
Rumah >Peranti teknologi >AI >Ciri segmen boleh dipelajari dengan melabelkan satu bingkai video, mencapai prestasi yang diselia sepenuhnya! Huake memenangi SOTA baharu untuk pengesanan tingkah laku berjujukan
Ciri segmen boleh dipelajari dengan melabelkan satu bingkai video, mencapai prestasi yang diselia sepenuhnya! Huake memenangi SOTA baharu untuk pengesanan tingkah laku berjujukan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-11 22:39:17793semak imbas
Bagaimana untuk mencari klip menarik daripada video? Penyetempatan Tindakan Temporal (TAL) ialah kaedah biasa. Selepas menggunakan kandungan video untuk pemodelan, anda boleh mencari keseluruhan video secara bebas.
Pasukan bersama Universiti Sains dan Teknologi Huazhong dan Universiti Michigan baru-baru ini telah membawa kemajuan baharu kepada teknologi ini -
Pada masa lalu, pemodelan dalam TAL berada di peringkat segmen atau pun contoh, tetapi kini hanya memerlukan
satu bingkai dalam video Ia boleh dicapai, dan kesannya setanding dengan pengawasan penuh.
 Sebuah pasukan dari Universiti Sains dan Teknologi Huazhong mencadangkan rangka kerja baharu yang dipanggil HR-Pro untuk pengesanan tingkah laku temporal yang diselia anotasi titik.
Sebuah pasukan dari Universiti Sains dan Teknologi Huazhong mencadangkan rangka kerja baharu yang dipanggil HR-Pro untuk pengesanan tingkah laku temporal yang diselia anotasi titik.
Melalui penyebaran kebolehpercayaan berbilang peringkat, HR-Pro boleh mempelajari lebih banyak ciri peringkat serpihan diskriminatif dan sempadan peringkat contoh yang lebih dipercayai dalam talian.
HR-Pro terdiri daripada dua peringkat sedar kebolehpercayaan, yang boleh menyebarkan petunjuk keyakinan tinggi dengan berkesan daripada anotasi titik peringkat segmen dan peringkat contoh, membolehkan rangkaian mempelajari lebih banyak perwakilan segmen yang diskriminatif dan tawaran Solid yang lebih baik.
Percubaan pada beberapa set data penanda aras menunjukkan bahawa HR-Pro mengatasi kaedah sedia ada dengan hasil terkini, menunjukkan keberkesanan dan potensi untuk anotasi titik.
Prestasi setanding dengan kaedah diselia sepenuhnya
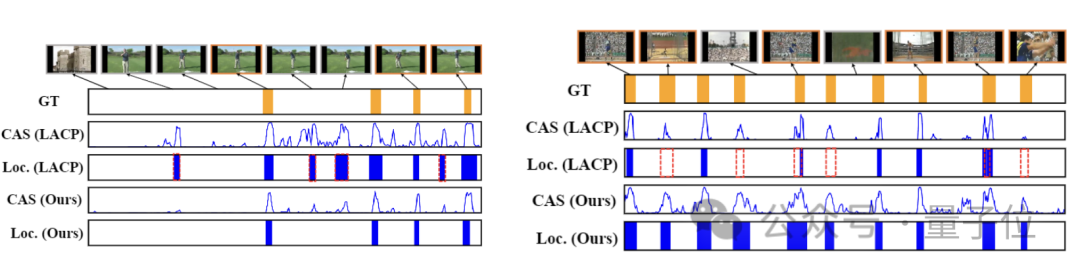
Rajah berikut menunjukkan perbandingan prestasi HR-Pro dan LACP dalam pengesanan tingkah laku temporal pada video ujian THUMOS14.
HR-Pro menunjukkan pengesanan contoh tindakan yang lebih tepat, khususnya:
Untuk tingkah laku "hayunan golf", HR-Pro dengan berkesan membezakan antara tingkah laku dan serpihan latar belakang, mengurangkan Positif Palsu yang sukar dikendalikan dengan Ramalan LACP- Untuk tingkah laku lempar cakera, HR-Pro mengesan segmen yang lebih lengkap daripada LACP, yang mempunyai nilai pengaktifan yang lebih rendah pada segmen tindakan tanpa diskriminasi.
 Hasil ujian pada set data juga mengesahkan perasaan intuitif ini.
