
Rumah >Tutorial sistem >LINUX >Optimumkan kecekapan capaian data HDFS: gunakan haba dan kesejukan data untuk mengurus
Optimumkan kecekapan capaian data HDFS: gunakan haba dan kesejukan data untuk mengurus

- 王林ke hadapan
- 2024-01-15 09:18:151477semak imbas
Pengenalan tema:
- Penjelasan fungsi storan dioptimumkan HDFS
- Reka bentuk seni bina sistem SSM
- Analisis senario aplikasi sistem SSM
Pada permulaan pembangunan data besar, senario aplikasi utama masih dalam senario pemprosesan kelompok luar talian, dan permintaan untuk storan adalah mengejar daya pemprosesan HDFS telah direka untuk senario sedemikian, dan dengan pembangunan teknologi yang berterusan, Lagi dan lebih banyak senario akan mengemukakan permintaan baharu pada storan, dan HDFS juga menghadapi cabaran baharu. Ia terutamanya merangkumi beberapa aspek:
1. Masalah kelantangan data Di satu pihak, dengan pertumbuhan perniagaan dan akses aplikasi baharu, lebih banyak data akan dibawa ke HDFS Sebaliknya, dengan pembangunan pembelajaran mendalam, kecerdasan buatan dan teknologi lain, pengguna biasanya berharap untuk menjimatkan data. untuk tempoh masa yang lebih lama, untuk meningkatkan kesan pembelajaran mendalam. Peningkatan pesat dalam jumlah data akan menyebabkan kluster menghadapi keperluan pengembangan secara berterusan, menyebabkan kos penyimpanan meningkat.
2. Masalah fail kecil Seperti yang kita semua tahu, HDFS direka untuk pemprosesan kumpulan luar talian bagi fail besar Memproses fail kecil bukanlah senario yang dikuasai oleh HDFS tradisional. Punca masalah fail kecil HDFS ialah maklumat metadata fail dikekalkan dalam memori Namenode tunggal, dan ruang memori mesin tunggal sentiasa terhad. Dianggarkan bilangan maksimum fail sistem yang boleh ditampung oleh gugusan namenode tunggal ialah kira-kira 150 juta. Malah, platform HDFS biasanya berfungsi sebagai platform storan asas untuk menyediakan pelbagai rangka kerja pengkomputeran lapisan atas dan berbilang senario perniagaan, jadi masalah fail kecil tidak dapat dielakkan dari perspektif perniagaan. Pada masa ini terdapat penyelesaian seperti HDFS-Federation untuk menyelesaikan masalah skalabiliti satu titik Namenode, tetapi pada masa yang sama ia juga akan membawa kesukaran besar dalam pengurusan operasi dan penyelenggaraan.
3. Masalah data panas dan sejuk Memandangkan jumlah data terus berkembang dan terkumpul, data juga akan menunjukkan perbezaan besar dengan populariti akses yang berbeza. Sebagai contoh, platform akan terus menulis data terkini, tetapi biasanya data yang ditulis baru-baru ini akan diakses dengan lebih kerap daripada data yang ditulis lama dahulu. Jika strategi storan yang sama digunakan tanpa mengira sama ada data itu panas atau sejuk, ia adalah pembaziran sumber kluster.
Cara mengoptimumkan sistem storan HDFS berdasarkan kepanasan dan kesejukan data adalah masalah segera yang perlu diselesaikan.
2. Teknologi pengoptimuman HDFS sedia ada Sudah lebih 10 tahun sejak kelahiran Hadoop Dalam tempoh ini, teknologi HDFS itu sendiri telah terus dioptimumkan dan berkembang. HDFS mempunyai beberapa teknologi sedia ada yang boleh menyelesaikan beberapa masalah di atas pada tahap tertentu. Berikut ialah pengenalan ringkas kepada storan heterogen HDFS dan teknologi pengekodan pemadaman HDFS.Storan heterogen HDFS: Hadoop menyokong fungsi storan heterogen bermula dari versi 2.6.0. Kami tahu bahawa strategi storan lalai HDFS menggunakan tiga salinan setiap blok data dan menyimpannya pada cakera pada nod yang berbeza. Peranan storan heterogen adalah untuk menggunakan pelbagai jenis media storan pada pelayan (termasuk cakera keras HDD, SSD, memori, dll.) untuk menyediakan lebih banyak strategi storan (contohnya, tiga salinan, satu disimpan dalam media SSD, dan baki dua masih disimpan dalam cakera keras HDD), sekali gus menjadikan storan HDFS lebih fleksibel dan cekap dalam bertindak balas kepada pelbagai senario aplikasi.
