
Rumah >Tutorial sistem >LINUX >Pengekstrakan masa nyata dan konsistensi penyegerakan data berasaskan log
Pengekstrakan masa nyata dan konsistensi penyegerakan data berasaskan log

- 王林ke hadapan
- 2024-01-16 14:36:05755semak imbas
Pengarang: Wang Dong
Arkitek Pusat R&D Teknologi CreditEase
- Sedang bekerja di Pusat R&D Teknologi CreditEase sebagai arkitek, bertanggungjawab untuk penstriman pengkomputeran dan penyelesaian produk perniagaan data besar.
- Bekerja sebagai jurutera kanan di Pusat R&D China Naver China (syarikat enjin carian terbesar di Korea Selatan Beliau telah terlibat dalam pembangunan kluster pangkalan data teragih CUBRID dan pembangunan enjin pangkalan data CUBRID selama bertahun-tahun http://www.cubrid). .org/blog/news/cubrid-cluster- introduction/
Pengenalan tema:
- Pengenalan latar belakang kepada DWS
- dbus+lubang cacing keseluruhan seni bina dan pelan pelaksanaan teknikal
- Kes aplikasi praktikal DWS
Salam semua, saya Wang Dong, dari Pusat R&D Teknologi CreditEase Ini adalah kali pertama saya berkongsi dalam komuniti Jika terdapat sebarang kekurangan, sila perbetulkan saya dan maafkan saya.
Tema perkongsian ini ialah "Pelaksanaan dan Aplikasi Platform DWS Berasaskan Log", terutamanya untuk berkongsi beberapa perkara yang sedang kami lakukan di CreditEase. Topik ini mengandungi hasil usaha ramai adik-beradik kedua-dua pasukan (hasil pasukan kami dan pasukan Shanwei). Kali ini saya akan menulisnya bagi pihak saya dan cuba sedaya upaya untuk memperkenalkannya kepada anda.
Malah, keseluruhan pelaksanaannya secara prinsipnya agak mudah, dan tentunya ia juga melibatkan banyak teknologi. Saya akan cuba menyatakannya dengan cara yang paling mudah untuk membolehkan semua orang memahami prinsip dan kepentingan perkara ini. Semasa proses itu, jika anda mempunyai sebarang soalan, anda boleh bertanya kepada mereka pada bila-bila masa dan saya akan cuba sedaya upaya untuk menjawabnya.
DWS adalah singkatan dan terdiri daripada 3 sub-projek, yang akan saya terangkan kemudian.
1 Perkara ini bermula dengan keperluan syarikat suatu masa dahulu Semua orang tahu bahawa CreditEase ialah sebuah syarikat kewangan Internet yang berbeza daripada syarikat Internet standard
 Semua orang yang bermain dengan data tahu bahawa data adalah sangat berharga, dan data ini disimpan dalam pangkalan data pelbagai sistem Bagaimana pengguna yang memerlukan data mendapat data yang konsisten dan masa nyata?
Semua orang yang bermain dengan data tahu bahawa data adalah sangat berharga, dan data ini disimpan dalam pangkalan data pelbagai sistem Bagaimana pengguna yang memerlukan data mendapat data yang konsisten dan masa nyata?
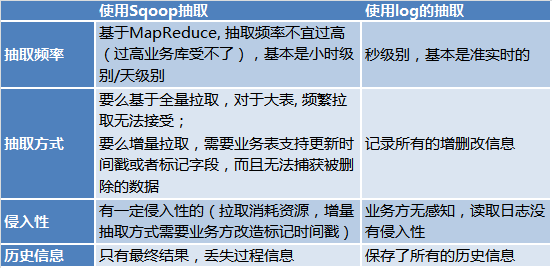
- Platform data besar bersatu syarikat menggunakan Sqoop untuk mengekstrak data secara seragam daripada pelbagai sistem semasa tempoh perniagaan yang rendah, menyimpannya ke dalam jadual Hive, dan kemudian menyediakan perkhidmatan data kepada pengguna data lain. Pendekatan ini menyelesaikan masalah ketekalan, tetapi ketepatan masanya kurang baik, pada dasarnya ketepatan masa T+1.
- Masalah utama untuk mendapatkan perubahan tambahan berdasarkan pencetus ialah bahagian perniagaan sangat mengganggu, dan pencetus juga menyebabkan kerugian prestasi.
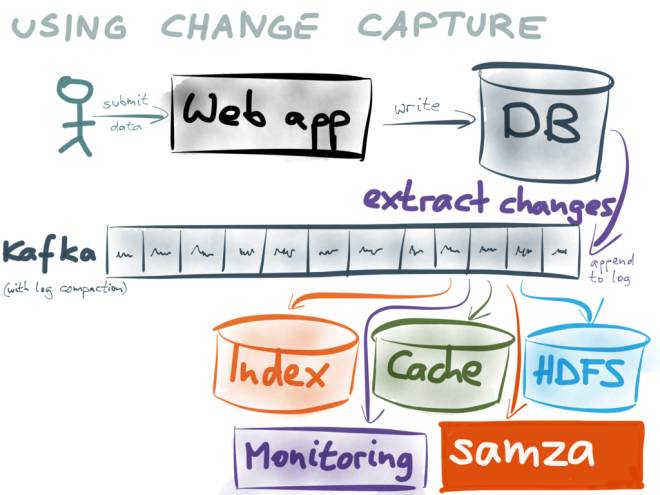 (Gambar ini datang daripada: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea / )
(Gambar ini datang daripada: https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea / )
Gunakan Log incremental sebagai asas kepada semua sistem. Pengguna data seterusnya menggunakan log dengan melanggan kafka.
Contohnya:
- Pengguna yang menyediakan perkhidmatan carian boleh menyimpannya ke Elasticsearch atau HBase;
- Pengguna yang menyediakan perkhidmatan caching boleh cache log ke Redis atau alluxio
- Pengguna penyegerakan data boleh menyimpan data ke pangkalan data mereka sendiri;
- Memandangkan log Kafka boleh digunakan berulang kali dan dicache untuk tempoh masa, setiap pengguna boleh mengekalkan konsistensi dengan pangkalan data dan memastikan prestasi masa nyata dengan menggunakan log Kafka
 Mengapa tidak menggunakan dual write? , sila rujuk https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
Mengapa tidak menggunakan dual write? , sila rujuk https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
Saya tidak akan menerangkan banyak perkara di sini.
Jadi kami mendapat idea untuk membina platform peringkat syarikat berdasarkan log.
Berikut menerangkan platform DWS Platform DWS terdiri daripada 3 sub-projek:
- Dbus (bas data): Bertanggungjawab untuk mengekstrak data daripada sumber dalam masa nyata, menukarnya kepada data format json (data UMS) yang dipersetujui dengan skemanya sendiri, dan memasukkannya ke dalam kafka
- Wormhole (platform pertukaran data): Bertanggungjawab membaca data dari kafka dan menulis data kepada sasaran
- Swifts (platform pengkomputeran masa nyata): Bertanggungjawab untuk membaca data daripada kafka, mengira dalam masa nyata dan menulis kembali data kepada kafka.
