
 Peranti teknologiAIModel besar + robot, laporan ulasan terperinci ada di sini, dengan penyertaan ramai sarjana Cina
Peranti teknologiAIModel besar + robot, laporan ulasan terperinci ada di sini, dengan penyertaan ramai sarjana Cina
Keupayaan cemerlang model besar adalah jelas kepada semua, dan jika ia disepadukan ke dalam robot, diharapkan robot akan mempunyai otak yang lebih pintar, membawa kemungkinan baharu kepada bidang robotik, seperti pemanduan autonomi, robot rumah, industri robot, robot tambahan, Robot perubatan, robot medan dan sistem berbilang robot.
Model Bahasa Besar (LLM) yang telah dilatih sebelumnya, Model Bahasa Penglihatan Besar (VLM), Model Bahasa Audio Besar (ALM) dan Model Navigasi Visual Besar (VNM) boleh digunakan untuk menangani pelbagai masalah dalam bidang robotik dengan lebih baik. Tugasan. Mengintegrasikan model asas ke dalam robotik ialah bidang yang berkembang pesat, dan komuniti robotik baru-baru ini mula meneroka penggunaan model besar ini dalam bidang robotik yang perlu ditulis semula: persepsi, ramalan, perancangan dan kawalan.
Baru-baru ini, pasukan penyelidikan bersama yang terdiri daripada Universiti Stanford, Universiti Princeton, NVIDIA, Google DeepMind dan syarikat lain mengeluarkan laporan semakan yang meringkaskan pembangunan dan cabaran masa depan model asas dalam bidang penyelidikan robotik

Kertas alamat: https://arxiv.org/pdf/2312.07843.pdf
Kandungan yang ditulis semula ialah: Pustaka kertas: https://github.com/robotics-survey/Awesome-Robotics-Foundation -Models
Terdapat ramai ulama Cina yang kita kenali di kalangan ahli pasukan, termasuk Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu, dll.
Model asas yang telah dilatih secara meluas menggunakan data berskala besar boleh digunakan pada pelbagai tugas hiliran selepas penalaan halus. Model asas ini telah membuat penemuan besar dalam bidang penglihatan dan pemprosesan bahasa, termasuk model berkaitan seperti BERT, GPT-3, GPT-4, CLIP, DALL-E dan PaLM-E
Sebelum kemunculan model asas, untuk robot Model pembelajaran mendalam tradisional dilatih menggunakan set data terhad yang dikumpul untuk tugasan yang berbeza. Sebaliknya, model asas telah dilatih terlebih dahulu menggunakan pelbagai data yang pelbagai dan telah menunjukkan kebolehsuaian, generalisasi dan prestasi keseluruhan dalam bidang lain seperti pemprosesan bahasa semula jadi, penglihatan komputer dan penjagaan kesihatan. Akhirnya, model asas juga dijangka menunjukkan potensinya dalam bidang robotik. Rajah 1 menunjukkan gambaran keseluruhan model asas dalam bidang robotik.
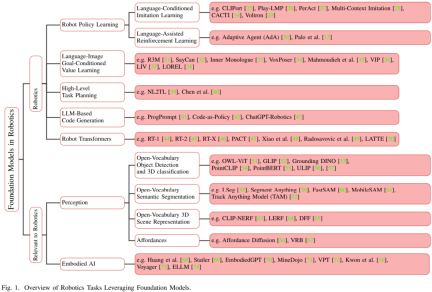
Berbanding dengan model khusus tugasan, pemindahan pengetahuan daripada model asas berpotensi untuk mengurangkan masa latihan dan sumber pengkomputeran. Terutamanya dalam bidang berkaitan robotik, model asas multimodal boleh menggabungkan dan menyelaraskan data heterogen berbilang mod yang dikumpul daripada penderia berbeza ke dalam perwakilan homogen padat, yang diperlukan untuk pemahaman dan penaakulan robot. Perwakilan yang dipelajarinya boleh digunakan dalam mana-mana bahagian tindanan teknologi automasi, termasuk yang perlu ditulis semula: persepsi, membuat keputusan dan kawalan.
Bukan itu sahaja, model asas juga boleh menyediakan keupayaan pembelajaran sifar pukulan, yang membolehkan sistem AI melaksanakan tugas tanpa sebarang contoh atau latihan yang disasarkan. Ini membolehkan robot menyamaratakan pengetahuan yang telah dipelajarinya kepada kes penggunaan baharu, meningkatkan kebolehsuaian dan fleksibiliti robot dalam persekitaran tidak berstruktur.
