
Rumah >Peranti teknologi >AI >Menyelam mendalam ke dalam model, data dan rangka kerja: tinjauan menyeluruh 54 halaman model bahasa besar yang cekap
Menyelam mendalam ke dalam model, data dan rangka kerja: tinjauan menyeluruh 54 halaman model bahasa besar yang cekap

- PHPzke hadapan
- 2024-01-14 19:48:061396semak imbas
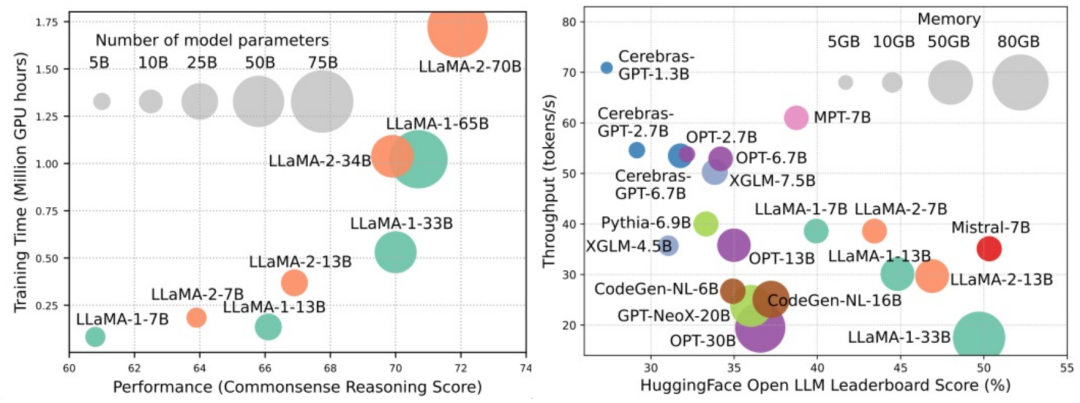
Model bahasa berskala besar (LLM) telah menunjukkan keupayaan yang menarik dalam banyak tugas penting, termasuk pemahaman bahasa semula jadi, penjanaan bahasa dan penaakulan yang kompleks, dan telah memberi kesan yang mendalam kepada masyarakat. Walau bagaimanapun, keupayaan cemerlang ini memerlukan sumber latihan yang ketara (ditunjukkan dalam imej kiri) dan masa inferens yang panjang (ditunjukkan dalam imej kanan). Oleh itu, penyelidik perlu membangunkan cara teknikal yang berkesan untuk menyelesaikan masalah kecekapan mereka.
Selain itu, seperti yang dapat dilihat dari sebelah kanan rajah, beberapa LLM (Model Bahasa) yang cekap seperti Mistral-7B telah berjaya digunakan dalam reka bentuk dan penggunaan LLM. LLM yang cekap ini boleh mengurangkan penggunaan memori inferens dan mengurangkan kependaman inferens sambil mengekalkan ketepatan yang serupa dengan LLaMA1-33B. Ini menunjukkan bahawa sudah ada beberapa kaedah yang boleh dilaksanakan dan cekap yang telah berjaya digunakan untuk reka bentuk dan penggunaan LLM.
Dalam ulasan ini, penyelidik dari Ohio State University, Imperial College, Michigan State University, University of Michigan, Amazon, Google, Boson AI dan Microsoft Asia Research memberikan cerapan tentang penyelidikan tentang LLM yang cekap tinjauan sistem. Mereka membahagikan teknologi sedia ada untuk mengoptimumkan kecekapan LLM kepada tiga kategori, termasuk model-centric, data-centric dan framework-centric, dan meringkaskan serta membincangkan teknologi berkaitan yang paling canggih.

- Kertas: https://arxiv.org/abs/2312.03863
- cekap-LLM s -Tinjauan
Untuk memudahkan menyusun kertas yang terlibat dalam semakan dan memastikannya dikemas kini, penyelidik mencipta repositori GitHub dan menyelenggaranya secara aktif. Mereka berharap repositori ini akan membantu penyelidik dan pengamal memahami secara sistematik penyelidikan dan pembangunan LLM yang cekap dan memberi inspirasi kepada mereka untuk menyumbang kepada bidang yang penting dan menarik ini.
