
Rumah >Peranti teknologi >AI >Ketahui arahan berbilang modal: AI penjanaan imej Google membolehkan anda mengikuti dengan mudah
Ketahui arahan berbilang modal: AI penjanaan imej Google membolehkan anda mengikuti dengan mudah

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-15 16:33:051085semak imbas
Kini terdapat model penjanaan imej baharu yang direka oleh Google, yang boleh melukis kucing dalam Rajah 1 dalam gaya Rajah 2 dan meletakkan topi padanya. Model ini menggunakan teknologi penalaan halus arahan untuk menjana imej baharu dengan tepat berdasarkan arahan teks dan imej rujukan berbilang. Kesannya sangat baik, setanding dengan master PS secara peribadi membantu anda membuat gambar.

Apabila menggunakan model bahasa besar (LLM), kami telah menyedari kepentingan penalaan halus arahan. Dengan penalaan halus yang sesuai, LLM boleh melaksanakan pelbagai tugas, seperti mengarang puisi, menulis kod, menulis skrip, membantu dalam penyelidikan saintifik, dan juga menjalankan pengurusan pelaburan.
Sekarang model besar telah memasuki era multi-modal, adakah penalaan halus arahan masih berkesan? Sebagai contoh, bolehkah kita memperhalusi kawalan penjanaan imej melalui arahan berbilang modal? Tidak seperti penjanaan bahasa, penjanaan imej melibatkan multimodaliti dari awal. Bolehkah kita membolehkan model memahami kerumitan multimodaliti dengan berkesan?
Untuk menyelesaikan masalah ini, Google DeepMind dan Google Research mencadangkan kaedah arahan pelbagai mod untuk mencapai penjanaan imej. Kaedah ini menjalin maklumat daripada modaliti yang berbeza untuk menyatakan syarat bagi penjanaan imej (contoh ditunjukkan dalam panel kiri Rajah 1).
Arahan berbilang mod boleh meningkatkan arahan bahasa Contohnya, pengguna boleh menentukan gaya imej rujukan untuk menjana model untuk memaparkan imej. Antara muka interaktif intuitif ini membolehkan penetapan keadaan berbilang mod yang cekap untuk tugas penjanaan imej.
Berdasarkan idea ini, pasukan mencipta model penjanaan imej arahan berbilang mod: Instruct-Imagen.

Alamat kertas: https://arxiv.org/abs/2401.01952

Model menggunakan kaedah latihan dua peringkat: mula-mula meningkatkan keupayaan model untuk mengendalikan arahan pelbagai mod, dan kemudian dengan setia mengikuti Niat pengguna pelbagai mod.
Dalam fasa pertama, pasukan itu menggunakan model teks-ke-imej terlatih yang ditugaskan untuk memproses input berbilang modal tambahan kemudiannya memperhalusinya supaya ia boleh bertindak balas dengan tepat kepada arahan berbilang modal. Khususnya, model pra-latihan yang mereka ambil ialah model resapan dan ditambah dengan konteks (imej, teks) yang serupa yang diambil daripada korpus skala rangkaian (imej, teks).
Dalam fasa kedua, pasukan memperhalusi model pada pelbagai tugas penjanaan imej, setiap satunya dipasangkan dengan arahan berbilang modal yang sepadan - arahan ini termasuk elemen utama tugasan masing-masing. Selepas langkah di atas, model Instruct-Imagen yang terhasil boleh mengendalikan input gabungan pelbagai modaliti dengan sangat mahir (seperti lakaran serta gaya visual yang diterangkan dengan arahan teks), supaya ia boleh menjana imej yang sesuai dengan konteks dengan tepat dan cukup terang.
Seperti yang ditunjukkan dalam Rajah 1, Instruct-Imagen berprestasi sangat baik, dapat memahami arahan multi-modal yang kompleks dan menjana imej yang mengikut niat manusia dengan setia, malah mengendalikan gabungan arahan yang belum pernah dilihat sebelum ini.

