
Rumah >Peranti teknologi >AI >Kaedah baharu Universiti Tsinghua berjaya mengesan klip video yang tepat! SOTA telah diatasi dan sumber terbuka
Kaedah baharu Universiti Tsinghua berjaya mengesan klip video yang tepat! SOTA telah diatasi dan sumber terbuka

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-09 15:26:221309semak imbas
Dengan hanya satu ayat penerangan, anda boleh mencari klip yang sepadan dalam video besar!
Sebagai contoh, menerangkan "seseorang minum air semasa menuruni tangga", melalui pemadanan imej video dan jejak langkah, kaedah baharu boleh mencari cap masa mula dan tamat yang sepadan dengan serta-merta:

Malah Semantik "ketawa" yang sukar difahami juga boleh diletakkan dengan tepat:

Kaedah ini dipanggil Adaptive Dual Branch Promotion Network (ADPN), yang dicadangkan oleh pasukan penyelidik Universiti Tsinghua.
Secara khusus, ADPN digunakan untuk menyelesaikan tugasan silang mod visual-linguistik yang dipanggil penentududukan klip video (Temporal Sentence Grounding, TSG), iaitu untuk mencari klip yang berkaitan daripada video berdasarkan teks pertanyaan.
ADPN dicirikan oleh keupayaannya untuk menggunakan secara cekap konsisten dan pelengkap modaliti visual dan audio dalam video untuk meningkatkan prestasi kedudukan klip video.
Berbanding dengan kerja TSG PMI-LOC dan UMT lain yang menggunakan audio, kaedah ADPN telah mencapai peningkatan prestasi yang lebih ketara daripada mod audio, dan telah memenangi SOTA baharu dalam berbilang ujian.
Pada masa ini, karya ini telah diterima oleh ACM Multimedia 2023 dan merupakan sumber terbuka sepenuhnya.

Mari kita lihat apa itu ADPN~
Menempatkan klip video dalam satu ayat
Penempatan klip video (Pengasasan Ayat Temporal, TSG) ialah tugas silang mod visual-linguistik yang penting
Tujuannya adalah untuk mencari cap masa mula dan tamat segmen yang sepadan secara semantik dalam video yang tidak diedit berdasarkan pertanyaan bahasa semula jadi. Kaedah ini memerlukan keupayaan penaakulan rentas mod temporal yang kuat.
Walau bagaimanapun, kebanyakan kaedah TSG sedia ada hanya mempertimbangkan maklumat visual dalam video, seperti RGB, aliran optik(aliran optik), kedalaman(depth), dsb., sambil mengabaikan maklumat audio yang secara semula jadi mengiringi video. .
Maklumat audio selalunya mengandungi semantik yang kaya dan konsisten serta pelengkap dengan maklumat visual Seperti yang ditunjukkan dalam rajah di bawah, sifat ini akan membantu tugasan TSG.
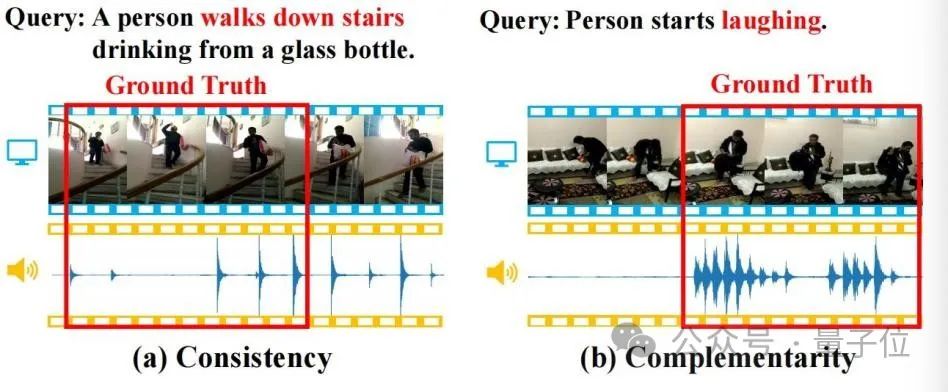
△Rajah 1
(a) Ketekalan: Imej video dan jejak kaki secara konsisten sepadan dengan semantik "turun tangga" dalam pertanyaan; (b) Pelengkap: Imej video sukar dikenal pasti tingkah laku untuk mencari makna semantik "ketawa" dalam pertanyaan, tetapi kehadiran ketawa memberikan petunjuk kedudukan pelengkap yang kuat.
