
Rumah >Peranti teknologi >AI >Google mengeluarkan set data BIG-Bench Mistake untuk membantu model bahasa AI meningkatkan keupayaan pembetulan diri
Google mengeluarkan set data BIG-Bench Mistake untuk membantu model bahasa AI meningkatkan keupayaan pembetulan diri

- 王林ke hadapan
- 2024-01-16 16:39:131386semak imbas

Google Research menggunakan penanda aras BIG-Bench sendiri untuk menubuhkan set data "BIG-Bench Mistake" dan menjalankan penyelidikan penilaian tentang kebarangkalian ralat dan keupayaan pembetulan ralat model bahasa popular di pasaran. Inisiatif ini bertujuan untuk meningkatkan kualiti dan ketepatan model bahasa dan menyediakan sokongan yang lebih baik untuk aplikasi dalam bidang carian pintar dan pemprosesan bahasa semula jadi.
Penyelidik Google berkata mereka mencipta set data khas yang dipanggil "BIG-Bench Mistake" untuk menilai kebarangkalian ralat dan keupayaan pembetulan sendiri model bahasa besar. Tujuan set data ini adalah untuk mengisi jurang kekurangan set data masa lalu untuk menilai keupayaan ini.
Para penyelidik menjalankan 5 tugasan pada penanda aras BIG-Bench menggunakan model bahasa PaLM. Selepas itu, mereka mengubah suai trajektori "Rantai-Pemikiran" yang dijana, menambah bahagian "ralat logik", dan menggunakan model itu sekali lagi untuk menentukan ralat dalam trajektori rantaian-pemikiran.
Untuk meningkatkan ketepatan set data, penyelidik Google mengulangi proses di atas dan membentuk set data penanda aras khusus yang dipanggil "BIG-Bench Mistake", yang mengandungi 255 ralat logik.
Penyelidik menegaskan bahawa ralat logik dalam set data "BIG-Bench Mistake" adalah sangat jelas, jadi ia boleh digunakan sebagai standard ujian yang baik untuk membantu model bahasa mula berlatih daripada ralat logik mudah dan secara beransur-ansur meningkatkan keupayaannya untuk mengenal pasti kesilapan.