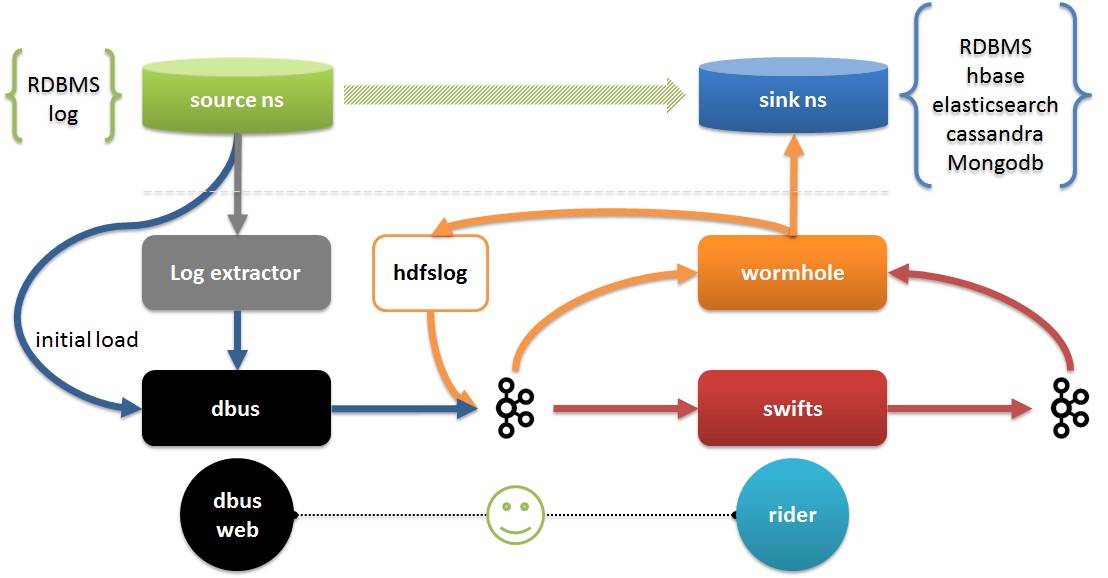
Dalam gambar:
- Pengekstrak log dan dbus bekerjasama untuk melengkapkan pengekstrakan data dan penukaran data Pengekstrakan termasuk pengekstrakan penuh dan tambahan.
- Wormhole boleh menyimpan semua data log ke HDFS; ia juga boleh melaksanakan data ke semua pangkalan data yang menyokong jdbc, termasuk HBash, Elasticsearch, Cassandra, dll.; Swifts menyokong pengiraan penstriman melalui konfigurasi dan SQL, termasuk menyokong penstriman bergabung, cari, penapis, pengagregatan tetingkap dan fungsi lain
- Dbus web ialah penghujung pengurusan konfigurasi dbus Selain pengurusan konfigurasi, rider juga termasuk pengurusan runtime Wormhole dan Swifts, pengesahan kualiti data, dsb.
Kami tahu bahawa walaupun MySQL InnoDB mempunyai lognya sendiri, penyegerakan utama dan sekunder MySQL dicapai melalui binlog. Seperti yang ditunjukkan di bawah:
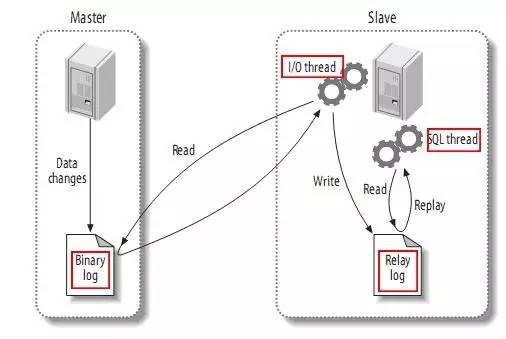
Dan binlog mempunyai tiga mod:
- Mod baris: Bentuk yang diubah suai bagi setiap baris data akan direkodkan dalam log, dan kemudian data yang sama akan diubah suai pada bahagian hamba.
- Mod penyata: Setiap pernyataan SQL yang mengubah suai data akan direkodkan dalam log bin induk. Apabila hamba mereplikasi, proses SQL akan menghuraikannya ke dalam SQL yang sama yang telah dilaksanakan pada bahagian induk asal dan melaksanakannya semula.
- Mod campuran: MySQL akan membezakan borang log yang akan direkodkan berdasarkan setiap pernyataan SQL tertentu yang dilaksanakan, iaitu, pilih satu antara Penyata dan Baris.

Disebabkan oleh kekurangan mod pernyataan, semasa komunikasi dengan DBA kami, kami mengetahui bahawa mod baris digunakan untuk replikasi dalam proses pengeluaran sebenar. Ini membolehkan anda membaca keseluruhan log.
Biasanya susun atur MySQL kami ialah penyelesaian 2 pangkalan data induk (vip) + 1 pangkalan data hamba + 1 pangkalan data pemulihan bencana sandaran Memandangkan pangkalan data pemulihan bencana biasanya digunakan untuk pemulihan bencana di luar tapak, prestasi masa nyata tidak tinggi. Tidak mudah untuk digunakan.
Untuk meminimumkan kesan pada hujung sumber, jelas sekali kita harus membaca log binlog dari perpustakaan hamba.
Terdapat banyak penyelesaian untuk membaca binlog, dan terdapat banyak di github Sila rujuk https://github.com/search?utf8=%E2%9C%93&q=binlog. Akhirnya, kami memilih terusan Alibaba sebagai kaedah pengekstrakan balak.
Terusan pertama kali digunakan untuk menyegerakkan bilik komputer Cina dan Amerika Alibaba Prinsip terusan adalah agak mudah:
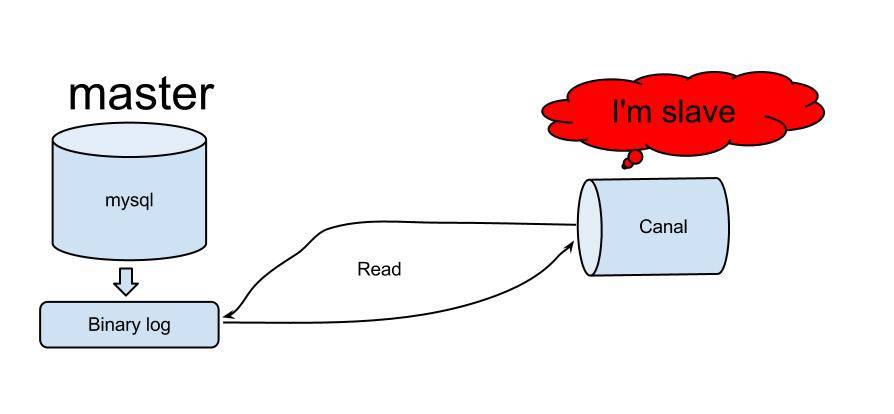
Gambar daripada: https://github.com/alibaba/canal
PenyelesaianPenyelesaian utama untuk versi MySQL Dbus adalah seperti berikut:
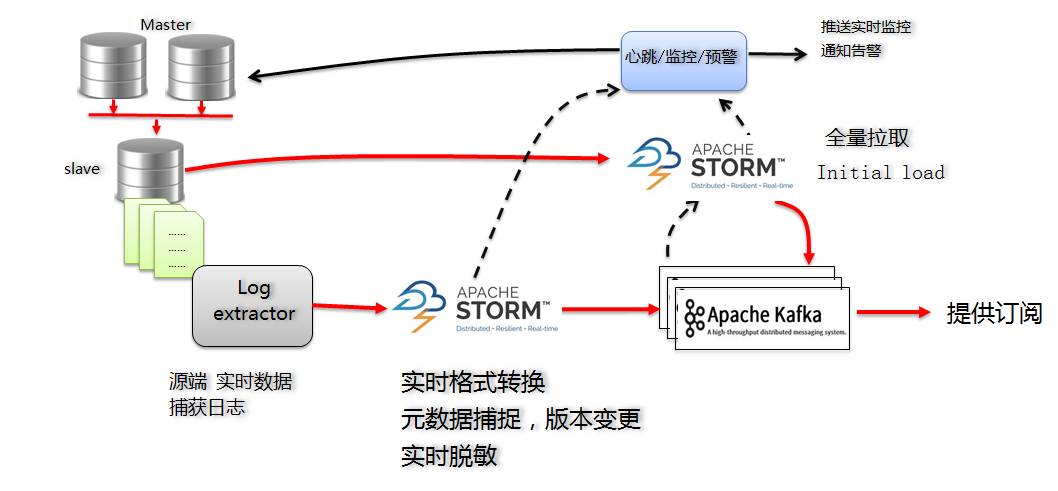
Untuk log incremental, dengan melanggan Canal Server, kami mendapat log incremental MySQL:
- Menurut output Canal, log adalah dalam format protobuf Bangunkan program Storm tambahan untuk menukar data ke dalam format UMS yang kami tentukan dalam masa nyata (format json, saya akan memperkenalkannya kemudian), dan simpan ke kafka;
- Program Storm tambahan juga bertanggungjawab untuk menangkap perubahan skema untuk mengawal nombor versi;
- Maklumat konfigurasi Ribut Bertambah disimpan dalam Zookeeper untuk memenuhi keperluan ketersediaan yang tinggi.
