
Rumah >Peranti teknologi >AI >Netizen dipuji: Transformer mengetuai versi ringkas kertas tahunan ada di sini
Netizen dipuji: Transformer mengetuai versi ringkas kertas tahunan ada di sini

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-14 13:51:171110semak imbas
Optimalkan dari akar model besar.
Seni bina Transformer boleh dikatakan sebagai kuasa utama di sebalik banyak kisah kejayaan baru-baru ini dalam bidang pembelajaran mendalam. Cara mudah untuk membina seni bina Transformer yang mendalam adalah dengan menyusun berbilang "blok" Transformer yang serupa satu demi satu, tetapi setiap "blok" adalah lebih kompleks dan terdiri daripada banyak komponen berbeza yang memerlukan susunan dan gabungan tertentu untuk mencapai prestasi yang baik.
Sejak kelahiran seni bina Transformer pada tahun 2017, para penyelidik telah melancarkan sejumlah besar kajian terbitan berdasarkannya, tetapi hampir tiada perubahan dibuat pada "blok" Transformer.
Jadi persoalannya, bolehkah blok Transformer standard dipermudahkan?
Dalam kertas kerja baru-baru ini, penyelidik dari ETH Zurich membincangkan cara memudahkan blok Transformer standard yang diperlukan untuk LLM tanpa menjejaskan sifat penumpuan dan prestasi tugas hiliran. Berdasarkan teori penyebaran isyarat dan bukti empirikal, mereka mendapati bahawa beberapa bahagian seperti sambungan baki, lapisan normalisasi (LayerNorm), parameter unjuran dan nilai, dan sub-blok bersiri MLP (memihak kepada susun atur selari) boleh dialih keluar untuk memudahkan GPT- seperti seni bina penyahkod dan model BERT gaya pengekod.
Para penyelidik meneroka sama ada komponen yang terlibat boleh dialih keluar tanpa menjejaskan kelajuan latihan, dan pengubahsuaian seni bina yang perlu dibuat pada blok Transformer.

Pautan kertas: https://arxiv.org/pdf/2311.01906.pdf
Lightning AI Pengasas dan penyelidik pembelajaran mesin Sebastian Raschka menggelar penyelidikan ini sebagai "" kertas kegemarannya: "
Tetapi sesetengah penyelidik mempersoalkan: "Sukar untuk mengulas melainkan saya telah melihat proses latihan yang lengkap. Jika tiada lapisan normalisasi dan tiada sambungan baki, bagaimana ia boleh lebih daripada 1 "
Sebastian Raschka bersetuju: "Ya, seni bina yang mereka uji adalah agak kecil, Sama ada ini boleh digeneralisasikan kepada Transformer dengan berbilion parameter masih perlu dilihat. Tetapi dia masih berkata kerja itu mengagumkan dan percaya itu kejayaan mengalih keluar sambungan baki adalah munasabah sepenuhnya (memandangkan skema permulaannya).
Dalam hal ini, pemenang Anugerah Turing Yann LeCun mengulas: "Kami hanya menyentuh permukaan bidang seni bina pembelajaran mendalam. Ini adalah ruang berdimensi tinggi, jadi kelantangan hampir sepenuhnya terkandung di permukaan, tetapi kami hanya menyentuh permukaan Sebahagian kecil daripada ‖

Mengapa kita perlu memudahkan blok Transformer?
Para penyelidik berkata bahawa memudahkan blok Transformer tanpa menjejaskan kelajuan latihan adalah masalah penyelidikan yang menarik.
Pertama sekali, seni bina rangkaian saraf moden adalah kompleks dalam reka bentuk dan mengandungi banyak komponen Peranan komponen yang berbeza ini dalam dinamik latihan rangkaian saraf dan cara ia berinteraksi antara satu sama lain tidak difahami dengan baik. Soalan ini berkaitan dengan jurang antara teori pembelajaran mendalam dan amalan, dan oleh itu sangat penting.
Teori perambatan isyarat telah terbukti berpengaruh dalam memotivasikan pilihan reka bentuk praktikal dalam seni bina rangkaian neural dalam. Penyebaran isyarat mengkaji evolusi maklumat geometri dalam rangkaian saraf selepas pemula, ditangkap oleh produk dalaman perwakilan hierarki merentas input, dan telah membawa kepada banyak hasil yang mengagumkan dalam melatih rangkaian saraf dalam.