URL gudang ialah https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. Dalam repositori ini anda boleh menemui kandungan yang berkaitan dengan tinjauan sistem pembelajaran mesin yang cekap dan berkuasa rendah. Repositori ini menyediakan kertas penyelidikan, kod dan dokumentasi untuk membantu orang ramai memahami dan meneroka sistem pembelajaran mesin yang cekap dan berkuasa rendah. Jika anda berminat dengan kawasan ini, anda boleh mendapatkan maklumat lanjut dengan melawati repositori ini.
Model-centricPendekatan model-centric memfokuskan pada teknik yang cekap pada tahap algoritma dan tahap sistem, di mana model itu sendiri adalah tumpuan. Memandangkan LLM mempunyai berbilion malah bertrilion parameter dan mempunyai ciri unik seperti kemunculan berbanding model berskala lebih kecil, teknik baharu perlu dibangunkan untuk mengoptimumkan kecekapan LLM. Artikel ini membincangkan lima kategori kaedah tertumpu model secara terperinci, termasuk
mampatan model, pra-latihan yang cekap, penalaan halus yang cekap, inferens yang cekap dan reka bentuk seni bina model yang cekap.
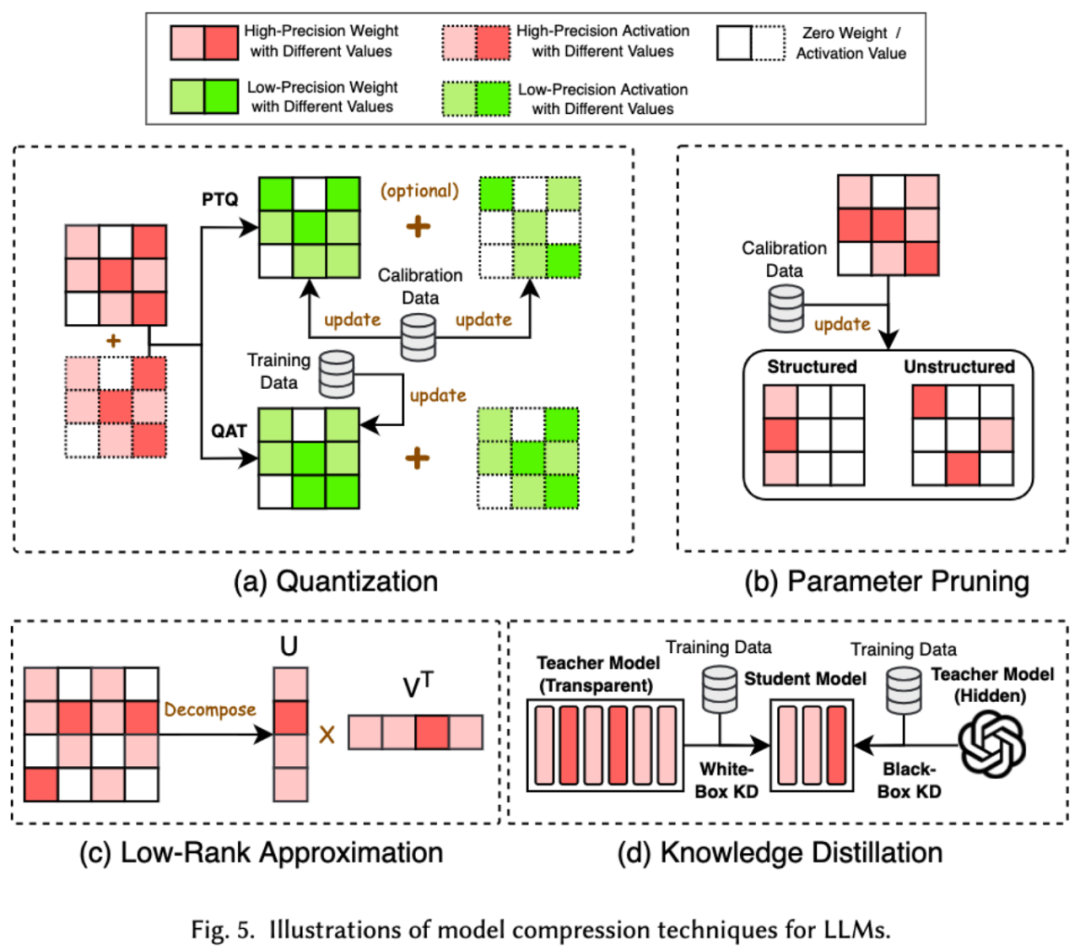
1 Dalam bidang pembelajaran mesin, saiz model sering menjadi pertimbangan penting. Model yang lebih besar selalunya memerlukan lebih banyak ruang storan dan sumber pengkomputeran, dan mungkin menghadapi