- Kafka berfungsi sebagai hasil keluaran dan sebagai penampan dan kawasan penyahbinaan mesej semasa pemprosesan.
Apabila mempertimbangkan untuk menggunakan Storm sebagai penyelesaian, kami berpendapat bahawa Storm mempunyai kelebihan berikut:
- Teknologi ini agak matang dan stabil, dan ia boleh dianggap sebagai gabungan standard apabila digandingkan dengan kafka
- Prestasi masa nyata agak tinggi dan boleh memenuhi keperluan masa nyata;
- Memenuhi keperluan ketersediaan tinggi;
- Dengan mengkonfigurasi konkurensi Storm, anda boleh mengaktifkan keupayaan untuk mengembangkan prestasi
Untuk jadual aliran, bahagian incremental sudah memadai, tetapi banyak jadual perlu mengetahui maklumat awal (sedia ada). Pada masa ini kita memerlukan beban awal (muatan pertama).
Untuk beban awal (muatan pertama), kami juga membangunkan program Storm pengekstrakan penuh untuk menarik dari pangkalan data siap sedia pangkalan data sumber melalui sambungan jdbc. Muatan awal adalah untuk menarik semua data, jadi kami mengesyorkan melakukannya semasa tempoh puncak perniagaan yang rendah. Nasib baik, anda hanya melakukannya sekali dan anda tidak perlu melakukannya setiap hari.
Untuk mengekstrak jumlah penuh, kami menggunakan idea Sqoop. Pengekstrakan penuh Storm dibahagikan kepada 2 bahagian:
- Perkongsian Data
- Pengeluaran sebenar
Perkongsian data perlu mempertimbangkan lajur sharding, bahagikan data mengikut julat mengikut konfigurasi dan pilih lajur secara automatik, dan simpan maklumat sharding ke kafka.
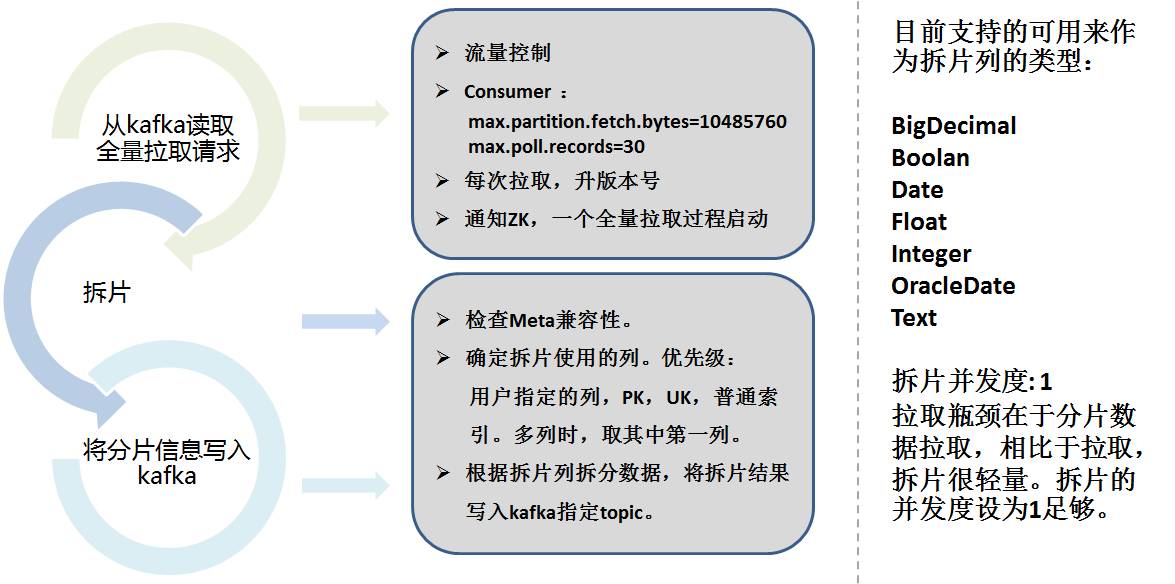
Berikut ialah strategi sharding khusus:
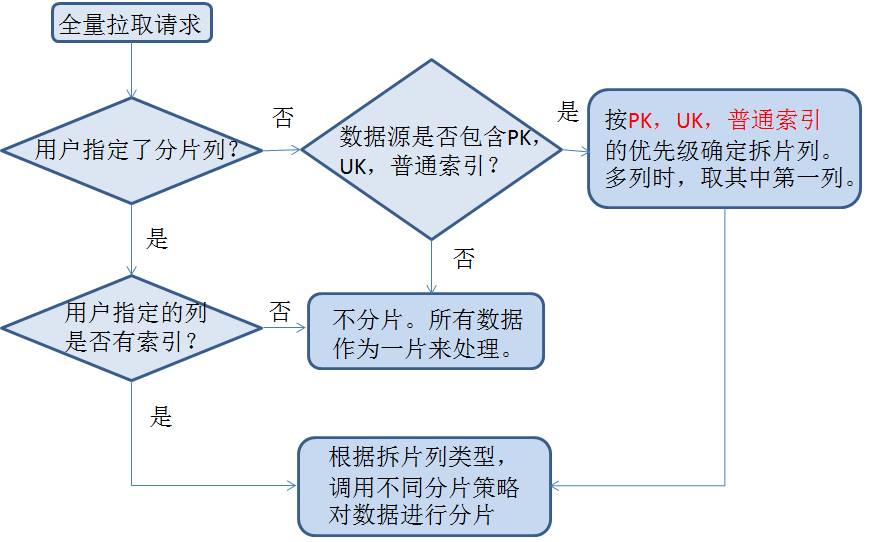
Program Storm untuk pengekstrakan penuh membaca maklumat serpihan Kafka, dan menggunakan berbilang tahap konkurensi untuk menyambung ke pangkalan data siap sedia secara selari untuk menarik. Kerana masa pengekstrakan mungkin sangat lama. Semasa proses pengekstrakan, status masa nyata ditulis kepada Zookeeper untuk memudahkan pemantauan program degupan jantung.