Pelbagai storan disokong yang dipratentukan dalam HDFS termasuk:
- ARKIB: Media storan dengan ketumpatan storan yang tinggi tetapi penggunaan kuasa yang rendah, seperti pita, biasanya digunakan untuk menyimpan data sejuk
- DISK: Media cakera, ini adalah medium storan terawal yang disokong oleh HDFS
- SSD: Pemacu keadaan pepejal ialah jenis media storan baharu yang kini digunakan oleh banyak syarikat Internet
- RAM_DISK: Data ditulis ke dalam memori, dan salinan lain akan ditulis (secara tidak segerak) ke medium storan pada masa yang sama
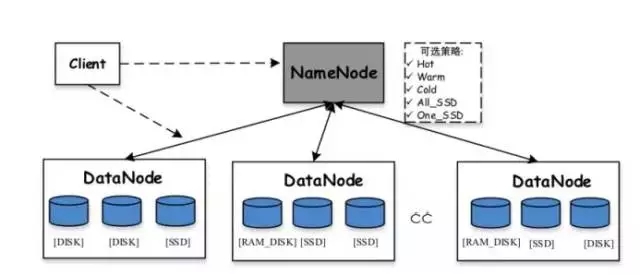
- Lazy_persist: Satu salinan disimpan dalam memori RAM_DISK dan baki salinan disimpan dalam cakera
- ALL_SSD: Semua salinan disimpan dalam SSD
-
One_SSD: Satu salinan disimpan dalam SSD dan baki salinan disimpan dalam cakera
-
Panas: Semua salinan disimpan pada cakera, yang juga merupakan dasar storan lalai
-
Suam: Satu salinan disimpan pada cakera dan baki salinan disimpan pada storan arkib
-
Sejuk: Semua salinan disimpan dalam simpanan arkib
Secara umumnya, nilai storan heterogen HDFS terletak pada penggunaan strategi yang berbeza mengikut kepopularan data untuk meningkatkan kecekapan penggunaan sumber keseluruhan kluster. Untuk data yang kerap diakses, simpan semua atau sebahagian daripadanya pada media storan (memori atau SSD) dengan prestasi capaian yang lebih tinggi untuk meningkatkan prestasi baca dan tulis bagi data yang jarang diakses, simpan pada media storan arkib untuk mengurangkan bacaan dan tulisnya prestasi. Walau bagaimanapun, konfigurasi storan heterogen HDFS memerlukan pengguna untuk menentukan dasar yang sepadan untuk direktori, iaitu, pengguna perlu mengetahui populariti akses fail dalam setiap direktori terlebih dahulu Dalam aplikasi platform data besar yang sebenar, ini lebih sukar.
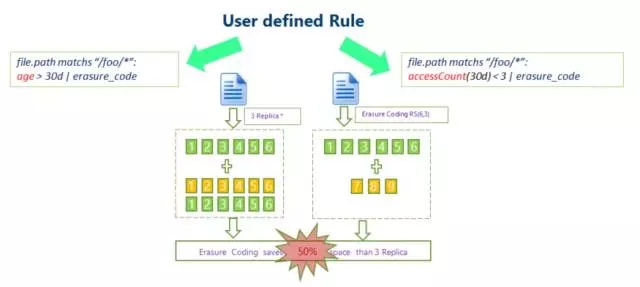
Kod Pemadaman HDFS:Data HDFS tradisional menggunakan mekanisme tiga salinan untuk memastikan kebolehpercayaan data Iaitu, untuk setiap 1TB data yang disimpan, data sebenar yang diduduki pada setiap nod kluster mencapai 3TB, dengan overhed tambahan sebanyak 200%. Ini memberi tekanan besar pada storan cakera nod dan penghantaran rangkaian.
Hadoop 3.0 mula memperkenalkan sokongan untuk pengekodan pemadaman peringkat blok fail HDFS, dan lapisan asas menggunakan algoritma Reed-Solomon (k, m). RS ialah algoritma pengekodan pemadaman yang biasa digunakan Melalui operasi matriks, digit semakan m-bit boleh dijana untuk data k-bit Bergantung pada nilai k dan m, tahap toleransi kesalahan boleh dicapai kaedah yang agak fleksibel.
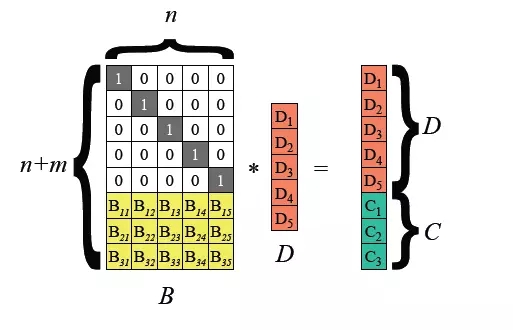
Algoritma biasa ialah RS(3,2), RS(6,3), RS(10,4), blok fail k dan blok semakan m membentuk kumpulan, dan mana-mana blok data m boleh diterima dalam kumpulan kehilangan ini.