Walau bagaimanapun, pada masa ini teori ini hanya mempertimbangkan model semasa pemulaan, dan selalunya hanya mempertimbangkan hantaran hadapan awal, jadi ia tidak boleh mendedahkan banyak isu kompleks dalam dinamik latihan rangkaian saraf dalam, seperti sumbangan sambungan baki kepada kelajuan latihan. Walaupun penyebaran isyarat adalah penting untuk motivasi pengubahsuaian, para penyelidik mengatakan mereka tidak dapat memperoleh modul Transformer yang dipermudahkan daripada teori sahaja dan terpaksa bergantung pada pandangan empirikal.
Dari segi aplikasi praktikal, memandangkan kos latihan semasa yang tinggi dan menggunakan model Transformer yang besar, sebarang peningkatan kecekapan dalam saluran latihan dan inferens seni bina Transformer mewakili potensi penjimatan yang besar. Jika modul Transformer boleh dipermudahkan dengan mengalih keluar komponen yang tidak diperlukan, ia boleh mengurangkan bilangan parameter dan meningkatkan daya pemprosesan model.
Kertas ini juga menyebut bahawa selepas mengalih keluar sambungan baki, parameter nilai, parameter unjuran dan sub-blok bersiri, ia boleh memadankan Transformer standard dari segi kelajuan latihan dan prestasi tugas hiliran. Akhirnya, penyelidik mengurangkan bilangan parameter sebanyak 16% dan memerhatikan peningkatan 16% dalam pemprosesan dalam latihan dan masa inferens.
Bagaimana untuk memudahkan blok Transformer?
Berdasarkan teori perambatan isyarat dan pemerhatian empirikal, pengkaji memperkenalkan cara menjana blok Transformer paling mudah bermula daripada modul Pra-LN (seperti ditunjukkan di bawah).
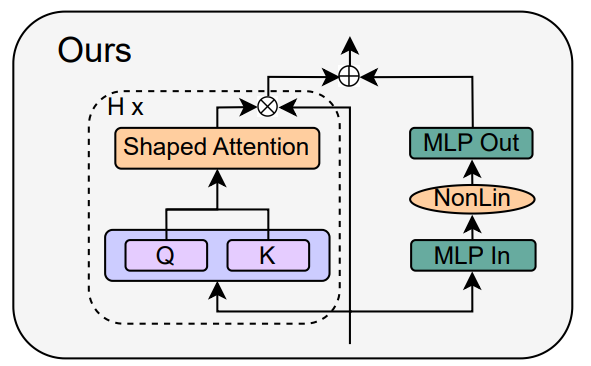
Dalam setiap bahagian Bab 4 kertas kerja, penulis memperkenalkan cara memadam satu komponen blok pada satu masa tanpa menjejaskan kelajuan latihan.
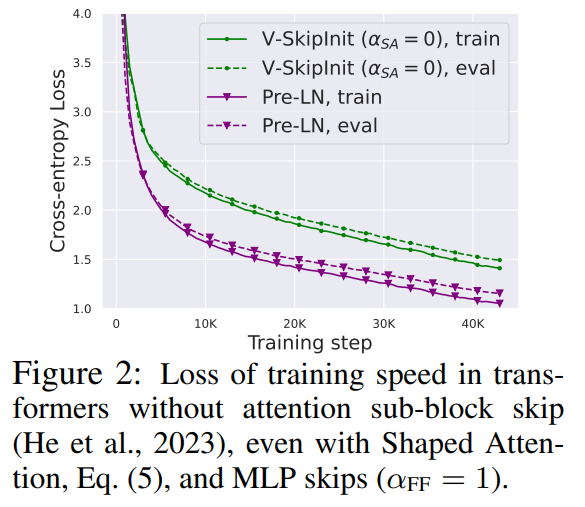
Semua percubaan dalam bahagian ini menggunakan model GPT penyahkod bersaiz 768 lebar 18-blok pada set data CodeParrot set data ini cukup besar supaya apabila pengarang berada dalam mod epos latihan tunggal, jurang isasi umum adalah sangat kecil (lihat Rajah 2), yang membolehkan mereka menumpukan pada kelajuan latihan.
