

 Peranti teknologiAIMemperkenalkan model MoE sumber terbuka domestik yang besar, prestasinya setanding dengan Llama 2-7B, manakala jumlah pengiraan dikurangkan sebanyak 60%
Peranti teknologiAIMemperkenalkan model MoE sumber terbuka domestik yang besar, prestasinya setanding dengan Llama 2-7B, manakala jumlah pengiraan dikurangkan sebanyak 60%Memperkenalkan model MoE sumber terbuka domestik yang besar, prestasinya setanding dengan Llama 2-7B, manakala jumlah pengiraan dikurangkan sebanyak 60%

Model sumber terbuka MoE akhirnya mengalu-alukan pemain domestik pertamanya!
Prestasinya tidak kalah dengan model Llama 2-7B yang padat, tetapi jumlah pengiraannya hanya 40%.
Model ini boleh dipanggil pahlawan 19 muka, terutamanya menghancurkan Llama dari segi kebolehan matematik dan pengekodan.
Ia adalah model pakar 16 bilion parameter sumber terbuka terbaru DeepSeek MoE oleh pasukan Deep Search.
Selain prestasi cemerlangnya, fokus utama DeepSeek MoE adalah untuk menjimatkan kuasa pengkomputeran.
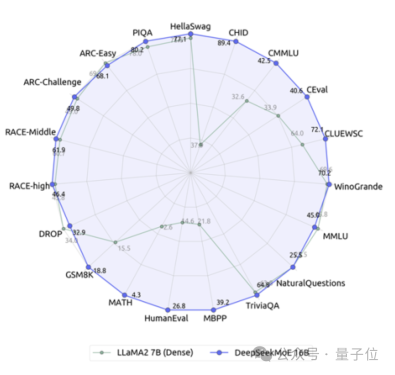
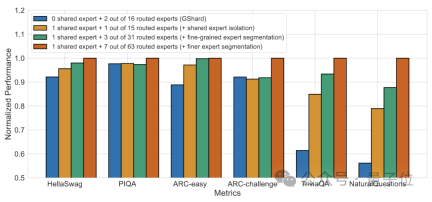
Dalam rajah parameter pengaktifan prestasi ini, ia "menyusun" dan menduduki kawasan kosong yang besar di penjuru kiri sebelah atas.

Hanya sehari selepas dikeluarkan, tweet pasukan DeepSeek di X menerima sejumlah besar tweet semula dan perhatian.
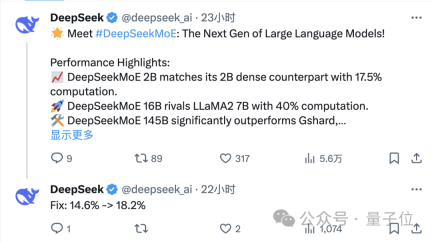
Maxime Labonne, seorang jurutera pembelajaran mesin di JP Morgan, juga berkata selepas menguji bahawa versi sembang DeepSeek MoE berprestasi lebih baik sedikit daripada "model kecil" Microsoft Phi-2.
Pada masa yang sama, DeepSeek MoE turut menerima 300+ bintang di GitHub dan muncul di halaman utama kedudukan model penjanaan teks Hugging Face.
Jadi, apakah prestasi khusus DeepSeek MoE?
Jumlah pengiraan dikurangkan sebanyak 60%
Versi semasa DeepSeek MoE mempunyai 16 bilion parameter, dan bilangan sebenar parameter yang diaktifkan ialah kira-kira 2.8 bilion.
Berbanding dengan model padat 7B kami sendiri, prestasi kedua-duanya pada 19 set data berbeza, tetapi prestasi keseluruhannya agak hampir.
Berbanding dengan Llama 2-7B, yang juga model padat, DeepSeek MoE juga menunjukkan kelebihan yang jelas dalam matematik, kod, dll.
Tetapi beban pengiraan kedua-dua model padat melebihi 180TFLOP setiap token 4k, manakala DeepSeek MoE hanya mempunyai 74.4TFLOP, iaitu hanya 40% daripada kedua-duanya.