Maklum balas manusia menunjukkan bahawa dalam banyak keadaan, Instruct-Imagen bukan sahaja memadankan prestasi model khusus tugasan pada tugasan yang sepadan, malah mengatasinya. Bukan itu sahaja, Instruct-Imagen juga menunjukkan keupayaan generalisasi yang kuat dan boleh digunakan untuk tugas penjanaan imej yang tidak kelihatan dan lebih kompleks.
Arahan berbilang mod untuk penjanaan
Model pra-latihan yang digunakan oleh pasukan adalah model penyebaran dan pengguna boleh menetapkan syarat input untuknya. Sila rujuk kertas asal untuk butiran.
Untuk arahan multi-modal, untuk memastikan fleksibiliti dan keupayaan generalisasi, pasukan mencadangkan format pengajaran multi-modal bersatu, di mana peranan bahasa adalah untuk menyatakan dengan jelas matlamat tugas, dan keadaan pelbagai mod digunakan sebagai maklumat rujukan.
Format arahan yang baru dicadangkan ini mengandungi dua komponen utama: (1) Perintah teks muatan, yang berperanan untuk menerangkan matlamat tugasan secara terperinci dan memberikan pengenalan maklumat rujukan, seperti [ref#?]. (2) Konteks multimodal dengan berpasangan (logo + teks, imej). Model kemudian menggunakan model pemahaman arahan yang dikongsi untuk mengendalikan arahan teks dan konteks multimodal—modaliti khusus konteks tidak terhad di sini.
Rajah 2 menunjukkan bagaimana format ini boleh mewakili pelbagai tugas generasi terdahulu melalui tiga contoh, yang menunjukkan bahawa format ini boleh serasi dengan tugas penjanaan imej sebelumnya. Lebih penting lagi, bahasa itu fleksibel, jadi arahan multimodal boleh dilanjutkan untuk tugasan baharu tanpa sebarang reka bentuk khas untuk modaliti dan tugasan.

Instruct-Imagen
Instruct-Imagen adalah berdasarkan arahan multi-modal. Berdasarkan ini, pasukan mereka bentuk seni bina model berdasarkan model resapan teks-ke-imej yang telah terlatih, iaitu model resapan bertingkat, supaya ia boleh mengguna pakai sepenuhnya syarat arahan berbilang mod input.
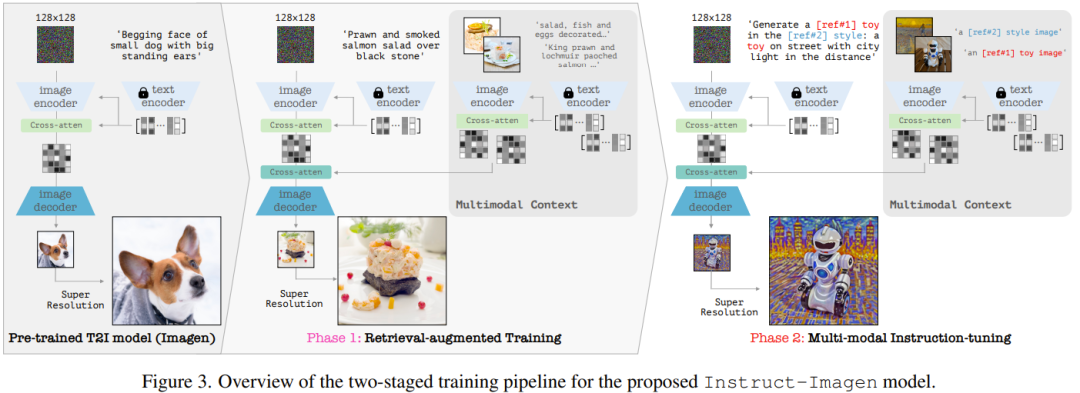
Secara khusus, mereka menggunakan varian Imagen, lihat kertas kerja "Model penyebaran teks-ke-imej fotorealistik dengan pemahaman bahasa yang mendalam", dan dilatih berdasarkan sumber data dalaman mereka. Model lengkapnya mengandungi dua sub-komponen: (1) komponen teks-ke-imej, yang tugasnya menjana imej resolusi 128×128 menggunakan gesaan teks sahaja; (2) model resolusi super bersyarat teks, yang boleh menukar resolusi 128 imej ke dalam Naik taraf kepada resolusi 1024.