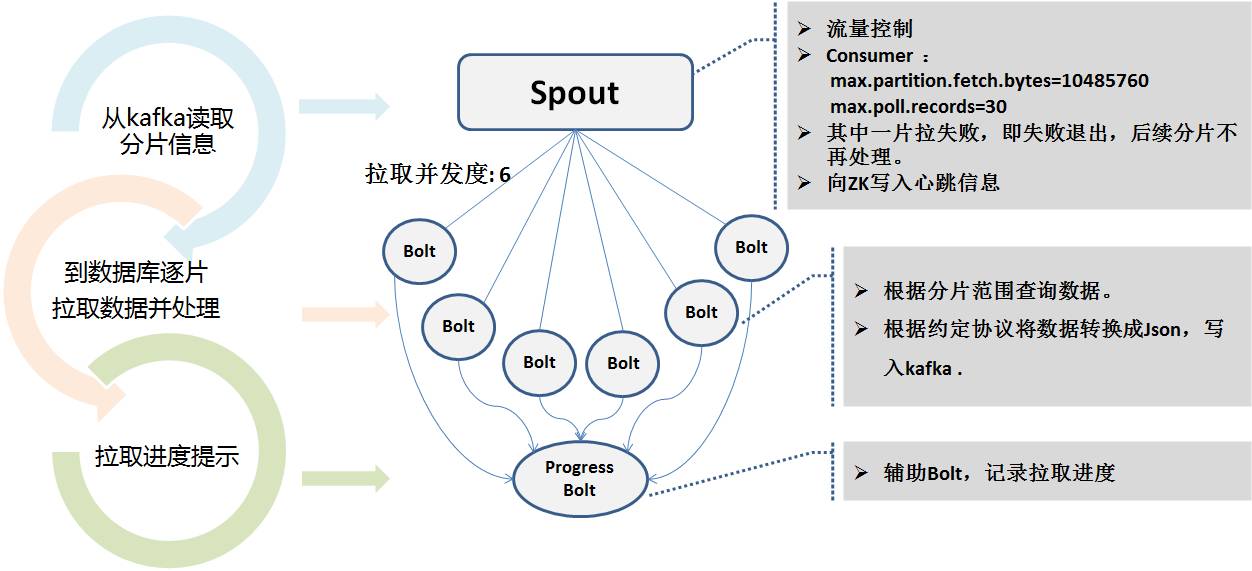
Sama ada tambahan atau penuh, output mesej terakhir kepada kafka ialah format mesej bersatu yang kami persetujui, dipanggil format UMS (skema mesej bersatu).
Seperti gambar di bawah:
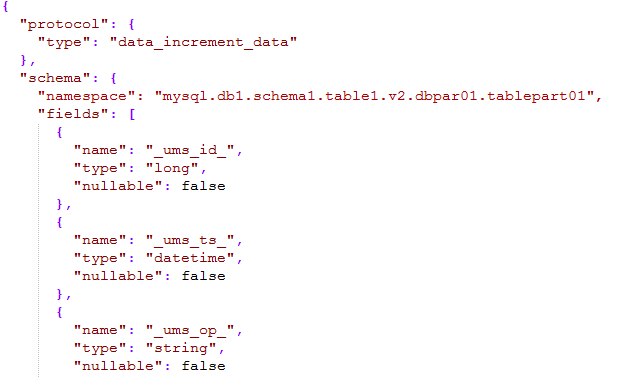

Bahagian skema mesej mentakrifkan ruang nama, yang terdiri daripada jenis + nama sumber data + nama skema + nama jadual + nombor versi + nombor sub-perpustakaan + nombor sub-jadual boleh terletak secara unik melalui ruang nama.
- _ums_op_ menunjukkan bahawa jenis data ialah I (masukkan), U (kemas kini), D (padam ).
- _ums_ts_ Cap masa acara penambahan, pemadaman dan pengubahsuaian Jelas sekali cap masa data baharu dikemas kini
- _ums_id_ Id unik mesej, memastikan mesej itu unik, tetapi di sini kami memastikan susunan mesej (diterangkan kemudian ).
Payload merujuk kepada data tertentu Pakej json boleh mengandungi 1 atau lebih keping data untuk meningkatkan muatan data.
Jenis data yang disokong dalam UMS merujuk kepada jenis Hive dan dipermudahkan, pada asasnya termasuk semua jenis data.
Ketekalan volum penuh dan volum tambahanDalam keseluruhan penghantaran data, untuk memastikan susunan mesej log sebanyak mungkin, Kafka menggunakan kaedah partition. Secara umum, ia pada asasnya berurutan dan unik.
Tetapi kami tahu bahawa penulisan Kafka akan gagal dan mungkin ditulis semula Storm juga menggunakan mekanisme buat semula Oleh itu, kami tidak menjamin dengan tepat sekali dan urutan lengkap, tetapi kami menjamin sekurang-kurangnya sekali.
Jadi _ums_id_ menjadi sangat penting.
Untuk pengekstrakan penuh, _ums_id_ adalah unik. Kepingan id yang berbeza diambil dari setiap tahap keselarasan dalam zk, memastikan keunikan dan prestasi tidak akan bercanggah dengan data tambahan, dan juga memastikan bahawa ia lebih awal daripada data tambahan. Jumlah berita.
Untuk pengekstrakan tambahan, kami menggunakan nombor fail log + log offset MySQL sebagai ID unik. Id digunakan sebagai integer panjang 64-bit, 7 bit atas digunakan untuk nombor fail log, dan 12 bit bawah digunakan sebagai offset log.
Contohnya: 000103000012345678. 103 ialah nombor fail log dan 12345678 ialah log offset.
Dengan cara ini, keunikan fizikal dipastikan dari peringkat log (nombor ID tidak akan berubah walaupun ia dibuat semula), dan pesanan juga dijamin (log juga boleh didapati). Dengan membandingkan log penggunaan _ums_id_, anda boleh mengetahui mesej yang dikemas kini dengan membandingkan _ums_id_.
Sebenarnya, niat _ums_ts_ dan _ums_id_ adalah serupa, kecuali kadangkala _ums_ts_ mungkin berulang, iaitu beberapa operasi berlaku dalam 1 milisaat, jadi anda perlu bergantung pada perbandingan _ums_id_.
Pemantauan degupan jantung dan amaran awalKeseluruhan sistem melibatkan penyegerakan utama dan sandaran pangkalan data, Pelayan Terusan, pelbagai proses Ribut serentak dan aspek lain.
Oleh itu, pemantauan dan amaran awal proses adalah amat penting.
Melalui modul degupan jantung, contohnya, sekeping data mentaliti dimasukkan ke dalam setiap jadual yang diekstrak setiap minit (boleh dikonfigurasikan) dan masa penghantaran disimpan jadual degupan jantung ini juga diekstrak dan mengikuti keseluruhan proses, yang sebenarnya sama seperti logik yang disegerakkan (kerana berbilang Ribut serentak mungkin mempunyai cawangan yang berbeza), apabila paket degupan jantung diterima, walaupun tiada data ditambah, dipadam atau diubah suai, ia boleh dibuktikan bahawa keseluruhan pautan terbuka.
Program Storm dan program degupan jantung menghantar data ke topik statistik awam, dan kemudian program statistik menyimpannya ke influxdb Gunakan grafana untuk memaparkannya, dan anda boleh melihat kesan berikut:
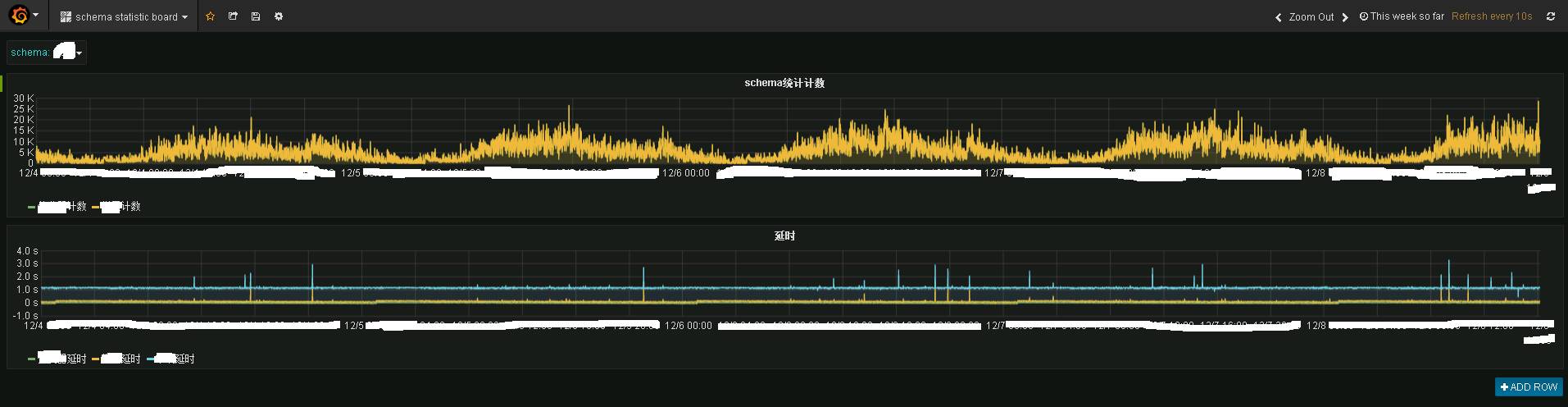
Gambar menunjukkan maklumat pemantauan masa nyata sistem perniagaan tertentu. Di atas ialah situasi trafik masa nyata, dan berikut ialah situasi kelewatan masa nyata. Ia boleh dilihat bahawa prestasi masa nyata masih sangat baik Pada asasnya, data telah dipindahkan ke terminal Kafka dalam 1 hingga 2 saat.
