

 Peranti teknologiAIBolehkah penyelidikan AI juga belajar daripada Impresionisme? Orang yang seperti hidup ini sebenarnya adalah model 3D
Peranti teknologiAIBolehkah penyelidikan AI juga belajar daripada Impresionisme? Orang yang seperti hidup ini sebenarnya adalah model 3D

Abad ke-19 ialah zaman pergerakan seni Impresionisme popular dalam bidang seni lukis, seni ukir, seni cetak dan lain-lain. Impresionisme dicirikan oleh penggunaan sapuan berus staccato yang pendek dengan sedikit mengejar ketepatan formal, yang kemudiannya berkembang menjadi gaya seni Impresionis. Ringkasnya, sapuan berus artis impresionis tidak diubah suai, menunjukkan ciri-ciri yang jelas, tidak mengejar ketepatan formal, malah agak kabur. Artis impresionis memperkenalkan konsep saintifik cahaya dan warna ke dalam lukisan dan merevolusikan konsep warna tradisional.
Dalam D3GA, penulis mempunyai matlamat yang unik Dia berharap untuk mencipta kesan prestasi foto-realistik dengan melakukan sebaliknya. Untuk mencapai matlamat ini, penulis secara kreatif menggunakan teknologi percikan Gaussian dalam D3GA sebagai "strok berus segmen" moden untuk membina struktur dan penampilan watak maya dan mencapai Kesan masa nyata dan stabil.

"Sunrise·Impression" ialah karya perwakilan pelukis Impresionis terkenal Monet.

Untuk mencipta imej manusia yang realistik yang boleh menjana kandungan baharu untuk animasi, pembinaan avatar pada masa ini memerlukan sejumlah besar data berbilang paparan. Ini kerana kaedah monokular mempunyai ketepatan yang terhad. Selain itu, teknik sedia ada memerlukan pra-pemprosesan yang kompleks, termasuk pendaftaran 3D yang tepat. Walau bagaimanapun, mendapatkan data pendaftaran ini memerlukan lelaran dan sukar untuk disepadukan ke dalam proses hujung ke hujung. Selain itu, terdapat kaedah yang tidak memerlukan pendaftaran yang tepat dan berdasarkan medan sinaran saraf (NeRF). Walau bagaimanapun, kaedah ini selalunya lambat pada pemaparan masa nyata atau menghadapi kesukaran dengan animasi pakaian.
Kerbl et al mencadangkan kaedah pemaparan yang dipanggil 3D Gaussian Splatting (3DGS), yang dipertingkatkan berdasarkan kaedah pemaparan Percikan Permukaan klasik. Berbanding dengan kaedah terkini berdasarkan medan sinaran saraf, 3DGS mampu menghasilkan imej berkualiti tinggi pada kadar bingkai yang lebih pantas dan tanpa memerlukan pemulaan 3D yang sangat tepat.
Walau bagaimanapun, 3DGS pada asalnya direka untuk adegan statik. Pada masa ini, sesetengah orang telah mencadangkan kaedah Gaussian Splating berdasarkan keadaan masa, yang boleh digunakan untuk menghasilkan adegan dinamik. Kaedah ini hanya boleh memainkan semula apa yang telah diperhatikan sebelum ini dan oleh itu tidak sesuai untuk menyatakan gerakan baru atau tidak kelihatan sebelum ini.
Berdasarkan medan sinaran saraf yang dipacu, pengarang memodelkan rupa dan ubah bentuk manusia 3D, meletakkan mereka dalam ruang yang dinormalkan, tetapi menggunakan Gaussians 3D dan bukannya medan sinaran. Selain prestasi yang lebih baik, Gaussian Splatting menghapuskan keperluan untuk menggunakan heuristik pensampelan sinar kamera.
Masalah selebihnya adalah untuk menentukan isyarat yang mencetuskan ubah bentuk sangkar ini. Teknologi terkini dalam avatar berasaskan pemacu memerlukan isyarat input padat, seperti imej RGB-D atau malah berbilang kamera, tetapi kaedah ini mungkin tidak sesuai untuk situasi di mana jalur lebar penghantaran agak rendah. Dalam kajian ini, penulis menggunakan input yang lebih padat berdasarkan pose manusia, termasuk sudut sendi rangka dan titik kunci muka 3D dalam bentuk kuaternion.
Dengan melatih model khusus individu pada sembilan jujukan berbilang paparan berkualiti tinggi yang meliputi pelbagai bentuk badan, pergerakan dan pakaian (tidak terhad kepada pakaian intim), kami kemudiannya boleh mencipta pose baharu untuk mana-mana subjek.