Bagi pengekodan arahan berbilang modal, lihat Rajah 3 (kanan), yang menunjukkan aliran data arahan berbilang mod pengekodan Instruct-Imagen.
Latihan Instruct-Imagen dengan kaedah dua peringkat
Proses latihan Instruct-Imagen terbahagi kepada dua peringkat.
Peringkat pertama ialah latihan teks-ke-imej yang dipertingkatkan, yang menggunakan pasangan jiran (imej, teks) yang dipertingkatkan untuk meneruskan latihan penjanaan teks-ke-imej.
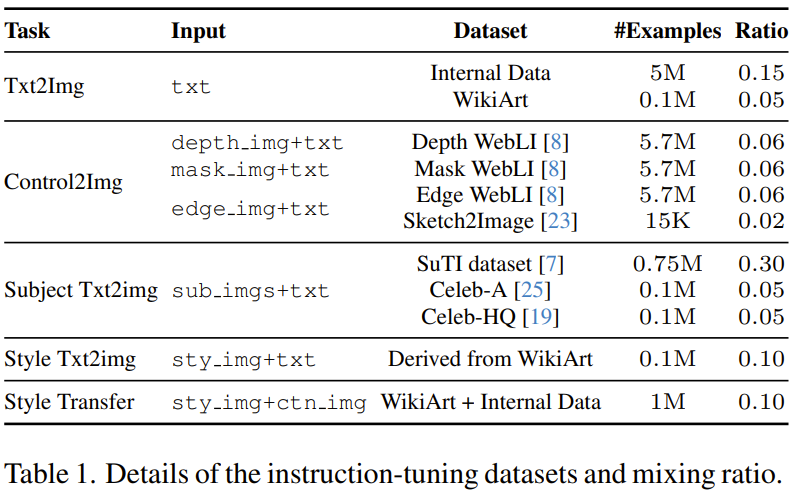
Peringkat kedua adalah untuk memperhalusi model keluaran peringkat pertama, yang akan menggunakan campuran pelbagai tugas penjanaan imej, setiap satunya dipasangkan dengan arahan berbilang modal yang sepadan. Khususnya, pasukan menggunakan 11 imej merentas 5 kategori tugasan untuk menjana set data, lihat Jadual 1.
Dalam kedua-dua peringkat latihan, model ini dioptimumkan dari hujung ke hujung.
Eksperimen
Pasukan menjalankan penilaian percubaan kaedah dan model yang baru dicadangkan, dan menjalankan analisis mendalam tentang reka bentuk dan mod kegagalan Instruct-Imagen.
Tetapan Eksperimen
Pasukan menilai model dalam dua tetapan, iaitu penilaian tugasan dalam domain dan penilaian tugasan sifar, di mana tetapan terakhir lebih mencabar daripada tetapan sebelumnya.
Keputusan Utama
Rajah 4 membandingkan Arahan-Imej dengan kaedah asas dan kaedah sebelumnya, dan keputusan menunjukkan bahawa ia adalah setanding dengan kaedah sebelumnya dalam penilaian domain dan penilaian sampel sifar.