Jadi penyelidik telah mengkaji dengan mendalam tugas penyetempatan klip video yang dipertingkatkan audio(Pengasasan Ayat Temporal Dipertingkatkan Audio, ATSG), bertujuan untuk menangkap petunjuk penyetempatan dengan lebih baik daripada modaliti visual dan audio Walau bagaimanapun, pengenalan mod audio modaliti juga membawa cabaran berikut:
- Ketekalan dan pelengkap modaliti audio dan visual dikaitkan dengan teks pertanyaan, jadi menangkap ketekalan dan pelengkap audiovisual memerlukan pemodelan teks-visual-audio tiga mod interaksi nyata.
- Terdapat perbezaan modal yang ketara antara audio dan penglihatan Ketumpatan maklumat dan keamatan bunyi kedua-duanya adalah berbeza, yang akan menjejaskan prestasi pembelajaran audio-visual.
Untuk menyelesaikan cabaran di atas, penyelidik mencadangkan kaedah ATSG novel "Rangkaian Digesa Dwi-cawangan Adaptif" (Rangkaian Digesa Dwi-cawangan Adaptif, ADPN).
Melalui reka bentuk struktur model dwi-cawangan, kaedah ini secara adaptif boleh memodelkan ketekalan dan pelengkap antara audio dan penglihatan, dan seterusnya menghapuskan hingar mod audio menggunakan strategi pengoptimuman denoising berdasarkan gangguan pembelajaran kursus, mendedahkan kepentingan isyarat audio untuk video mendapatkan semula.
Struktur keseluruhan ADPN ditunjukkan dalam rajah di bawah:
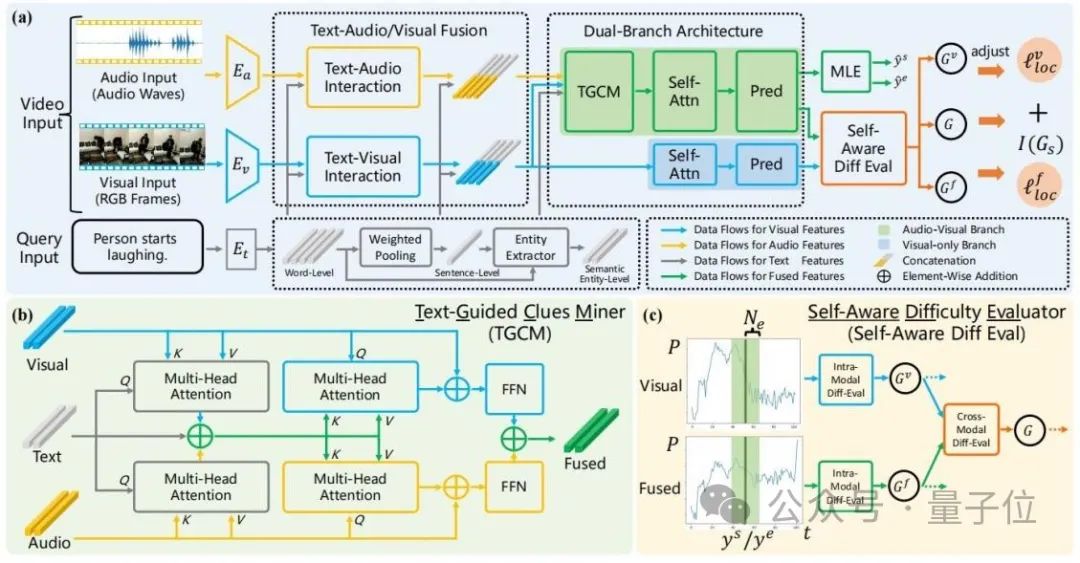
△ Rajah 2: Gambar rajah skema keseluruhan Rangkaian Promosi Dua Cawangan Adaptive (ADPN)
Ia merangkumi tiga reka bentuk:
.1reka bentuk struktur rangkaian
Memandangkan bunyi audio lebih jelas, dan untuk tugasan TSG, audio biasanya mempunyai lebih banyak maklumat berlebihan, jadi proses pembelajaran modaliti audio dan visual perlu diberi kepentingan yang berbeza, jadi artikel ini melibatkan dua cawangan Struktur rangkaian menggunakan audio dan penglihatan untuk pembelajaran pelbagai mod sambil meningkatkan maklumat visual.Secara khusus, merujuk kepada Rajah 2(a), ADPN secara serentak melatih cawangan (cawangan visual) yang hanya menggunakan maklumat visual dan cawangan (cawangan bersama) yang menggunakan kedua-dua maklumat visual dan maklumat audio.
Kedua-dua cawangan mempunyai struktur yang serupa, di mana cawangan bersama menambah unit perlombongan petunjuk teks (TGCM) untuk memodelkan interaksi mod teks-visual-audio. Semasa proses latihan, kedua-dua cawangan mengemas kini parameter pada masa yang sama, dan fasa inferens menggunakan hasil cawangan bersama sebagai hasil ramalan model. Pelombong Berpandukan Teks untuk memodelkan interaksi antara tiga modaliti teks-visual-audio.
