
Rumah >Peranti teknologi >AI >NVIDIA, Mila dan Caltech bersama-sama mengeluarkan model teks struktur molekul multimodal yang menggabungkan LLM dengan penemuan dadah
NVIDIA, Mila dan Caltech bersama-sama mengeluarkan model teks struktur molekul multimodal yang menggabungkan LLM dengan penemuan dadah

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-14 20:00:05891semak imbas

Pengarang |. Liu Shengchao
Editor |.
Dengan pembangunan model besar dan aplikasi pelbagai mod, bolehkah kita menggunakan teknik ini untuk penemuan dadah? Dan, bolehkah huraian tekstual bahasa semula jadi ini membawa perspektif baharu kepada masalah yang mencabar ini? Jawapannya ya, dan kami optimis mengenainya
Baru-baru ini, pasukan penyelidik dari Montreal Institute for Learning Algorithm (Mila) di Kanada, NVIDIA Research, University of Illinois di Urbana-Champaign (UIUC), Princeton University dan California Institut Teknologi , model teks struktur molekul multimodal MoleculeSTM dicadangkan dengan mempelajari secara bersama struktur kimia dan penerangan teks molekul melalui strategi pembelajaran kontrastif.
Penyelidikan ini bertajuk "Model struktur molekul berbilang modal–model teks untuk pengambilan dan penyuntingan berasaskan teks" dan telah diterbitkan dalam "Nature Machine Intelligence" pada 18 Disember 2023.
 Pautan kertas: https://www.nature.com/articles/s42256-023-00759-6 perlu ditulis semula
Pautan kertas: https://www.nature.com/articles/s42256-023-00759-6 perlu ditulis semula
Dr. Liu Shengchao ialah pengarang pertama, dan Profesor Anima Anandkumar dari NVIDIA Research pengarang yang sepadan. Nie Weili, Wang Chengpeng, Lu Jiarui, Qiao Zhuoran, Liu Ling, Tang Jian dan Xiao Chaowei ialah pengarang bersama.
Projek ini telah dijalankan oleh Dr Liu Shengchao selepas menyertai NVIDIA Research pada Mac 2022, di bawah bimbingan Teachers Nie Weili, Teacher Tang Jian, Teacher Xiao Chaowei dan Teacher Anima Anandkumar.
Dr. Liu Shengchao berkata: "Motivasi kami adalah untuk menjalankan penerokaan awal LLM dan penemuan dadah, dan akhirnya mencadangkan MoleculeSTM
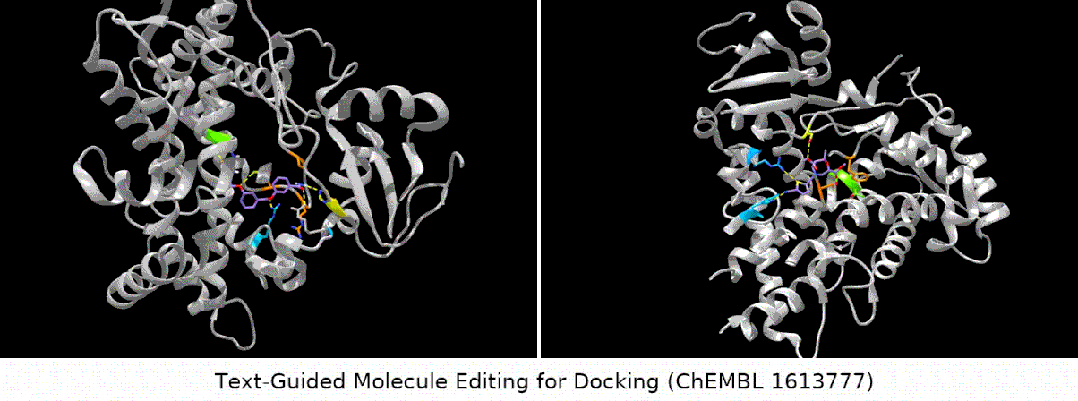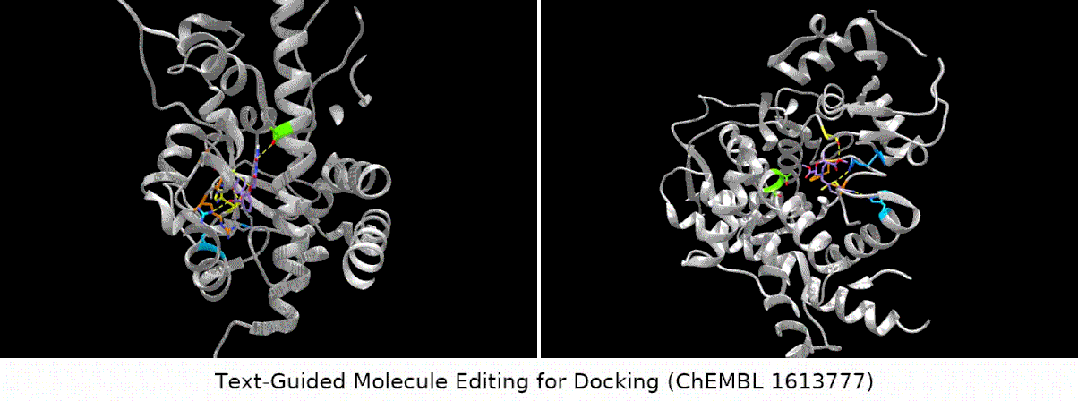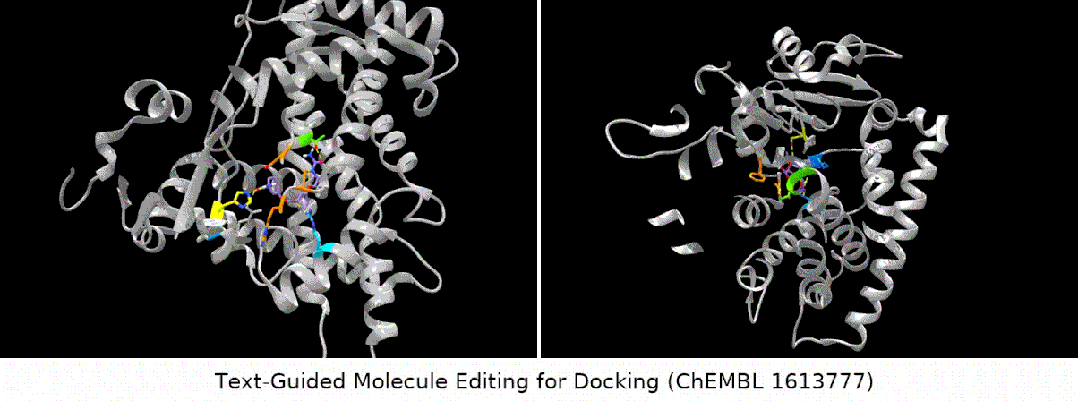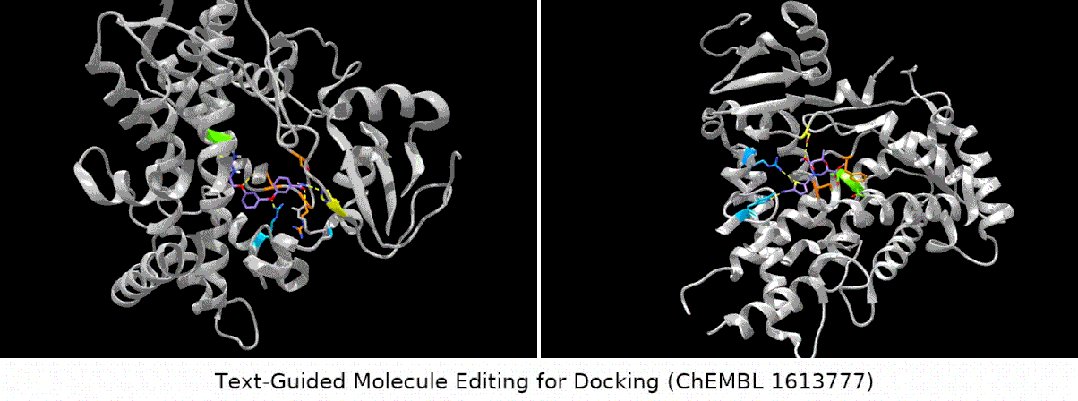 Teks yang digunakan untuk dok direka untuk membimbing penyuntingan molekul Molekul." adalah sangat mudah dan