Padamkan baki sambungan
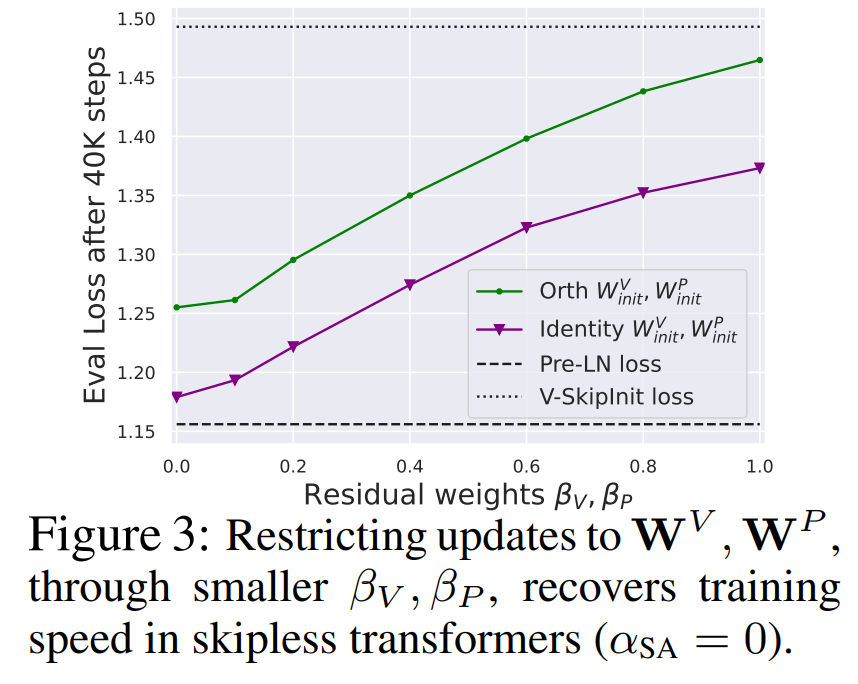
Para penyelidik mula-mula mempertimbangkan untuk memadamkan baki sambungan dalam sub-blok perhatian. Dalam notasi persamaan (1), ini bersamaan dengan menetapkan α_SA kepada 0. Hanya mengalih keluar sambungan baki perhatian boleh membawa kepada kemerosotan isyarat, iaitu keruntuhan pangkat, mengakibatkan kebolehlatihan yang lemah. Dalam Bahagian 4.1 kertas kerja, penyelidik menerangkan kaedah mereka secara terperinci. . Maksudnya, apabila β_V = β_P = 0 dan identiti dimulakan
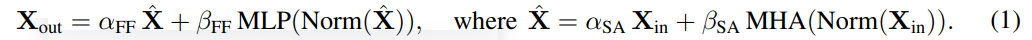
, selepas bilangan langkah latihan yang sama, kajian ini pada asasnya boleh mencapai prestasi blok Pra-LN. Dalam kes ini, W^V = W^P = I mempunyai W^V = W^P = I sepanjang proses latihan, iaitu nilai dan parameter unjuran adalah konsisten. Penulis membentangkan kaedah terperinci dalam Bahagian 4.2.
Memadamkan sambungan sisa sub-blok MLP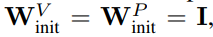
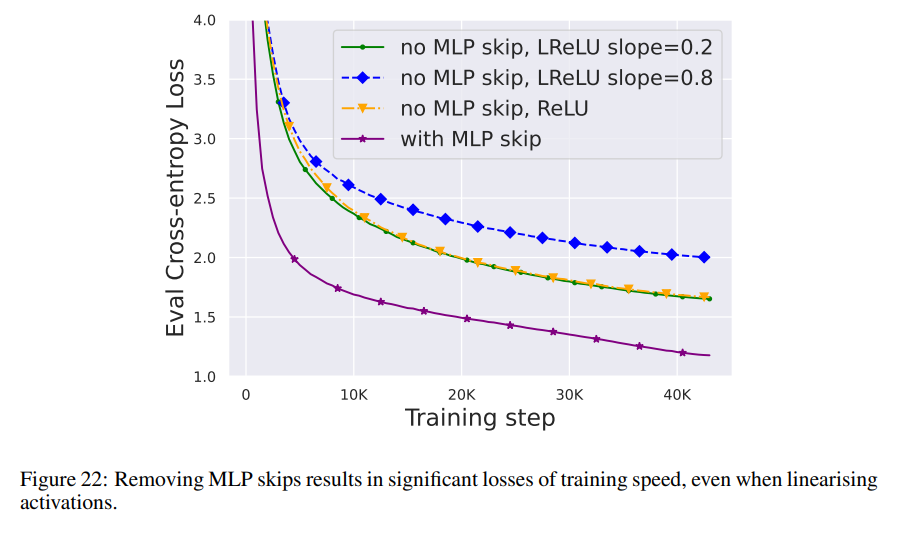
Berbanding dengan modul di atas, memadamkan sambungan baki sub-blok MLP adalah lebih mencabar. Seperti dalam penyelidikan terdahulu, penulis mendapati bahawa apabila menggunakan Adam, tanpa sambungan baki MLP, menjadikan pengaktifan lebih linear melalui perambatan isyarat masih menghasilkan penurunan ketara dalam kelajuan latihan setiap kemas kini, seperti yang ditunjukkan dalam Rajah 22.