Mengintegrasikan model asas ke dalam sistem robot boleh meningkatkan keupayaan robot untuk melihat persekitaran dan berinteraksi dengan persekitaran Ia adalah mungkin untuk merealisasikan konteks yang perlu ditulis semula: sistem robot persepsi.
Sebagai contoh, perkara yang perlu ditulis semula ialah: dalam bidang persepsi, model bahasa visual (VLM) berskala besar boleh mempelajari perkaitan antara data visual dan teks, supaya mempunyai keupayaan pemahaman merentas mod, dengan itu membantu pengelasan imej tangkapan sifar, Tugas seperti sampel sifar pengesanan objek dan pengelasan 3D. Sebagai contoh lain, asas bahasa (iaitu, menjajarkan pemahaman kontekstual VLM dengan dunia sebenar 3D) dalam dunia 3D boleh meningkatkan keperluan ruang robot dengan mengaitkan sebutan dengan objek, lokasi atau tindakan tertentu dalam persekitaran 3D : keupayaan untuk melihat.
Dalam bidang membuat keputusan atau perancangan, penyelidikan mendapati bahawa LLM dan VLM boleh membantu robot dalam menentukan tugas yang melibatkan perancangan peringkat tinggi.
Dengan memanfaatkan isyarat bahasa yang berkaitan dengan operasi, navigasi dan interaksi, robot boleh melaksanakan tugas yang lebih kompleks. Sebagai contoh, untuk teknologi pembelajaran dasar robot seperti pembelajaran tiruan dan pembelajaran pengukuhan, model asas nampaknya mempunyai keupayaan untuk meningkatkan kecekapan data dan pemahaman konteks. Khususnya, ganjaran yang didorong oleh bahasa boleh membimbing agen pembelajaran pengukuhan dengan menyediakan ganjaran berbentuk.
Selain itu, penyelidik sudah pun menggunakan model bahasa untuk memberikan maklum balas bagi teknologi pembelajaran dasar. Beberapa kajian telah menunjukkan bahawa keupayaan menjawab soalan visual (VQA) model VLM boleh digunakan untuk kes penggunaan robotik. Sebagai contoh, penyelidik telah menggunakan VLM untuk menjawab soalan yang berkaitan dengan kandungan visual untuk membantu robot menyelesaikan tugas. Selain itu, sesetengah penyelidik menggunakan VLM untuk membantu dengan anotasi data dan menjana label penerangan untuk kandungan visual.
Walaupun model asas mempunyai keupayaan transformatif dalam pemprosesan penglihatan dan bahasa, generalisasi dan penalaan halus model asas untuk tugas robotik dunia sebenar masih agak mencabar.
Cabaran-cabaran ini termasuk:
1) Kekurangan data: Cara mendapatkan data berskala Internet untuk menyokong tugas seperti pengendalian robot, kedudukan, navigasi, dll., dan cara menggunakan data ini untuk latihan yang diselia sendiri
2) Perbezaan besar: Cara menangani kepelbagaian besar persekitaran fizikal, platform robot fizikal dan tugas robot yang berpotensi, sambil mengekalkan keluasan yang diperlukan bagi model asas
3) Masalah kuantifikasi ketidakpastian: Bagaimana untuk menyelesaikan contoh- ketidakpastian tahap (seperti kekaburan bahasa atau ilusi LLM), ketidakpastian tahap pengedaran dan masalah anjakan pengedaran, terutamanya masalah anjakan pengedaran yang disebabkan oleh penggunaan robot gelung tertutup.
4) Penilaian keselamatan: Cara menguji sistem robot dengan teliti berdasarkan model asas sebelum penggunaan, semasa proses kemas kini dan semasa proses kerja.
5) Prestasi masa nyata: Cara menangani masa inferens yang panjang bagi beberapa model asas - yang akan menghalang penggunaan model asas pada robot dan cara mempercepatkan inferens model asas - yang diperlukan untuk keputusan dalam talian- membuat.