Ujian prestasi yang dijalankan pada 2 bilion parameter menunjukkan DeepSeek MoE juga boleh mencapai keputusan yang setara atau lebih baik daripada GShard 2.8B, yang juga model MoE dengan 1.5 kali ganda bilangan parameter dan menggunakan kurang pengiraan.
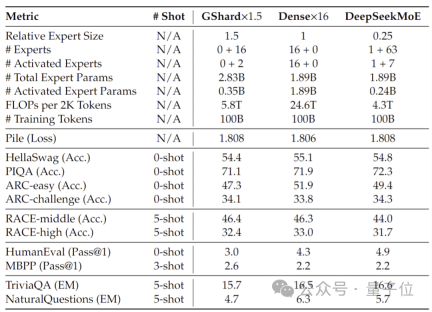
Selain itu, pasukan Deep Seek juga memperhalusi versi Sembang DeepSeek MoE berdasarkan SFT, dan prestasinya juga hampir dengan versi padatnya sendiri dan Llama 2-7B.
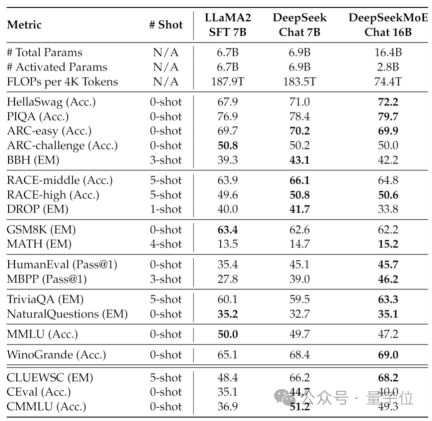
Selain itu, pasukan DeepSeek juga mendedahkan bahawa terdapat juga versi 145B model DeepSeek MoE yang sedang dibangunkan.
Ujian awal berfasa menunjukkan bahawa 145B DeepSeek MoE mempunyai pendahuluan yang besar berbanding GShard 137B, dan boleh mencapai prestasi yang setara dengan versi padat model DeepSeek 67B dengan 28.5% daripada jumlah pengiraan.
Selepas penyelidikan dan pembangunan selesai, pasukan juga akan membuka sumber versi 145B.
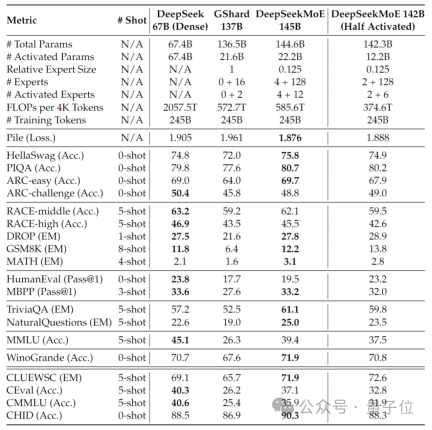
Di sebalik prestasi model-model ini adalah seni bina MoE baharu DeepSeek yang dibangunkan sendiri.
Seni bina baharu KPM yang dibangunkan sendiri
Pertama sekali, berbanding dengan seni bina MoE tradisional, DeepSeek mempunyai bahagian pakar yang lebih terperinci.
Apabila jumlah parameter ditetapkan, model tradisional boleh mengklasifikasikan N pakar, manakala DeepSeek boleh mengklasifikasikan pakar 2N.
Pada masa yang sama, bilangan pakar yang dipilih setiap kali tugasan dilakukan adalah dua kali ganda berbanding model tradisional, jadi bilangan keseluruhan parameter yang digunakan kekal sama, tetapi tahap kebebasan memilih meningkat.
Strategi segmentasi ini membolehkan gabungan pakar pengaktifan yang lebih fleksibel dan adaptif, sekali gus meningkatkan ketepatan model pada tugas yang berbeza dan kepentingan pemerolehan pengetahuan.