Mereka juga mencuba pelbagai variasi permulaan Looks Linear, termasuk pemberat Gaussian, pemberat ortogon atau pemberat identiti, tetapi tidak berjaya. Oleh itu, mereka menggunakan pengaktifan standard (cth. ReLU) sepanjang kerja dan permulaan mereka dalam sub-blok MLP. Pengarang beralih kepada konsep sub-blok MHA dan MLP selari, yang telah terbukti popular dalam beberapa model pengubah besar baru-baru ini, seperti PALM dan ViT-22B. Blok pengubah selari ditunjukkan dalam rajah di bawah.
 Pengarang memperincikan operasi khusus untuk mengalih keluar sambungan sisa sub-blok MLP dalam Bahagian 4.3 kertas itu.
Pengarang memperincikan operasi khusus untuk mengalih keluar sambungan sisa sub-blok MLP dalam Bahagian 4.3 kertas itu.
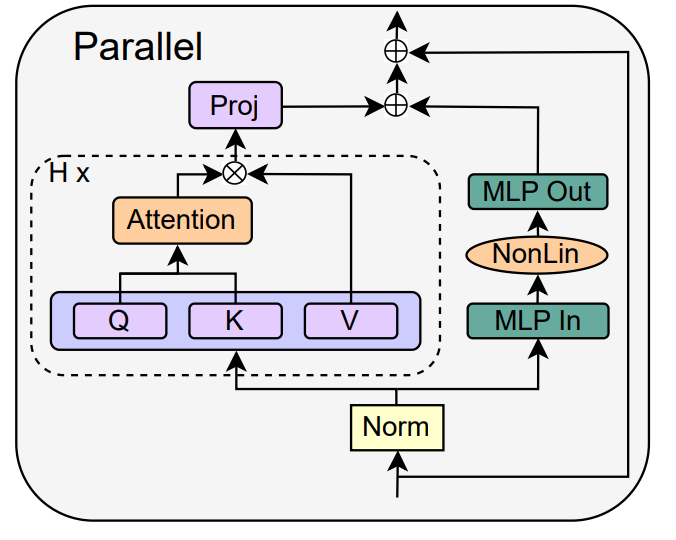
Hasil eksperimen
Peluasan kedalaman
Memandangkan teori perambatan isyarat biasanya memfokuskan pada kedalaman yang besar, degradasi isyarat biasanya berlaku dalam kes ini. Jadi persoalan yang wajar ialah, adakah kelajuan latihan yang dipertingkatkan yang dicapai oleh blok pengubah mudah kami juga meningkat kepada kedalaman yang lebih mendalam?Dapat diperhatikan daripada Rajah 6 bahawa selepas memanjangkan kedalaman daripada 18 blok kepada 72 blok, prestasi kedua-dua model dan pengubah Pra-LN dalam kajian ini bertambah