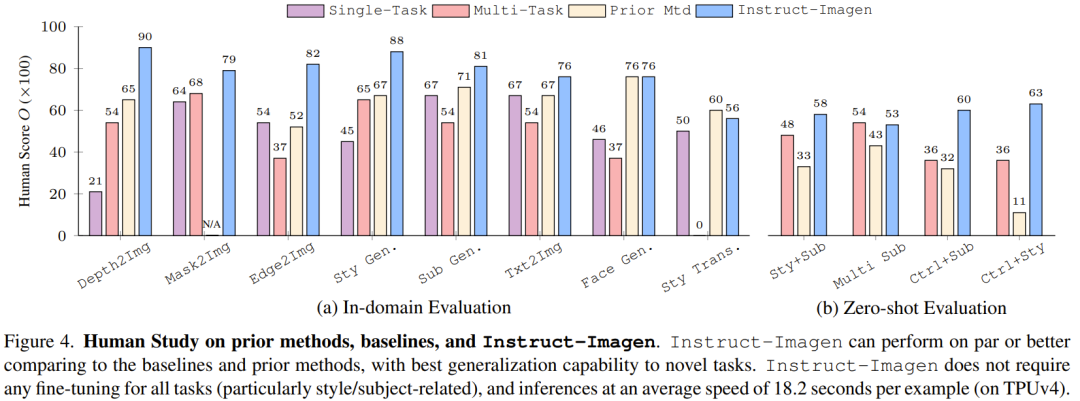
Ini menunjukkan bahawa latihan dengan arahan multimodal boleh meningkatkan prestasi model pada tugasan dengan data latihan terhad (seperti penjanaan penggayaan), sambil mengekalkan prestasi pada tugas yang kaya dengan data (seperti menjana imej seperti foto) Kesan. Tanpa latihan arahan berbilang modal, penanda aras berbilang tugas cenderung menghasilkan kualiti imej dan penjajaran teks yang lemah.
Sebagai contoh, dalam contoh penggayaan dalam konteks dalam Rajah 5, penanda aras berbilang tugas mengalami kesukaran membezakan gaya daripada objek, jadi objek dihasilkan semula dalam hasil yang dijana. Atas sebab yang sama, ia juga berprestasi buruk pada tugas pemindahan gaya. Pemerhatian ini menyerlahkan nilai penalaan halus arahan.
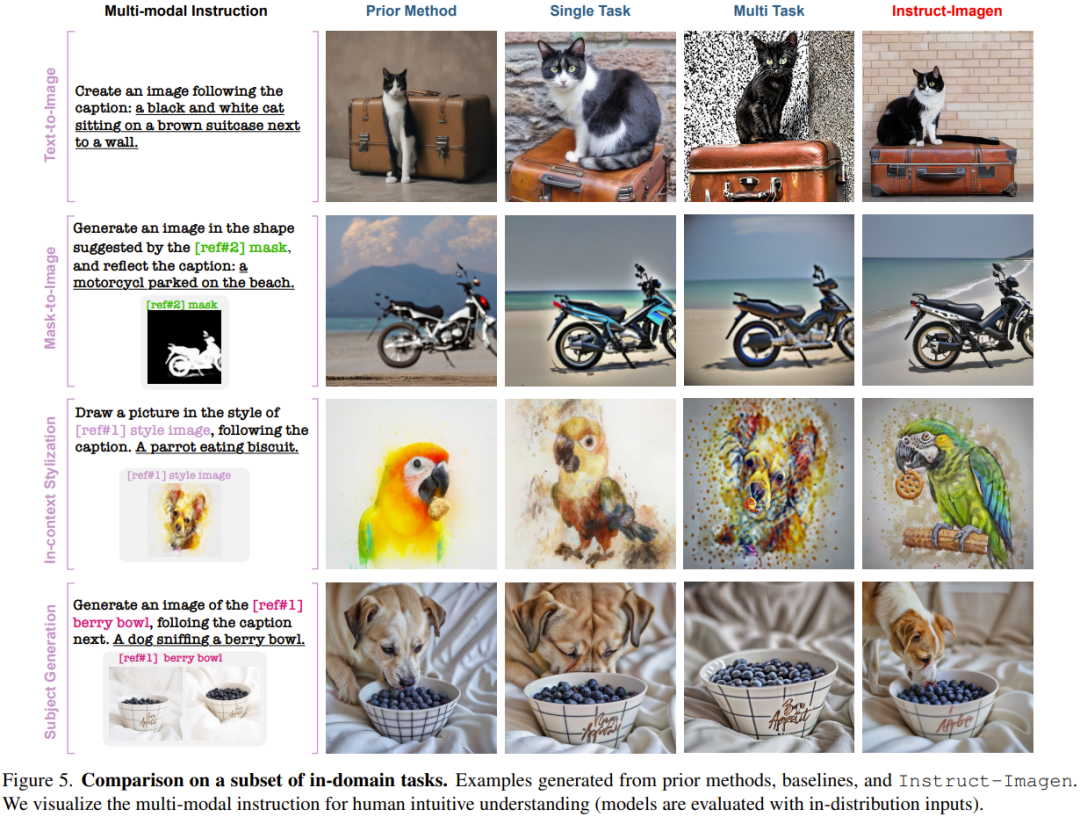
Tidak seperti kaedah atau latihan semasa yang bergantung pada tugasan tertentu, Instruct-Imagen boleh menguruskan tugasan gabungan dengan cekap (tanpa penalaan halus, seperti contoh) dengan memanfaatkan arahan yang menggabungkan matlamat tugasan yang berbeza dan melaksanakan penaakulan dalam konteks mengambil masa 18.2 saat).
Seperti yang ditunjukkan dalam Rajah 6, Instruct-Imagen sentiasa mengatasi model lain dari segi arahan mengikut dan kualiti output.