pengehadan apabila dijalankan pada peranti mudah alih. Oleh itu, memampatkan model ialah teknik yang biasa digunakan untuk mengurangkan saiz model Teknik pemampatan model terutamanya dibahagikan kepada empat kategori: kuantisasi, pemangkasan parameter, anggaran peringkat rendah dan penyulingan pengetahuan (lihat rajah di bawah), antaranya Kuantisasi. akan memampatkan pemberat atau nilai pengaktifan model daripada ketepatan tinggi kepada ketepatan rendah Pemangkasan parameter akan mencari dan memadam bahagian yang lebih berlebihan dari berat model akan menukar matriks berat model kepada beberapa rendah. peringkat matriks kecil. Penyulingan produk dan pengetahuan secara langsung menggunakan model besar untuk melatih model kecil, supaya model kecil mempunyai keupayaan untuk menggantikan model besar apabila melakukan tugas-tugas tertentu.
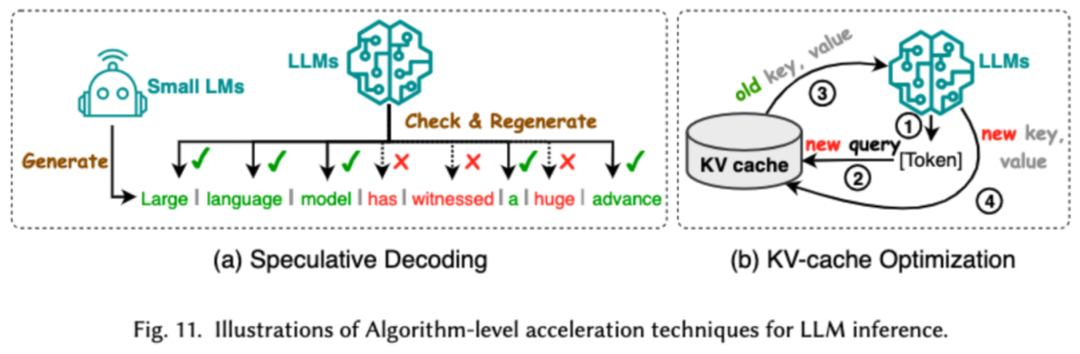
2. Pra-latihan yang cekap
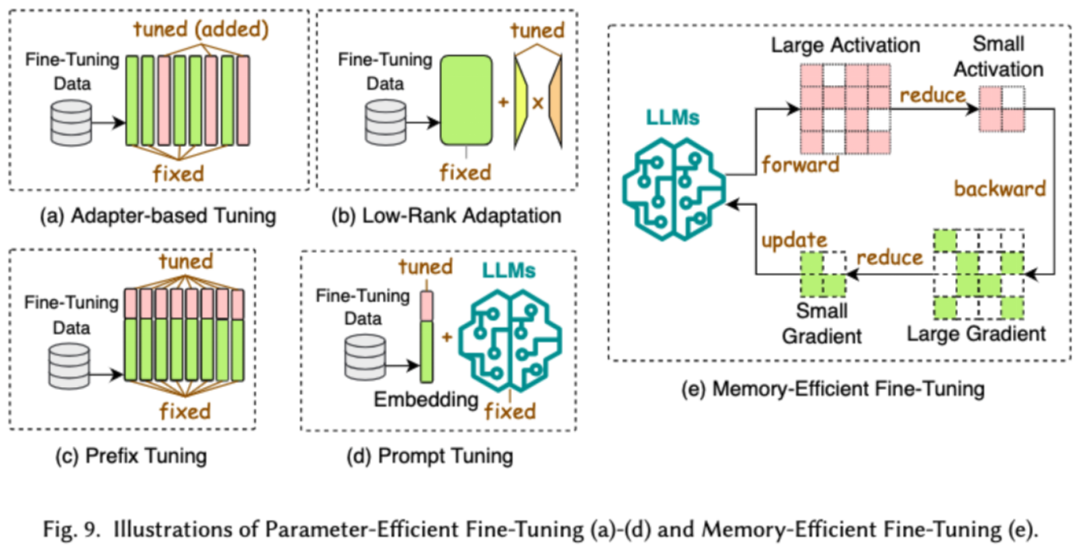
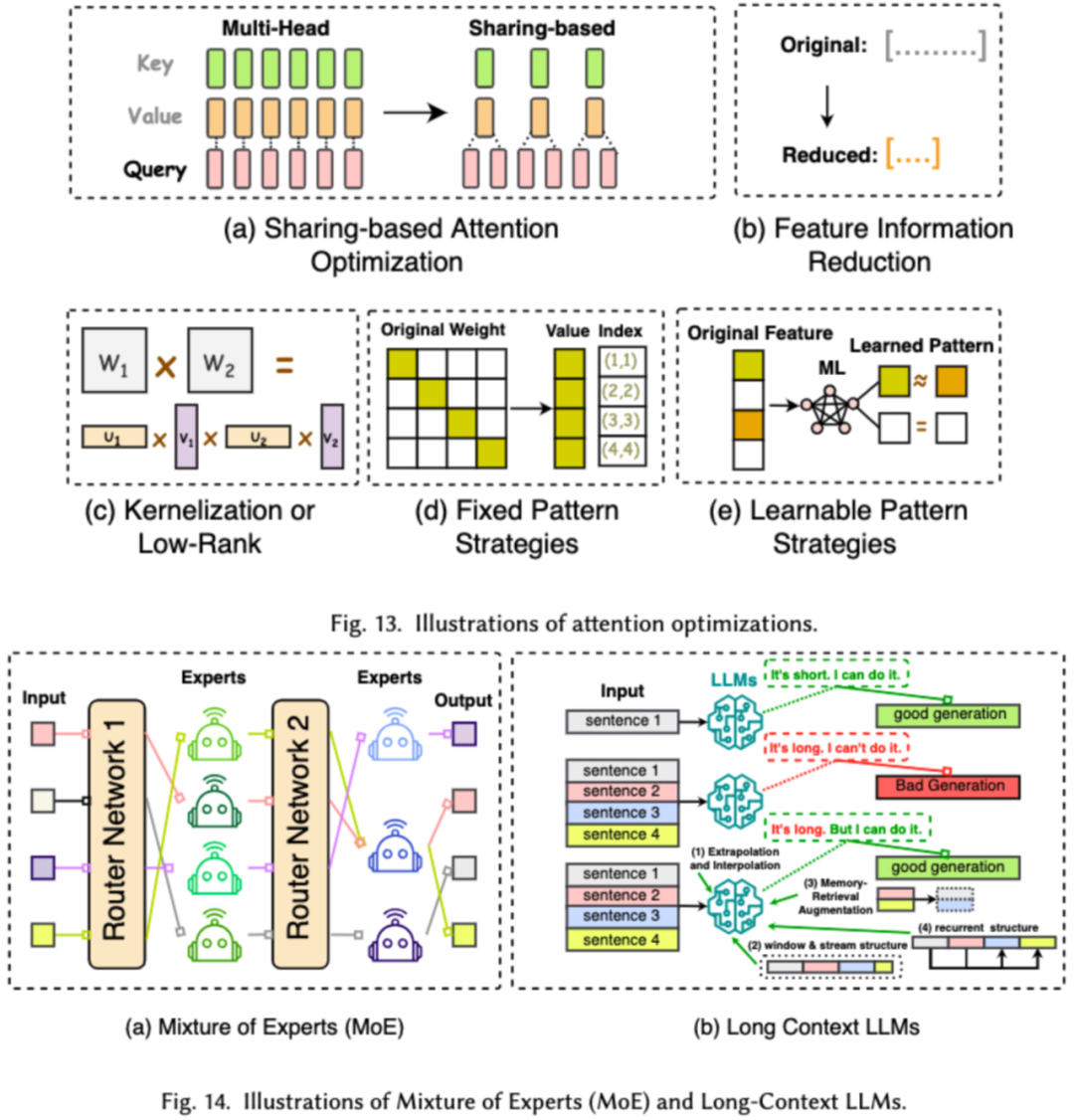
Kos pra-latihan LLM sangat mahal. Pra-latihan yang cekap bertujuan untuk meningkatkan kecekapan dan mengurangkan kos proses pra-latihan LLM. Pra-latihan yang cekap boleh dibahagikan kepada pecutan ketepatan campuran, penskalaan model, teknologi permulaan, strategi pengoptimuman dan pecutan peringkat sistem.Pecutan ketepatan campuran