
Rumah >Peranti teknologi >AI >Model ramalan tindak balas bebas templat hujung ke hujung berdasarkan dua tugasan
Model ramalan tindak balas bebas templat hujung ke hujung berdasarkan dua tugasan

- WBOYke hadapan
- 2024-01-12 17:24:06580semak imbas

Diformat semula|
Pautan kertas: https://doi.org/10.1007/s10489-023-05048-8Kod berkaitan: https://github.com/AILBC/BiG2S gambar rajah peningkatan semasa dalam bidang retrosintesis bebas templat Berdasarkan rangka kerja model jujukan, kami seterusnya cuba membina model BiG2S (Graf Dwi Arah kepada Jujukan) yang serentak menyelesaikan tugas ramalan retrosintesis dan ramalan tindak balas hadapan dalam satu model pada skala parameter yang sama Pada masa yang sama, penulis juga mengkaji songsang arus perdana Analisis awal telah dijalankan pada set data sintetik USPTO-50k, dan perbezaan dalam kesukaran ramalan model untuk segmen SMILES yang berbeza semasa proses latihan. dan turun naik kadar pemadanan Top-k model pada set pengesahan telah diterokai, dan kehilangan ketidakseimbangan telah diperkenalkan untuk menangani isu ini serta menambah baik ensemble model dan strategi carian rasuk 
Pada masa ini, input dan output kebanyakan model retrosintetik bebas templat ialah rentetan molekul SMILES, iaitu, menggunakan proses turutan-ke-jujukan (Seq2Seq). Kaedah ini boleh menggunakan rangka kerja model sedia ada dengan baik dalam bidang pemprosesan bahasa semula jadi, serta aliran pemprosesan data yang matang untuk kaedah perwakilan SMILES Walau bagaimanapun, memandangkan SMILES sebagai urutan rentetan satu dimensi tidak dapat mewakili dan Menggunakan dengan baik maklumat struktur dua dimensi/tiga dimensi yang terkandung dalam graf molekul, kaedah graf-ke-jujukan (Graph2Seq) yang menggunakan graf molekul dan bukannya SMILES kerana input model secara beransur-ansur muncul dalam medan ini, atau maklumat struktur tambahan graf molekul dibenamkan ke dalam urutan SMILES kaedah Urutan-ke-jujukan dalam . Kedua-dua kaedah boleh menggunakan ciri struktur yang kaya daripada graf molekul
Berdasarkan perkara ini, kertas kerja ini berdasarkan kaedah graf-ke-jujukan yang muncul dan melatih tugas-tugas ramalan tindak balas retrosintesis dan ke hadapan secara serentak pada model berasaskan SMILES yang asal. . Berdasarkan penanda aras penerokaan yang berkaitan, kami meneroka secara menyeluruh pembinaan dan eksperimen jenis model dwi-tugas ini, dan juga meneroka dan menganalisis ketidakseimbangan kesukaran dan turun naik kadar pemadanan Top-k yang dipaparkan oleh model semasa proses latihan. ;Model BiG2S yang dibina atas dasar ini boleh mengendalikan tugasan retrosintesis dan ramalan tindak balas hadapan dengan lebih baik dalam set data arus perdana, dan mencapai keupayaan ramalan tindak balas yang konsisten dengan model retrosintesis tanpa templat lain tanpa menggunakan peningkatan data
Rangka kerja keseluruhan perlu ditulis semula
