Animate124, tukar satu gambar menjadi video 3D dengan mudah. . Mengimbas kembali pada tahun lalu, kami telah menyaksikan kemajuan ketara dalam kualiti dan kawalan teknologi penjanaan statik 3D. Pembangunan teknologi bermula daripada penjanaan berasaskan teks, disepadukan secara beransur-ansur ke dalam imej paparan tunggal, dan kemudian dibangunkan untuk menyepadukan berbilang isyarat kawalan.
Berbanding dengan ini, penjanaan pemandangan dinamik 3D masih di peringkat awal. Pada awal 2023, Meta melancarkan MAV3D
, menandakan percubaan pertama menjana video 3D berdasarkan teks. Walau bagaimanapun, terhad oleh kekurangan model penjanaan video sumber terbuka, kemajuan dalam bidang ini agak perlahan.
Namun, kini, teknologi penjanaan video 3D berdasarkan gabungan grafik dan teks telah dikeluarkan! Walaupun penjanaan video 3D berasaskan teks mampu menghasilkan kandungan yang pelbagai, ia masih mempunyai batasan dalam mengawal butiran dan pose objek. Dalam bidang penjanaan statik 3D, objek 3D boleh dibina semula dengan berkesan menggunakan satu imej sebagai input. Diilhamkan oleh ini, pasukan penyelidik dari
National University of Singapore (NUS) dan Huawei mencadangkan model Animate124
. Model ini menggabungkan satu imej dengan penerangan tindakan yang sepadan untuk membolehkan kawalan tepat penjanaan video 3D. Laman utama projek: https://animate124.github.io/Alamat kertas: https://arxiv.org/abs/2311.14603
- com/HeliosZhao/Animate124
Kaedah teras
dan kord halus pengoptimuman, artikel ini membahagikan penjanaan video 3D kepada 3 peringkat : 1) Fasa penjanaan statik: Gunakan model penyebaran graf Vincentian dan graf 3D untuk menjana objek 3D daripada imej tunggal 2) Fasa penjanaan kasar dinamik: Gunakan model video Vincentian untuk mengoptimumkan tindakan mengikut huraian bahasa; Selain itu, ControlNet penalaan halus diperibadikan digunakan untuk mengoptimumkan dan menambah baik sisihan yang disebabkan oleh perihalan bahasa peringkat kedua pada penampilan.
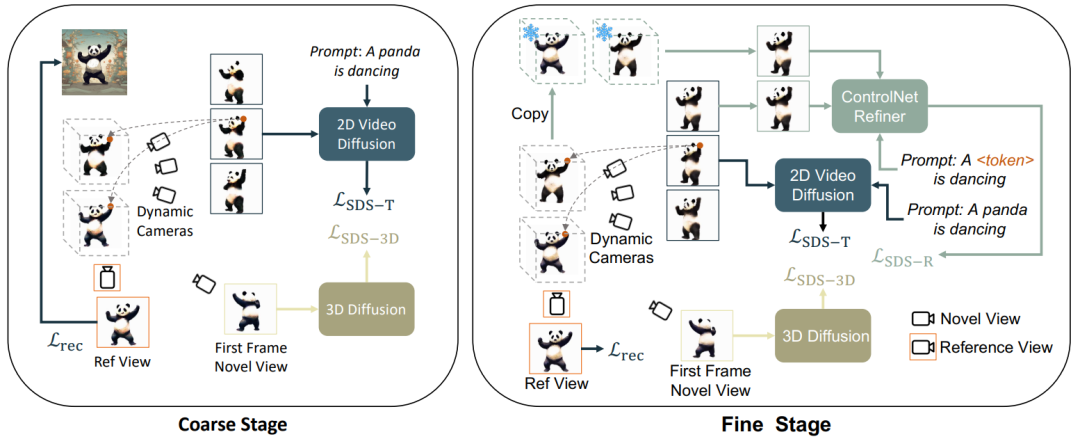 Figure 1. Rangka Kerja Keseluruhan Generasi Generasi
Figure 1. Rangka Kerja Keseluruhan Generasi Generasi
ini meneruskan kaedah Magic123, menggunakan penyebaran yang stabil dan penyebaran 3D (zero- 1-ke-3
) Hasilkan objek statik berdasarkan gambar:
Untuk perspektif yang sepadan dengan gambar bersyarat, gunakan juga fungsi kehilangan untuk mengoptimumkan: Melalui dua matlamat pengoptimuman di atas, pelbagai perspektif yang konsisten diperolehi 3D objek (peringkat ini ditinggalkan dalam rajah bingkai). 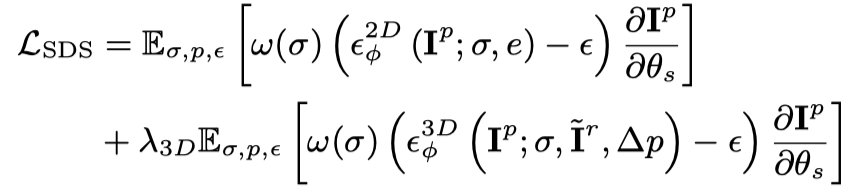
Penjanaan kasar dinamik
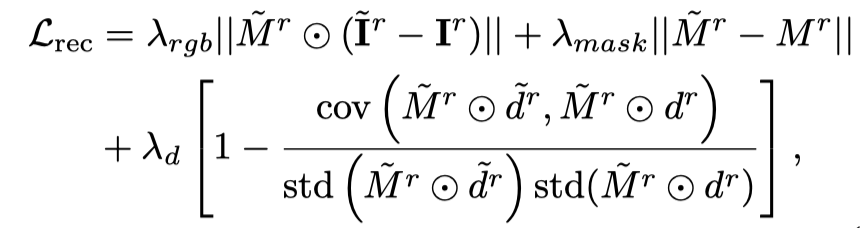
Peringkat ini terutamanya menggunakan model penyebaran video Vinson
, yang menganggap 3D statik sebagai bingkai awal dan menjana tindakan Khususnya, model 3D dinamik (NeRF dinamik) menghasilkan video berbilang bingkai dengan cap masa berterusan dan memasukkan video ini ke dalam model penyebaran video Vincent, menggunakan kehilangan penyulingan SDS untuk mengoptimumkan model 3D dinamik:
Hanya menggunakan Vincent video Kehilangan penyulingan akan menyebabkan model 3D melupakan kandungan gambar, dan pensampelan rawak akan membawa kepada latihan yang tidak mencukupi pada peringkat awal dan akhir video. Oleh itu, penyelidik dalam kertas ini terlebih sampel cap masa mula dan tamat. Dan, apabila mengambil sampel bingkai awal, fungsi statik tambahan digunakan untuk pengoptimuman (kehilangan penyulingan SDS bagi graf 3D): Oleh itu, fungsi kehilangan pada peringkat ini ialah: 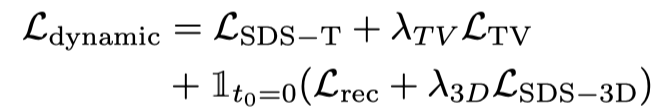
Walaupun dengan pensampelan bingkai awal dan penyeliaan tambahan padanya, semasa proses penyebaran objek video menggunakan model, penampilan masih dipengaruhi oleh teks, yang mengimbangi imej rujukan. Oleh itu, kertas kerja ini mencadangkan peringkat pengoptimuman semantik untuk menambah baik offset semantik melalui model yang diperibadikan. Memandangkan hanya terdapat satu gambar, model video Vincent tidak boleh diperibadikan dilatih Artikel ini memperkenalkan model resapan berdasarkan imej dan teks, dan melakukan penalaan halus yang diperibadikan pada model resapan ini. Model penyebaran ini tidak seharusnya mengubah kandungan dan tindakan video asal, tetapi hanya melaraskan penampilan. Oleh itu, artikel ini menggunakan model grafik ControlNet-Tile, menggunakan bingkai video yang dijana pada peringkat sebelumnya sebagai syarat dan mengoptimumkan mengikut bahasa. ControlNet adalah berdasarkan model Stable Diffusion Ia hanya perlu melakukan penalaan halus yang diperibadikan (Textual Inversion) pada Stable Diffusion untuk mengekstrak maklumat semantik dalam imej rujukan. Selepas penalaan halus diperibadikan, layan video sebagai imej berbilang bingkai dan gunakan ControlNet untuk mengawasi satu imej: 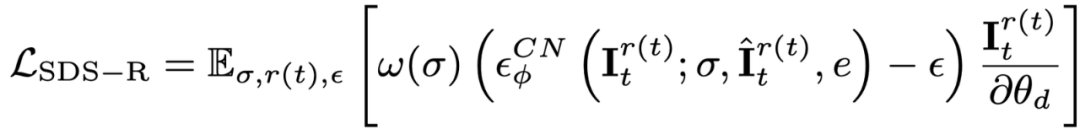