Granfana menyediakan keupayaan pemantauan masa nyata.
Jika berlaku kelewatan, penggera e-mel atau penggera SMS akan dihantar melalui modul degupan jantung dbus.
Penyahpekaan masa nyataMemandangkan keselamatan data, program ribut penuh dan ribut tambahan Dbus turut melengkapkan fungsi penyahpekaan masa nyata untuk senario di mana penyahpekaan diperlukan. Terdapat 3 cara penyahpekaan:

Untuk meringkaskan: Ringkasnya, Dbus mengeksport data daripada pelbagai sumber dalam masa nyata dan menyediakan langganan dalam bentuk UMS, menyokong penyahpekaan masa nyata, pemantauan sebenar dan membimbangkan.
Selepas bercakap tentang Dbus, tiba masanya untuk bercakap tentang Wormhole Mengapa kedua-dua projek itu bukan satu tetapi disambungkan melalui kafka?
Salah satu sebab utama ialah penyahgandingan Kafka mempunyai keupayaan penyahgandingan semula jadi, dan program ini boleh terus melaksanakan mesej tak segerak melalui Kafka. Dbus dan Wornhole juga menggunakan kafka secara dalaman untuk penghantaran mesej dan penyahgandingan.
Sebab lain ialah UMS menggambarkan diri Dengan melanggan kafka, mana-mana pengguna yang berkebolehan boleh terus menggunakan UMS untuk digunakan.
Walaupun keputusan UMS boleh dilanggan terus, ia tetap memerlukan kerja pembangunan. Apa yang diselesaikan oleh Wormhole ialah menyediakan konfigurasi satu klik untuk melaksanakan data dalam Kafka ke dalam pelbagai sistem, membenarkan pengguna data tanpa keupayaan pembangunan untuk menggunakan data melalui Wormhole.
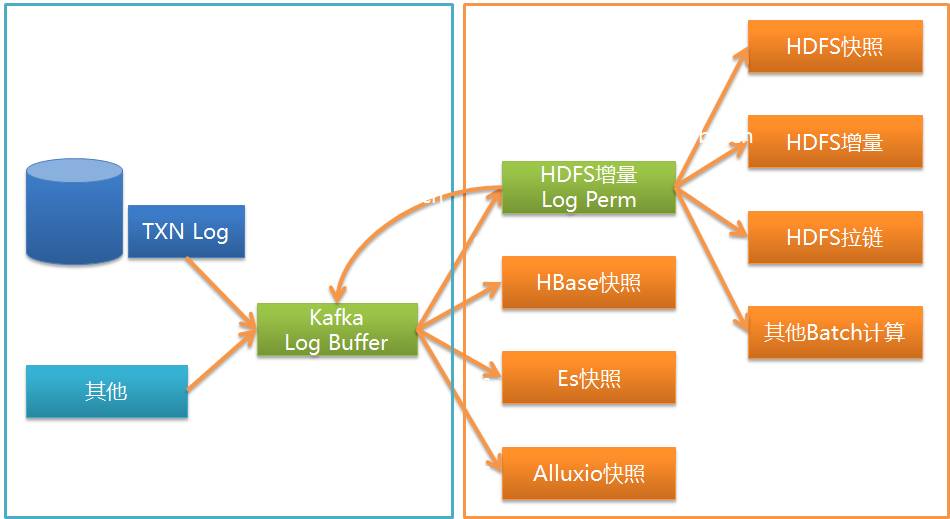
Seperti yang ditunjukkan dalam rajah, Wormhole boleh melaksanakan UMS dalam kafka kepada pelbagai sistem, pada masa ini yang paling biasa digunakan ialah HDFS, pangkalan data JDBC dan HBase.
Dari segi susunan teknologi, lubang cacing memilih untuk menggunakan penstriman percikan.
Dalam Wormhole, aliran merujuk dari namaspace dari sumber ke sasaran. Satu penstriman percikan berfungsi dengan pelbagai aliran.
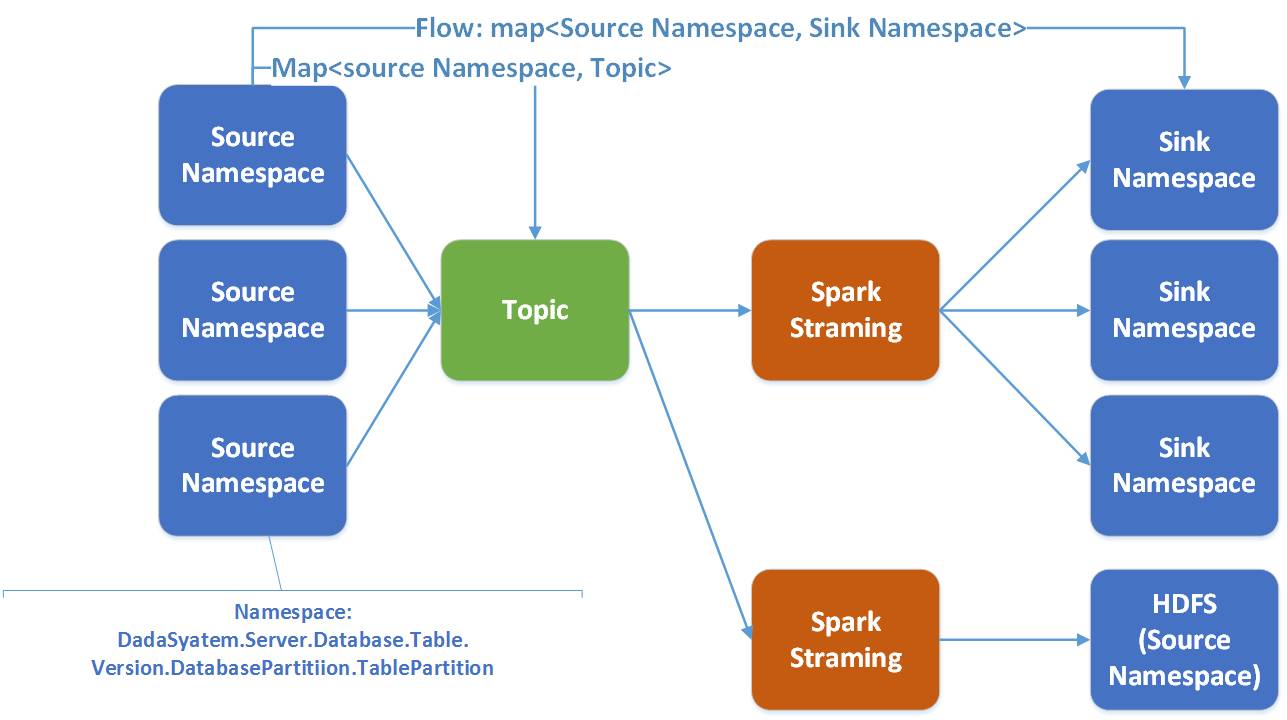
Ada sebab yang baik untuk memilih Spark:
- Spark secara semula jadi menyokong pelbagai sistem storan heterogen
- Walaupun Spark Stream mempunyai kependaman sedikit lebih buruk daripada Storm, Spark mempunyai daya pemprosesan yang lebih baik dan prestasi pengkomputeran yang lebih baik
- Spark mempunyai fleksibiliti yang lebih besar dalam menyokong pengkomputeran selari
- Spark menyediakan fungsi bersatu untuk menyelesaikan Sparking Job, Spark Streaming dan Spark SQL dalam timbunan teknologi untuk memudahkan pembangunan kemudian
Berikut ialah fungsi Swifts:
- Intipati Swifts ialah membaca data UMS dalam kafka, melakukan pengiraan masa nyata dan menulis keputusan ke topik lain dalam kafka.