meningkatkan kecekapan pra-latihan dengan mengira kecerunan, pemberat dan pengaktifan menggunakan pemberat ketepatan rendah, kemudian menukarnya kembali kepada ketepatan tinggi dan menggunakannya untuk mengemas kini pemberat asal. Penskalaan model mempercepatkan penumpuan pra-latihan dan mengurangkan kos latihan dengan menggunakan parameter model kecil untuk menskalakan kepada model besar. Teknologi permulaan mempercepatkan penumpuan model dengan mereka bentuk nilai permulaan model. Strategi pengoptimuman menumpukan pada mereka bentuk pengoptimum ringan untuk mengurangkan penggunaan memori semasa latihan model Pecutan peringkat sistem menggunakan teknologi teragih dan lain untuk mempercepatkan pra-latihan model dari peringkat sistem. 3. Penalaan halus yang cekap Penalaan halus yang cekap direka untuk meningkatkan kecekapan proses penalaan halus LLM. Teknologi penalaan halus cekap biasa terbahagi kepada dua kategori, satu penalaan halus cekap berasaskan parameter, dan satu lagi penalaan halus cekap memori. Penalaan Halus Cekap Parameter (PEFT) bertujuan untuk menyesuaikan LLM kepada tugas hiliran dengan membekukan keseluruhan tulang belakang LLM dan mengemas kini hanya set kecil parameter tambahan. Dalam makalah itu, kami membahagikan lagi PEFT kepada penalaan halus berasaskan penyesuai, penyesuaian peringkat