Kertas ulasan ini meringkaskan penggunaan semasa model asas dalam bidang robotik. Para penyelidik meninjau kaedah, aplikasi dan cabaran semasa dan mencadangkan arah penyelidikan masa depan untuk menangani cabaran ini. Mereka juga menunjukkan potensi risiko menggunakan model asas untuk mencapai autonomi robot
Pengetahuan latar belakang model asas
Model asas mempunyai berbilion parameter dan dilatih terlebih dahulu menggunakan data berskala besar peringkat Internet. Melatih model yang besar dan kompleks itu sangat mahal. Kos untuk memperoleh, memproses dan mengurus data juga boleh menjadi tinggi. Proses latihannya memerlukan sejumlah besar sumber pengkomputeran, memerlukan penggunaan perkakasan khusus seperti GPU atau TPU, dan juga memerlukan perisian dan infrastruktur untuk latihan model, yang semuanya memerlukan pelaburan kewangan. Di samping itu, masa latihan model asas juga sangat panjang, yang juga membawa kepada kos yang tinggi. Oleh itu, model ini sering digunakan sebagai modul boleh pasang, iaitu menyepadukan model asas ke dalam pelbagai aplikasi tanpa kerja penyesuaian yang meluas
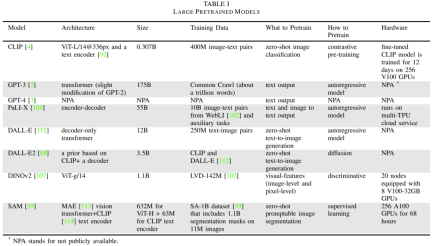
Jadual 1 memberikan butiran model asas yang biasa digunakan.
Bahagian ini akan memfokuskan pada LLM, Transformer visual, VLM, model bahasa berbilang modal terjelma dan model generatif visual. Selain itu, kaedah latihan berbeza yang digunakan untuk melatih model asas juga akan diperkenalkan
Mereka mula-mula memperkenalkan beberapa terminologi dan pengetahuan matematik yang berkaitan, yang melibatkan tokenisasi, model generatif, model diskriminatif, seni bina Transformer, model autoregresif, Pengekodan automatik bertopeng, pembelajaran kontrastif , dan model resapan.
Kemudian mereka memperkenalkan contoh dan latar belakang sejarah Model Bahasa Besar (LLM). Selepas itu, Transformer visual, model bahasa penglihatan multimodal (VLM), model bahasa multimodal yang terkandung, dan model generatif visual telah diserlahkan.
Penyelidikan Robot
Bahagian ini memfokuskan pada pembuatan keputusan, perancangan dan kawalan robot. Dalam bidang ini, kedua-dua model bahasa besar (LLM) dan model bahasa visual (VLM) mempunyai potensi untuk digunakan untuk meningkatkan keupayaan robot. Sebagai contoh, LLM boleh memudahkan proses spesifikasi tugas supaya robot boleh menerima dan mentafsir arahan peringkat tinggi daripada manusia.
VLM juga diharapkan dapat menyumbang kepada bidang ini. VLM cemerlang dalam menganalisis data visual. Untuk robot membuat keputusan termaklum dan melaksanakan tugas yang kompleks, pemahaman visual adalah penting. Kini, robot boleh menggunakan isyarat bahasa semula jadi untuk meningkatkan keupayaan mereka untuk melaksanakan tugas yang berkaitan dengan manipulasi, navigasi dan interaksi.
Pembelajaran dasar visual-linguistik berasaskan matlamat (sama ada melalui pembelajaran tiruan atau pembelajaran pengukuhan) dijangka akan ditambah baik oleh model asas. Model bahasa juga boleh memberikan maklum balas untuk teknik pembelajaran dasar. Gelung maklum balas ini membantu mempertingkatkan keupayaan membuat keputusan robot secara berterusan, kerana robot boleh mengoptimumkan tindakannya berdasarkan maklum balas yang diterima daripada LLM.
Bahagian ini memfokuskan kepada aplikasi LLM dan VLM dalam bidang pembuatan keputusan robot.
Bahagian ini terbahagi kepada enam bahagian. Bahagian pertama memperkenalkan pembelajaran dasar untuk membuat keputusan dan kawalan dan robot, termasuk pembelajaran tiruan berasaskan bahasa dan pembelajaran peneguhan berbantukan bahasa.
Bahagian kedua ialah pembelajaran nilai imej bahasa berasaskan matlamat.
Bahagian ketiga memperkenalkan penggunaan model bahasa yang besar untuk merancang tugasan robot, yang termasuk menerangkan tugasan melalui arahan bahasa dan menggunakan model bahasa untuk menjana kod untuk perancangan tugas.