Selain itu, kerana ControlNet menggunakan imej kasar sebagai syarat, panduan tanpa pengelas (CFG) boleh menggunakan julat normal (10 kiri dan kanan) dan bukannya menggunakan nilai yang sangat besar (biasanya 100) seperti graf Vincentian dan model video Vincentian. CFG yang terlalu besar akan menyebabkan imej terlampau tepu Oleh itu, menggunakan model penyebaran ControlNet boleh mengurangkan fenomena lebih tepu dan mencapai hasil penjanaan yang lebih baik. Penyeliaan peringkat ini digabungkan dengan kehilangan peringkat dinamik dan penyeliaan ControlNet: 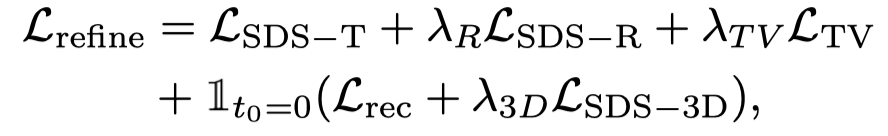
Sebagai model penjanaan video 3D berasaskan imej pertama, artikel ini dibandingkan dengan dua model penjanaan video 3D. model dan MAV3D dibandingkan. Animate124 mempunyai hasil yang lebih baik berbanding kaedah lain. Perbandingan hasil visual
Rajah 2. Animasikan124 berbanding dengan dua garis dasar
Bandingkan dengan video MAV3D Vincent 3D
Rajah 3.1. Perbandingan bagi video 3D grafik Animate124 dan MAV3D Perbandingan keputusan kuantitatif penggunaan CL.IP dan penunjuk kualiti ini persamaan dengan teks dan perolehan semula ketepatan, persamaan dengan imej, dan ketekalan temporal. Penunjuk penilaian manual termasuk persamaan dengan teks, persamaan dengan gambar, kualiti video, realisme pergerakan dan amplitud pergerakan. Penilaian manual diwakili oleh nisbah model tunggal kepada pemilihan Animate124 pada metrik yang sepadan.
Berbanding dengan dua model asas, Animate124 mencapai hasil yang lebih baik dalam kedua-dua CLIP dan penilaian manual.

Table 1. Perbandingan kuantitatif antara animate124 dan dua baselines animate124 adalah yang pertama untuk mengubah sebarang imej menjadi 3D berdasarkan kaedah penerangan teks. Ia menggunakan pelbagai model resapan untuk penyeliaan dan bimbingan, mengoptimumkan rangkaian perwakilan dinamik 4D untuk menjana video 3D berkualiti tinggi.
Atas ialah kandungan terperinci Dengan hanya gambar dan arahan tindakan, Animate124 boleh menjana video 3D dengan mudah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

