
Rumah >Peranti teknologi >AI >Google Deepmind membayangkan masa depan yang mencipta semula robot, membawa kecerdasan yang terkandung kepada model berskala besar
Google Deepmind membayangkan masa depan yang mencipta semula robot, membawa kecerdasan yang terkandung kepada model berskala besar

- PHPzke hadapan
- 2024-01-09 19:49:591008semak imbas
Pada tahun lalu, model berskala besar berturut-turut telah membuat penemuan yang membentuk semula bidang penyelidikan robotik.
Dengan model besar yang paling maju menjadi "otak" robot, robot berkembang lebih pantas daripada yang dibayangkan.
Pada bulan Julai, Google DeepMind mengumumkan pelancaran RT-2: model vision-language-action (VLA) pertama di dunia untuk mengawal robot.
Anda hanya perlu memberi arahan seperti perbualan, dan ia akan dapat mengenal pasti Swift di antara sekumpulan gambar dan memberinya sebalang "air gembira".

Ia juga boleh berfikir secara proaktif, melengkapkan lonjakan penaakulan pelbagai peringkat daripada "memilih haiwan untuk kepupusan" kepada meraih dinosaur plastik di atas meja.

Selepas RT-2, Google DeepMind mencadangkan Q-Transformer, dan dunia robotik juga mempunyai Transformer sendiri. Q-Transformer membolehkan robot menembusi pergantungan mereka pada data demonstrasi berkualiti tinggi dan menjadi lebih baik dalam mengumpul pengalaman dengan bergantung pada "pemikiran" bebas.
Hanya dua bulan selepas dikeluarkan, RT-2 mempunyai satu lagi detik ImageNet untuk robot. Google DeepMind dan institusi lain melancarkan Buka idea baharu.
Bayangkan hanya memberi pembantu robot anda permintaan mudah, seperti "bersihkan rumah" atau "memasak hidangan yang lazat dan sihat", dan mereka boleh menyelesaikan tugasan ini. Bagi manusia, tugas ini mungkin mudah, tetapi bagi robot, mereka memerlukan pemahaman yang mendalam tentang dunia, yang tidak mudah. Berdasarkan penyelidikan bertahun-tahun dalam bidang Transformers robot, Google baru-baru ini mengumumkan satu siri kemajuan penyelidikan robot: AutoRT, SARA-RT dan RT-Trajectory, yang boleh membantu robot membuat keputusan dengan lebih cepat dan memahaminya dengan lebih baik Jenis persekitaran anda berada dalam boleh membimbing anda dengan lebih baik untuk menyelesaikan tugasan. Google percaya bahawa dengan pelancaran hasil penyelidikan seperti AutoRT, SARA-RT dan RT-Trajectory, ia boleh membawa peningkatan kepada pengumpulan data, kelajuan dan keupayaan generalisasi robot dunia sebenar. Seterusnya, mari semak kajian penting ini.AutoRT: Gunakan model besar untuk melatih robot dengan lebih baik
AutoRT menggabungkan model asas yang besar (seperti model bahasa besar (LLM) atau model bahasa visual (VLM)) dan model kawalan robot (RT-1 atau RT-2 ) , mencipta sistem yang boleh menggunakan robot dalam persekitaran baharu untuk mengumpul data latihan. AutoRT serentak boleh membimbing berbilang robot yang dilengkapi dengan kamera video dan pengesan akhir untuk melaksanakan pelbagai tugas dalam pelbagai persekitaran. Secara khusus, setiap robot akan menggunakan