Bahagian keempat ialah pembelajaran kontekstual (ICL) untuk membuat keputusan.
Yang seterusnya yang akan diperkenalkan ialah Robot Transformers
Bahagian keenam ialah navigasi robot dan operasi perpustakaan perbendaharaan kata terbuka.
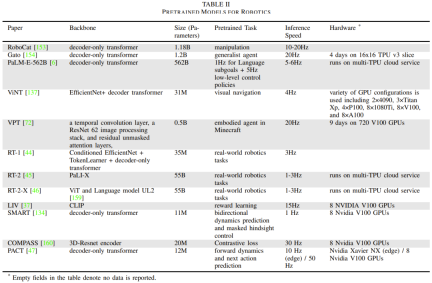
Jadual 2 memberikan beberapa model asas khusus robot, pelaporan saiz dan seni bina model, tugas pra-latihan, masa inferens dan persediaan perkakasan.
Apa yang perlu ditulis semula ialah: persepsi
Robot yang berinteraksi dengan persekitaran sekeliling menerima maklumat deria dalam modaliti yang berbeza, seperti imej, video, audio dan bahasa. Data berdimensi tinggi ini penting untuk robot memahami, menaakul dan berinteraksi dengan persekitaran mereka. Model asas boleh mengubah input berdimensi tinggi ini kepada perwakilan berstruktur abstrak yang mudah ditafsir dan dimanipulasi. Khususnya, model asas multimodal membenarkan robot untuk mengintegrasikan input daripada deria berbeza ke dalam perwakilan bersatu yang mengandungi maklumat semantik, ruang, temporal dan kemampuan. Model multimodal ini memerlukan interaksi silang modal, selalunya memerlukan penjajaran elemen daripada modaliti yang berbeza untuk memastikan konsistensi dan kesesuaian bersama. Sebagai contoh, tugas perihalan imej memerlukan penjajaran teks dan data imej.
Bahagian ini akan menumpukan pada perkara yang robot perlu tulis semula: satu siri tugasan yang berkaitan dengan persepsi, yang boleh dipertingkatkan dengan menggunakan model asas untuk menyelaraskan modaliti. Penekanan adalah pada penglihatan dan bahasa.
Bahagian ini dibahagikan kepada lima bahagian, pertama ialah pengesanan sasaran dan klasifikasi 3D bagi perbendaharaan kata terbuka, kemudian pembahagian semantik perbendaharaan kata terbuka, kemudian ialah adegan 3D dan perwakilan sasaran bagi perbendaharaan kata terbuka, dan kemudian ialah kemampuan yang dipelajari, dan akhirnya model ramalan.
Embodied AI
Baru-baru ini, beberapa kajian telah menunjukkan bahawa LLM boleh berjaya digunakan dalam bidang Embodied AI, di mana "embodied" biasanya merujuk kepada penjelmaan maya dalam simulator dunia, dan bukannya mempunyai badan robot Fizikal.
Beberapa rangka kerja, set data dan model yang menarik telah muncul di kawasan ini. Nota khusus ialah penggunaan permainan Minecraft sebagai platform untuk melatih ejen yang terkandung. Contohnya, Voyager menggunakan GPT-4 untuk membimbing ejen meneroka persekitaran Minecraft. Ia boleh berinteraksi dengan GPT-4 melalui reka bentuk segera kontekstual tanpa perlu memperhalusi parameter model GPT-4.
Pembelajaran peneguhan ialah hala tuju penyelidikan yang penting dalam bidang pembelajaran robot Penyelidik cuba menggunakan model asas untuk mereka bentuk fungsi ganjaran untuk mengoptimumkan pembelajaran peneguhan
Untuk robot melaksanakan perancangan peringkat tinggi, penyelidik telah meneroka penggunaan asas. model untuk membantu. Di samping itu, beberapa penyelidik cuba menggunakan kaedah penaakulan berasaskan rantai pemikiran dan penjanaan tindakan untuk menjelmakan kecerdasan
Cabaran dan hala tuju masa hadapan
Bahagian ini akan memberikan cabaran yang berkaitan dengan menggunakan model asas untuk robot. Pasukan ini juga akan meneroka arah penyelidikan masa depan yang mungkin menangani cabaran ini.