Struktur keseluruhan BiG2S ialah penyahkod pengekod hujung ke hujung, seperti yang ditunjukkan dalam Rajah 1. Bahagian pengekod menggunakan rangkaian graf penghantaran mesej terarah tempatan dan Transformer graf global yang menggabungkan maklumat bias struktur graf untuk menjana perwakilan nod graf molekul akhir. Penyahkod menggunakan penyahkod Transformer standard untuk menjana urutan SMILES molekul sasaran secara autoregresifPerlu diingat bahawa untuk mempelajari retrosintesis dan ramalan tindak balas hadapan pada masa yang sama, input kepada penyahkod tambahan mengandungi dua kali ganda. urutan tanpa menambah maklumat kedudukan. Pada masa yang sama, lapisan normalisasi dan lapisan linear akhir pada bahagian penyahkod mempunyai dua set parameter, yang digunakan untuk mempelajari tugas retrosintesis dan tugas ramalan tindak balas hadapan masing-masingRajah 1: rajah rangka kerja keseluruhan BiG2S
Memerlukan dua tugas Rangka kerja latihanRetrosintesis dan ramalan tindak balas hadapan ialah dua tugas yang berkaitan Tugas retrosintesis menggunakan produk sebagai input dan reaktan sebagai output sasaran, manakala tugas ramalan tindak balas hadapan melakukan sebaliknya. Terdapat hubungan rapat antara kedua-dua tugas ini, kerana ia boleh diubah menjadi tugas ramalan tindak balas ke hadapan dengan menukar input dan output sasaran tugas retrosintesis
Oleh itu, beberapa model tanpa templat berdasarkan SMILES telah mencuba Sintesis dan ke hadapan ramalan tindak balas digunakan sebagai matlamat latihan untuk meningkatkan pemahaman tindak balas kimia dan telah mencapai keputusan tertentu. Berdasarkan idea ini, penulis seterusnya cuba memperkenalkan latihan dwi-tugas ke dalam model graf-ke-jujukan
Secara khusus, penulis berdasarkan strategi perkongsian parameter yang sebelum ini digunakan pada kaedah lain, dalam lapisan normalisasi penyahkod dan lapisan linear akhir Dua set parameter khusus tugasan dibina dalam. Dalam modul lain, kedua-dua jenis tugasan berkongsi set parameter. Pada masa yang sama, label dwi-tugas tambahan ditambahkan pada nod graf molekul input dan jujukan input awal penyahkod. Dengan cara ini, walaupun semasa mengawal saiz model keseluruhan, model ini dapat membezakan antara kedua-dua jenis tugasan dan mempelajari pengagihan data mereka yang berbeza
Memerlukan latihan dan pengoptimuman inferens
Semasa proses latihan, penulis selanjutnya merekodkan dan menganalisis Dua jenis masalah model yang dicerminkan dalam proses latihan
Pertama, pengarang merekodkan kekerapan kejadian aksara SMILES yang berbeza dalam USPTO-50k dan ketepatan ramalan yang sepadan semasa latihan, seperti yang ditunjukkan dalam Rajah 2. Semasa proses latihan, untuk S dan Br, yang masing-masing menyumbang 0.4% dan 0.3% dalam set latihan, perbezaan mutlak dalam ketepatan ramalan keseluruhan mencapai 8%. Ini pada mulanya menunjukkan bahawa terdapat perbezaan yang jelas dalam kesukaran ramalan antara struktur / serpihan molekul yang berbeza Oleh itu, penulis mengurangkan masalah tersebut dengan memperkenalkan fungsi kehilangan tidak seimbang (seperti Focal Loss), supaya model dapat memberi perhatian lebih kepada. ketepatan semasa latihan. Serpihan molekul yang lebih rendah