Bukan itu sahaja, apabila terdapat berbilang rujukan dalam konteks berbilang modal, model garis dasar berbilang tugas tidak boleh sepadan dengan arahan teks dengan rujukan, menyebabkan beberapa syarat berbilang modal diabaikan. Keputusan ini menunjukkan lagi keberkesanan model yang baru dicadangkan.
Analisis Model dan Kajian Ablasi
Pasukan menganalisis had dan mod kegagalan model.
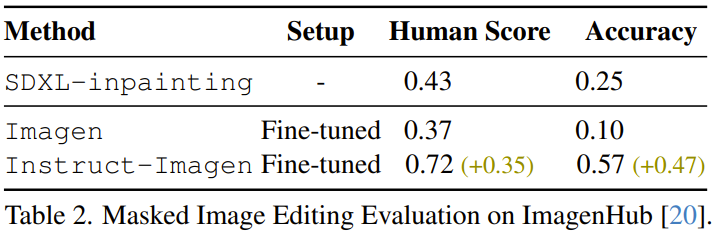
Sebagai contoh, pasukan mendapati bahawa Instruct-Imagen yang diperhalusi boleh mengedit imej. Seperti yang ditunjukkan dalam Jadual 2, dengan membandingkan pengecatan SDXL sebelumnya, Imagen yang ditala halus pada dataset MagicBrush dan Instruct-Imagen yang ditala halus, boleh didapati bahawa Instruct-Imagen yang ditala halus adalah jauh lebih baik daripada satu yang direka khusus untuk pengeditan imej berasaskan topeng.
Walau bagaimanapun, Instruct-Imagen yang diperhalusi menghasilkan artifak dalam imej yang diedit, terutamanya output resolusi tinggi selepas langkah resolusi super, seperti yang ditunjukkan dalam Rajah 7. Para penyelidik mengatakan ini kerana model itu sebelum ini tidak belajar untuk menyalin piksel secara tepat terus dari konteks.