mudah, iaitu, perihalan molekul boleh dibahagikan kepada dua kategori: struktur kimia dalaman dan penerangan fungsi luaran. Di sini kami menggunakan kaedah pra-latihan kontras untuk menyelaraskan dan menghubungkan kedua-dua jenis maklumat ini. Rajah khusus ditunjukkan dalam rajah di bawah
Teks yang digunakan untuk dok direka untuk membimbing penyuntingan molekul Molekul." adalah sangat mudah dan mudah, iaitu, perihalan molekul boleh dibahagikan kepada dua kategori: struktur kimia dalaman dan penerangan fungsi luaran. Di sini kami menggunakan kaedah pra-latihan kontras untuk menyelaraskan dan menghubungkan kedua-dua jenis maklumat ini. Rajah khusus ditunjukkan dalam rajah di bawah
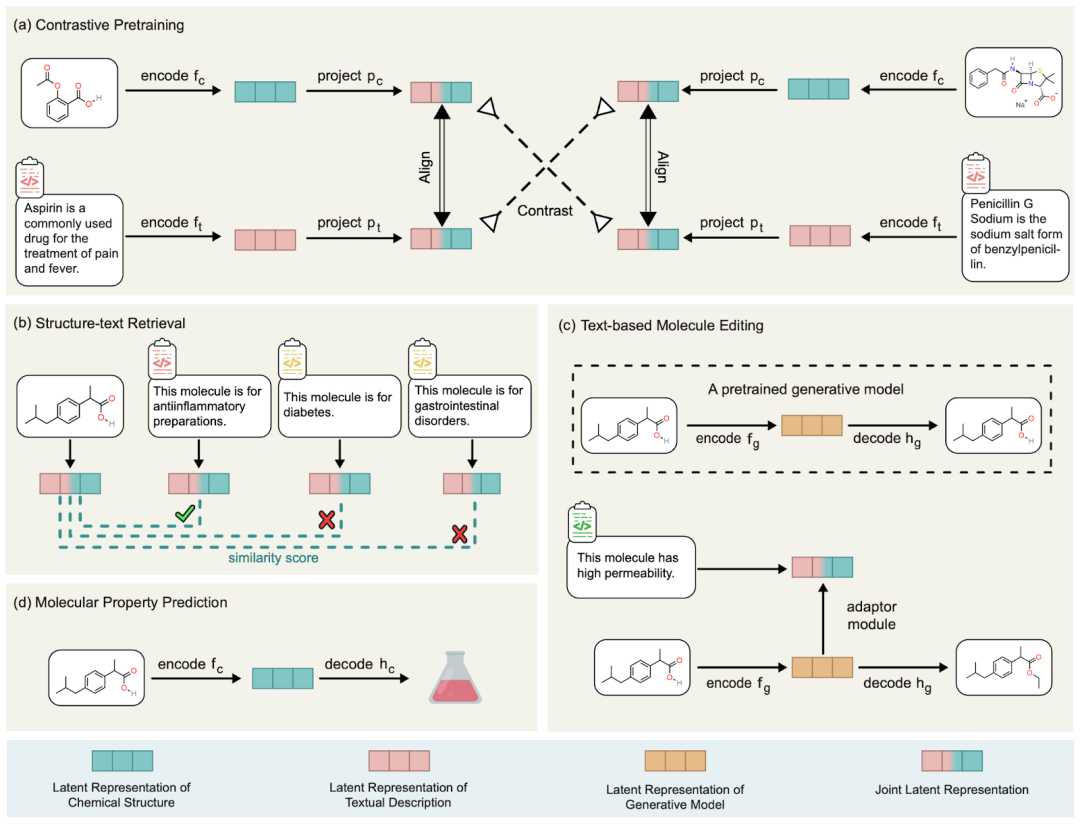 Dan penjajaran MoleculeSTM ini mempunyai sifat yang sangat baik: apabila terdapat beberapa tugasan yang sukar diselesaikan dalam ruang kimia, kita boleh memindahkannya ke ruang bahasa semula jadi. Dan tugas bahasa semula jadi akan lebih mudah diselesaikan kerana ciri-cirinya. Berdasarkan ini, kami mereka bentuk pelbagai jenis tugas hiliran untuk mengesahkan keberkesanannya. Di bawah ini kita membincangkan beberapa pandangan secara terperinci.