rendah, penalaan halus awalan dan penalaan halus perkataan segera. Penalaan halus berasaskan memori yang cekap memfokuskan pada mengurangkan penggunaan memori semasa keseluruhan proses penalaan halus LLM, seperti mengurangkan memori yang digunakan oleh status pengoptimum dan nilai pengaktifan. 4. Penaakulan Cekap Penaakulan yang cekap bertujuan untuk meningkatkan kecekapan proses inferens LLM. Penyelidik membahagikan teknologi penaakulan kecekapan tinggi biasa kepada dua kategori utama, satu ialah pecutan penaakulan peringkat algoritma, dan satu lagi ialah pecutan penaakulan peringkat sistem. Pecutan inferens pada peringkat algoritma boleh dibahagikan kepada dua kategori: penyahkodan spekulatif dan KV - pengoptimuman cache. Penyahkodan spekulatif mempercepatkan proses pensampelan dengan mengira token secara selari menggunakan model draf yang lebih kecil untuk mencipta awalan spekulatif untuk model sasaran yang lebih besar. KV - Pengoptimuman cache merujuk kepada pengoptimuman pengiraan berulang pasangan Nilai-Kekunci (KV) semasa proses inferens LLM. Pecutan inferens peringkat sistem adalah untuk mengoptimumkan bilangan capaian memori pada perkakasan tertentu, meningkatkan jumlah selari algoritma, dsb. untuk mempercepatkan inferens LLM. 5. Reka bentuk seni bina model yang cekap Reka bentuk seni bina yang cekap