model bahasa visual (VLM) untuk "melihat sekeliling" dan memahami persekitaran serta objek dalam garis penglihatannya, berdasarkan AutoRT. Seterusnya, model bahasa besar akan mencadangkan satu siri tugasan kreatif untuknya, seperti "meletakkan makanan ringan di atas meja," dan memainkan peranan sebagai pembuat keputusan, memilih tugasan untuk dilakukan oleh robot. Penyelidik menjalankan penilaian menyeluruh selama tujuh bulan AutoRT di dunia nyata. Eksperimen telah membuktikan bahawa sistem AutoRT boleh menyelaraskan sehingga 20 robot pada masa yang sama dengan selamat, dan jumlah maksimum 52 robot. Dengan membimbing robot untuk melaksanakan pelbagai tugas dalam pelbagai bangunan pejabat, para penyelidik mengumpul set data yang pelbagai merangkumi 77,000 ujian robot dengan 6,650 tugas unik.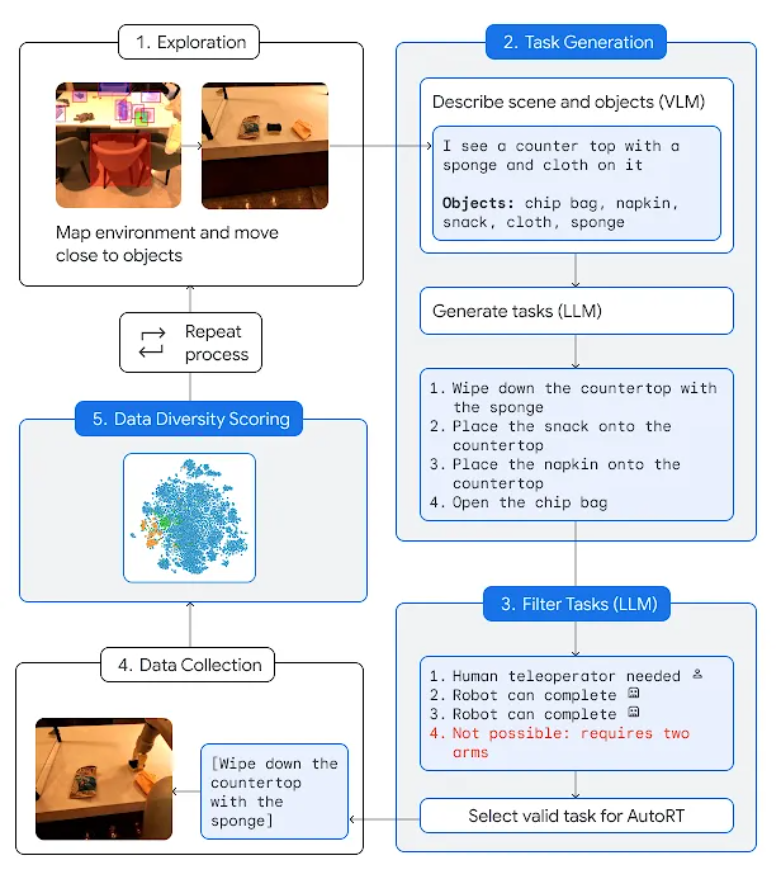
Walaupun AutoRT hanyalah sistem pengumpulan data sekarang, anggaplah ia sebagai peringkat awal robot autonomi di dunia nyata. Ia menampilkan pagar keselamatan, salah satunya ialah satu set kata gesaan berfokuskan keselamatan yang menyediakan peraturan asas untuk dipatuhi apabila robot membuat keputusan berasaskan LLM.
Peraturan ini sebahagiannya diilhamkan oleh Three Laws of Robotics Isaac Asimov, yang paling penting ialah robot "tidak boleh membahayakan manusia." Peraturan keselamatan juga memerlukan robot untuk tidak mencuba tugas yang melibatkan manusia, haiwan, objek tajam atau peralatan elektrik.
Hanya bekerja pada kata-kata segera tidak dapat menjamin sepenuhnya isu keselamatan dalam aplikasi sebenar robot. Oleh itu, sistem AutoRT juga merangkumi lapisan langkah keselamatan praktikal yang merupakan reka bentuk klasik robotik. Contohnya, robot kolaboratif diprogramkan untuk berhenti secara automatik jika daya pada sendi mereka melebihi ambang yang diberikan, dan semua robot yang dikawal secara autonomi boleh dihadkan kepada garis penglihatan penyelia manusia melalui suis penyahaktifan fizikal.
SARA-RT: Jadikan robot Transformer (RT) lebih pantas dan ramping
Satu lagi pencapaian, SARA-RT, boleh menukar model robot Transformer (RT) kepada versi yang lebih cekap.
Seni bina rangkaian neural RT yang dibangunkan oleh pasukan Google telah digunakan dalam sistem kawalan robot terkini, termasuk model RT-2. Model SARA-RT-2 terbaik adalah 10.6% lebih tepat dan 14% lebih pantas daripada model RT-2 apabila diberi sejarah imej ringkas. Google mengatakan ia adalah mekanisme perhatian berskala pertama yang meningkatkan kuasa pengkomputeran tanpa menjejaskan kualiti.
Walaupun Transformer berkuasa, mereka boleh dihadkan oleh keperluan pengiraan, memperlahankan proses membuat keputusan. Transformer terutamanya bergantung pada modul perhatian kerumitan kuadratik. Ini bermakna jika input kepada model RT digandakan (cth., menyediakan robot dengan lebih banyak atau lebih penderia resolusi lebih tinggi), sumber pengiraan yang diperlukan untuk memproses input itu meningkat empat kali ganda, mengakibatkan pembuatan keputusan yang lebih perlahan.
