
Rumah >Peranti teknologi >AI >LLM belajar untuk melawan satu sama lain, dan model asas mungkin membawa kepada inovasi kumpulan
LLM belajar untuk melawan satu sama lain, dan model asas mungkin membawa kepada inovasi kumpulan

- 王林ke hadapan
- 2024-01-08 19:34:011239semak imbas
Terdapat kemahiran seni mempertahankan diri yang unik dalam novel seni mempertahankan diri Jin Yong: pertarungan kiri dan kanan Ia adalah seni mempertahankan diri yang dicipta oleh Zhou Botong yang berlatih bersungguh-sungguh di dalam gua di Pulau Peach Blossom selama lebih daripada sepuluh tahun bergaduh antara tangan kiri dan tangan kanan untuk hiburan sendiri. Idea ini bukan sahaja boleh digunakan untuk berlatih seni mempertahankan diri, tetapi juga boleh digunakan untuk melatih model pembelajaran mesin, seperti Generative Adversarial Network (GAN) yang menjadi tumpuan sejak beberapa tahun lalu.
Dalam era model besar (LLM) hari ini, penyelidik telah menemui penggunaan halus interaksi kiri dan kanan. Baru-baru ini, pasukan Gu Quanquan di University of California, Los Angeles, mencadangkan kaedah baharu yang dipanggil SPIN (Self-Play Fine-Tuning). Kaedah ini boleh meningkatkan keupayaan LLM hanya melalui permainan sendiri tanpa menggunakan data penalaan halus tambahan. Profesor Gu Quanquan berkata: "Adalah lebih baik untuk mengajar seseorang memancing daripada mengajarnya memancing: melalui penalaan halus permainan sendiri (SPIN), semua model besar boleh diperbaiki daripada lemah kepada kuat
Penyelidikan ini juga pada rangkaian sosial Ia telah menyebabkan banyak perbincangan Contohnya, Profesor Ethan Mollick dari Wharton School of the University of Pennsylvania berkata: "Lebih banyak bukti menunjukkan bahawa AI tidak akan dihadkan oleh jumlah yang dicipta oleh manusia. kandungan yang tersedia untuk latihan. Kertas ini sekali lagi menunjukkan bahawa penggunaan AI Training AI dengan data yang dicipta boleh mencapai hasil yang lebih berkualiti daripada hanya menggunakan data buatan manusia "
Selain itu, terdapat ramai penyelidik yang. teruja dengan kaedah ini dan menantikan perkembangannya ke arah yang berkaitan pada tahun 2024. Kemajuan menunjukkan jangkaan yang besar. Profesor Gu Quanquan memberitahu Machine Heart: "Jika anda ingin melatih model besar di luar GPT-4, ini adalah teknologi yang pasti patut dicuba." /2401.01335.pdf.
 Model Bahasa Besar (LLM) telah memulakan era kejayaan dalam kecerdasan buatan am (AGI), dengan keupayaan luar biasa untuk menyelesaikan pelbagai tugas yang memerlukan penaakulan dan kepakaran yang kompleks. Bidang kepakaran LLM termasuk penaakulan/penyelesaian masalah matematik, penjanaan kod/pengaturcaraan, penjanaan teks, rumusan dan penulisan kreatif, dan banyak lagi.
Model Bahasa Besar (LLM) telah memulakan era kejayaan dalam kecerdasan buatan am (AGI), dengan keupayaan luar biasa untuk menyelesaikan pelbagai tugas yang memerlukan penaakulan dan kepakaran yang kompleks. Bidang kepakaran LLM termasuk penaakulan/penyelesaian masalah matematik, penjanaan kod/pengaturcaraan, penjanaan teks, rumusan dan penulisan kreatif, dan banyak lagi.
Satu kemajuan utama LLM ialah proses penjajaran selepas latihan, yang boleh menjadikan model berkelakuan lebih selaras dengan keperluan, tetapi proses ini sering bergantung pada data berlabel manusia yang mahal. Kaedah penjajaran klasik termasuk penyeliaan penalaan halus (SFT) berdasarkan demonstrasi manusia dan pembelajaran pengukuhan berdasarkan maklum balas keutamaan manusia (RLHF).
