
Rumah >Peranti teknologi >AI >PixelLM, model besar berbilang modal bait yang cekap melaksanakan penaakulan tahap piksel tanpa pergantungan SA
PixelLM, model besar berbilang modal bait yang cekap melaksanakan penaakulan tahap piksel tanpa pergantungan SA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-10 21:46:36674semak imbas
Model besar berbilang modal sedang meletup. Adakah anda bersedia untuk memasukkan aplikasi praktikal dalam tugasan yang terperinci seperti penyuntingan imej, pemanduan autonomi dan robotik?
Pada masa ini, keupayaan kebanyakan model masih terhad untuk menjana penerangan teks bagi keseluruhan imej atau kawasan tertentu, dan keupayaannya dalam pemahaman tahap piksel (seperti pembahagian objek) agak terhad.
Sebagai tindak balas kepada masalah ini, beberapa kerja telah mula meneroka penggunaan model besar berbilang modal untuk mengendalikan arahan pembahagian pengguna (contohnya, "Sila belah buah-buahan yang kaya dengan vitamin C dalam gambar").
Walau bagaimanapun, kaedah di pasaran mengalami dua kelemahan utama:
1) Ketidakupayaan untuk mengendalikan tugas yang melibatkan pelbagai objek sasaran, yang amat diperlukan dalam senario dunia sebenar
2) Bergantung pada alat seperti SAM Untuk pra seperti itu; -model pembahagian imej terlatih, jumlah pengiraan yang diperlukan untuk satu perambatan hadapan SAM sudah cukup untuk Llama-7B menjana lebih daripada 500 token.
Untuk menyelesaikan masalah ini, pasukan penciptaan pintar ByteDance bekerjasama dengan penyelidik dari Universiti Jiaotong Beijing dan Universiti Sains dan Teknologi Beijing untuk mencadangkan PixelLM, model inferens peringkat piksel berskala besar pertama yang cekap yang tidak bergantung pada SAM.
Sebelum memperkenalkannya secara terperinci, mari kita rasai kesan pembahagian sebenar beberapa kumpulan PixelLM:
Berbanding dengan kerja sebelumnya, kelebihan PixelLM ialah:
- Ia boleh mengendalikan sebarang bilangan sasaran domain terbuka dan penaakulan kompleks yang pelbagai. Pisah tugas.
- Mengelakkan model segmentasi tambahan dan mahal, meningkatkan kecekapan dan keupayaan pemindahan ke aplikasi yang berbeza.
Seterusnya, untuk menyokong latihan dan penilaian model dalam bidang penyelidikan ini, pasukan penyelidik membina set data MUSE untuk senario segmentasi penaakulan pelbagai objektif berdasarkan set data LVIS dan GPT-4V Ia mengandungi 200,000 Lebih daripada 900,000 pasangan soalan-jawapan, yang melibatkan lebih daripada 900,000 topeng pembahagian contoh.


Untuk mencapai kesan di atas, bagaimanakah kajian ini dijalankan?
Prinsip di sebalik
 Pictures
Pictures
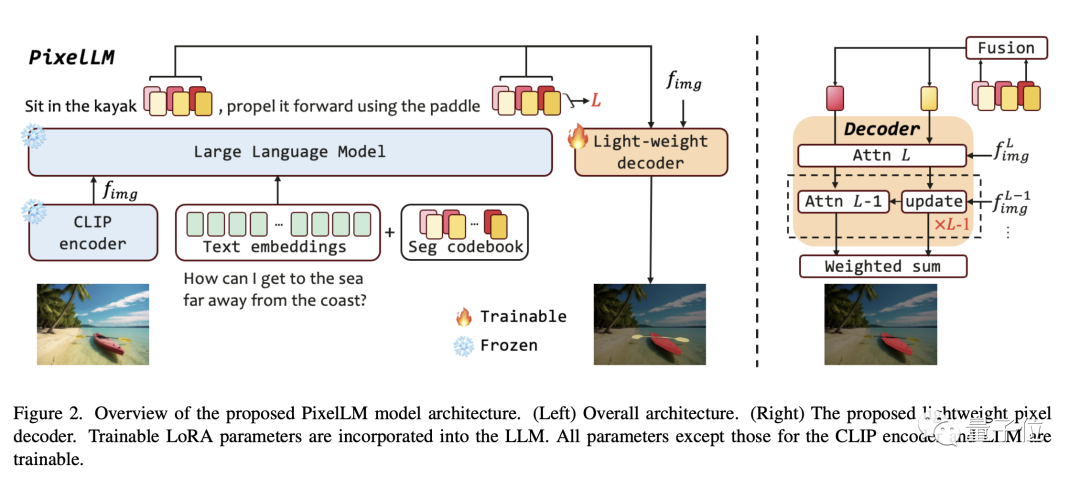
Seperti yang ditunjukkan dalam rajah rangka kerja dalam kertas, seni bina PixelLM adalah sangat mudah dan terdiri daripada empat bahagian utama yang kedua adalah teras PixelLM:
- -
- . Pengekod penglihatan CLIP-ViT terlatih
- Model Bahasa Besar
- Penyahkod Piksel Ringan
- Buku Kod Seg
Buku kod Seg mengandungi token yang boleh dipelajari, yang digunakan untuk mengekod maklumat sasaran pada skala CLIP-ViT yang berbeza. Kemudian, penyahkod piksel menjana hasil pembahagian objek berdasarkan token ini dan ciri imej CLIP-ViT. Terima kasih kepada reka bentuk ini, PixelLM boleh menjana hasil segmentasi berkualiti tinggi tanpa model segmentasi luaran, meningkatkan kecekapan model dengan ketara.