Hasil ujian pada set data juga mengesahkan perasaan intuitif ini.
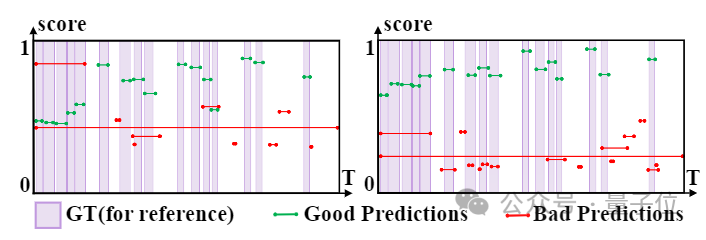
Selepas memvisualisasikan hasil pengesanan pada set data THUMOS14, dapat diperhatikan bahawa selepas pembelajaran integriti peringkat contoh, perbezaan antara ramalan berkualiti tinggi dan ramalan berkualiti rendah meningkat dengan ketara.
(Sebelah kiri ialah hasil sebelum pembelajaran integriti peringkat contoh, dan sebelah kanan ialah hasil selepas pembelajaran. Paksi mendatar dan menegak masing-masing mewakili markah masa dan kebolehpercayaan.)
 Secara keseluruhan, secara lazimnya digunakan Dalam 4 set data, prestasi HR-Pro dengan ketara mengatasi kaedah penyeliaan titik tercanggih Purata mAP pada set data THUMOS14 mencapai 60.3%, iaitu peningkatan sebanyak 6.5% berbanding sebelumnya. Kaedah SoTA (53.7%), dan boleh Ia mencapai hasil yang setanding dengan beberapa kaedah yang diselia sepenuhnya.
Secara keseluruhan, secara lazimnya digunakan Dalam 4 set data, prestasi HR-Pro dengan ketara mengatasi kaedah penyeliaan titik tercanggih Purata mAP pada set data THUMOS14 mencapai 60.3%, iaitu peningkatan sebanyak 6.5% berbanding sebelumnya. Kaedah SoTA (53.7%), dan boleh Ia mencapai hasil yang setanding dengan beberapa kaedah yang diselia sepenuhnya.
Berbanding dengan kaedah terkini yang terkini dalam jadual di bawah pada set ujian THUMOS14, HR-Pro mencapai purata peta 60.3% untuk ambang IoU antara 0.1 dan 0.7, iaitu 6.5% lebih tinggi daripada sebelumnya. kaedah terkini CRRC-Net .
Dan HR-Pro mampu mencapai prestasi yang setanding dengan kaedah berdaya saing diselia sepenuhnya, seperti AFSD (purata mAP 51.1% berbanding 52.0% untuk ambang IoU antara 0.3 dan 0.7).
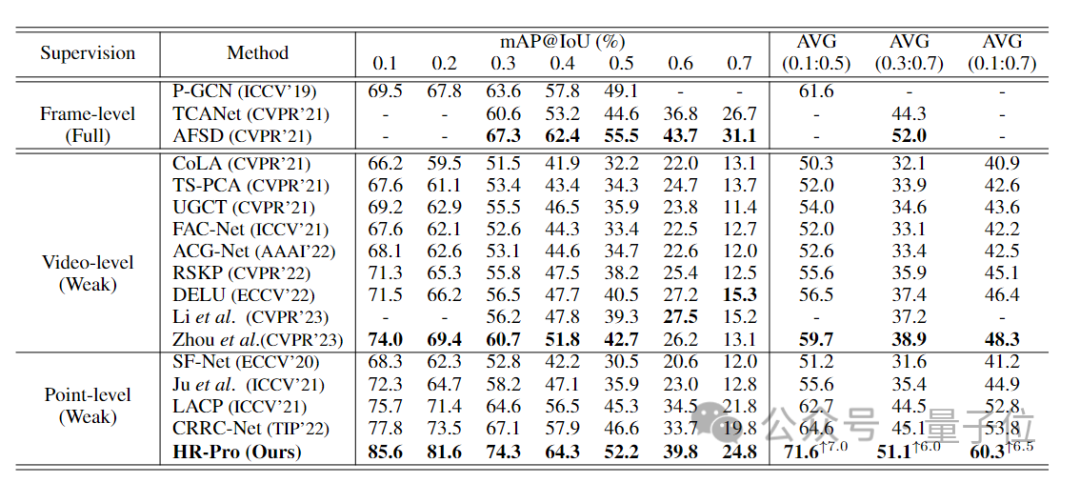 △Perbandingan kaedah HR-Pro dan bekas SOTA pada dataset THUMOS14
△Perbandingan kaedah HR-Pro dan bekas SOTA pada dataset THUMOS14
HR-Pro juga jauh lebih baik daripada kaedah sedia ada dari segi serba boleh dan keunggulan pada pelbagai set data penanda aras, dan dalam GTEA , BEOID dan ActivityNet 1.3 peningkatan masing-masing sebanyak 3.8%, 7.6% dan 2.0%.
