

 Peranti teknologiAIRangka kerja pembenaman pengetahuan spatiotemporal Universiti Sun Yat-sen yang baharu memacu kemajuan terkini dalam tugas penjanaan graf adegan video, diterbitkan dalam TIP '24
Peranti teknologiAIRangka kerja pembenaman pengetahuan spatiotemporal Universiti Sun Yat-sen yang baharu memacu kemajuan terkini dalam tugas penjanaan graf adegan video, diterbitkan dalam TIP '24
Penjanaan Graf Pemandangan Video (VidSGG) bertujuan untuk mengenal pasti objek dalam adegan visual dan membuat kesimpulan hubungan visual antara mereka.
Tugas ini bukan sahaja memerlukan pemahaman menyeluruh tentang setiap objek yang tersebar di seluruh adegan, tetapi juga kajian mendalam tentang pergerakan dan interaksi mereka dari semasa ke semasa.
Baru-baru ini, penyelidik dari Universiti Sun Yat-sen menerbitkan kertas kerja dalam jurnal kecerdasan buatan teratas IEEE T-IP Mereka meneroka tugas yang berkaitan dan mendapati bahawa: setiap pasangan gabungan objek dan hubungan mereka adalah dalam setiap Terdapat co spatial. -korelasi kejadian dalam imej, dan korelasi ketekalan/terjemahan temporal antara imej yang berbeza.

Pautan kertas: https://arxiv.org/abs/2309.13237
Berdasarkan pengetahuan sedia ada ini, penyelidik mencadangkan Transformer (STKET) berasaskan pengetahuan smporotemporal smbepatiotemporal sebelum ini Pengetahuan digabungkan ke dalam mekanisme perhatian silang berbilang kepala untuk mempelajari lebih banyak perwakilan perhubungan visual yang mewakili.
Secara khusus, korelasi kejadian bersama spatial dan transformasi temporal mula-mula dipelajari secara statistik kemudian, lapisan pembenaman pengetahuan spatiotemporal direka untuk meneroka sepenuhnya interaksi antara perwakilan visual dan pengetahuan, dan masing-masing menjana perhubungan pengetahuan visual spatial perwakilan; akhirnya, pengarang mengagregatkan ciri ini untuk meramalkan label semantik akhir dan hubungan visualnya.
Sebilangan besar percubaan menunjukkan bahawa rangka kerja yang dicadangkan dalam artikel ini jauh lebih baik daripada algoritma bersaing semasa. Pada masa ini, kertas itu telah diterima. .
Walau bagaimanapun, kaedah ini selalunya hanya mempertimbangkan satu imej dan mengabaikan sejumlah besar maklumat kontekstual yang wujud dalam siri masa, menyebabkan kebanyakan algoritma penjanaan graf pemandangan sedia ada tidak dapat mengenal pasti kandungan yang terkandung dalam dinamik tertentu hubungan visual.
Oleh itu, ramai penyelidik komited untuk membangunkan algoritma Penjanaan Graf Pemandangan Video (VidSGG) untuk menyelesaikan masalah ini.
Kerja semasa tertumpu terutamanya pada mengagregatkan maklumat visual peringkat objek daripada perspektif spatial dan temporal untuk mempelajari perwakilan perhubungan visual yang sepadan.
Walau bagaimanapun, disebabkan oleh perbezaan yang besar dalam penampilan visual pelbagai objek dan tindakan interaktif dan pengedaran ekor panjang yang ketara bagi hubungan visual yang disebabkan oleh pengumpulan video, hanya menggunakan maklumat visual sahaja dengan mudah boleh membawa kepada model meramalkan visual yang salah. perhubungan.
Sebagai tindak balas kepada masalah di atas, penyelidik telah melakukan dua aspek kerja berikut:
Pertama, adalah dicadangkan untuk melombong pengetahuan spatiotemporal terdahulu yang terkandung dalam sampel latihan untuk mempromosikan bidang penjanaan graf adegan video. Antaranya, pengetahuan spatiotemporal terdahulu termasuk:
1) Korelasi kejadian bersama ruang: Hubungan antara kategori objek tertentu cenderung kepada interaksi tertentu.