Dan kaedah penjajaran ini semuanya memerlukan sejumlah besar data berlabel manusia. Oleh itu, untuk menyelaraskan proses penjajaran, penyelidik berharap untuk membangunkan kaedah penalaan halus yang memanfaatkan data manusia dengan berkesan.
Ini juga merupakan matlamat penyelidikan ini: untuk membangunkan kaedah penalaan halus baharu supaya model penalaan halus dapat terus menjadi lebih kukuh, dan proses penalaan halus ini tidak memerlukan penggunaan data berlabel manusia di luar set data penalaan halus.
Malah, komuniti pembelajaran mesin sentiasa mengambil berat tentang cara menambah baik model yang lemah kepada model yang kukuh tanpa menggunakan data latihan tambahan bahkan boleh dikesan kembali kepada algoritma penggalak. Terdapat juga kajian yang menunjukkan bahawa algoritma latihan kendiri boleh menukar pelajar yang lemah kepada pelajar yang kuat dalam model hibrid tanpa memerlukan data berlabel tambahan. Walau bagaimanapun, keupayaan untuk menambah baik LLM secara automatik tanpa bimbingan luaran adalah rumit dan kurang dikaji. Ini menimbulkan persoalan berikut:
Bolehkah kita membuat peningkatan diri LLM tanpa data berlabel manusia tambahan? . Matlamat seterusnya adalah untuk mencari LLM pθ{t+1} baharu yang mempunyai keupayaan untuk membezakan tindak balas y' yang dihasilkan oleh pθt daripada tindak balas y yang diberikan oleh manusia.
Proses ini boleh dilihat sebagai proses permainan antara dua pemain: pemain utama ialah LLM pθ{t+1} baharu, yang matlamatnya adalah untuk membezakan tindak balas pemain lawan pθt daripada tindak balas yang dihasilkan manusia; pemain lawan ialah LLM pθt lama, yang tugasnya adalah untuk menjana respons yang sedekat mungkin dengan set data SFT berlabel manusia.
LLM pθ{t+1} baharu diperoleh dengan memperhalusi LLM pθt lama Proses latihan adalah untuk menjadikan LLM pθ{t+1} baharu mempunyai kebolehan yang baik untuk membezakan tindak balas y' yang dihasilkan oleh pθt. dan tindak balas yang diberikan oleh manusia y. Dan latihan ini bukan sahaja membolehkan LLM pθ{t+1} baharu mencapai keupayaan diskriminasi yang baik sebagai pemain utama, tetapi juga membolehkan LLM pθ{t+1} baharu memberikan penjajaran yang lebih baik sebagai pemain lawan dalam lelaran seterusnya. Respons daripada set data SFT. Dalam lelaran seterusnya, LLM pθ{t+1} yang baru diperolehi menjadi pemain lawan yang dijana tindak balas. . berbeza daripada versi sebelumnya dan manusia Respons yang dihasilkan adalah berbeza.
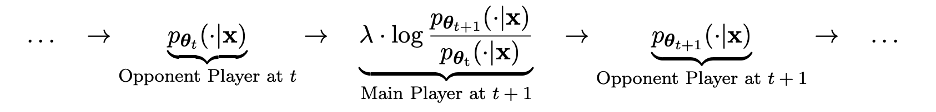 Menariknya, kaedah baharu ini menunjukkan persamaan dengan kaedah pengoptimuman keutamaan langsung (DPO) yang baru-baru ini dicadangkan oleh Rafailov et al., tetapi perbezaan ketara kaedah baharu itu ialah penggunaan mekanisme permainan sendiri. Oleh itu, kaedah baharu ini mempunyai kelebihan yang ketara: tiada data keutamaan manusia tambahan diperlukan.
Menariknya, kaedah baharu ini menunjukkan persamaan dengan kaedah pengoptimuman keutamaan langsung (DPO) yang baru-baru ini dicadangkan oleh Rafailov et al., tetapi perbezaan ketara kaedah baharu itu ialah penggunaan mekanisme permainan sendiri. Oleh itu, kaedah baharu ini mempunyai kelebihan yang ketara: tiada data keutamaan manusia tambahan diperlukan.