Teknologi pengekodan pemadaman HDFS boleh mengurangkan lebihan storan data Mengambil RS(3,2) sebagai contoh, lebihan datanya ialah 67%, yang sangat berkurangan berbanding 200% lalai Hadoop. Walau bagaimanapun, teknologi pengekodan pemadaman memerlukan penggunaan CPU untuk pengiraan untuk penyimpanan data dan pemulihan data Ia sebenarnya merupakan pilihan pertukaran masa untuk ruang Oleh itu, senario yang lebih sesuai ialah penyimpanan data sejuk. Data yang disimpan dalam data sejuk selalunya tidak diakses untuk masa yang lama selepas ditulis sekali Dalam kes ini, teknologi pengekodan pemadaman boleh digunakan untuk mengurangkan bilangan salinan. 3 Pengoptimuman storan data besar: SSM
Sama ada storan heterogen HDFS atau teknologi pengekodan pemadaman yang diperkenalkan sebelum ini, premisnya ialah pengguna perlu menentukan gelagat storan untuk data tertentu, yang bermaksud pengguna perlu mengetahui data yang mana data panas dan data sejuk. Jadi adakah cara untuk mengoptimumkan storan secara automatik?Jawapannya ialah ya Sistem SSM (Pengurusan Storan Pintar) yang diperkenalkan di sini memperoleh maklumat metadata daripada storan asas (biasanya HDFS), dan memperoleh status haba data melalui analisis maklumat akses baca dan tulis, menyasarkan data dengan tahap haba yang berbeza. mengikut satu siri peraturan yang telah ditetapkan, mengguna pakai strategi pengoptimuman storan yang sepadan untuk meningkatkan kecekapan keseluruhan sistem storan. SSM ialah projek sumber terbuka yang diketuai oleh Intel, dan China Mobile turut mengambil bahagian dalam penyelidikan dan pembangunannya Projek ini boleh didapati di Github: https://github.com/Intel-bigdata/SSM.
Penempatan SSM ialah sistem pengoptimuman persisian storan yang menggunakan seni bina Pelayan-Agen-Pelanggan secara keseluruhan Pelayan bertanggungjawab untuk pelaksanaan logik keseluruhan SSM, Ejen digunakan untuk melaksanakan pelbagai operasi pada kluster storan, dan Pelanggan ialah akses data yang diberikan kepada pengguna, biasanya termasuk antara muka HDFS asli.
Rangka kerja utama SSM-Server ditunjukkan dalam rajah di atas Dari atas ke bawah, StatesManager berinteraksi dengan kluster HDFS untuk mendapatkan maklumat metadata HDFS dan mengekalkan maklumat haba akses setiap fail. Maklumat dalam StatesManager akan disimpan ke pangkalan data hubungan. TiDB digunakan sebagai pangkalan data storan asas dalam SSM. RuleManager mengekalkan dan mengurus maklumat berkaitan peraturan Pengguna menentukan satu siri peraturan storan untuk SSM melalui antara muka hadapan dan RuleManger bertanggungjawab untuk menghuraikan dan melaksanakan peraturan. CacheManager/StorageManager menjana tugas tindakan khusus berdasarkan populariti dan peraturan. ActionExecutor bertanggungjawab untuk tugas tindakan tertentu, memberikan tugas kepada Ejen dan melaksanakannya pada nod Ejen. 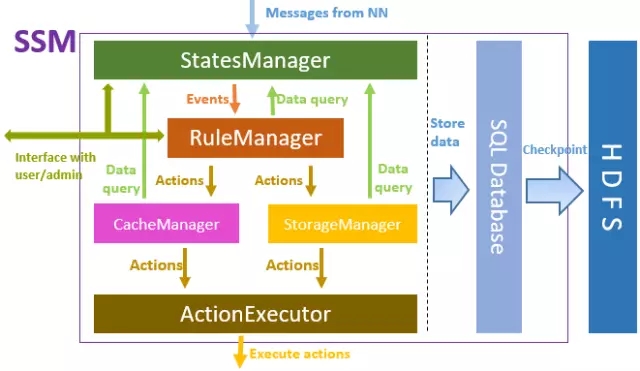
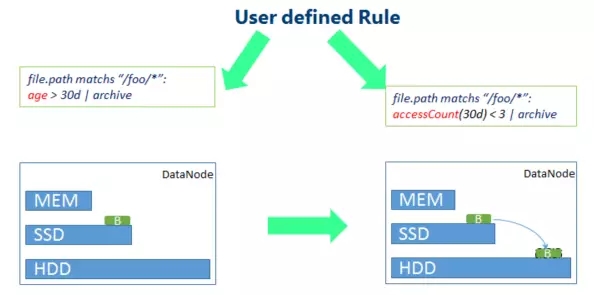
Pelaksanaan logik dalaman SSM-Server bergantung pada definisi peraturan, yang memerlukan pentadbir untuk merumuskan satu siri peraturan untuk sistem SSM melalui halaman web bahagian hadapan. Peraturan terdiri daripada beberapa bahagian: 
- Objek operasi biasanya merujuk kepada fail yang memenuhi syarat tertentu.