 △Perbandingan kaedah HR-Pro dan bekas SOTA pada GTEA dan set data lain
△Perbandingan kaedah HR-Pro dan bekas SOTA pada GTEA dan set data lain
Jadi, bagaimanakah HR-Pro dilaksanakan?
Pembelajaran dijalankan dalam dua peringkat
Pasukan penyelidik mencadangkan kaedah penyebaran boleh dipercayai berbilang peringkat, memperkenalkan modul memori serpihan yang boleh dipercayai pada peringkat serpihan dan menggunakan kaedah perhatian silang untuk menyebarkan kepada serpihan lain, dan mencadangkan penjanaan cadangan berdasarkan penyeliaan titik di peringkat contoh, mengaitkan serpihan dan kejadian digunakan untuk menjana cadangan dengan tahap kebolehpercayaan yang berbeza, dan seterusnya mengoptimumkan keyakinan dan sempadan cadangan pada peringkat contoh.
Struktur model HR-Pro ditunjukkan dalam rajah di bawah: Pengesanan tingkah laku temporal terbahagi kepada proses pembelajaran dua peringkat iaitu
pembelajaran diskriminatif pada peringkat serpihan dan pembelajaran integriti pada peringkat instance. Pasukan penyelidik memperkenalkan pembelajaran diskriminatif peringkat segmen yang sedar kebolehpercayaan, mencadangkan untuk menyimpan prototaip yang boleh dipercayai untuk setiap kategori, dan menggabungkan keyakinan tinggi dalam prototaip ini melalui intra-video dan antara- kaedah video Petunjuk darjah disebarkan kepada serpihan lain. . C ) untuk dapat menggunakan maklumat ciri bagi keseluruhan set data. Pasukan penyelidik memilih ciri segmen dengan anotasi titik untuk memulakan prototaip: Untuk mengetahui lebih banyak ciri segmen yang diskriminatif, pasukan itu juga membina kehilangan perbandingan segmen yang sedar kebolehpercayaan: Fasa 2: Pembelajaran integriti peringkat contoh Untuk menggunakan maklumat awal anotasi titik peringkat contoh semasa proses latihan, pasukan mencadangkan kaedah penjanaan cadangan berdasarkan anotasi titik untuk menjana cadangan dengan kebolehpercayaan yang berbeza. Berdasarkan skor kebolehpercayaan dan kedudukan sementara anotasi titik relatif, cadangan ini boleh dibahagikan kepada dua jenis: Cadangan Boleh Dipercayai (RP): Bagi setiap mata dalam setiap kategori, cadangan mengandungi Perkara ini telah dicapai dan telah kebolehpercayaan tertinggi; kemudian menggunakan