Pasukan juga menjalankan pembuktian teori kaedah baharu ini, dan keputusan menunjukkan kaedah itu boleh menumpu jika dan hanya jika pengedaran LLM adalah sama dengan pengedaran data sasaran, iaitu, p_θ_t=p_data.
Eksperimen
Dalam percubaan, pasukan menggunakan instance LLM zephyr-7b-sft-full berdasarkan penalaan halus Mistral-7B.
Hasilnya menunjukkan bahawa kaedah baharu boleh terus meningkatkan zephyr-7b-sft-full dalam lelaran berterusan Sebagai perbandingan, apabila kaedah SFT digunakan untuk latihan berterusan pada dataset SFT Ultrachat200k, skor penilaian akan mencapai prestasi. kesesakan.
Apa yang lebih menarik ialah set data yang digunakan oleh kaedah baharu hanyalah subset 50k daripada set data Ultrachat200k!
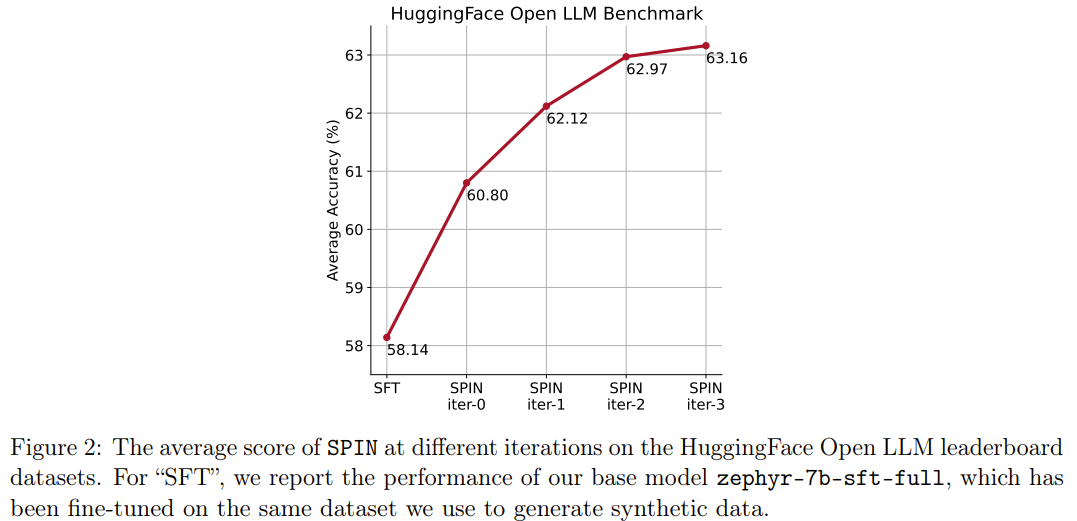
Kaedah baharu SPIN mempunyai satu lagi pencapaian: ia boleh meningkatkan skor purata model asas zephyr-7b-sft-full secara berkesan dalam kedudukan LLM Terbuka HuggingFace dari 58.14 hingga 63.16, antaranya ia boleh mencapai keputusan yang lebih baik pada GSM8k dan TruthfulQA Peningkatan yang menakjubkan lebih daripada 10%, ia juga boleh ditingkatkan daripada 5.94 kepada 6.78 pada MT-Bench. .
Kesimpulan
Dengan menggunakan sepenuhnya data anotasi manusia, SPIN membenarkan model besar berubah daripada lemah kepada kuat melalui permainan sendiri. Berbanding dengan pembelajaran pengukuhan berdasarkan maklum balas keutamaan manusia (RLHF), SPIN membolehkan LLM memperbaiki diri tanpa maklum balas manusia tambahan atau maklum balas LLM yang lebih kukuh. Dalam percubaan pada berbilang set data penanda aras termasuk papan pendahulu LLM Terbuka HuggingFace, SPIN meningkatkan prestasi LLM dengan ketara dan stabil, malah model berprestasi tinggi yang dilatih dengan maklum balas AI tambahan.
Kami menjangkakan SPIN boleh membantu evolusi dan penambahbaikan model besar, dan akhirnya mencapai kecerdasan buatan melebihi tahap manusia.
Atas ialah kandungan terperinci LLM belajar untuk melawan satu sama lain, dan model asas mungkin membawa kepada inovasi kumpulan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!