Gambaran keseluruhan kaedah

- Pautan kertas: https://arxiv.org/pdf/2311.08581.pdf
- Pautan projek: https://zielon.github.io/d3ga/
Pautan projek: https://zielon.github.io/d3ga/
Current digunakan untuk mengevolumetrikkan aksara maya secara dinamik sama ada memetakan titik dari ruang ubah bentuk kepada ruang kanonik atau bergantung semata-mata pada pemetaan hadapan. Kaedah berdasarkan pemetaan belakang cenderung untuk mengumpul ralat dalam ruang kanonik kerana ia memerlukan hantaran belakang yang terdedah kepada ralat dan bermasalah dalam memodelkan kesan bergantung kepada perspektif.

D3GA menggunakan pose 3D ϕ, benam muka κ, sudut pandangan dk dan sangkar kanonik v (dan ciri warna dinyahkod secara automatik hi) untuk menjana pemaparan akhir C¯ dan pemaparan pensegmenan tambahan P¯. Input di sebelah kiri diproses melalui tiga rangkaian (ΨMLP, ΠMLP, ΓMLP) setiap bahagian aksara maya untuk menjana anjakan sangkar Δv, ubah bentuk Gaussian bi, qi, si, dan warna/ketelusan ci, oi.

Hasil eksperimen
 D3GA dinilai berdasarkan metrik seperti SSIM, PSNR dan LPIPS metrik persepsi. Jadual 1 menunjukkan bahawa D3GA mempunyai prestasi terbaik dalam PSNR dan SSIM antara kaedah yang hanya menggunakan LBS (iaitu, tidak perlu mengimbas data 3D untuk setiap bingkai), dan mengatasi semua kaedah FFD dalam penunjuk ini, kedua selepas BD. FFD, walaupun isyarat latihannya lemah dan tiada imej ujian (DVA telah diuji menggunakan kesemua 200 kamera).
D3GA dinilai berdasarkan metrik seperti SSIM, PSNR dan LPIPS metrik persepsi. Jadual 1 menunjukkan bahawa D3GA mempunyai prestasi terbaik dalam PSNR dan SSIM antara kaedah yang hanya menggunakan LBS (iaitu, tidak perlu mengimbas data 3D untuk setiap bingkai), dan mengatasi semua kaedah FFD dalam penunjuk ini, kedua selepas BD. FFD, walaupun isyarat latihannya lemah dan tiada imej ujian (DVA telah diuji menggunakan kesemua 200 kamera).
 Perbandingan kualitatif menunjukkan bahawa D3GA boleh memodelkan pakaian dengan lebih baik daripada kaedah terkini yang lain, terutamanya pakaian longgar seperti skirt atau seluar peluh (Rajah 4). FFD adalah singkatan kepada Free Deformation Mesh, yang mengandungi isyarat latihan yang lebih kaya daripada jejaring LBS (Rajah 9).
Perbandingan kualitatif menunjukkan bahawa D3GA boleh memodelkan pakaian dengan lebih baik daripada kaedah terkini yang lain, terutamanya pakaian longgar seperti skirt atau seluar peluh (Rajah 4). FFD adalah singkatan kepada Free Deformation Mesh, yang mengandungi isyarat latihan yang lebih kaya daripada jejaring LBS (Rajah 9).


Atas ialah kandungan terperinci Bolehkah penyelidikan AI juga belajar daripada Impresionisme? Orang yang seperti hidup ini sebenarnya adalah model 3D. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