untuk LLM merujuk kepada mengoptimumkan struktur model dan proses pengiraan secara strategik sambil meminimumkan prestasi dan proses pengiraan Kami membahagikan reka bentuk seni bina model yang cekap kepada empat kategori utama berdasarkan jenis model: modul perhatian yang cekap, model pakar hibrid, model besar teks panjang dan seni bina yang boleh menggantikan pengubah. Modul perhatian yang cekap bertujuan untuk mengoptimumkan pengiraan kompleks dan penggunaan memori dalam modul perhatian Model pakar hibrid (MoE) menggantikan keputusan penaakulan beberapa modul LLM dengan berbilang model pakar kecil model besar teks ialah LLM yang direka khas untuk memproses teks ultra-panjang dengan cekap Seni bina yang boleh menggantikan pengubah mengurangkan kerumitan model dan mencapai keupayaan penaakulan yang setanding dengan seni bina pasca pengubah dengan mereka bentuk semula seni bina model. Pendekatan data-centric memfokuskan pada peranan kualiti dan struktur data dalam meningkatkan kecekapan LLM. Dalam artikel ini, penyelidik membincangkan dua jenis kaedah berpusatkan data secara terperinci, termasuk pemilihan data dan kejuruteraan perkataan kiu. 1. Pemilihan data Pemilihan data LLM bertujuan untuk membersihkan dan memilih data pra-latihan/penalaan halus, seperti mengalih keluar data yang berlebihan dan tidak sah, untuk mempercepatkan proses latihan. 