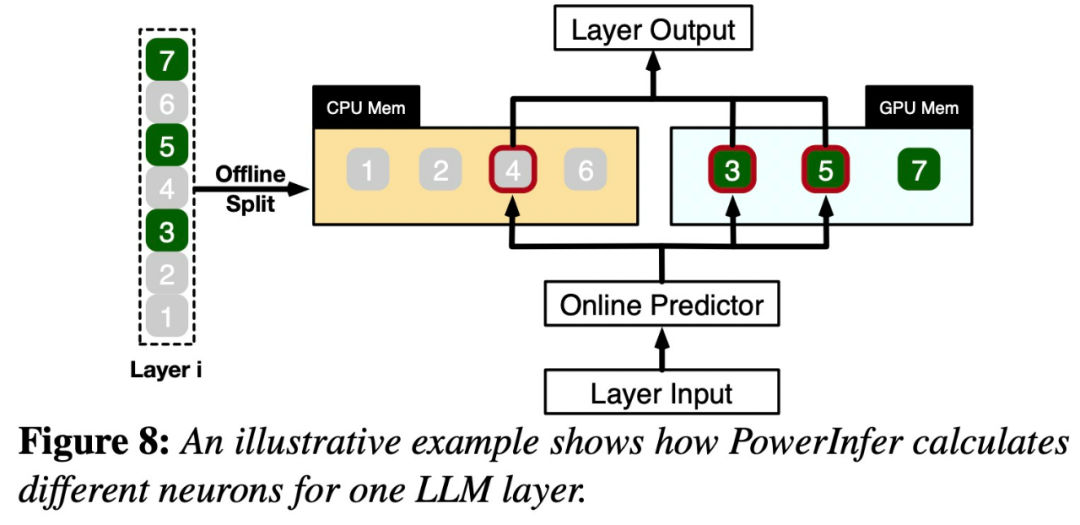
Kemunculan PowerInfer menjadikan Running AI pada perkakasan gred pengguna telah menjadi lebih cekap


Kedua-dua PowerInfer dan llama.cpp dijalankan pada perkakasan yang sama dan memanfaatkan sepenuhnya VRAM pada RTX 4090.
Atas ialah kandungan terperinci Shanghai Jiao Tong University mengeluarkan enjin inferens PowerInfer Kadar penjanaan tokennya hanya 18% lebih rendah daripada A100. Ia mungkin menggantikan 4090 sebagai pengganti A100.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:
Artikel ini dikembalikan pada:jiqizhixin.com. Jika ada pelanggaran, sila hubungi admin@php.cn Padam
Artikel sebelumnya:Masa depan rumah: Terokai cara aliran teknologi akan mengubah kehidupan kita pada 2024Artikel seterusnya:Masa depan rumah: Terokai cara aliran teknologi akan mengubah kehidupan kita pada 2024
Artikel berkaitan
Lihat lagi- 世界vr产业大会地址在哪
- Memperkasakan industri fesyen dengan teknologi untuk membantu Daerah Futian membina 'Pusat Ibu Pejabat Fesyen Bay Area'
- Huawei Cloud dan beberapa syarikat mengeluarkan inisiatif tindakan: bersama-sama membina ekosistem perindustrian terbuka untuk pemanduan autonomi
- Permintaan untuk kuasa pengkomputeran AI telah meningkat dengan mendadak, dan Shanghai Lingang akan membina industri kuasa pengkomputeran berskala puluhan bilion
- Entah dari mana! Pembantu kecerdasan buatan Ai Pin dikeluarkan: ia boleh menayangkan skrin dari tapak tangan anda [dengan analisis rantaian industri kecerdasan buatan]