Menurut penerangan penyelidik, token dalam buku kod Seg boleh dibahagikan kepada kumpulan L, setiap kumpulan mengandungi N token, dan setiap kumpulan sepadan dengan skala daripada ciri visual CLIP-ViT.
Untuk imej input, PixelLM mengekstrak ciri skala L daripada ciri imej yang dihasilkan oleh pengekod visual CLIP-ViT Lapisan terakhir meliputi maklumat imej global dan akan digunakan oleh LLM untuk memahami kandungan imej.
Token buku kod Seg akan dimasukkan ke dalam LLM bersama-sama dengan arahan teks dan lapisan terakhir ciri imej untuk menghasilkan output dalam bentuk autoregresi. Output juga akan termasuk token buku kod Seg yang diproses oleh LLM, yang akan dimasukkan ke dalam penyahkod piksel bersama-sama ciri CLIP-ViT skala L untuk menghasilkan hasil pembahagian akhir.
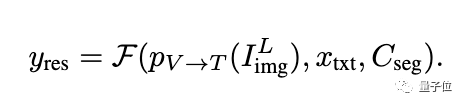 Gambar
Gambar
 Gambar
Gambar
Jadi mengapa kita perlu menetapkan setiap kumpulan untuk mengandungi N token? Para penyelidik menjelaskan bersama-sama dengan angka berikut:
Dalam senario yang melibatkan berbilang sasaran atau semantik yang terkandung dalam sasaran adalah sangat kompleks, walaupun LLM boleh memberikan respons teks terperinci, menggunakan hanya satu token mungkin tidak menangkap sepenuhnya semua semantik sasaran kandungan.
Untuk meningkatkan keupayaan model dalam senario penaakulan yang kompleks, para penyelidik memperkenalkan berbilang token dalam setiap kumpulan skala dan melakukan operasi gabungan linear bagi satu token. Sebelum token dihantar ke penyahkod, lapisan unjuran linear digunakan untuk menggabungkan token dalam setiap kumpulan.
Gambar di bawah menunjukkan kesan apabila terdapat berbilang token dalam setiap kumpulan. Peta perhatian ialah rupa setiap token selepas diproses oleh penyahkod ini menunjukkan bahawa berbilang token memberikan maklumat yang unik dan pelengkap, menghasilkan output pembahagian yang lebih berkesan.
 Pictures
Pictures
Selain itu, untuk meningkatkan keupayaan model untuk membezakan berbilang sasaran, PixelLM turut mereka bentuk Target Refinement Loss tambahan.
Set Data MUSE
Walaupun penyelesaian di atas telah dicadangkan, untuk mengeksploitasi sepenuhnya keupayaan model, model masih memerlukan data latihan yang sesuai. Mengkaji set data awam yang tersedia pada masa ini, kami mendapati bahawa data sedia ada mempunyai had utama berikut:
1) Penerangan butiran objek yang tidak mencukupi
2) Kekurangan pasangan soalan-jawapan dengan alasan yang kompleks dan nombor sasaran yang pelbagai.