Selain daripada perbezaan dalam bahagian pakar, DeepSeek juga secara inovatif memperkenalkan tetapan "pakar kongsi".
Pakar yang dikongsi ini mengaktifkan token untuk semua input dan tidak terjejas oleh modul penghalaan Tujuannya adalah untuk menangkap dan menyepadukan pengetahuan umum yang diperlukan dalam konteks yang berbeza.
Dengan memampatkan pengetahuan yang dikongsi ini kepada pakar yang dikongsi, lebihan parameter dalam kalangan pakar lain dapat dikurangkan, dengan itu meningkatkan kecekapan parameter model.
Tetapan pakar yang dikongsi membantu pakar lain lebih fokus pada bidang pengetahuan unik mereka, dengan itu meningkatkan tahap keseluruhan pengkhususan pakar.
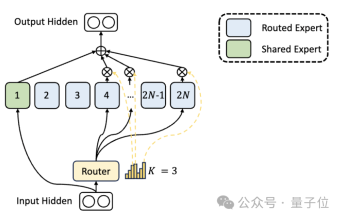
Hasil percubaan ablasi menunjukkan bahawa kedua-dua penyelesaian telah memainkan peranan penting dalam "pengurangan kos dan peningkatan kecekapan" DeepSeek MoE.
Alamat kertas: https://arxiv.org/abs/2401.06066.
Pautan rujukan: https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg.
Atas ialah kandungan terperinci Memperkenalkan model MoE sumber terbuka domestik yang besar, prestasinya setanding dengan Llama 2-7B, manakala jumlah pengiraan dikurangkan sebanyak 60%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AM
Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AMMeneroka kerja -kerja dalam model bahasa dengan skop Gemma Memahami kerumitan model bahasa AI adalah satu cabaran penting. Pelepasan Google Gemma Skop, Toolkit Komprehensif, menawarkan penyelidik cara yang kuat untuk menyelidiki
 Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AM
Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AMMembuka Kejayaan Perniagaan: Panduan untuk Menjadi Penganalisis Perisikan Perniagaan Bayangkan mengubah data mentah ke dalam pandangan yang boleh dilakukan yang mendorong pertumbuhan organisasi. Ini adalah kuasa penganalisis Perniagaan Perniagaan (BI) - peranan penting dalam GU
 Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMPernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AM
Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AMPengenalan Bayangkan pejabat yang sibuk di mana dua profesional bekerjasama dalam projek kritikal. Penganalisis perniagaan memberi tumpuan kepada objektif syarikat, mengenal pasti bidang penambahbaikan, dan memastikan penjajaran strategik dengan trend pasaran. Simu
 Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMPengiraan dan Analisis Data Excel: Penjelasan terperinci mengenai fungsi Count dan Counta Pengiraan dan analisis data yang tepat adalah kritikal dalam Excel, terutamanya apabila bekerja dengan set data yang besar. Excel menyediakan pelbagai fungsi untuk mencapai matlamat ini, dengan fungsi Count dan CountA menjadi alat utama untuk mengira bilangan sel di bawah keadaan yang berbeza. Walaupun kedua -dua fungsi digunakan untuk mengira sel, sasaran reka bentuk mereka disasarkan pada jenis data yang berbeza. Mari menggali butiran khusus fungsi Count dan Counta, menyerlahkan ciri dan perbezaan unik mereka, dan belajar cara menerapkannya dalam analisis data. Gambaran keseluruhan perkara utama Memahami kiraan dan cou
 Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AM
Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AMRevolusi AI Google Chrome: Pengalaman melayari yang diperibadikan dan cekap Kecerdasan Buatan (AI) dengan cepat mengubah kehidupan seharian kita, dan Google Chrome mengetuai pertuduhan di arena pelayaran web. Artikel ini meneroka exciti
 Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AM
Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AMImpak Reimagining: garis bawah empat kali ganda Selama terlalu lama, perbualan telah dikuasai oleh pandangan sempit kesan AI, terutama memberi tumpuan kepada keuntungan bawah. Walau bagaimanapun, pendekatan yang lebih holistik mengiktiraf kesalinghubungan BU
 5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AM
5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AMPerkara bergerak terus ke arah itu. Pelaburan yang dicurahkan ke dalam penyedia perkhidmatan kuantum dan permulaan menunjukkan bahawa industri memahami kepentingannya. Dan semakin banyak kes penggunaan dunia nyata muncul untuk menunjukkan nilainya


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Dreamweaver CS6
Alat pembangunan web visual

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