- Pengiraan masa nyata boleh dilakukan dalam pelbagai cara: seperti penapis, unjuran (unjuran), carian, penstriman menyertai pengagregatan tetingkap, yang boleh melengkapkan pelbagai pengiraan masa nyata penstriman dengan nilai perniagaan.
Perbandingan antara Wormhole dan Swifts adalah seperti berikut:
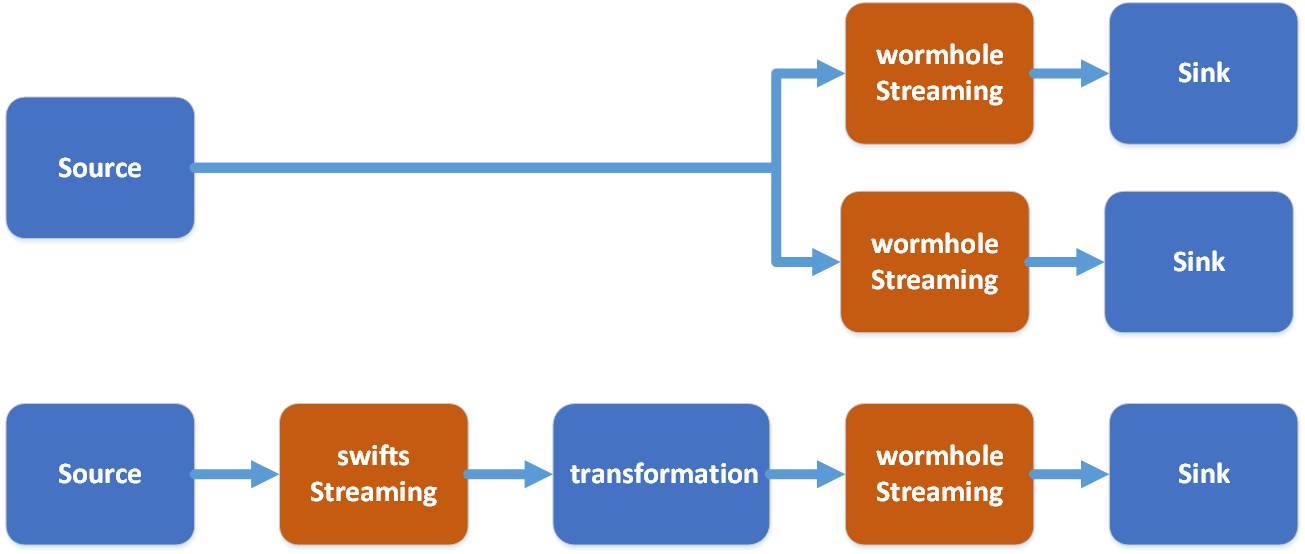
Gunakan program Wormhole Wpark Streaming untuk menggunakan UMS kafka Pertama, log UMS boleh disimpan ke HDFS.
Kafka secara amnya hanya menyimpan beberapa hari maklumat dan tidak menyimpan semua maklumat, manakala HDFS boleh menyimpan semua penambahan sejarah, pemadaman dan pengubahsuaian. Ini membolehkan banyak perkara:
- Dengan memainkan semula log dalam HDFS, kami boleh memulihkan syot kilat sejarah pada bila-bila masa.
- Anda boleh membuat senarai zip untuk memulihkan maklumat sejarah setiap rekod untuk analisis mudah
- Apabila ralat berlaku dalam program, anda boleh menggunakan isian semula untuk menggunakan semula mesej dan membentuk semula syot kilat baharu.
Boleh dikatakan log in HDFS adalah asas kepada banyak perkara.
Oleh kerana Spark menyokong parket secara asli, Spark SQL boleh memberikan pertanyaan yang baik untuk Parket. Apabila UMS dilaksanakan pada HDFS, ia disimpan ke dalam fail Parket. Kandungan Parket ialah maklumat tambahan, pemadaman dan pengubahsuaian semua log, serta _ums_id_ dan _ums_ts_.
Penstriman percikan lubang cacing mengedar dan menyimpan data ke dalam direktori yang berbeza mengikut ruang nama, iaitu jadual dan versi yang berbeza diletakkan dalam direktori yang berbeza.
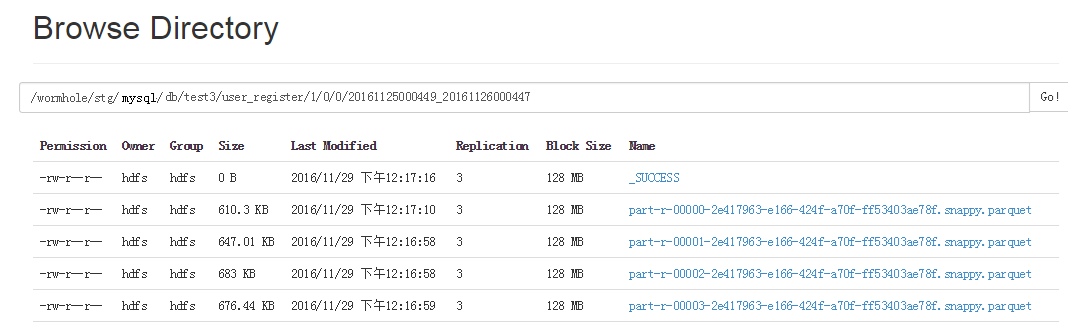
Memandangkan fail Parket yang ditulis setiap kali adalah fail kecil, semua orang tahu bahawa HDFS tidak berfungsi dengan baik untuk fail kecil, jadi ada tugas lain untuk menggabungkan fail Parket ini ke dalam fail besar dengan kerap setiap hari.
Setiap direktori fail Parket disertakan dengan masa mula dan masa tamat data fail. Dengan cara ini, apabila mengisi semula data, anda boleh memutuskan fail Parket yang perlu dibaca berdasarkan julat masa yang dipilih, tanpa membaca semua data.
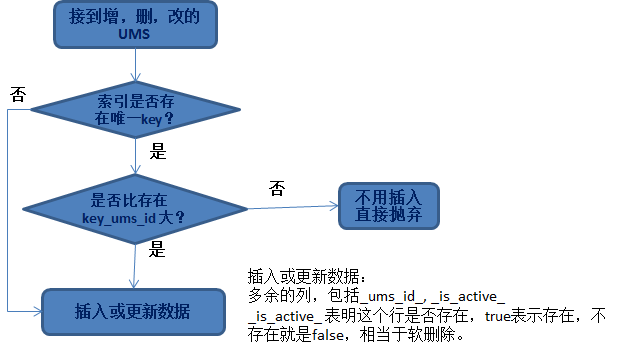
Idempotensi memasukkan atau mengemas kini dataSelalunya keperluan yang kita hadapi adalah untuk memproses data dan memasukkannya ke dalam pangkalan data atau HBase. Jadi persoalan yang terlibat di sini ialah, apakah jenis data yang boleh dikemas kini?