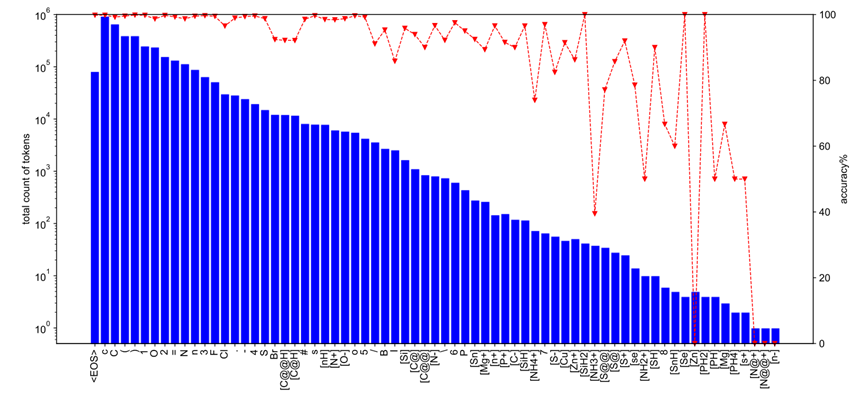
Rajah 2: Dalam set latihan USPTO-50k, kekerapan berlakunya watak SMILES yang berbeza dan ketepatan ramalan keseluruhannya semasa latihan
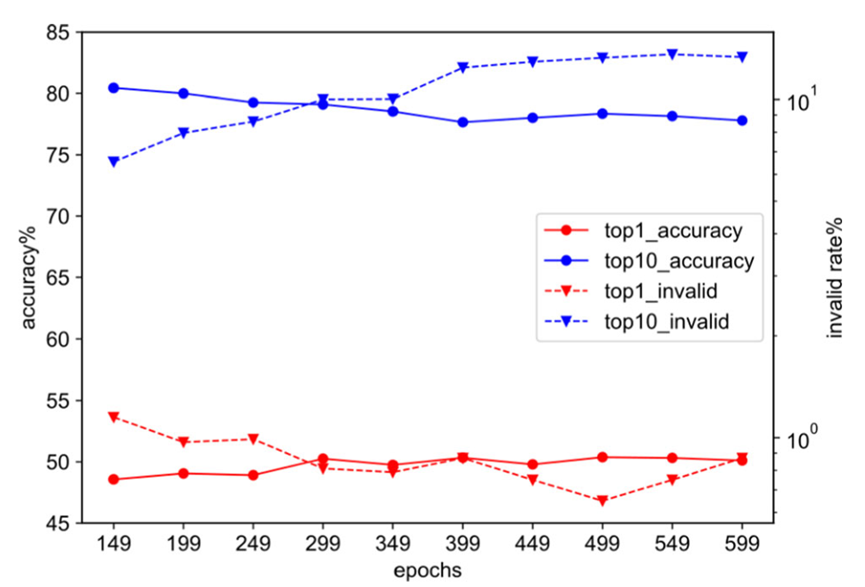
Selain itu, penulis juga merekodkan pengesahan model semasa latihan Kualiti keputusan ramalan perubahan set, seperti yang ditunjukkan dalam Rajah 3. Penulis mendapati bahawa pada peringkat pertengahan dan akhir latihan set data USPTO-50k, ketepatan Top-1 model pada set pengesahan masih bertambah baik, tetapi terdapat penurunan dalam kualiti ramalan Top-3, Top-5 , dan Top-10 Penurunan ketara
Untuk meningkatkan kualiti ramalan 1 teratas model sambil mengekalkan kualiti keseluruhan hasil penjanaan reaktan sepuluh teratas model, kami juga membina jenis strategi penyepaduan model berdasarkan penunjuk penilaian tersuai . Khususnya, kami membina baris gilir untuk menyimpan model dan mengisih model yang disimpan mengikut penunjuk penilaian yang telah ditetapkan (seperti ketepatan Top-1, ketepatan Top-k berwajaran, dll.). Sepanjang proses latihan, kami menyimpan model calon secara dinamik dan menjana model ensemble secara automatik berdasarkan 3-5 teratas dalam baris gilir, dengan itu mengekalkan model Top-k dengan kualiti ramalan tertinggi. Dalam fasa inferens, kami juga membina semula strategi carian rasuk berdasarkan rangka kerja baharu dan lebih memfokuskan pada keluasan carian untuk meningkatkan kualiti keseluruhan model hasil yang dijana Top-k
Memerlukan set data penanda aras dalam eksperimen dwi-tugas
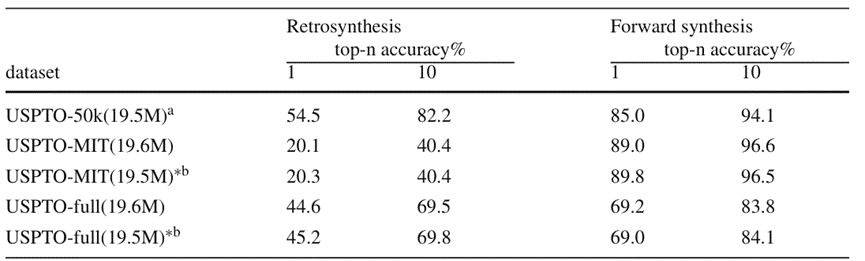
Pengarang menjalankan ia dalam tugas retrosintesis dan tugas ramalan tindak balas hadapan Eksperimen telah dijalankan menggunakan set data USPTO-50k, USPTO-MIT, dan penuh USPTO yang mengandungi 50,000, 500,000, dan 1 juta data tindak balas kimia. Dalam eksperimen, prestasi model dwi tugas dan model tugas tunggal telah dibandingkan. Mengikut keputusan ujian dalam Rajah 4,
Dalam set data berskala kecil, BiG2S mencapai ketepatan ramalan utama dalam tugasan retrosintesis berdasarkan latihan dwi-tugas, di samping mengekalkan ketepatan ramalan tindak balas ke hadapan yang tinggi walau bagaimanapun, ia adalah berat sebelah ke arah tindak balas positif Dalam set data USPTO-MIT untuk ramalan tindak balas dan set data berskala besar USPTO-penuh, disebabkan oleh had jumlah parameter keseluruhan model, prestasi model selepas latihan dwi-tugas mempunyai menurun. Walau bagaimanapun, keupayaan untuk memproses secara serentak tugas retrosintesis dan tugas ramalan tindak balas hadapan diperoleh daripada model dwi-tugas dengan bilangan parameter yang hampir sama dan pengurangan kecil dalam keupayaan ramalan tindak balas (perbezaan mutlak dalam ketepatan Top-k adalah sekitar 0.5%). Dari perspektif keupayaan, model BiG2S telah mencapai matlamat yang dijangkakan