- Pencetus merujuk kepada titik masa apabila peraturan dicetuskan, seperti pencetus yang dijadualkan setiap hari.
- Syarat pelaksanaan, tentukan satu siri syarat berdasarkan populariti, seperti keperluan kiraan akses fail dalam tempoh masa.
- Laksanakan operasi, lakukan operasi berkaitan pada data yang memenuhi syarat pelaksanaan, biasanya menyatakan strategi penyimpanannya, dsb.
Contoh peraturan sebenar:
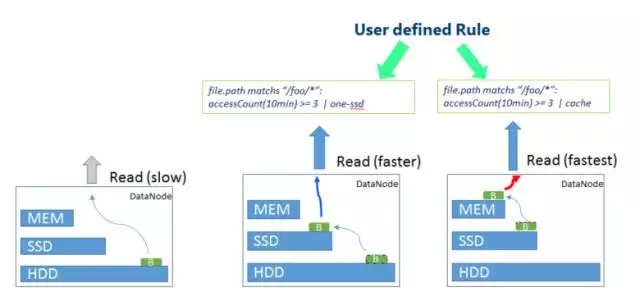
file.path sepadan dengan ”/foo/*”: accessCount(10min) >= 3 |
Peraturan ini bermakna bahawa untuk fail dalam direktori /foo, jika ia diakses tidak kurang daripada tiga kali dalam masa 10 minit, strategi storan Satu-SSD akan diguna pakai, iaitu, satu salinan data akan disimpan pada SSD , dan baki 2 salinan akan digunakan pada cakera biasa.4. Senario aplikasi SSM SSM boleh menggunakan strategi penyimpanan yang berbeza untuk mengoptimumkan kepanasan dan kesejukan data Berikut adalah beberapa senario aplikasi biasa:

Perlu juga dinyatakan bahawa SSM juga mempunyai kaedah pengoptimuman yang sepadan untuk fail kecil. Ciri ini masih dalam proses pembangunan. Logik umum ialah SSM akan menggabungkan satu siri fail kecil pada HDFS ke dalam fail besar Pada masa yang sama, hubungan pemetaan antara fail kecil asal dan fail besar yang digabungkan dan lokasi setiap fail kecil dalam fail besar akan menjadi. direkodkan dalam metadata SSM. Apabila pengguna perlu mengakses fail kecil, fail kecil asal diperoleh daripada fail yang digabungkan melalui klien khusus SSM (SmartClient) berdasarkan maklumat pemetaan fail kecil dalam metadata SSM.
Akhir sekali, SSM adalah projek sumber terbuka dan masih dalam proses evolusi berulang yang sangat pesat. Mana-mana rakan yang berminat dialu-alukan untuk menyumbang kepada pembangunan projek.
S&J
S1: Apakah skala yang harus kita mulakan apabila membina HDFS sendiri?
A1: HDFS menyokong mod pengedaran pseudo Walaupun hanya terdapat satu nod, anda boleh membina sistem HDFS. Jika anda ingin mengalami dan memahami seni bina HDFS yang diedarkan dengan lebih baik, adalah disyorkan untuk membina persekitaran dengan 3 hingga 5 nod.
S2: Adakah Su Yan menggunakan SSM dalam platform data besar sebenar setiap wilayah?
A2: Projek ini masih berkembang pesat Ia akan digunakan secara beransur-ansur dalam pengeluaran selepas ujian stabil.
S3: Apakah perbezaan antara HDFS dan Spark? Apakah kebaikan dan keburukan?
A3: HDFS dan Spark bukanlah teknologi pada tahap yang sama ialah sistem storan, manakala Spark ialah enjin pengkomputeran. Perkara yang sering kita bandingkan dengan Spark ialah rangka kerja pengkomputeran Mapreduce dalam Hadoop dan bukannya sistem storan HDFS. Dalam pembinaan projek sebenar, HDFS dan Spark biasanya mempunyai hubungan kerjasama HDFS digunakan untuk storan asas dan Spark digunakan untuk pengkomputeran peringkat atas.
Atas ialah kandungan terperinci Optimumkan kecekapan capaian data HDFS: gunakan haba dan kesejukan data untuk mengurus. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!