SARA-RT menggunakan kaedah penalaan halus model baru (dipanggil "up-training") untuk meningkatkan kecekapan model. Uptraining menukarkan kerumitan kuadratik kepada kerumitan linear semata-mata, dengan ketara mengurangkan keperluan pengiraan. Penukaran ini bukan sahaja meningkatkan kelajuan model asal, tetapi juga mengekalkan kualitinya.
Google berharap ramai penyelidik dan pengamal akan menggunakan sistem praktikal ini untuk robotik dan bidang lain. Oleh kerana SARA menyediakan kaedah umum untuk mempercepatkan Transformer tanpa memerlukan pra-latihan yang mahal secara pengiraan, pendekatan ini berpotensi untuk menskalakan teknologi Transformer pada skala. SARA-RT tidak memerlukan sebarang pengekodan tambahan kerana pelbagai varian linear sumber terbuka tersedia.
Apabila SARA-RT digunakan pada model SOTA RT-2 dengan berbilion parameter, ia membolehkan membuat keputusan yang lebih pantas dan prestasi yang lebih baik dalam pelbagai tugas robotik:

untuk manipulasi SARA-RT-2 model misi. Pergerakan robot dikondisikan pada imej dan arahan teks.
Dengan asas teori yang kukuh, SARA-RT boleh diaplikasikan pada pelbagai model Transformer. Contohnya, menggunakan SARA-RT pada Point Cloud Transformer, yang memproses data spatial daripada kamera kedalaman robot, boleh lebih daripada menggandakan kelajuan.
RT-Trajektori: Membantu robot membuat generalisasi
Manusia secara intuitif boleh memahami dan belajar cara membersihkan meja, tetapi robot memerlukan banyak cara yang mungkin untuk menterjemahkan arahan kepada tindakan fizikal sebenar.
Secara tradisinya, latihan senjata robot bergantung pada pemetaan bahasa semula jadi abstrak (lap meja) kepada tindakan konkrit (tutup pencengkam, gerak ke kiri, gerak ke kanan), yang menyukarkan untuk menyamaratakan model kepada tugasan baharu . Sebaliknya, Model RT-Trajektori membolehkan model RT memahami "bagaimana" tugasan dicapai dengan mentafsir tindakan robot tertentu (seperti dalam video atau lakaran).
Model RT-Trajektori boleh menambah garis besar visual secara automatik untuk menerangkan pergerakan robot dalam video latihan. RT-Trajektori menindan setiap video dalam set data latihan dengan lakaran trajektori 2D pencengkam semasa lengan robot menjalankan tugas. Trajektori ini, dalam bentuk imej RGB, memberikan petunjuk visual praktikal tahap rendah untuk model mempelajari strategi kawalan robot.
Apabila diuji pada 41 tugasan yang tidak dilihat dalam data latihan, lengan robot yang dikawal oleh RT-Trajectory lebih dua kali ganda prestasi model SOTA RT sedia ada: kadar kejayaan tugasan mencapai 63%, manakala RT- 2 mempunyai kadar kejayaan hanya 29%.
Sistem ini sangat serba boleh, RT-Trajectory juga boleh mencipta trajektori dengan menonton demonstrasi manusia tentang tugas yang diperlukan, dan juga menerima lakaran lukisan tangan. Selain itu, ia boleh menyesuaikan diri dengan platform robot yang berbeza pada bila-bila masa.