Untuk mendapatkan cadangan gelagat sempadan yang lebih tepat, penyelidik memasukkan ciri kawasan permulaan dan ciri wilayah berakhir daripada cadangan dalam setiap PP ke dalam regresi Dalam kepala ramalan φr, mengimbangi masa mula dan tamat cadangan yang diramalkan. Kirakan cadangan yang telah diperhalusi, dan harap cadangan yang telah diperhalusi akan bertepatan dengan cadangan yang boleh dipercayai. Ringkasnya, HR-Pro boleh mencapai hasil yang hebat dengan hanya beberapa anotasi, sangat mengurangkan kos mendapatkan label, dan pada masa yang sama mempunyai keupayaan generalisasi yang kukuh, menjadikannya sesuai untuk penggunaan sebenar permohonan Keadaan yang menggalakkan disediakan. Menurut ini, penulis meramalkan bahawa HR-Pro akan mempunyai prospek aplikasi yang luas dalam bidang analisis tingkah laku, interaksi manusia-komputer, dan analisis pemanduan. Alamat kertas: https://arxiv.org/abs/2308.12608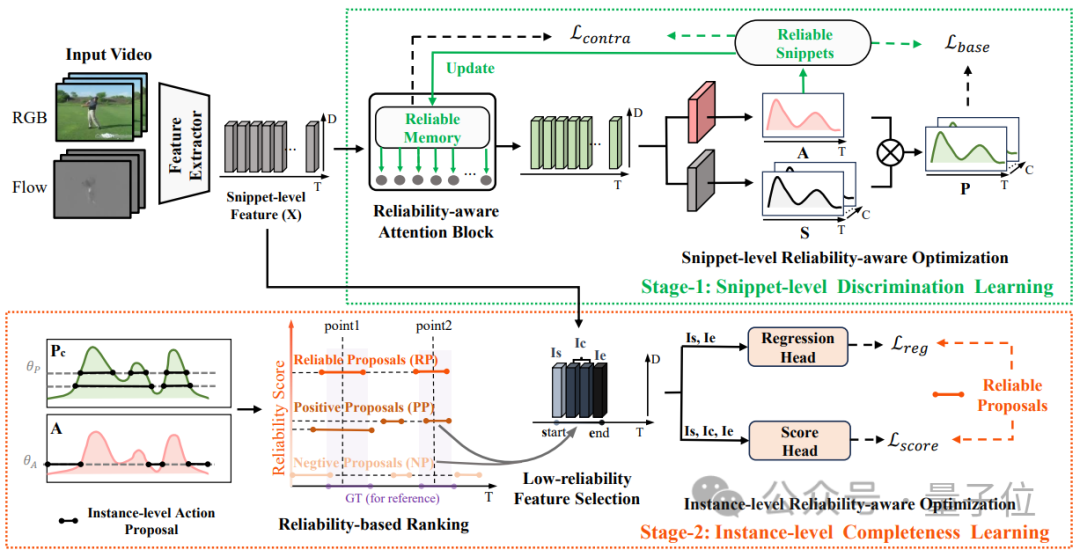
Fasa 1: Pembelajaran diskriminatif peringkat segmen
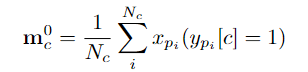 Pengoptimuman kebolehpercayaan peringkat serpihan
Pengoptimuman kebolehpercayaan peringkat serpihan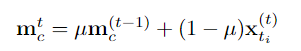
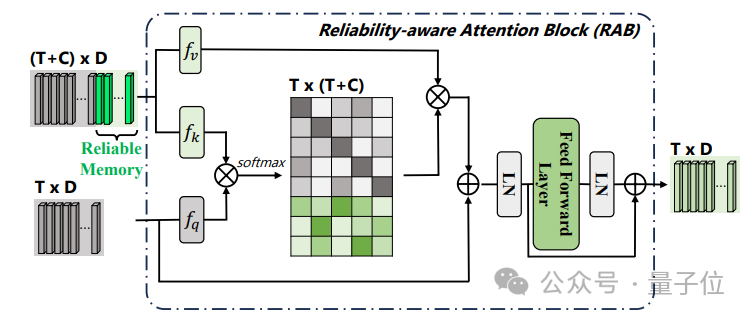
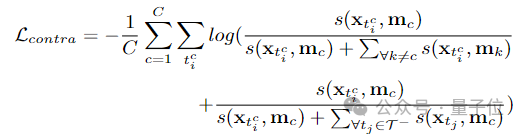
Untuk memastikan bilangan sampel positif dan negatif yang seimbang, pasukan penyelidik mengumpulkan segmen tersebut dengan skor perhatian bebas kategori yang lebih rendah daripada nilai yang telah ditetapkan ke dalam Cadangan Negatif (NP).
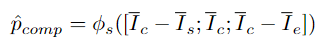
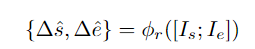
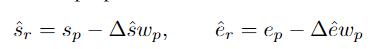
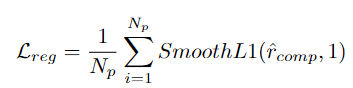
Atas ialah kandungan terperinci Ciri segmen boleh dipelajari dengan melabelkan satu bingkai video, mencapai prestasi yang diselia sepenuhnya! Huake memenangi SOTA baharu untuk pengesanan tingkah laku berjujukan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!