Rujuk Rajah 2(b), TGCM terbahagi kepada dua langkah: "extraction" dan "propagation". Pertama, teks digunakan sebagai syarat pertanyaan, dan maklumat yang berkaitan diekstrak dan disepadukan daripada modaliti visual dan audio, kemudian modaliti visual dan audio digunakan sebagai syarat pertanyaan, dan maklumat bersepadu disebarkan ke visual dan mod audio melalui perhatian Modaliti masing-masing akhirnya digabungkan melalui FFN.
3. Strategi Pengoptimuman Pembelajaran KurikulumPenyelidik mendapati bahawa audio mengandungi hingar, yang akan menjejaskan kesan pembelajaran pelbagai mod, jadi mereka menggunakan intensiti hingar sebagai rujukan untuk kesukaran sampel dan memperkenalkan pembelajaran kurikulum
(Curriculum Learning , CL)Denoise the optimization process, rujuk Rajah 2(c).
Mereka menilai kesukaran sampel berdasarkan perbezaan output yang diramalkan bagi kedua-dua cabang Mereka percaya bahawa sampel yang terlalu sukar mempunyai kebarangkalian yang tinggi untuk menunjukkan bahawa audionya mengandungi terlalu banyak hingar dan tidak sesuai untuk. Tugas TSG, jadi kerugian kepada proses latihan adalah berdasarkan skor penilaian kesukaran sampel Istilah fungsi ditimbang semula untuk membuang kecerunan buruk yang disebabkan oleh hingar dalam audio. . tugasan, dan dibandingkan dengan kaedah garis dasar Perbandingan ditunjukkan dalam Jadual 1. Kaedah ADPN boleh mencapai prestasi SOTA, khususnya, berbanding PMI-LOC dan UMT kerja TSG lain yang menggunakan audio, kaedah ADPN memperoleh peningkatan prestasi yang lebih ketara daripada modaliti audio, menunjukkan bahawa kaedah ADPN menggunakan modaliti audio untuk menggalakkan keunggulan TSG.
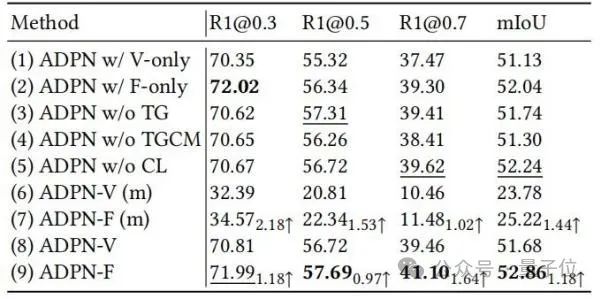
△Jadual 1: Keputusan eksperimen pada Charades-STA dan ActivityNet CaptionsPara penyelidik seterusnya menunjukkan keberkesanan unit reka bentuk yang berbeza dalam ADPN melalui eksperimen ablasi, seperti yang ditunjukkan dalam Jadual 2.
△Jadual 2: Eksperimen Ablasi pada Charades-STA
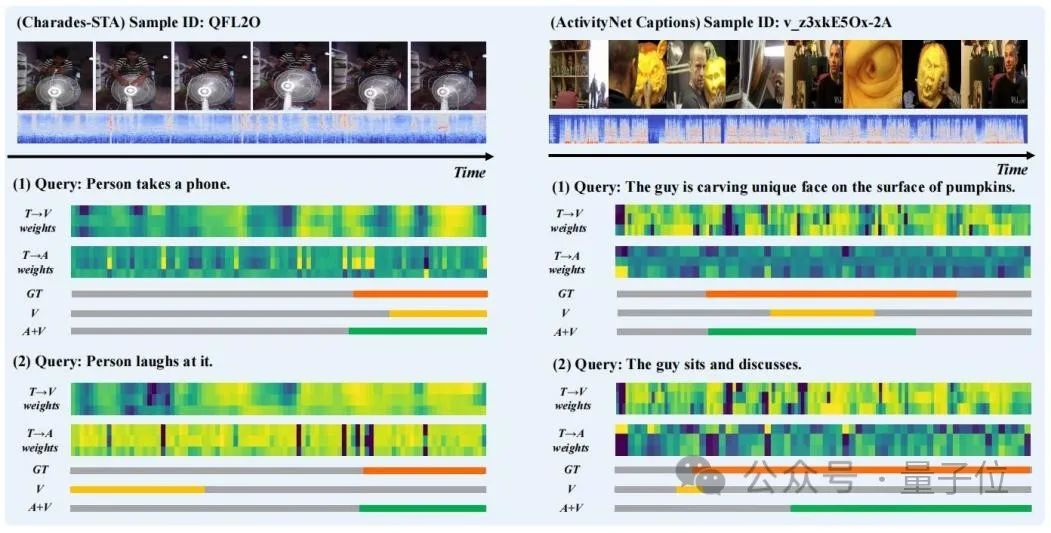
Para penyelidik memilih keputusan ramalan beberapa sampel untuk visualisasi, dan melukis "teks kepada penglihatan" (T→V) dalam langkah "pengekstrakan" dalam TGCM ) dan "teks ke audio" (T→A) taburan berat perhatian, seperti yang ditunjukkan dalam Rajah 3.