baik, yang menunjukkan bahawa model dipermudah dalam kajian ini bukan sahaja lebih pantas dalam latihan Lebih pantas dan dapat memanfaatkan keupayaan tambahan yang disediakan oleh kedalaman yang lebih mendalam. Malah, apabila normalisasi digunakan, trajektori setiap kemas kini bagi blok dipermudahkan dan Pra-LN dalam kajian ini hampir tidak dapat dibezakan pada kedalaman yang berbeza. 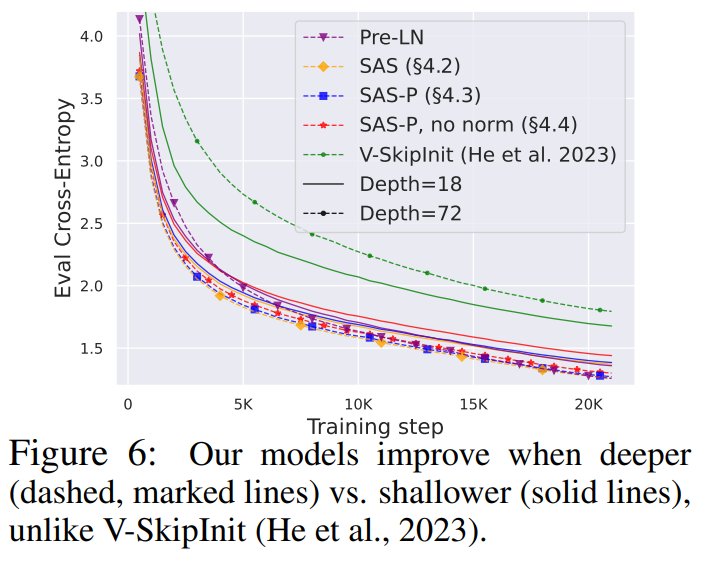
BERT
Seterusnya, pengarang menunjukkan bahawa prestasi blok dipermudahkan mereka digunakan pada set data dan seni bina yang berbeza sebagai tambahan kepada penyahkod autoregresif, serta tugas hiliran. Mereka memilih tetapan popular model BERT pengekod dwiarah sahaja untuk pemodelan bahasa bertopeng dan menggunakan penanda aras hiliran GLUE.
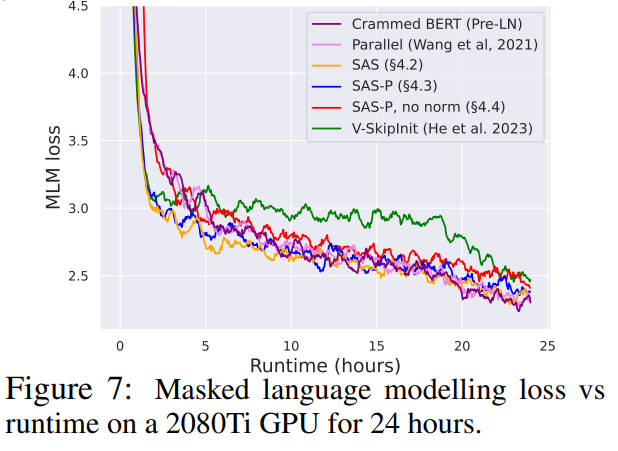
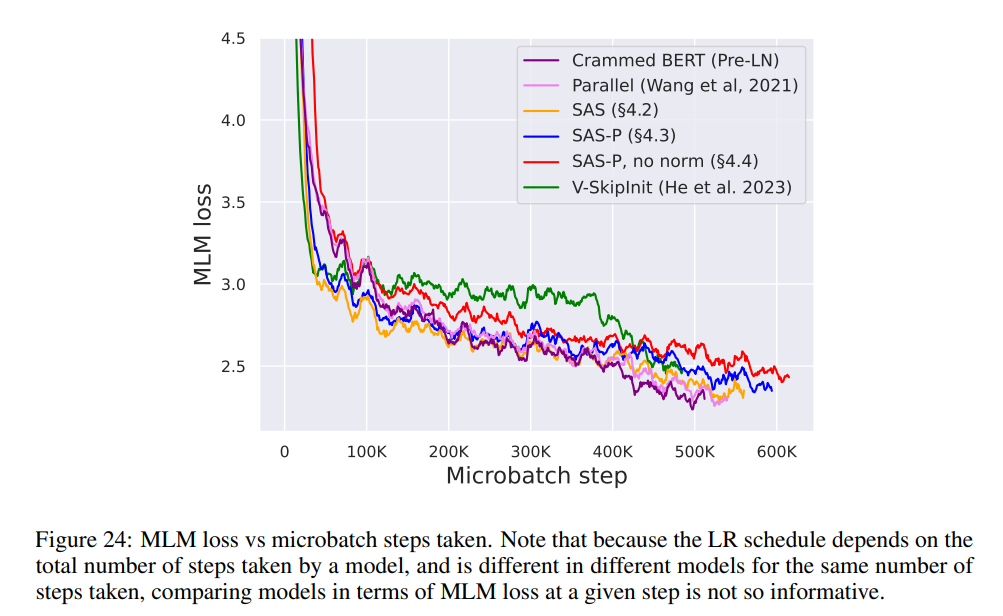
Seperti yang ditunjukkan dalam Rajah 7, dalam masa 24 jam masa jalanan, blok yang dipermudahkan kajian ini adalah setanding dengan kelajuan pra-latihan tugas pemodelan bahasa bertopeng berbanding garis dasar Pra-LN (Crammed). Sebaliknya, mengalih keluar sambungan sisa tanpa mengubah nilai dan unjuran sekali lagi membawa kepada penurunan ketara dalam kelajuan latihan. Dalam Rajah 24, penulis menyediakan gambar rajah setara bagi langkah mikrobatch.