Prinsip yang paling penting di sini ialah penyahdayaan data.
Tidak kira semasa menambah, memadam atau mengubah suai sebarang data, masalah yang kami hadapi ialah:
- Barisan manakah yang perlu dikemas kini
- Apakah strategi yang dikemas kini.
Untuk soalan pertama, anda sebenarnya perlu mencari kunci unik untuk mencari data yang biasa termasuk:
- Gunakan kunci utama perpustakaan perniagaan;
- Pihak perniagaan menentukan beberapa lajur sebagai indeks unik bersama
Untuk soalan kedua, ia melibatkan _ums_id_, kerana kami telah memastikan nilai _ums_id_ yang besar dikemas kini, jadi selepas menemui baris data yang sepadan, kami akan menggantikan dan mengemas kininya mengikut prinsip ini.
Sebab mengapa kita perlu memadam lembut dan menambah lajur _is_active_ adalah untuk situasi sedemikian:
Jika _ums_id_ yang dimasukkan agak besar, ia adalah data yang dipadam (menunjukkan bahawa data itu telah dipadamkan, jika ia bukan pemadaman lembut, masukkan data _ums_id_ (data lama) yang kecil pada masa ini, dan ia sebenarnya akan dimasukkan). .
Ini menyebabkan data lama akan dimasukkan. Tidak lagi idempoten. Oleh itu, adalah penting bahawa data yang dipadam masih dikekalkan (penghapusan lembut), dan ia boleh digunakan untuk memastikan data yang hilang.
HBase penjimatanMemasukkan data ke dalam Hbase agak mudah. Perbezaannya ialah HBase boleh mengekalkan berbilang versi data (sudah tentu, anda juga boleh mengekalkan hanya satu versi lalainya adalah untuk mengekalkan 3 versi;
Jadi apabila memasukkan data ke dalam HBase, masalah yang perlu diselesaikan ialah:
- Pilih kekunci baris yang sesuai: Reka bentuk Rowkey adalah pilihan Pengguna boleh memilih kunci utama jadual sumber, atau memilih beberapa lajur sebagai kunci utama bersama.
- Pilih versi yang sesuai: Gunakan _ums_id_+ offset yang lebih besar (seperti 10 bilion) sebagai versi baris.
Dari perspektif meningkatkan prestasi, kami boleh terus memasukkan keseluruhan koleksi Set Data Penstriman Spark ke dalam HBase tanpa perbandingan. Biarkan HBase menentukan secara automatik untuk kami data mana yang boleh disimpan dan data mana yang tidak perlu disimpan berdasarkan versi.
Masukkan data dalam Jdbc:
Masukkan data ke dalam pangkalan data Walaupun prinsip memastikan hilang pucuk adalah mudah, jika anda ingin meningkatkan prestasi, pelaksanaannya menjadi lebih rumit.
Kami tahu bahawa RDD/set data Spark dikendalikan dalam cara pengumpulan untuk meningkatkan prestasi Begitu juga, kami perlu mencapai mati pucuk dalam cara operasi pengumpulan.
Idea khusus ialah:
- Pertama, tanya pangkalan data sasaran berdasarkan kunci utama dalam set untuk mendapatkan set data sedia ada
- Berbanding dengan koleksi dalam set data, ia terbahagi kepada dua kategori:
B: Bandingkan data sedia ada dengan _ums_id_, dan akhirnya hanya kemas kini baris _ums_id_ yang lebih besar kepada pangkalan data sasaran dan buang terus baris yang lebih kecil.
Apabila mempertimbangkan konkurensi, kedua-dua sisipan dan kemas kini mungkin gagal, jadi terdapat juga strategi untuk dipertimbangkan selepas kegagalan.
Contohnya: kerana pekerja lain telah memasukkan, dan sisipan gagal kerana kekangan unik, sebaliknya anda perlu mengemas kininya dan bandingkan _ums_id_ untuk melihat sama ada ia boleh dikemas kini.
Untuk situasi lain di mana kemasukan adalah mustahil (seperti masalah dengan sistem sasaran), Wormhole juga mempunyai mekanisme cuba semula. Terdapat begitu banyak butiran. Tidak banyak pengenalan di sini.
Ada yang masih dalam pembangunan.
Saya tidak akan membincangkan butiran tentang memasukkan ke dalam storan lain Prinsip umum ialah: reka bentuk pelaksanaan pemasukan data serentak berasaskan koleksi berdasarkan ciri setiap storan. Ini adalah usaha Wormhole untuk prestasi, dan pengguna yang menggunakan Wormhole tidak perlu risau tentangnya.
Setelah berkata begitu banyak, apakah aplikasi praktikal DWS? Seterusnya, saya akan memperkenalkan pemasaran masa nyata yang dilaksanakan oleh sistem tertentu menggunakan DWS.
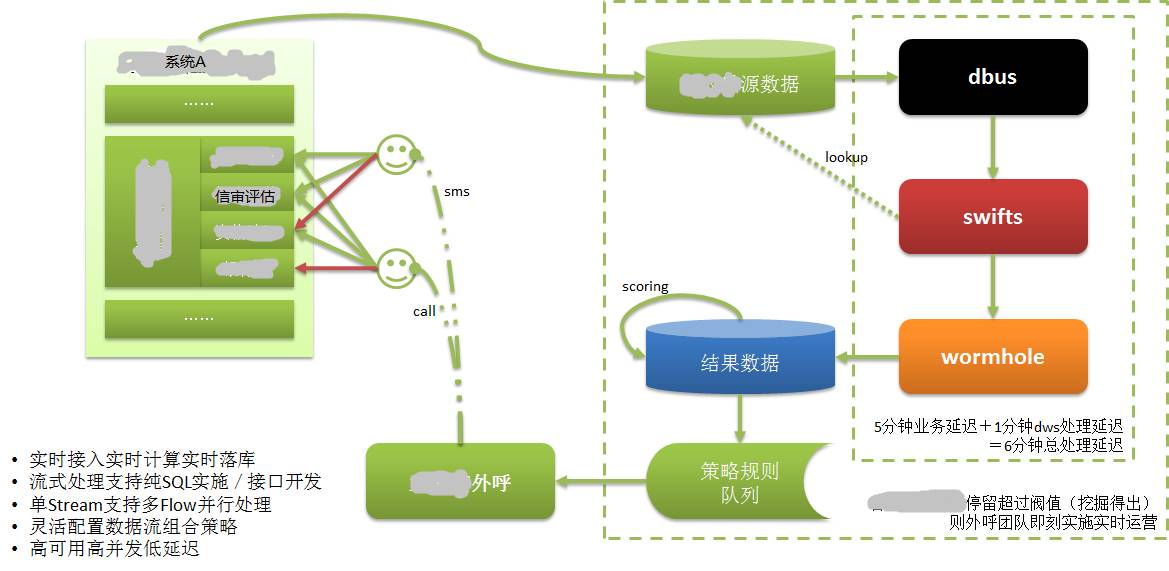
Seperti gambar di atas:
Data Sistem A disimpan dalam pangkalan datanya sendiri Kami tahu bahawa CreditEase menyediakan banyak perkhidmatan kewangan, termasuk peminjaman, dan perkara yang sangat penting dalam proses peminjaman adalah semakan kredit.