2. Kejuruteraan perkataan segera Kejuruteraan kata cepat membimbing LLM untuk menjana output yang diingini dengan mereka bentuk input yang berkesan (kata-kata gesaan terletak pada kecekapannya dan Selepas penalaan model yang membosankan). . Penyelidik membahagikan teknologi kejuruteraan kata gesaan biasa kepada tiga kategori utama: kejuruteraan kata gesaan beberapa sampel, pemampatan kata gesaan dan penjanaan kata gesaan. Beberapa contoh kejuruteraan kata cepat menyediakan LLM set contoh terhad untuk membimbing pemahamannya tentang tugas yang perlu dilaksanakan. Pemampatan perkataan pantas mempercepatkan pemprosesan input LLM dengan memampatkan input atau pembelajaran segera yang panjang dan menggunakan perwakilan segera. Penjanaan perkataan pantas bertujuan untuk mencipta gesaan berkesan secara automatik yang membimbing model untuk menjana respons khusus dan berkaitan, dan bukannya menggunakan data beranotasi secara manual. Para penyelidik menyiasat rangka kerja LLM cekap yang popular baru-baru ini dan menyenaraikan tugas cekap yang boleh mereka ikuti dan optimumkan, termasuk pra-latihan halus ditunjukkan dalam rajah). Dalam tinjauan ini, penyelidik memberikan anda semakan sistematik tentang LLM yang cekap, yang merupakan bidang penyelidikan penting yang didedikasikan untuk