Selain itu, dalam Jadual 1, para penyelidik mendapati bahawa kaedah mereka, selepas penalaan halus pada penanda aras GLUE, menunjukkan prestasi yang setanding dengan penanda aras Crammed BERT.
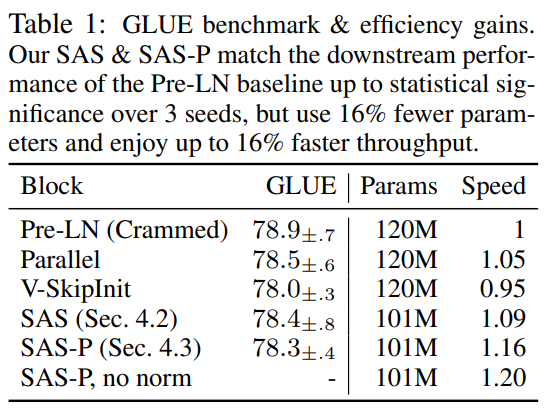
Mereka memecahkan tugas hiliran dalam Jadual 2. Untuk perbandingan yang saksama, mereka menggunakan protokol penalaan halus yang sama seperti Geiping & Goldstein (2023) (5 zaman, hiperparameter tetap untuk setiap tugas, regularisasi keciciran).
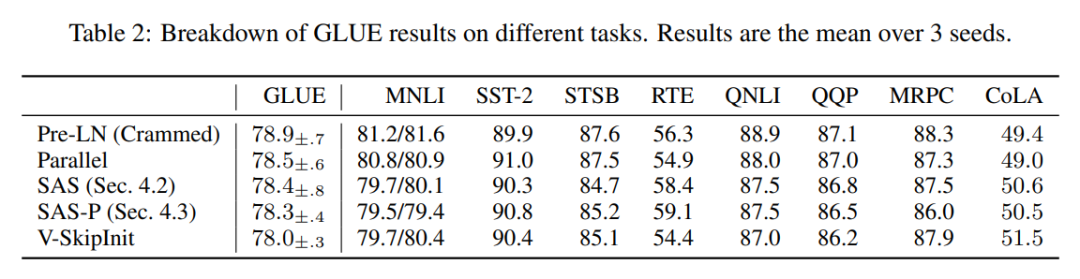
Peningkatan kecekapan
Dalam Jadual 1, penyelidik juga memperincikan bilangan parameter dan kelajuan latihan model menggunakan blok Transformer berbeza dalam tugas pemodelan bahasa bertopeng. Mereka mengira kelajuan sebagai nisbah bilangan langkah mikrobatch yang diambil selama 24 jam pralatihan kepada garis dasar Pra-LN Crammed BERT. Kesimpulannya ialah model menggunakan 16% lebih sedikit parameter, dan SAS-P dan SAS masing-masing adalah 16% dan 9% lebih cepat setiap lelaran daripada blok Pra-LN.
Dapat diambil perhatian bahawa dalam pelaksanaan di sini, blok selari hanya 5% lebih cepat daripada blok Pra-LN, manakala kelajuan latihan yang diperhatikan oleh Chowdhery et al (2022) adalah 15% lebih cepat, menunjukkan bahawa dengan lebih pelaksanaan yang dioptimumkan, Ada kemungkinan bahawa kelajuan latihan keseluruhan boleh dipertingkatkan lagi. Seperti Geiping & Goldstein (2023), pelaksanaan ini juga menggunakan teknologi gabungan operator automatik dalam PyTorch (Sarofeen et al., 2022).