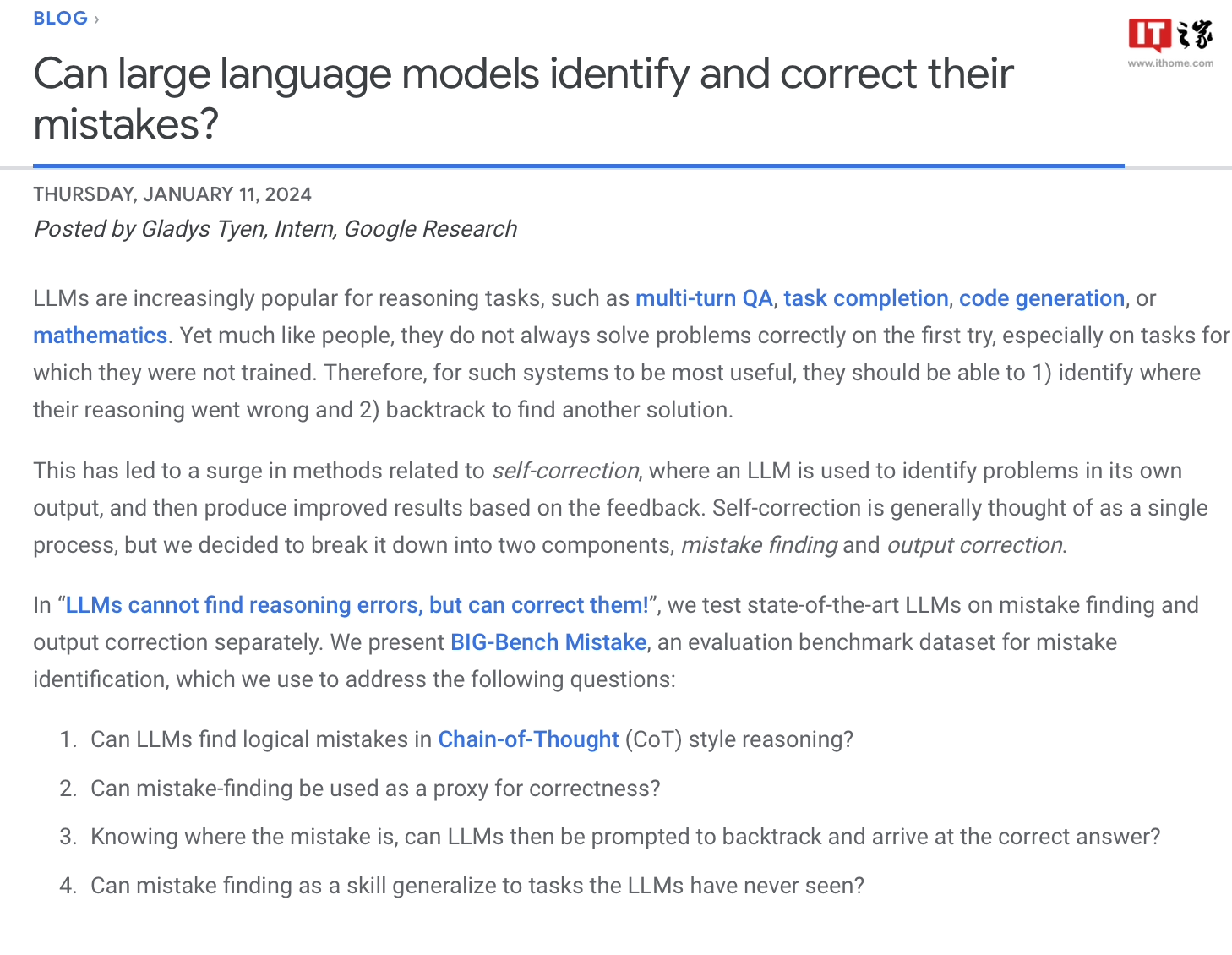
Para penyelidik menggunakan set data ini untuk menguji model di pasaran, dan mendapati bahawa walaupun sebahagian besar model bahasa dapat mengenal pasti ralat logik yang berlaku semasa proses penaakulan dan membetulkan sendiri, proses ini "tidak ideal" dan biasanya memerlukan campur tangan Manusia untuk membetulkan kandungan output model.
▲ Sumber gambar Siaran Akhbar Penyelidikan Google
Tapak ini mendapati daripada laporan bahawa Google mendakwa bahawa "model bahasa besar yang paling maju pada masa ini" mempunyai keupayaan pembetulan diri yang agak terhad, dan ia menunjukkan prestasi terbaik dalam keputusan ujian yang berkaitan. Model itu hanya menemui 52.9% daripada ralat logik.

Menggunakan model khusus yang kecil. untuk menyelia model besar mempunyai Ia akan membantu meningkatkan kecekapan, mengurangkan kos penggunaan AI yang berkaitan dan memudahkan penalaan halus.
Atas ialah kandungan terperinci Google mengeluarkan set data BIG-Bench Mistake untuk membantu model bahasa AI meningkatkan keupayaan pembetulan diri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- win10发现不了airpods怎么办
- Raja Lewat Malam Google mempunyai kemas kini hebat! Model besar PaLM 2 dikeluarkan secara mengejutkan! Bard menulis kod dan tidak tahu apa yang perlu dilakukan!
- Pembaca terbaru Aragonite, Onyx BOOX Palma, dilancarkan, kelihatan menarik perhatian seperti telefon bimbit
- Kunlun Wanwei melancarkan Tiangong AI Search: alat carian AI domestik pertama yang menyepadukan model bahasa berskala besar