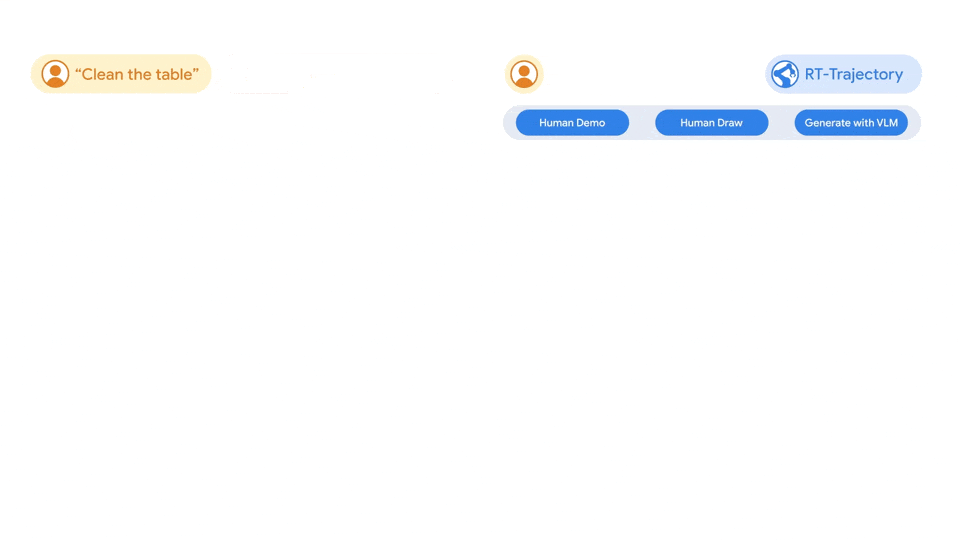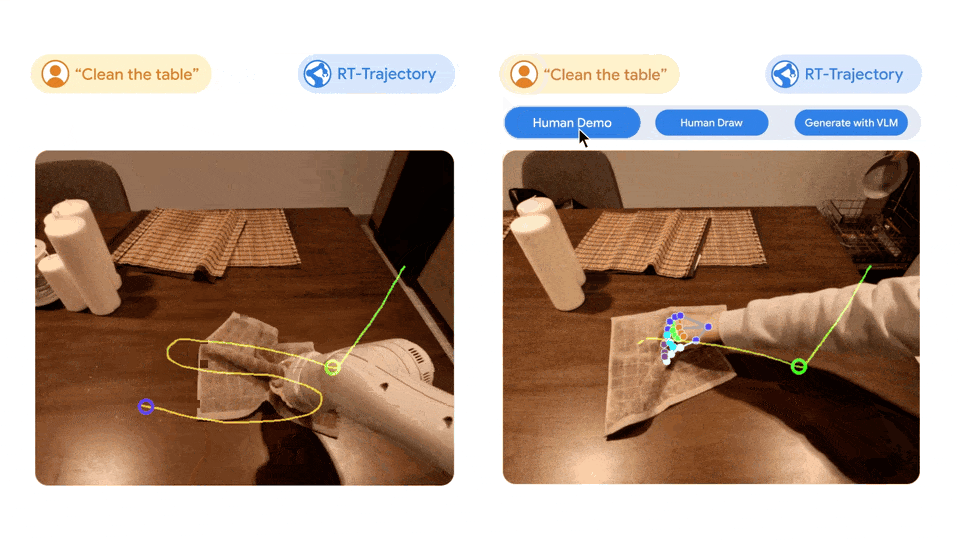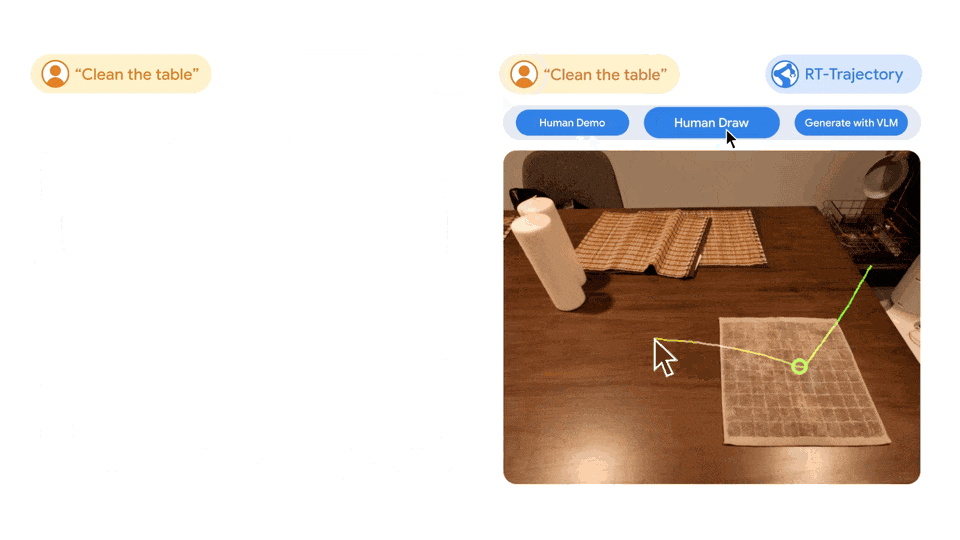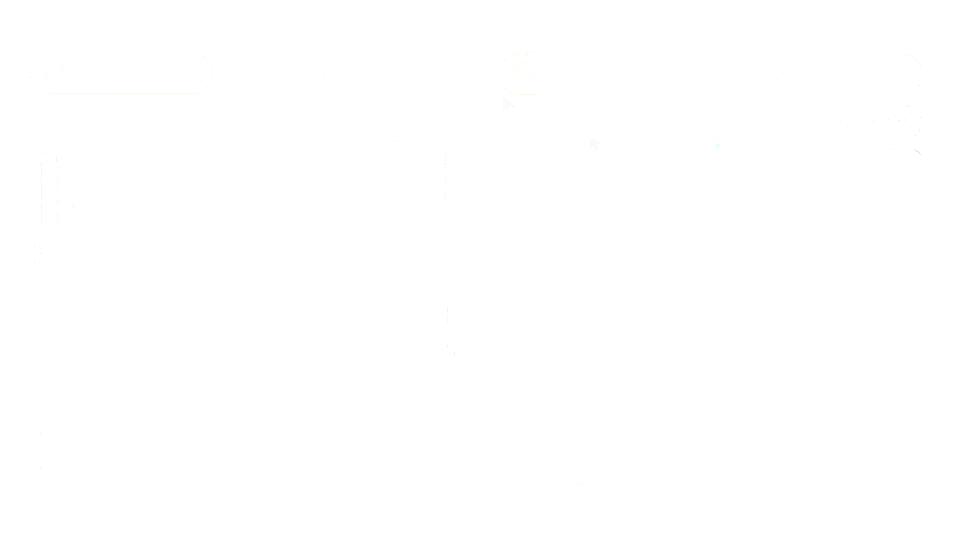 Gambar kiri: Robot yang dikawal oleh model RT yang dilatih hanya menggunakan set data bahasa semula jadi berasa kecewa apabila melakukan tugas baharu mengelap meja, manakala robot yang dikawal oleh model trajektori RT yang dilakukan pada set data yang sama dipertingkatkan. oleh trajektori 2D Selepas latihan, trajektori mengelap telah berjaya dirancang dan dilaksanakan. Kanan: Model trajektori RT terlatih, diberi tugas baharu (mengelap meja), boleh mencipta trajektori 2D dalam pelbagai cara, dengan bantuan manusia atau sendiri menggunakan model bahasa visual.
Gambar kiri: Robot yang dikawal oleh model RT yang dilatih hanya menggunakan set data bahasa semula jadi berasa kecewa apabila melakukan tugas baharu mengelap meja, manakala robot yang dikawal oleh model trajektori RT yang dilakukan pada set data yang sama dipertingkatkan. oleh trajektori 2D Selepas latihan, trajektori mengelap telah berjaya dirancang dan dilaksanakan. Kanan: Model trajektori RT terlatih, diberi tugas baharu (mengelap meja), boleh mencipta trajektori 2D dalam pelbagai cara, dengan bantuan manusia atau sendiri menggunakan model bahasa visual.