Latihan yang lebih lama
Akhir sekali, memandangkan trend semasa melatih model yang lebih kecil pada lebih banyak data untuk jangka masa yang lebih lama, para penyelidik membincangkan sama ada blok yang dipermudahkan masih boleh mencapai latihan blok Pra-LN selepas kelajuan latihan yang panjang. Untuk melakukan ini, mereka menggunakan model dalam Rajah 5 pada CodeParrot dan berlatih dengan token 3x. Tepatnya, latihan mengambil kira-kira 120K langkah (bukannya 40K langkah) dengan saiz kelompok 128 dan panjang urutan 128, yang menghasilkan kira-kira 2B token.
Seperti yang dapat dilihat dari Rajah 8, apabila lebih banyak token digunakan untuk latihan, kelajuan latihan blok kod SAS dan SAS-P yang dipermudahkan masih setanding dengan, atau lebih baik daripada, blok kod PreLN.
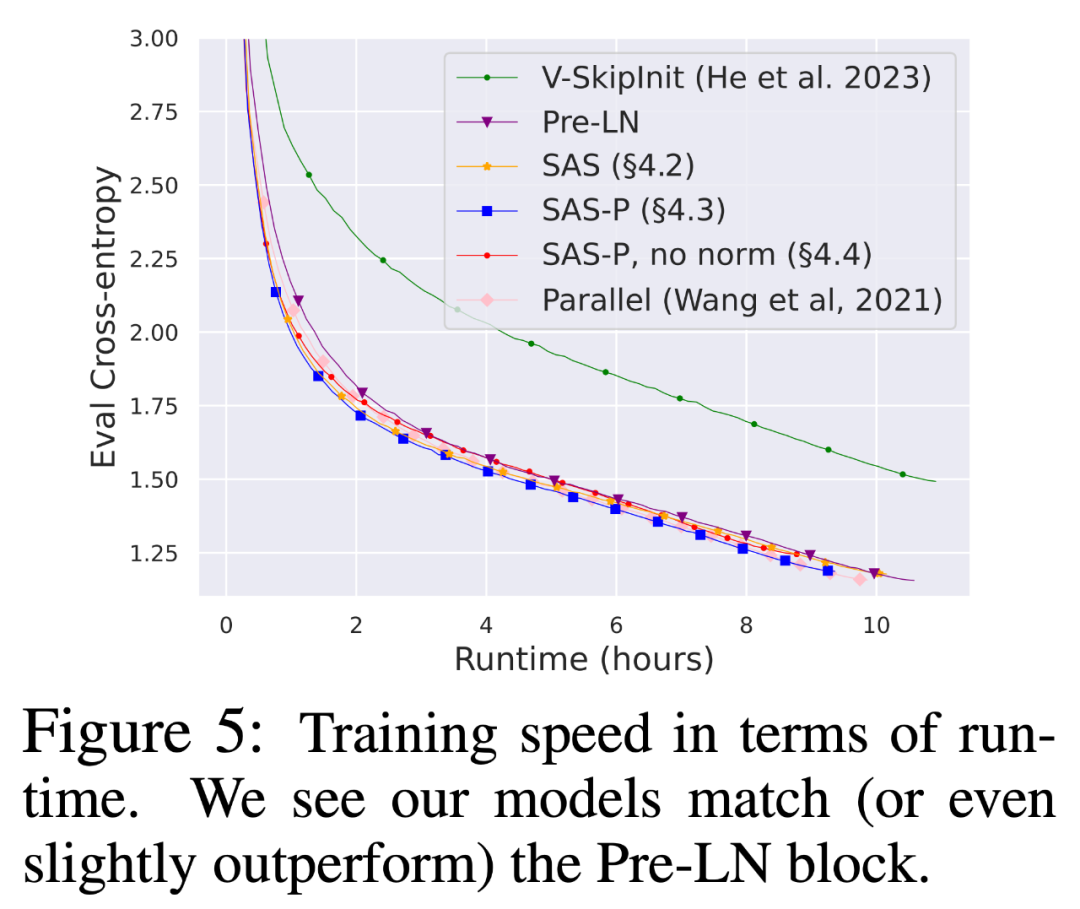
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Netizen dipuji: Transformer mengetuai versi ringkas kertas tahunan ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!