2) Ketekalan Temporal/Korelasi Peralihan: Sepasang perhubungan tertentu cenderung untuk konsisten merentas klip video berturut-turut, atau mempunyai kebarangkalian tinggi untuk beralih kepada perhubungan khusus yang lain.
Kedua, rangka kerja Transformer novel (Spatial-Temporal Knowledge-Embedded Transformer, STKET) berdasarkan pembenaman pengetahuan spatial-temporal dicadangkan.
Rangka kerja ini menggabungkan pengetahuan spatiotemporal terdahulu ke dalam mekanisme perhatian silang berbilang kepala untuk mempelajari lebih banyak perwakilan perhubungan visual yang mewakili. Mengikut keputusan perbandingan yang diperoleh pada penanda aras ujian, boleh didapati bahawa rangka kerja STKET yang dicadangkan oleh penyelidik mengatasi prestasi kaedah terkini yang terkini. . perwakilan pengetahuan
Dalam Apabila membuat kesimpulan hubungan visual, manusia bukan sahaja menggunakan isyarat visual tetapi juga terkumpul pengetahuan terdahulu [1, 2]. Diilhamkan oleh ini, penyelidik mencadangkan untuk mengekstrak pengetahuan spatiotemporal terdahulu secara langsung daripada set latihan untuk memudahkan tugas penjanaan graf adegan video.
Antaranya, korelasi kejadian bersama spatial ditunjukkan secara khusus apabila objek tertentu digabungkan, taburan hubungan visualnya akan menjadi sangat condong (contohnya, taburan hubungan visual antara "orang" dan "cawan" adalah jelas berbeza daripada "anjing" dan "anjing"). Taburan antara "mainan") dan korelasi pemindahan masa secara khusus ditunjukkan dalam kebarangkalian peralihan setiap hubungan visual akan berubah dengan ketara apabila hubungan visual pada saat sebelumnya diberikan (untuk contoh, apabila hubungan visual pada saat sebelumnya diketahui sebagai "makan", kebarangkalian bahawa hubungan visual akan dipindahkan kepada "menulis" pada saat berikutnya sangat berkurangan).
Seperti yang ditunjukkan dalam Rajah 2, selepas anda secara intuitif dapat merasakan gabungan objek yang diberikan atau hubungan visual sebelumnya, ruang ramalan boleh dikurangkan dengan banyaknya.

Rajah 2: Kebarangkalian kejadian bersama ruang [3] dan kebarangkalian peralihan temporal hubungan visual
Khususnya, untuk gabungan objek jenis ke-i, dan objek jenis ke-j momen sebelumnya Untuk perhubungan jenis ke-x, mula-mula dapatkan matriks kebarangkalian kejadian bersama spatial yang sepadan E^{i,j} dan matriks kebarangkalian peralihan masa Ex^{i,j} melalui statistik.
Kemudian, masukkannya ke dalam lapisan bersambung sepenuhnya untuk mendapatkan perwakilan ciri yang sepadan, dan gunakan fungsi objektif yang sepadan untuk memastikan perwakilan pengetahuan yang dipelajari oleh model mengandungi pengetahuan spatiotemporal terdahulu yang sepadan.

Rajah 3: Proses pembelajaran spatial (a) dan temporal (b) representasi pengetahuan
Pengetahuan tertanam dalam lapisan perhatian
dan maklumat tentang lokasi, biasanya mengandungi jarak antara lokasi maklumat entiti. Pengetahuan temporal, sebaliknya, melibatkan urutan, tempoh, dan selang antara tindakan.
Memandangkan sifat uniknya, merawatnya secara individu boleh membenarkan pemodelan khusus untuk menangkap corak yang wujud dengan lebih tepat.