Cabaran pertama adalah untuk mengatasi masalah kekurangan data semasa melatih model asas untuk robot, yang merangkumi:
1 Memperluas pembelajaran robot menggunakan data permainan tidak berstruktur dan video manusia tidak berlabel
2
3 Atasi masalah kekurangan data 3D semasa melatih model asas 3D
4. Hasilkan data sintetik melalui simulasi ketelitian tinggi
5 Menggunakan VLM untuk penambahan data ialah kaedah yang berkesan
6 Kemahiran fizikal robot dihadkan oleh pengagihan kemahiran
Cabaran kedua adalah berkaitan dengan prestasi masa nyata, di mana kuncinya ialah masa inferens model asas. .
Cabaran ketiga melibatkan batasan perwakilan multimodal.
Cabaran keempat ialah cara mengukur ketidakpastian pada tahap yang berbeza, seperti tahap contoh dan tahap pengedaran. Ia juga melibatkan masalah cara menentukur dan menangani anjakan pengedaran.
Cabaran kelima melibatkan penilaian keselamatan, termasuk ujian keselamatan sebelum penggunaan dan pemantauan masa jalan dan pengesanan situasi luar pengedaran.
Cabaran keenam melibatkan cara memilih: menggunakan model asas sedia ada atau membina model asas baharu untuk robot?
Cabaran ketujuh melibatkan kebolehubahan yang tinggi dalam persediaan robot.
Cabaran kelapan ialah cara menanda aras dan memastikan kebolehulangan dalam tetapan robot.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Model besar + robot, laporan ulasan terperinci ada di sini, dengan penyertaan ramai sarjana Cina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 机器人学我表情的样子,让人感到一丝恐惧Apr 09, 2023 am 10:11 AM
机器人学我表情的样子,让人感到一丝恐惧Apr 09, 2023 am 10:11 AM通常,机器人的主要功能是完成一些简单的操作任务,我们希望机器人可以模仿人,让能力尽可能接近人类水平。不论是小米的 CyberOne 还是特斯拉的 Optimus,人们关心的主要是其机械关节数量,控制算法和行走速度。不过在这个领域,有些人探索的方向更加脑洞大开:现在,有一种机器人把模仿真人表情做到了极致:先尝试一下自拍。从「嫌弃」到「惊讶」,都可以做到完全同步:这个机器人名叫 Ameca,是个表情怪。除了模仿,它自己也能照镜子做很多小表情,看起来非常像真人。Ameca「假装」第一次见到镜子,首
 拿破仑、孔子在线陪聊!AI聊天机器人「复活」历史名人,网友:真上头!Apr 08, 2023 pm 12:11 PM
拿破仑、孔子在线陪聊!AI聊天机器人「复活」历史名人,网友:真上头!Apr 08, 2023 pm 12:11 PM和活生生的已故历史名人聊天是个什么感觉?近日,就有一群开发者利用语言模型,把千百年来各行各业的历史名人全部「复活」成了聊天机器人,做进了一款手机app里,起名叫「你好,历史」!开发者声称,这个与古代名人聊天的app涉及的内容几乎无所不包。比如可以:与玛丽莲·梦露聊好莱坞八卦与弗里达·卡洛讨论现代艺术问问圣诞老人他有多少只驯鹿问问科特·科本为什么自杀向穴居人学习如何生火与宇宙意识辩论生命的意义不过他们也没忘记提醒用户,这些对话是由人工智能生成的,所以不要太认真。而且每个对话都是独一无二的,你永远不