Dan penjajaran MoleculeSTM ini mempunyai sifat yang sangat baik: apabila terdapat beberapa tugasan yang sukar diselesaikan dalam ruang kimia, kita boleh memindahkannya ke ruang bahasa semula jadi. Dan tugas bahasa semula jadi akan lebih mudah diselesaikan kerana ciri-cirinya. Berdasarkan ini, kami mereka bentuk pelbagai jenis tugas hiliran untuk mengesahkan keberkesanannya. Di bawah ini kita membincangkan beberapa pandangan secara terperinci.
Dalam MoleculeSTM, kami menimbulkan masalah buat kali pertama. Kami mengambil kesempatan daripada perbendaharaan kata terbuka dan ciri gabungan bahasa semula jadi
Kosa kata terbuka bermakna kita boleh menyatakan semua pengetahuan semasa manusia dalam bahasa semula jadi, jadi pengetahuan baru yang akan muncul pada masa hadapan juga boleh diringkaskan dan diringkaskan menggunakan bahasa sedia ada. rumuskan. Sebagai contoh, jika protein baharu muncul, kami berharap dapat menerangkan fungsinya dalam bahasa semula jadi. Kekomposisian bermaksud bahawa dalam bahasa semula jadi, konsep yang kompleks boleh diungkapkan bersama oleh beberapa konsep mudah. Ini sangat membantu untuk tugas seperti pengeditan berbilang atribut: sangat sukar untuk mengedit molekul untuk memenuhi berbilang sifat pada masa yang sama dalam ruang kimia, tetapi kita boleh menyatakan berbilang sifat dengan sangat mudah dalam bahasa semula jadi.- Dalam kerja terbaru kami ChatDrug (https://arxiv.org/abs/2305.18090), kami meneroka ciri dialog antara bahasa semula jadi dan model bahasa besar Rakan yang berminat dengan ini boleh menyemaknya
Untuk tugasan imej bahasa yang sedia ada, ia boleh dianggap sebagai tugasan berkaitan seni, seperti penjanaan Gambar atau teks. Maksudnya, keputusan mereka berbeza-beza dan tidak pasti. Walau bagaimanapun, penemuan saintifik adalah masalah saintifik, selalunya dengan hasil yang agak jelas, seperti penjanaan molekul kecil dengan fungsi tertentu. Ini membawa cabaran yang lebih besar dalam reka bentuk tugasan Dalam MoleculeSTM (Lampiran B), kami mencadangkan dua garis panduan:
- Tugas pertama yang kami pertimbangkan ialah dapat melakukan simulasi pengiraan dan mendapatkan hasil. Pada masa hadapan, keputusan pengesahan makmal basah akan dipertimbangkan, tetapi ini tidak dalam skop kerja semasa.
- Kedua, kami hanya mempertimbangkan masalah dengan keputusan yang samar-samar. Contoh khusus termasuk menjadikan molekul tertentu lebih larut air atau boleh ditembusi. Sesetengah masalah mempunyai hasil yang jelas, seperti menambah kumpulan berfungsi tertentu pada kedudukan tertentu dalam molekul Kami percaya bahawa tugas sedemikian adalah lebih mudah dan lebih mudah untuk pakar ubat dan kimia. Jadi ia boleh digunakan sebagai tugas bukti konsep pada masa hadapan, tetapi ia tidak akan menjadi sasaran tugas utama. .