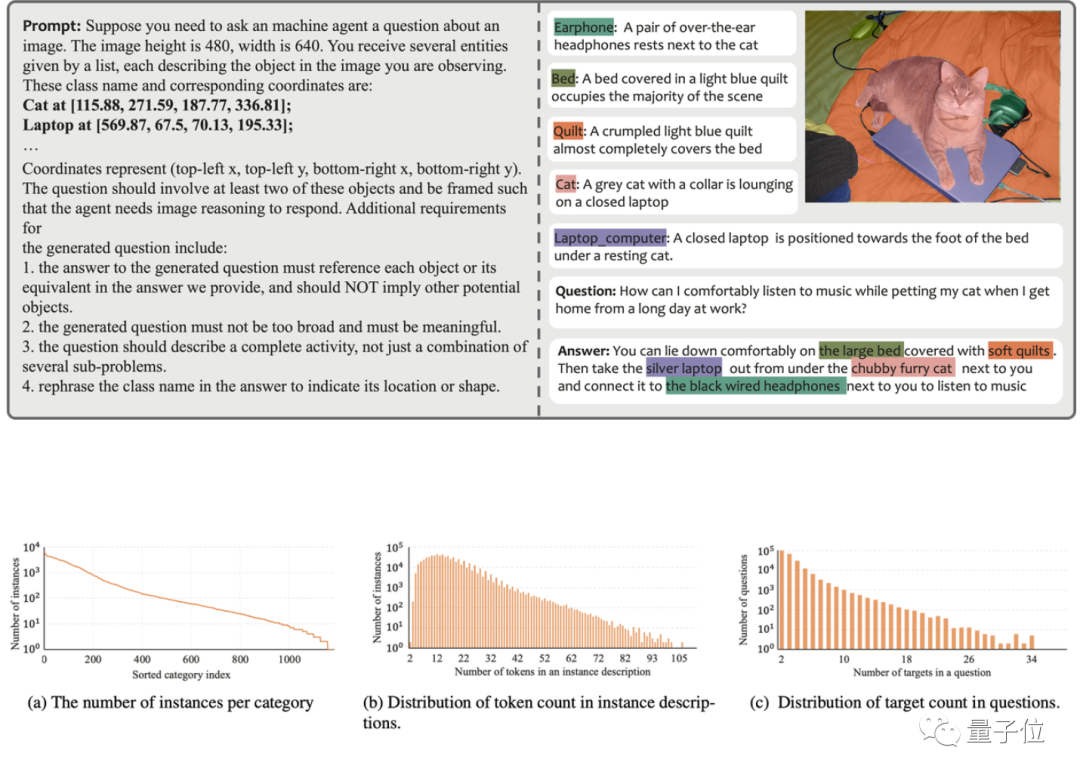
Untuk menyelesaikan masalah ini, pasukan penyelidik menggunakan GPT-4V untuk membina saluran paip anotasi data automatik, dan dengan itu menghasilkan set data MUSE. Rajah di bawah menunjukkan contoh gesaan yang digunakan semasa menjana MUSE dan data yang dijana.
 Gambar
Gambar
Dalam MUSE, semua topeng contoh adalah daripada set data LVIS, dan penerangan teks terperinci tambahan yang dijana berdasarkan kandungan imej ditambah. MUSE mengandungi 246,000 pasangan soalan-jawapan, dan setiap pasangan soalan-jawapan melibatkan purata 3.7 objek sasaran. Di samping itu, pasukan penyelidik menjalankan analisis statistik lengkap set data:
Statistik Kategori: Terdapat lebih daripada 1000 kategori dalam MUSE daripada set data LVIS asal, dan 900,000 kejadian dengan penerangan unik berdasarkan pasangan soalan-jawab berbeza-beza bergantung pada konteks. Rajah (a) menunjukkan bilangan kejadian bagi setiap kategori merentas semua pasangan soalan-jawapan.
Statistik nombor token: Rajah (b) menunjukkan taburan bilangan token yang diterangkan dalam contoh, beberapa daripadanya mengandungi lebih daripada 100 token. Perihalan ini tidak terhad kepada nama kategori mudah sebaliknya, ia diperkaya dengan maklumat terperinci tentang setiap contoh, termasuk rupa, sifat dan hubungan dengan objek lain, melalui proses penjanaan data berasaskan GPT-4V. Kedalaman dan kepelbagaian maklumat dalam set data meningkatkan keupayaan generalisasi model terlatih, membolehkannya menyelesaikan masalah domain terbuka dengan berkesan.