 盘点全球不错的七所机器人工程专业学校Apr 08, 2023 pm 01:31 PM
盘点全球不错的七所机器人工程专业学校Apr 08, 2023 pm 01:31 PM有抱负的工程师应该了解世界各地著名的机器人工程学院。现在是从事机器人和工程事业的最佳时机——从人工智能到太空探索,这一领域充满了令人兴奋的创新和进步。美国劳工统计局估计,未来10年,机械工程领域的职业总体上将保持7%的稳定增长率,确保毕业生将有大量的就业机会。机器人工程专业的学生平均工资超过9万美元,无需担心还助学贷款的问题。对于那些考虑投身机器人工程领域的人来说,选择一所合适的大学是非常重要的。世界上许多顶尖的机器人工程学院都在美国,尽管国外也有一些很棒的项目。这是7所世界上最好的机器人工程学
 人类与人工智能如何建立关系Apr 09, 2023 pm 07:41 PM
人类与人工智能如何建立关系Apr 09, 2023 pm 07:41 PM人类与人工智能相比,哪个更擅长建立关系?事实上,这项革命性的技术已经存在了很长一段时间。然而,直到最近人们才意识到人工智能对人类的重要性。人工智能利用算法模拟人类,并随着时间的推移从经验中学习的能力,为这项技术与人类建立关系开辟道路。人类如何建立人际关系作为人类,我们倾向于只与少数人建立关系。我们试图确保不需要的和不相干的人从我们的生活中消失。在将我们的关系限制在少数人的同时,我们确保与那些对我们真正重要的人建立高质量的关系。然而,同样的方法在商业用语中可能不是理想的,并可能适得其反。尽管知道这
 女王登基70周年,世上首个超逼真人形机器艺术家献上肖像画作,被锐评“缺少信念”Apr 08, 2023 pm 08:11 PM
女王登基70周年,世上首个超逼真人形机器艺术家献上肖像画作,被锐评“缺少信念”Apr 08, 2023 pm 08:11 PM大数据文摘出品作者:Caleb为庆祝英国女王伊丽莎白二世登基70周年,英国也是早早就洋溢出了庆典的味道。据了解,英国将于6月2日至5日连放4天公众假期,并在期间举行多项庆祝活动。英国皇家铸币厂也在精心打造有史以来最大的硬币,直径220毫米,重15公斤,面值15000英镑,耗时近400小时打造,是该厂1100年来生产的最大硬币。这枚金币一面雕刻着代表英国女王伊丽莎白二世的符号EⅡR,周围环绕着代表英国的玫瑰、水仙、蓟和三叶草。另一面有女王骑在马背上的图案。在这么热闹的日子里,AI当然也必须来凑一凑
 让机器人学会咖啡拉花,得从流体力学搞起!CMU&MIT推出流体模拟平台Apr 07, 2023 pm 04:46 PM
让机器人学会咖啡拉花,得从流体力学搞起!CMU&MIT推出流体模拟平台Apr 07, 2023 pm 04:46 PM机器人也能干咖啡师的活了!比如让它把奶泡和咖啡搅拌均匀,效果是这样的:然后上点难度,做杯拿铁,再用搅拌棒做个图案,也是轻松拿下:这些是在已被ICLR 2023接收为Spotlight的一项研究基础上做到的,他们推出了提出流体操控新基准FluidLab以及多材料可微物理引擎FluidEngine。研究团队成员分别来自CMU、达特茅斯学院、哥伦比亚大学、MIT、MIT-IBM Watson AI Lab、马萨诸塞大学阿默斯特分校。在FluidLab的加持下,未来机器人处理更多复杂场景下的流体工作也都
 四足机器人学会“双腿站立下楼梯”!效率比腿式系统高83%Apr 09, 2023 am 11:21 AM
四足机器人学会“双腿站立下楼梯”!效率比腿式系统高83%Apr 09, 2023 am 11:21 AM还记得那个和特斯拉飙车的机器人吗?这是瑞士苏黎世联邦理工学院衍生公司研发的与公司同名的四足轮腿式机器人——Swiss-Mile,前身是ANYmal四足机器人。距离它和特斯拉飙车还不到半年的时间,它又实现了重大升级。这次升级改进了机器人的算法,运动能力直接UP UP UP ! 可以双腿站立下楼梯:(小编内心OS:如果是我穿轮滑鞋下楼梯可能会摔个狗吃屎)楼梯爬累了,坐个电梯吧,用前脚按开电梯门:面对障碍物应对自如:它还能知道什么时候该站起来,什么时候该“趴下”,双腿直立与四足运动之间的切换更丝滑:
 聊一聊AI有哪四种类型Apr 09, 2023 pm 11:31 PM
聊一聊AI有哪四种类型Apr 09, 2023 pm 11:31 PM随着人工智能成为一种趋势,人们对它如何工作以及可以做什么存在很多问题。一个经常被问到的问题就是——AI有哪四种类型。下面小编就来为大家解答一下。AI有哪四种类型反应性机器反应性机器在AI中是一个非常受欢迎的概念。这是因为它是最基本也是最古老的AI类型。反应性机器是指仅对某些刺激和场景有反应性的机器。与之后的许多人工智能软件不同的是,它们不能利用以前的经验或负载的知识来评估和应对特定的情况。甚至不使用GPS或数字地图来导航周围的环境或绘制路线。相反,它们会根据所看到的东西移动。反应型机器擅长象棋和


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