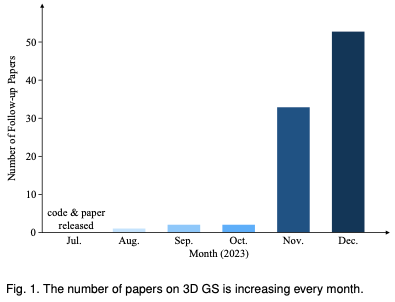 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?Jan 17, 2024 pm 02:57 PM写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符号Apr 24, 2023 pm 10:28 PM您一定记得,尤其是如果您是Teams用户,Microsoft在其以工作为重点的视频会议应用程序中添加了一批新的3DFluent表情符号。在微软去年宣布为Teams和Windows提供3D表情符号之后,该过程实际上已经为该平台更新了1800多个现有表情符号。这个宏伟的想法和为Teams推出的3DFluent表情符号更新首先是通过官方博客文章进行宣传的。最新的Teams更新为应用程序带来了FluentEmojis微软表示,更新后的1800表情符号将为我们每天
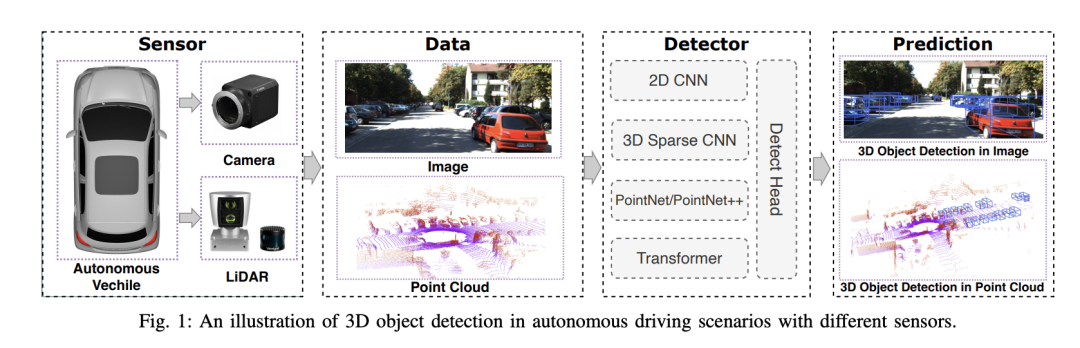 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述Jan 26, 2024 am 11:18 AM0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下载、安装和使用指南Apr 26, 2023 am 11:28 AM当八卦开始传播新的Windows11正在开发中时,每个微软用户都对新操作系统的外观以及它将带来什么感到好奇。经过猜测,Windows11就在这里。操作系统带有新的设计和功能更改。除了一些添加之外,它还带有功能弃用和删除。Windows11中不存在的功能之一是Paint3D。虽然它仍然提供经典的Paint,它对抽屉,涂鸦者和涂鸦者有好处,但它放弃了Paint3D,它提供了额外的功能,非常适合3D创作者。如果您正在寻找一些额外的功能,我们建议AutodeskMaya作为最好的3D设计软件。如
 单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PM
单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具May 23, 2023 pm 02:34 PMChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spacesoftheweek)。△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Imageto3D技术,受到了广泛关注现行beta版本生成的3D模型,
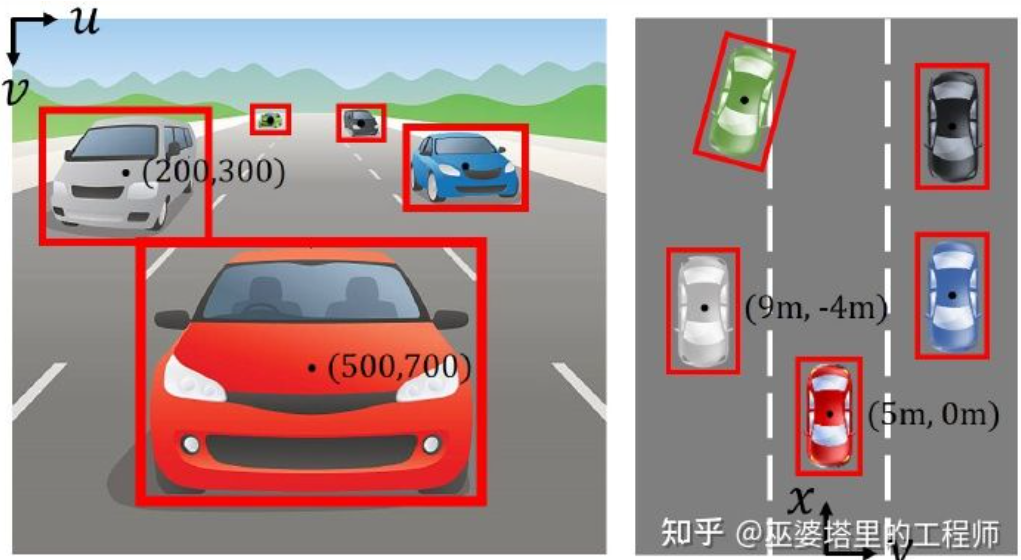 自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM
自动驾驶3D视觉感知算法深度解读Jun 02, 2023 pm 03:42 PM对于自动驾驶应用来说,最终还是需要对3D场景进行感知。道理很简单,车辆不能靠着一张图像上得到感知结果来行驶,就算是人类司机也不能对着一张图像来开车。因为物体的距离和场景的和深度信息在2D感知结果上是体现不出来的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(PerspectiveView)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,
 跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM
跨模态占据性知识的学习:使用渲染辅助蒸馏技术的RadOccJan 25, 2024 am 11:36 AM原标题:Radocc:LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation论文链接:https://arxiv.org/pdf/2312.11829.pdf作者单位:FNii,CUHK-ShenzhenSSE,CUHK-Shenzhen华为诺亚方舟实验室会议:AAAI2024论文思路:3D占用预测是一项新兴任务,旨在使用多视图图像估计3D场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景
 《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM
《原神》:知名原神3d同人作者被捕Feb 15, 2024 am 09:51 AM一些原神“奇怪”的关键词,在这两天很有关注度,明明搜索指数没啥变化,却不断有热议话题蹦窜。例如了龙王、钟离等“转变”立绘激增,虽在网络上疯传了一阵子,但是经过追溯发现这些是合理、常规的二创同人。如果单是这些,倒也翻不起多大的热度。按照一部分网友的说法,除了原神自身就有热度外,发现了一件格外醒目的事情:原神3d同人作者shirakami已经被捕。这引发了不小的热议。为什么被捕?关键词,原神3D动画。还是越过了线(就是你想的那种),再多就不能明说了。经过多方求证,以及新闻报道,确实有此事。自从去年发


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

