

 Peranti teknologiAITeknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!
Peranti teknologiAITeknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!Teknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!

Dalam dua tahun yang lalu, dengan pembukaan set data imej dan teks berskala besar seperti LAION-5B, satu siri kaedah dengan kesan yang menakjubkan telah muncul dalam bidang penjanaan imej, seperti Stable Diffusion, DALL-E 2, ControlNet dan Komposer. Kemunculan kaedah ini telah membuat terobosan dan kemajuan yang besar dalam bidang penjanaan imej. Bidang penjanaan imej telah berkembang pesat dalam tempoh dua tahun yang lalu.
Walau bagaimanapun, penjanaan video masih menghadapi cabaran besar. Pertama, berbanding dengan penjanaan imej, penjanaan video perlu memproses data berdimensi lebih tinggi dan perlu mengambil kira dimensi masa tambahan, yang membawa masalah pemodelan masa. Untuk memacu pembelajaran dinamik temporal, kami memerlukan lebih banyak data pasangan teks video. Walau bagaimanapun, anotasi temporal video yang tepat adalah sangat mahal, yang mengehadkan saiz set data teks video. Pada masa ini, set data video WebVid10M sedia ada hanya mengandungi 10.7M pasangan teks video Berbanding dengan set data imej LAION-5B, saiz data adalah jauh berbeza. Ini sangat mengehadkan kemungkinan pengembangan model penjanaan video secara besar-besaran.
Untuk menyelesaikan masalah di atas, pasukan penyelidik bersama Universiti Sains dan Teknologi Huazhong, Alibaba Group, Zhejiang University dan Ant Group baru-baru ini mengeluarkan penyelesaian video TF-T2V:

alamat: https: //arxiv.org/abs/2312.15770
Laman utama projek: https://tf-t2v.github.io/
Kod sumber akan dikeluarkan tidak lama lagi: https://github.com /ali-vilab/i2vgen -xl (projek VGen).
Penyelesaian ini mengambil pendekatan baharu dan mencadangkan penjanaan video berdasarkan data video beranotasi tanpa teks berskala besar, yang boleh mempelajari dinamik gerakan yang kaya.
Mula-mula, mari kita lihat kesan penjanaan video TF-T2V:
Tugasan Video Vincent
Kata-kata gesaan: Cipta video yang besar seperti salji tanah berbumbung. 
Kata gesaan: Hasilkan video animasi lebah kartun. 
Kata gesaan: Hasilkan video yang mengandungi motosikal fantasi futuristik. 
Kata gesaan: Hasilkan video budak kecil tersenyum gembira. 
Kata gesaan: Hasilkan video seorang lelaki tua berasa sakit kepala. Tugas penjanaan video 
combined
given teks dan peta kedalaman atau teks dan lakaran lakaran, TF-T2V mampu generasi video yang dapat dikawal: 
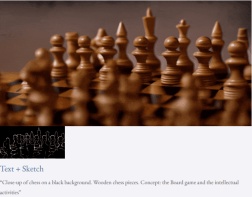
juga tersedia membuat tinggi- sintesis video resolusi: 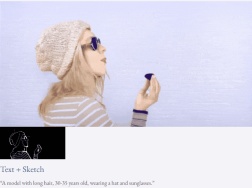

Tetapan separuh seliaan
Kaedah TF-T2V di bawah tetapan separa seliaan juga boleh menjana video yang sepadan dengan perihalan teks gerakan, seperti "Orang ramai berlari dari kanan ke kiri."


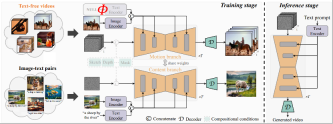
Pengenalan kaedah
Idea teras TF-T2V adalah untuk membahagikan model kepada cabang gerakan dan cabang penampilan, model dan gerakan digunakan cabang rupa digunakan untuk mempelajari maklumat yang jelas. Kedua-dua cabang ini dilatih secara bersama, dan akhirnya boleh mencapai penjanaan video dipacu teks.
Untuk meningkatkan ketekalan temporal video yang dijana, pasukan pengarang juga mencadangkan kehilangan ketekalan temporal untuk mempelajari secara jelas kesinambungan antara bingkai video.
Perlu dinyatakan bahawa TF-T2V ialah rangka kerja umum yang bukan sahaja sesuai untuk tugasan video Vincent, tetapi juga untuk tugas penjanaan video gabungan, seperti lakaran-ke-video, lukisan video, bingkai pertama -ke-video dll.
Untuk butiran khusus dan lebih banyak hasil percubaan, sila rujuk kertas asal atau halaman utama projek.
Selain itu, pasukan pengarang juga menggunakan TF-T2V sebagai model guru dan menggunakan teknologi penyulingan yang konsisten untuk mendapatkan model VideoLCM:

Alamat kertas: https://arxiv.org/abs/ 2312.09109
Laman utama projek: https://tf-t2v.github.io/
Kod sumber akan dikeluarkan tidak lama lagi: https://github.com/ali-vilab/i2vgen-xl (projek VGen) .
Berbeza dengan kaedah penjanaan video sebelum ini yang memerlukan kira-kira 50 langkah denoising DDIM, kaedah VideoLCM berdasarkan TF-T2V boleh menjana video berkesetiaan tinggi dengan hanya kira-kira 4 langkah denoising inferens, yang sangat meningkatkan kecekapan penjanaan video. kecekapan.
Mari kita lihat keputusan inferens denoising 4-langkah VideoLCM:
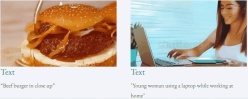

untuk keputusan projek yang asli dan lebih lanjut sila rujuk kepada kertas kerja LC laman utama.
Secara keseluruhannya, penyelesaian TF-T2V membawa idea baharu kepada bidang penjanaan video dan mengatasi cabaran yang disebabkan oleh saiz set data dan masalah pelabelan. Memanfaatkan data video anotasi tanpa teks berskala besar, TF-T2V mampu menjana video berkualiti tinggi dan digunakan pada pelbagai tugas penjanaan video. Inovasi ini akan menggalakkan pembangunan teknologi penjanaan video dan membawa senario aplikasi dan peluang perniagaan yang lebih luas kepada semua lapisan masyarakat.
🎜Atas ialah kandungan terperinci Teknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Satu arahan boleh memintas setiap perlindungan utama LLMApr 25, 2025 am 11:16 AM
Satu arahan boleh memintas setiap perlindungan utama LLMApr 25, 2025 am 11:16 AMPenyelidikan terobosan HiddenLayer mendedahkan kelemahan kritikal dalam model bahasa yang besar (LLMS). Penemuan mereka mendedahkan teknik bypass sejagat, yang digelar "Bonfetri Policy," mampu mengelakkan hampir semua LLM utama
 5 Kesalahan Kebanyakan perniagaan akan membuat tahun ini dengan kemampananApr 25, 2025 am 11:15 AM
5 Kesalahan Kebanyakan perniagaan akan membuat tahun ini dengan kemampananApr 25, 2025 am 11:15 AMDorongan untuk tanggungjawab alam sekitar dan pengurangan sisa secara asasnya mengubah bagaimana perniagaan beroperasi. Transformasi ini mempengaruhi pembangunan produk, proses pembuatan, hubungan pelanggan, pemilihan rakan kongsi, dan penggunaan baru
 H20 Chip Ban Jolts China AI Firma, tetapi mereka telah lama bersiap untuk kesanApr 25, 2025 am 11:12 AM
H20 Chip Ban Jolts China AI Firma, tetapi mereka telah lama bersiap untuk kesanApr 25, 2025 am 11:12 AMSekatan baru -baru ini mengenai perkakasan AI maju menyerlahkan persaingan geopolitik yang semakin meningkat untuk dominasi AI, mendedahkan pergantungan China terhadap teknologi semikonduktor asing. Pada tahun 2024, China mengimport semikonduktor bernilai $ 385 bilion
 Jika Openai membeli Chrome, AI boleh memerintah perang penyemak imbasApr 25, 2025 am 11:11 AM
Jika Openai membeli Chrome, AI boleh memerintah perang penyemak imbasApr 25, 2025 am 11:11 AMPotensi yang dipaksa oleh Chrome dari Google telah menyalakan perdebatan sengit dalam industri teknologi. Prospek Openai memperoleh pelayar terkemuka, yang membanggakan bahagian pasaran global 65%, menimbulkan persoalan penting mengenai masa depan th
 Bagaimana AI dapat menyelesaikan kesakitan media runcitApr 25, 2025 am 11:10 AM
Bagaimana AI dapat menyelesaikan kesakitan media runcitApr 25, 2025 am 11:10 AMPertumbuhan media runcit semakin perlahan, walaupun melampaui pertumbuhan pengiklanan secara keseluruhan. Fasa kematangan ini memberikan cabaran, termasuk pemecahan ekosistem, peningkatan kos, isu pengukuran, dan kerumitan integrasi. Walau bagaimanapun, Buatan Buatan
 'Ai adalah kita, dan lebih daripada kita'Apr 25, 2025 am 11:09 AM
'Ai adalah kita, dan lebih daripada kita'Apr 25, 2025 am 11:09 AMSatu retak radio lama dengan statik di tengah -tengah koleksi skrin berkedip dan lengai. Tumpukan elektronik yang tidak menentu ini, dengan mudah tidak stabil, membentuk teras "Tanah E-Waste," salah satu daripada enam pemasangan dalam Pameran Immersive, & Qu
 Awan Google semakin serius mengenai infrastruktur pada 2025 seterusnyaApr 25, 2025 am 11:08 AM
Awan Google semakin serius mengenai infrastruktur pada 2025 seterusnyaApr 25, 2025 am 11:08 AMGoogle Cloud's Next 2025: Fokus pada Infrastruktur, Sambungan, dan AI Persidangan seterusnya 2025 Google Cloud mempamerkan banyak kemajuan, terlalu banyak untuk terperinci sepenuhnya di sini. Untuk analisis mendalam mengenai pengumuman khusus, rujuk artikel oleh saya
 Bercakap Baby Ai Meme, Paip Filem AI $ 5.5 juta Arcana, penyokong rahsia IR mendedahkanApr 25, 2025 am 11:07 AM
Bercakap Baby Ai Meme, Paip Filem AI $ 5.5 juta Arcana, penyokong rahsia IR mendedahkanApr 25, 2025 am 11:07 AMMinggu ini di AI dan XR: Gelombang kreativiti berkuasa AI menyapu melalui media dan hiburan, dari generasi muzik hingga pengeluaran filem. Mari kita menyelam ke tajuk utama. Impak Kandungan Kandungan Ai-Dihasilkan: Perunding Teknologi Shelly Palme


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