Oleh itu, para penyelidik mereka bentuk lapisan pembenaman pengetahuan spatiotemporal untuk meneroka secara menyeluruh interaksi antara perwakilan visual dan pengetahuan spatiotemporal. . lapisan pembenaman pengetahuan temporal meneroka korelasi pemindahan temporal antara imej yang berbeza, dengan itu meneroka sepenuhnya interaksi antara perwakilan visual dan pengetahuan spatiotemporal.
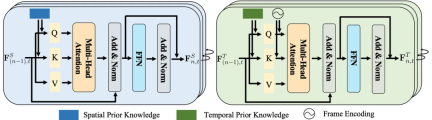 Walau bagaimanapun, kedua-dua lapisan ini mengabaikan maklumat kontekstual jangka panjang, yang membantu untuk mengenal pasti kebanyakan perhubungan visual yang berubah secara dinamik.
Walau bagaimanapun, kedua-dua lapisan ini mengabaikan maklumat kontekstual jangka panjang, yang membantu untuk mengenal pasti kebanyakan perhubungan visual yang berubah secara dinamik.
Untuk tujuan ini, para penyelidik mereka bentuk modul pengagregatan ruang (STA) untuk mengagregatkan perwakilan setiap pasangan objek ini untuk meramalkan label semantik akhir dan hubungannya. Ia mengambil sebagai input representasi perhubungan terbenam spatial dan temporal bagi pasangan subjek-objek yang sama dalam bingkai yang berbeza.
Secara khusus, penyelidik menggabungkan perwakilan pasangan objek yang sama ini untuk menghasilkan perwakilan kontekstual.
Kemudian, untuk mencari pasangan subjek-objek yang sama dalam bingkai yang berbeza, label objek yang diramalkan dan IoU (iaitu Persimpangan atas Kesatuan) digunakan untuk memadankan pasangan subjek-objek yang sama yang dikesan dalam bingkai.
Akhir sekali, memandangkan perhubungan dalam bingkai mempunyai perwakilan yang berbeza dalam kelompok yang berbeza, perwakilan terawal dalam tetingkap gelongsor dipilih.
Hasil eksperimen
Untuk menilai secara menyeluruh prestasi rangka kerja yang dicadangkan, selain membandingkan kaedah penjanaan graf adegan video sedia ada (STTran, TPI, APT), para penyelidik juga memilih kaedah penjanaan graf adegan imej lanjutan (KERN, VCTREE, ReIDN, GPS-Net) untuk perbandingan.
Antaranya, untuk memastikan perbandingan yang adil, kaedah penjanaan graf pemandangan imej mencapai matlamat untuk menghasilkan graf adegan yang sepadan untuk video tertentu dengan mengenal pasti setiap bingkai imej.
Rajah 5: Keputusan eksperimen menggunakan Recall sebagai indeks penilaian pada set data Genom Tindakan
Rajah 6: Keputusan eksperimen menggunakan Recall min sebagai indeks penilaian pada set data Genom Tindakan
Atas ialah kandungan terperinci Rangka kerja pembenaman pengetahuan spatiotemporal Universiti Sun Yat-sen yang baharu memacu kemajuan terkini dalam tugas penjanaan graf adegan video, diterbitkan dalam TIP '24. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Memasak Inovasi: Bagaimana Kecerdasan Buatan Mengubah Perkhidmatan MakananApr 12, 2025 pm 12:09 PM
Memasak Inovasi: Bagaimana Kecerdasan Buatan Mengubah Perkhidmatan MakananApr 12, 2025 pm 12:09 PMAI Menambah Penyediaan Makanan Walaupun masih dalam penggunaan baru, sistem AI semakin digunakan dalam penyediaan makanan. Robot yang didorong oleh AI digunakan di dapur untuk mengautomasikan tugas penyediaan makanan, seperti membuang burger, membuat pizza, atau memasang SA
 Panduan Komprehensif mengenai Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PM
Panduan Komprehensif mengenai Python Namespaces & Variable ScopesApr 12, 2025 pm 12:00 PMPengenalan Memahami ruang nama, skop, dan tingkah laku pembolehubah dalam fungsi Python adalah penting untuk menulis dengan cekap dan mengelakkan kesilapan runtime atau pengecualian. Dalam artikel ini, kami akan menyelidiki pelbagai ASP
 Panduan Komprehensif untuk Model Bahasa Visi (VLMS)Apr 12, 2025 am 11:58 AM
Panduan Komprehensif untuk Model Bahasa Visi (VLMS)Apr 12, 2025 am 11:58 AMPengenalan Bayangkan berjalan melalui galeri seni, dikelilingi oleh lukisan dan patung yang terang. Sekarang, bagaimana jika anda boleh bertanya setiap soalan dan mendapatkan jawapan yang bermakna? Anda mungkin bertanya, "Kisah apa yang anda ceritakan?