Kami akan menumpukan pada tugasan kedua dalam bahagian seterusnya
- Hasil kualitatif penyuntingan molekul dinyatakan semula seperti berikut:
- Tugas ini adalah untuk memasukkan molekul dan huraian bahasa semula jadi (seperti atribut tambahan) di masa yang sama, dan kemudian Adalah wajar untuk dapat mengeluarkan huraian teks bahasa kompleks bagi molekul baru. Ini ialah pengoptimuman petunjuk berpandukan teks.
- Kaedah khusus ialah menggunakan model penjanaan molekul yang telah terlatih dan MoleculeSTM kami yang telah terlatih untuk mempelajari penjajaran ruang terpendam mereka untuk melakukan interpolasi ruang terpendam, dan kemudian menjana molekul sasaran melalui penyahkodan. Gambar rajah proses adalah seperti berikut.
Kandungan yang perlu ditulis semula ialah: gambar rajah proses dua peringkat penyuntingan molekul berpandukan teks sifar sampel
Di sini kami menunjukkan hasil kualitatif beberapa kumpulan penyuntingan molekul, dinyatakan semula seperti berikut: (The butiran hasil tugasan hiliran yang tinggal boleh Rujuk kertas asal). Kami mempertimbangkan terutamanya empat jenis tugas penyuntingan molekul:Suntingan atribut tunggal: Mengedit atribut tunggal, seperti keterlarutan air, kebolehtembusan dan bilangan penderma dan penerima ikatan hidrogen.
Suntingan atribut komposit: Edit berbilang atribut pada masa yang sama, seperti keterlarutan air dan bilangan penderma ikatan hidrogen. 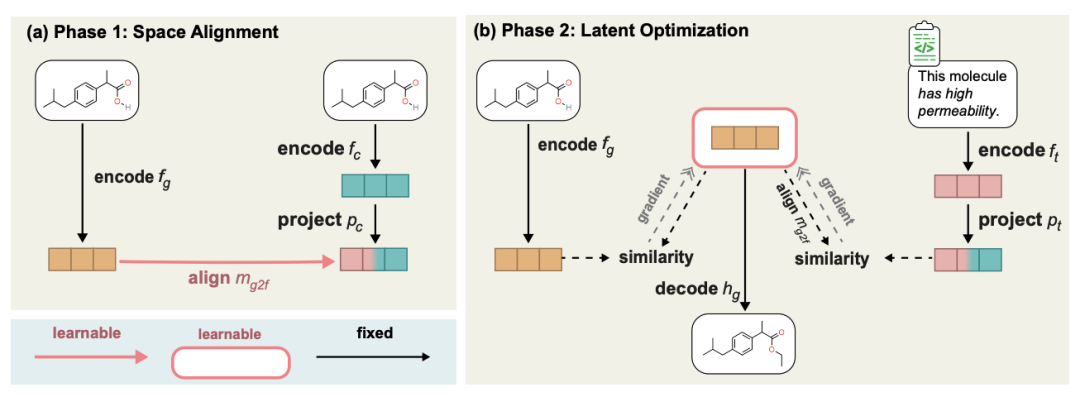
- Paparan hasil: penyuntingan molekul berpandukan teks sampel sifar. (Nota: Ini adalah terjemahan langsung ayat asal ke dalam bahasa Cina.)
- Apa yang lebih menarik ialah jenis tugasan terakhir Kami mendapati bahawa MoleculeSTM sememangnya boleh melakukan pemadanan ligan berdasarkan keterangan teks protein sasaran pengoptimuman. (Nota: Maklumat struktur protein di sini hanya akan diketahui selepas penilaian.)
Atas ialah kandungan terperinci NVIDIA, Mila dan Caltech bersama-sama mengeluarkan model teks struktur molekul multimodal yang menggabungkan LLM dengan penemuan dadah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!