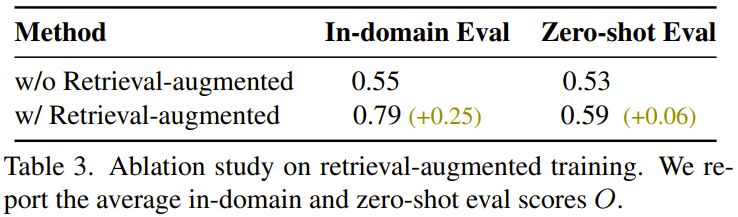
Pasukan juga mendapati bahawa latihan yang dipertingkatkan dapat membantu meningkatkan keupayaan generalisasi, dan hasilnya ditunjukkan dalam Jadual 3.
Mengenai mod kegagalan Instruct-Imagen, penyelidik mendapati bahawa apabila arahan multi-modal lebih kompleks (sekurang-kurangnya 3 keadaan multi-modal), Instruct-Imagen mengalami kesukaran menjana hasil yang mematuhi arahan. Rajah 8 memberikan dua contoh.

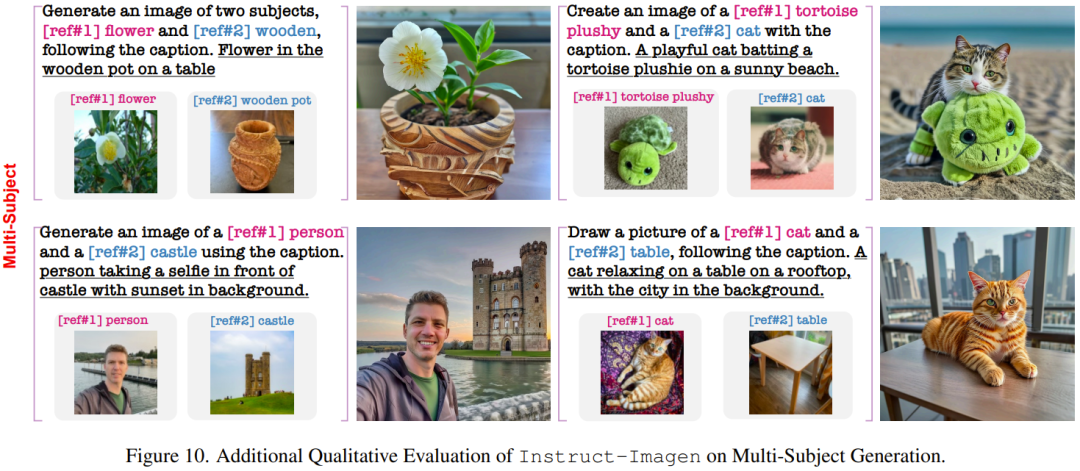
Berikut menunjukkan beberapa keputusan mengenai tugas kompleks yang belum dilihat semasa latihan.


Pasukan juga menjalankan kajian ablasi untuk membuktikan kepentingan komponen reka bentuknya.
Walau bagaimanapun, disebabkan kebimbangan keselamatan, Google belum mengeluarkan kod dan API penyelidikan ini lagi.
Sila rujuk kertas asal untuk butiran lanjut.
Atas ialah kandungan terperinci Ketahui arahan berbilang modal: AI penjanaan imej Google membolehkan anda mengikuti dengan mudah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 人工智能产业链包括
- Peraturan baharu untuk bulan Oktober ada di sini! Melibatkan papan tanda lalu lintas jalan baharu, industri kecerdasan buatan, dsb.
- Tesla merancang untuk menubuhkan sebuah kilang kenderaan elektrik di India untuk mengaktifkan industri kenderaan elektrik India
- Baidu melancarkan model perubatan 'peringkat industri' pertama China 'Model Perubatan Rohani': Baidu melancarkan model perubatan 'peringkat industri' pertama China 'Model Perubatan Rohani'
- Mari kita bina Guangxi digital bersama-sama dan pergi ke masa depan digital bersama-sama! Persidangan Ekologi Industri Kepintaran Buatan Guangxi Kunpeng Shengteng 2023 telah berjaya diadakan