Peminjam perlu memberikan maklumat yang membuktikan kelayakan kredit mereka, seperti laporan kredit bank pusat, iaitu data dengan data kredit terkuat. Urus niaga bank dan transaksi beli-belah dalam talian juga merupakan data dengan atribut kredit yang kukuh.
Apabila peminjam mengisi maklumat kredit dalam Sistem A melalui Web atau APP mudah alih, dia mungkin tidak dapat meneruskan atas sebab tertentu Walaupun peminjam ini mungkin bakal pelanggan yang berkualiti tinggi, pada masa lalu, maklumat ini tidak tersedia atau hanya boleh diketahui untuk masa yang lama.
Selepas memohon DWS, maklumat yang diisi oleh peminjam telah direkodkan dalam pangkalan data, dan diekstrak, dikira dan dilaksanakan dalam pangkalan data sasaran dalam masa nyata melalui DWS. Nilaikan pelanggan berkualiti tinggi berdasarkan penilaian pelanggan. Kemudian segera keluarkan maklumat pelanggan kepada sistem perkhidmatan pelanggan.
Kakitangan perkhidmatan pelanggan menghubungi peminjam (bakal pelanggan) dengan menelefon dalam masa yang sangat singkat (dalam beberapa minit), menyediakan perkhidmatan pelanggan, dan menukar bakal pelanggan menjadi pelanggan sebenar. Kami tahu bahawa peminjaman adalah sensitif masa dan tidak akan bernilai jika ia mengambil masa terlalu lama.
Tanpa keupayaan untuk mengekstrak/mengira/menjatuhkan dalam masa nyata, semua ini tidak akan dapat dilakukan.
Sistem pelaporan masa nyataSatu lagi aplikasi laporan masa nyata adalah seperti berikut:
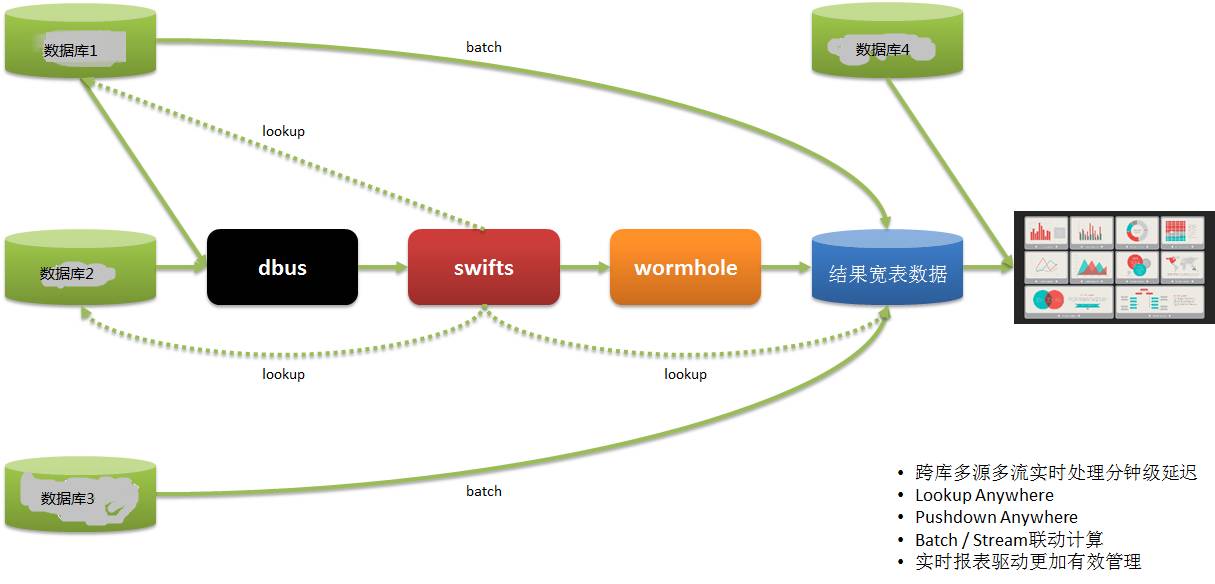
Data pengguna data kami datang daripada berbilang sistem Pada masa lalu, kami menggunakan T+1 untuk mendapatkan maklumat laporan dan kemudian membimbing operasi pada hari berikutnya, yang mengakibatkan ketepatan masa yang buruk.
Melalui DWS, data diekstrak daripada berbilang sistem dalam masa nyata, dikira dan dilaksanakan, dan laporan disediakan, supaya operasi boleh membuat penggunaan dan pelarasan tepat pada masanya serta bertindak balas dengan cepat.
- Teknologi DWS adalah berdasarkan rangka kerja teknologi data besar penstriman masa nyata arus perdana, dengan ketersediaan tinggi, daya pemprosesan yang besar, pengembangan mendatar yang kuat, kependaman rendah dan toleransi kerosakan yang tinggi, dan pada akhirnya konsisten.
- Keupayaan DWS menyokong sistem berbilang sumber dan berbilang sasaran yang heterogen, berbilang format data (data berstruktur, separa berstruktur dan tidak berstruktur) dan keupayaan teknikal masa nyata.
- DWS menggabungkan tiga sub-projek dan melancarkannya sebagai satu platform, memberikan kami keupayaan masa nyata untuk memacu pelbagai aplikasi senario masa nyata.
Senario yang sesuai termasuk: Penyegerakan masa nyata/pengiraan masa nyata/pemantauan masa nyata/pelaporan masa nyata/analisis masa nyata/cerapan masa nyata/pengurusan masa nyata/operasi masa nyata/masa nyata membuat keputusan
S1: Adakah terdapat penyelesaian sumber terbuka untuk pembaca log Oracle?
A1: Terdapat juga banyak penyelesaian komersial untuk industri Oracle, seperti: Oracle GoldenGate (goldengate asal), Oracle Xstream, IBM InfoSphere Change Data Capture (DataMirror asal), Dell SharePlex (Quest asal), DSG superSync Wait domestik , terdapat sangat sedikit penyelesaian sumber terbuka yang mudah digunakan.
S2: Berapa banyak tenaga manusia dan sumber bahan telah dilaburkan dalam projek ini? Rasanya agak rumit.
S2: DWS terdiri daripada tiga sub-projek, dengan purata 5~7 orang bagi setiap projek. Ia agak rumit, tetapi ia sebenarnya adalah percubaan untuk menggunakan teknologi data besar untuk menyelesaikan kesukaran yang sedang dihadapi oleh syarikat kami.
Oleh kerana kami terlibat dalam teknologi berkaitan data besar, semua saudara dan saudari dalam pasukan cukup gembira:)Malah, Dbus dan Wormhole agak tetap dan mudah digunakan semula. Pengkomputeran masa nyata Swifts berkaitan dengan setiap perniagaan, mempunyai penyesuaian yang kukuh dan agak menyusahkan.
S3: Adakah sistem DWS CreditEase akan menjadi sumber terbuka?
A3: Kami juga telah mempertimbangkan untuk menyumbang kepada komuniti Sama seperti projek sumber terbuka Yixin yang lain, projek itu baru sahaja dibentuk dan saya percaya bahawa kami akan membuka sumbernya pada satu masa akan datang.
S4: Bagaimana anda memahami seorang arkitek?
A4: Bukan jurutera sistem Kami mempunyai berbilang arkitek di CreditEase. Mereka harus dianggap sebagai pengurus teknikal yang memacu perniagaan dengan teknologi. Termasuk reka bentuk produk, pengurusan teknikal, dsb.
S5: Adakah skema replikasi OGG?
A5: OGG dan penyelesaian komersial lain yang dinyatakan di atas adalah pilihan.
Sumber artikel: komuniti DBAplus (dbaplus)
Atas ialah kandungan terperinci Pengekstrakan masa nyata dan konsistensi penyegerakan data berasaskan log. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!