menjadikan LLM lebih demokratis. Mereka bermula dengan menerangkan mengapa LLM yang cekap diperlukan. Di bawah rangka kerja yang teratur, kertas kerja ini menyiasat teknologi yang cekap pada tahap algoritma dan tahap sistem LLM daripada perspektif berpusat model, berpusat data, dan berpusat rangka kerja. Penyelidik percaya bahawa kecekapan akan memainkan peranan yang semakin penting dalam sistem berorientasikan LLM dan LLM. Mereka berharap tinjauan ini akan membantu penyelidik dan pengamal dengan cepat memasuki bidang ini dan berfungsi sebagai pemangkin untuk merangsang penyelidikan baharu tentang LLM yang cekap. 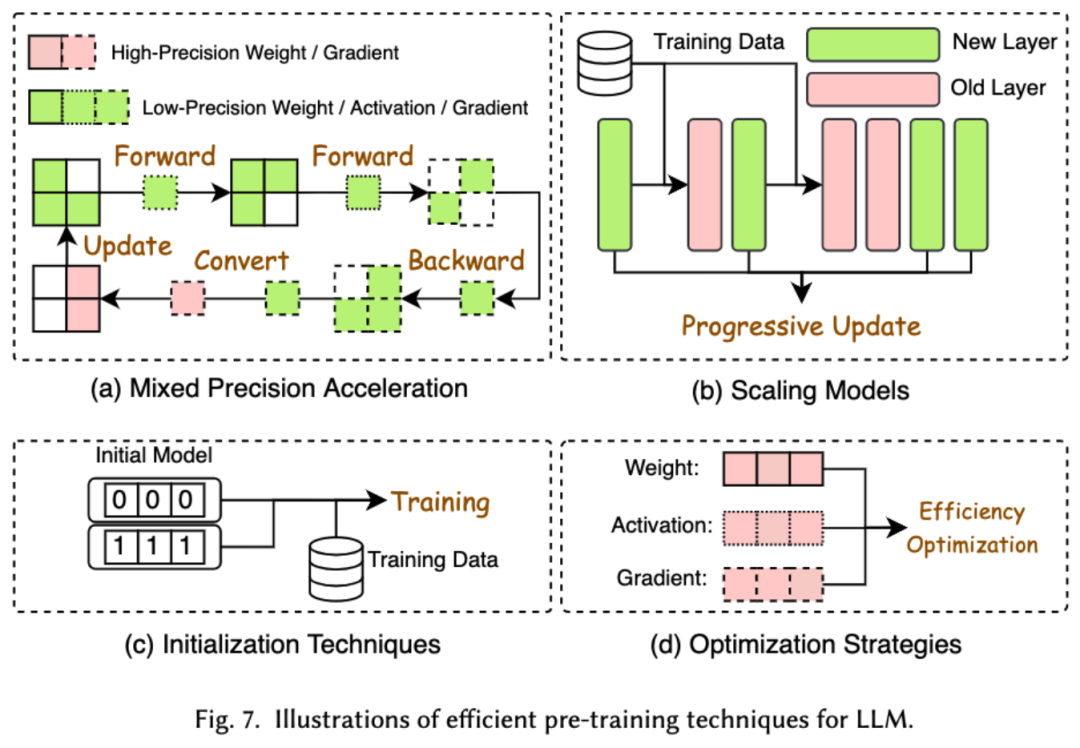
Data-centric
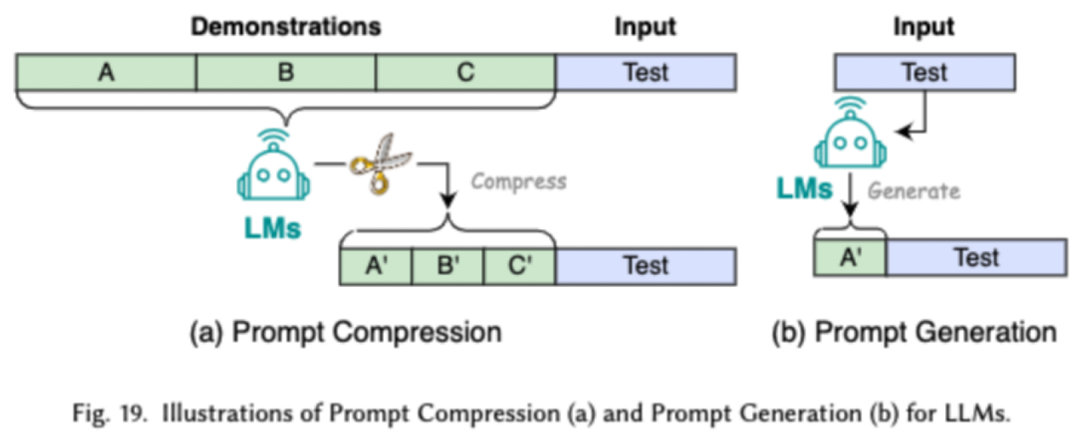
Framework-centric
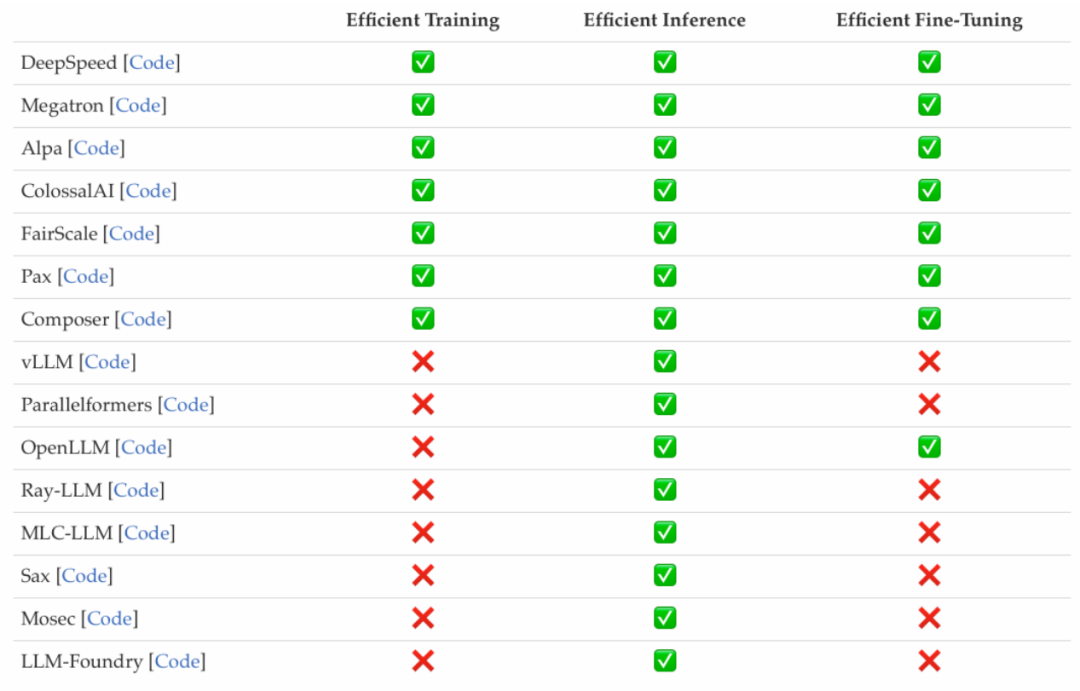
Ringkasan
Atas ialah kandungan terperinci Menyelam mendalam ke dalam model, data dan rangka kerja: tinjauan menyeluruh 54 halaman model bahasa besar yang cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 深入研究Vue CLI3
- ai合并图层的快捷键是什么
- Apakah alat tinjauan soal selidik?
- Semakan model bahasa berskala besar yang baru dikeluarkan: ulasan paling komprehensif dari T5 hingga GPT-4, dikarang bersama oleh lebih daripada 20 penyelidik domestik
- Cara menggunakan JavaScript dan WebSocket untuk melaksanakan sistem tinjauan soal selidik dalam talian masa nyata