 MediaTek meningkatkan barisan premium dengan Kompanio Ultra dan Dimensity 9400Apr 12, 2025 am 11:52 AM
MediaTek meningkatkan barisan premium dengan Kompanio Ultra dan Dimensity 9400Apr 12, 2025 am 11:52 AMMeneruskan irama produk, bulan ini MediaTek telah membuat satu siri pengumuman, termasuk Kompanio Ultra dan Dimensity 9400 yang baru. Produk ini mengisi bahagian perniagaan MediaTek yang lebih tradisional, termasuk cip untuk telefon pintar
 Minggu ini di AI: Walmart menetapkan trend fesyen sebelum mereka pernah berlakuApr 12, 2025 am 11:51 AM
Minggu ini di AI: Walmart menetapkan trend fesyen sebelum mereka pernah berlakuApr 12, 2025 am 11:51 AM#1 Google melancarkan Agent2Agent Cerita: Ia Isnin pagi. Sebagai perekrut berkuasa AI, anda bekerja lebih pintar, tidak lebih sukar. Anda log masuk ke papan pemuka syarikat anda di telefon anda. Ia memberitahu anda tiga peranan kritikal telah diperolehi, dijadualkan, dan dijadualkan untuk
 AI Generatif Bertemu PsychobabbleApr 12, 2025 am 11:50 AM
AI Generatif Bertemu PsychobabbleApr 12, 2025 am 11:50 AMSaya akan meneka bahawa anda mesti. Kita semua seolah -olah tahu bahawa psychobabble terdiri daripada pelbagai perbualan yang menggabungkan pelbagai terminologi psikologi dan sering akhirnya menjadi tidak dapat difahami atau sepenuhnya tidak masuk akal. Semua yang anda perlu lakukan untuk memuntahkan fo
 Prototaip: saintis menjadikan kertas menjadi plastikApr 12, 2025 am 11:49 AM
Prototaip: saintis menjadikan kertas menjadi plastikApr 12, 2025 am 11:49 AMHanya 9.5% plastik yang dihasilkan pada tahun 2022 dibuat daripada bahan kitar semula, menurut satu kajian baru yang diterbitkan minggu ini. Sementara itu, plastik terus menumpuk di tapak pelupusan sampah -dan ekosistem -sekitar dunia. Tetapi bantuan sedang dalam perjalanan. Pasukan Engin
 Kebangkitan Penganalisis AI: Mengapa ini boleh menjadi pekerjaan yang paling penting dalam Revolusi AIApr 12, 2025 am 11:41 AM
Kebangkitan Penganalisis AI: Mengapa ini boleh menjadi pekerjaan yang paling penting dalam Revolusi AIApr 12, 2025 am 11:41 AMPerbualan baru -baru ini dengan Andy Macmillan, Ketua Pegawai Eksekutif Platform Analytics Enterprise terkemuka Alteryx, menonjolkan peranan kritikal namun kurang dihargai ini dalam revolusi AI. Seperti yang dijelaskan oleh Macmillan, jurang antara data perniagaan mentah dan maklumat siap sedia


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