Dapat diperhatikan bahawa pengenalan modaliti audio meningkatkan hasil ramalan. Daripada kes "Orang mentertawakannya", kita dapat melihat bahawa taburan berat perhatian T→A adalah lebih dekat dengan Ground Truth, yang membetulkan panduan sesat ramalan model oleh taburan berat T→V. .
Mereka mereka bentuk struktur model dwi-cawangan untuk bersama-sama melatih cawangan visual dan cabang gabungan audiovisual untuk menyelesaikan perbezaan maklumat antara modaliti audio dan visual. 
Mereka juga mencadangkan unit perlombongan petunjuk teks 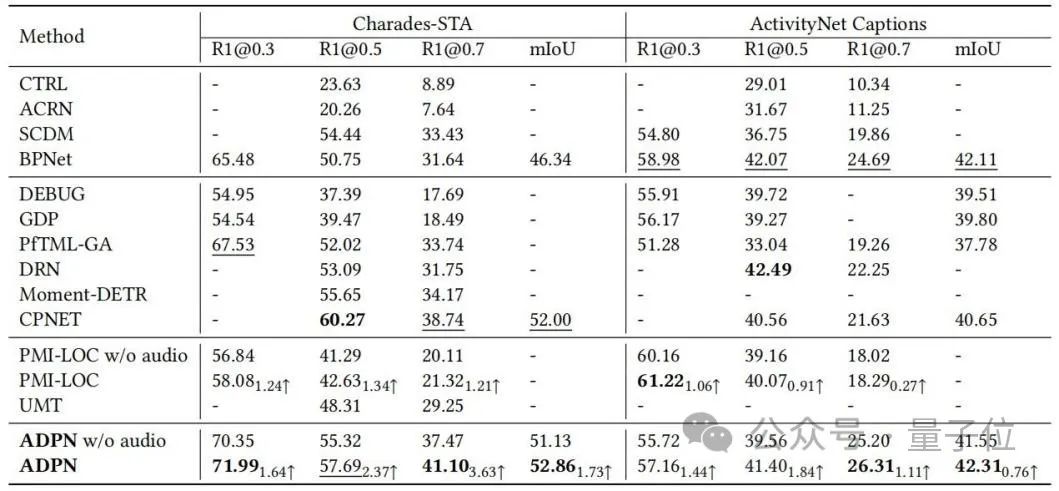
(TGCM)
yang menggunakan semantik teks sebagai panduan untuk memodelkan interaksi teks-audio-visual. Akhir sekali, para penyelidik mereka bentuk strategi pengoptimuman berasaskan pembelajaran kursus untuk menghapuskan lagi hingar audio, menilai kesukaran sampel sebagai ukuran keamatan hingar dengan cara yang sedar diri dan menyesuaikan proses pengoptimuman secara adaptif.
Mereka mula-mula menjalankan kajian mendalam tentang ciri-ciri audio dalam ATSG untuk meningkatkan kesan peningkatan prestasi mod audio dengan lebih baik.
 Mereka mula-mula menjalankan kajian mendalam tentang ciri-ciri audio dalam ATSG untuk meningkatkan kesan peningkatan prestasi mod audio dengan lebih baik.
Mereka mula-mula menjalankan kajian mendalam tentang ciri-ciri audio dalam ATSG untuk meningkatkan kesan peningkatan prestasi mod audio dengan lebih baik. Pada masa hadapan, mereka berharap dapat membina penanda aras penilaian yang lebih sesuai untuk ATSG bagi menggalakkan penyelidikan yang lebih mendalam dalam bidang ini.
Pautan kertas: https://dl.acm.org/doi/pdf/10.1145/3581783.3612504Pautan repositori: https://github.com/hlchen23/ADPN-MM
Atas ialah kandungan terperinci Kaedah baharu Universiti Tsinghua berjaya mengesan klip video yang tepat! SOTA telah diatasi dan sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!