Trajektori RT mengeksploitasi maklumat gerakan robot yang kaya yang terdapat dalam semua set data robot tetapi pada masa ini kurang digunakan. RT-Trajectory bukan sahaja mewakili satu lagi langkah dalam laluan untuk mencipta robot yang bergerak dengan cekap dan tepat untuk tugasan baharu, tetapi juga membolehkan penemuan pengetahuan daripada set data sedia ada.
Atas ialah kandungan terperinci Google Deepmind membayangkan masa depan yang mencipta semula robot, membawa kecerdasan yang terkandung kepada model berskala besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Artikel ciri|Permintaan untuk kuasa pengkomputeran meletup di bawah ledakan model besar AI: Lingang mahu membina industri berpuluh-puluh bilion, dan SenseTime akan menjadi 'tuan rantai'
- Untuk membantu pembangunan industri Yuanverse, pertandingan aplikasi inovatif komunikasi mudah alih ini telah dilancarkan
- Penerokaan aplikasi bahasa Go dalam industri kereta pintar
- Kementerian Perindustrian dan Teknologi Maklumat: skala industri teras AI negara saya mencapai 500 bilion yuan, dan lebih daripada 2,500 bengkel digital dan kilang pintar telah dibina
- Forum Pembangunan Industri Model Besar Kecerdasan Buatan Am dan Majlis Pembukaan Kawasan Kluster Industri Model Besar Kepintaran Buatan Am di Daerah Shijingshan telah berlangsung dengan jayanya