Analisis semula eksperimen ablasi
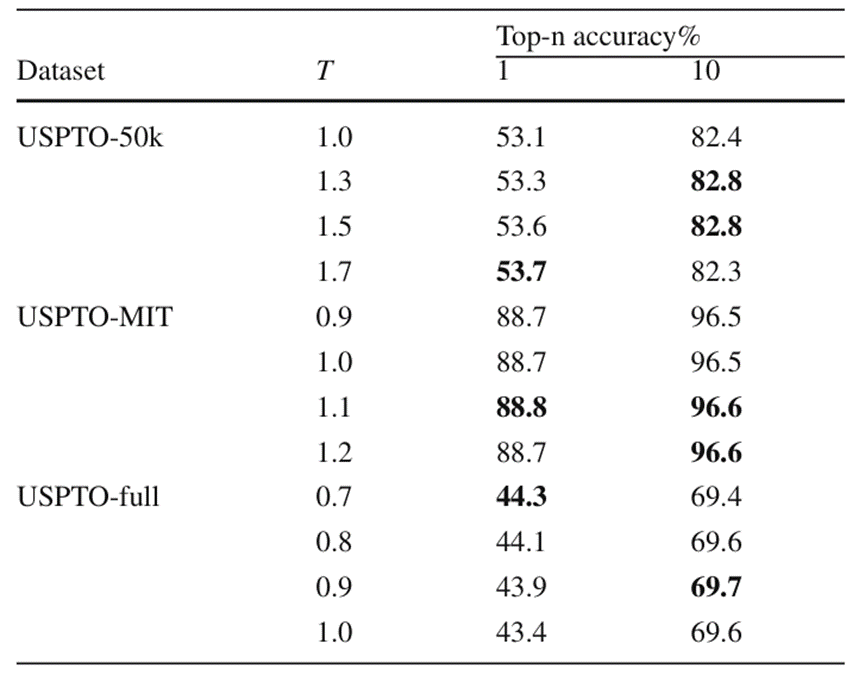
Pengarang mengesahkan lagi algoritma carian pancaran baharu dan hiperparameter suhu optimum BiG2S apabila meramalkan dalam set data yang berbeza selepas menggunakan kehilangan ketidakseimbangan melalui eksperimen ablasi. Hiperparameter suhu di sini merujuk kepada parameter suhu T yang digunakan dalam Softmax untuk mengawal taburan kebarangkalian keluaran. Keputusan eksperimen ditunjukkan dalam Rajah 5 dan Rajah 6
Dalam eksperimen pada algoritma carian rasuk, boleh diperhatikan OpenNMT mengembangkan lebar carian kepada 3 kali manakala masa carian hanya berkembang kepada 1.74 kali, manakala carian rasuk baharu algoritma Apabila ketepatan Top-1 konsisten dengan OpenNMT, masa carian keseluruhan meningkat sebanyak 1-2 kali ganda tetapi dari segi kualiti hasil ramalan Top-10, algoritma carian rasuk baharu mempunyai kelebihan ketepatan mutlak sekurang-kurangnya; 3% berbanding dengan OpenNMT Serta kelebihan perkadaran molekul yang berkesan sebanyak 2%, boleh dikatakan bahawa algoritma carian pancaran baharu telah meningkatkan kualiti hasil carian Top-k keseluruhan model dengan ketara pada kos masa carian.
Apabila menjalankan eksperimen pada hiperparameter suhu, para penyelidik Didapati bahawa menggunakan parameter suhu yang lebih besar pada set data berskala kecil boleh meningkatkan ketepatan ramalan Top-k keseluruhan dengan ketara. Dalam set data yang lebih besar, memandangkan saiz model BiG2S tidak dapat menyesuaikan sepenuhnya dengan semua data tindak balas, memilih parameter suhu yang lebih kecil pada masa ini sering membantu carian model

Kesimpulan kajian menunjukkan...
Dalam artikel ini, penulis mencadangkan model ramalan tindak balas tanpa templat yang dipanggil BiG2S, yang boleh mengendalikan tugas retrosintesis secara serentak dan tugas ramalan tindak balas ke hadapan . Dengan menggunakan strategi perkongsian parameter yang sesuai dan label dwi-tugas tambahan, BiG2S dapat menyelesaikan tugas retrosintesis dan tugas ramalan tindak balas pada set data saiz berbeza dengan bilangan parameter yang lebih kecil, dan keupayaan ramalan keseluruhannya setanding dengan model arus perdana
Untuk Untuk menyelesaikan masalah kesukaran ramalan tidak sekata bagi aksara SMILES yang berbeza dan turun naik dalam ketepatan ramalan Top-k semasa latihan model, penulis memperkenalkan kehilangan ketidakseimbangan, strategi penyepaduan automatik model berdasarkan penunjuk penilaian tersuai dan algoritma carian rasuk berdasarkan a rangka kerja baharu untuk mengurangkan masalah ini
BiG2S telah menunjukkan keupayaan ramalan dwi-tugas yang baik pada tiga set data arus perdana dengan saiz yang berbeza, dan eksperimen ablasi selanjutnya juga membuktikan keberkesanan latihan dan strategi inferens yang diperkenalkan tambahan
Atas ialah kandungan terperinci Model ramalan tindak balas bebas templat hujung ke hujung berdasarkan dua tugasan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!