Statistik nombor sasaran: Rajah (c) menunjukkan statistik bilangan sasaran bagi setiap pasangan soalan-jawapan. Purata bilangan sasaran ialah 3.7, dan bilangan maksimum sasaran boleh mencapai 34. Nombor ini boleh merangkumi kebanyakan senario inferens sasaran untuk satu imej. Penilaian
Algoritma
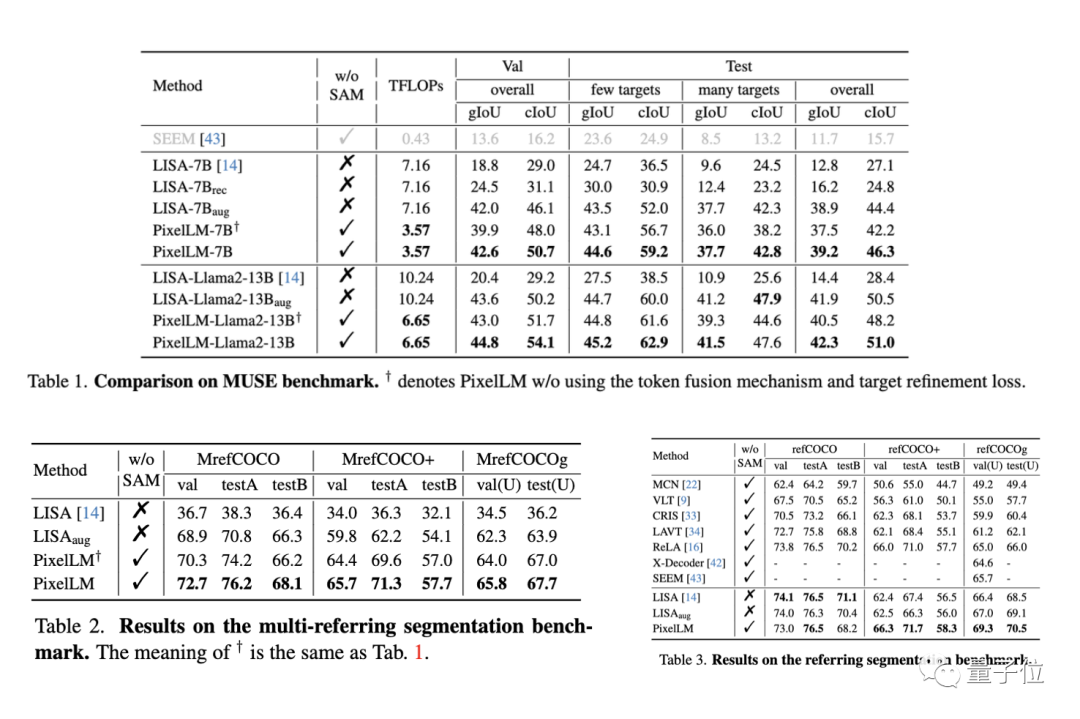
Pasukan penyelidikan menilai prestasi Pixellm pada tiga tanda aras, termasuk penanda aras Muse, merujuk penanda aras segmentasi, dan penanda aras segmentasi multi-referring. masalah Bahagikan berbilang objek secara berterusan yang terkandung dalam setiap imej dalam penanda aras pembahagian yang merujuk.
Pada masa yang sama, memandangkan PixelLM ialah model pertama yang mengendalikan tugasan penaakulan piksel kompleks yang melibatkan berbilang sasaran, pasukan penyelidik menubuhkan empat garis dasar untuk menjalankan analisis perbandingan model tersebut.
Tiga daripada garis dasar adalah berdasarkan LISA, kerja yang paling relevan pada PixelLM, termasuk:
1) LISA asal
2) LISA_rec: mula-mula masukkan soalan ke dalam LLAVA-13B untuk mendapatkan balasan teks sasaran, dan kemudian gunakan LISA untuk membahagikan teks ;
3) LISA_aug: Terus tambah MUSE pada data latihan LISA.
4) Yang satu lagi ialah SEEM, model segmentasi umum yang tidak menggunakan LLM.
 Gambar
Gambar
Pada kebanyakan penunjuk bagi tiga penanda aras, prestasi PixelLM adalah lebih baik daripada kaedah lain, dan kerana PixelLM tidak bergantung pada SAM, TFLOPnya jauh lebih rendah daripada model dengan saiz yang sama.
Rakan-rakan yang berminat boleh beri perhatian dahulu dan tunggu kod menjadi sumber terbuka~
Pautan rujukan:
[1]https://www.php.cn/link/9271858951e6fe9504d1f05ae8576001:
/www.php.cn/link/f1686b4badcf28d33ed632036c7ab0b8
Atas ialah kandungan terperinci PixelLM, model besar berbilang modal bait yang cekap melaksanakan penaakulan tahap piksel tanpa pergantungan SA. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!