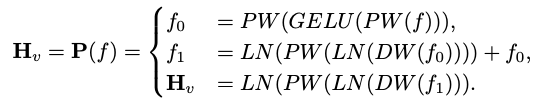Gelombang model besar yang datang ke terminal mudah alih semakin kuat dan semakin kuat, dan akhirnya seseorang telah memindahkan model besar berbilang mod ke terminal mudah alih. Baru-baru ini, Meituan, Universiti Zhejiang, dsb. telah melancarkan model besar berbilang modal yang boleh digunakan pada terminal mudah alih, termasuk keseluruhan proses latihan asas LLM, SFT dan VLM. Mungkin dalam masa terdekat, semua orang akan dapat memiliki model besar mereka sendiri dengan mudah, cepat dan pada kos yang rendah.
MobileVLM ialah pembantu bahasa visual yang pantas, berkuasa dan terbuka yang direka untuk peranti mudah alih. Ia menggabungkan reka bentuk seni bina dan teknologi untuk peranti mudah alih, termasuk model bahasa parameter 1.4B dan 2.7B yang dilatih dari awal, model penglihatan berbilang modal yang telah dilatih secara CLIP, dan interaksi silang mod yang cekap melalui unjuran. Prestasi MobileVLM adalah setanding dengan model besar pada pelbagai penanda aras bahasa visual. Selain itu, ia menunjukkan kelajuan inferens terpantas pada CPU Qualcomm Snapdragon 888 dan GPU NVIDIA Jeston Orin. 
- Alamat kertas: https://arxiv.org/pdf/2312.16886.pdf
- Alamat kod: https://github.com/Meituan-AutoML/MobileVLM
Model multimodal berskala besar (LMM), terutamanya keluarga model bahasa visual (VLM), telah menjadi hala tuju penyelidikan yang menjanjikan untuk membina pembantu sejagat kerana keupayaan mereka yang sangat dipertingkatkan dalam persepsi dan penaakulan. Walau bagaimanapun, cara untuk menyambung perwakilan model bahasa besar (LLM) yang telah terlatih dan model visual, mengekstrak ciri rentas modal dan menyelesaikan tugasan seperti menjawab soalan visual, sari kata imej, penaakulan pengetahuan visual dan dialog sentiasa menjadi masalah. .
Prestasi cemerlang GPT-4V dan Gemini dalam tugasan ini telah terbukti berkali-kali. Walau bagaimanapun, butiran pelaksanaan teknikal model proprietari ini masih kurang difahami. Pada masa yang sama, komuniti penyelidik juga telah mencadangkan beberapa siri kaedah laras bahasa. Contohnya, Flamingo memanfaatkan token visual untuk mengkondisikan model bahasa beku melalui lapisan perhatian silang berpagar. BLIP-2 menganggap interaksi ini tidak mencukupi dan memperkenalkan pengubah pertanyaan ringan (dipanggil Q-Former) yang mengekstrak ciri paling berguna daripada pengekod visual beku dan menyuapnya terus ke dalam LLM beku. MiniGPT-4 menggandingkan pengekod visual beku daripada BLIP-2 dengan model bahasa beku Vicuna melalui lapisan unjuran. Selain itu, LLaVA menggunakan rangkaian pemetaan mudah dilatih untuk menukar ciri visual kepada token pembenaman dengan dimensi yang sama seperti pembenaman perkataan untuk diproses oleh model bahasa.
Perlu diingat bahawa strategi latihan berubah secara beransur-ansur untuk menyesuaikan diri dengan kepelbagaian data berbilang modal berskala besar. LLaVA mungkin percubaan pertama untuk meniru paradigma penalaan arahan LLM kepada senario pelbagai mod. Untuk menjana data surih arahan berbilang mod, LLaVA memasukkan maklumat teks, seperti ayat huraian imej dan koordinat kotak sempadan imej, kepada model bahasa tulen GPT-4. MiniGPT-4 mula-mula dilatih pada set data komprehensif bagi ayat penerangan imej dan kemudian diperhalusi pada set data penentukuran pasangan [teks imej]. InstructBLIP melaksanakan penalaan arahan bahasa visual berdasarkan model BLIP-2 yang telah dilatih dan Q-Former dilatih pada pelbagai set data yang diatur dalam format yang ditala arahan. mPLUG-Owl memperkenalkan strategi latihan dua peringkat: pertama pra-latih bahagian visual, dan kemudian gunakan LoRA untuk memperhalusi model bahasa besar LLaMA berdasarkan data arahan daripada sumber yang berbeza.
Walaupun kemajuan VLM yang dinyatakan di atas, terdapat juga keperluan untuk menggunakan fungsi rentas modal di bawah sumber pengkomputeran yang terhad. Gemini mengatasi sota pada julat penanda aras berbilang modal dan memperkenalkan VLM gred mudah alih dengan parameter 1.8B dan 3.25B untuk peranti memori rendah. Dan Gemini juga menggunakan teknik mampatan biasa seperti penyulingan dan kuantisasi. Matlamat kertas kerja ini adalah untuk membina VLM terbuka, gred mudah alih yang pertama, dilatih menggunakan set data awam dan teknologi yang tersedia untuk persepsi dan penaakulan visual, dan disesuaikan untuk platform terhad sumber. Sumbangan artikel ini adalah seperti berikut:
- Artikel ini mencadangkan MobileVLM, yang merupakan transformasi tindanan penuh model bahasa visual berbilang mod yang disesuaikan untuk senario mudah alih. Menurut pengarang, ini adalah model bahasa visual pertama yang menyampaikan prestasi terperinci, boleh dihasilkan semula dan berkuasa dari awal. Melalui set data sumber terkawal dan terbuka, penyelidik telah mewujudkan satu set model bahasa asas berprestasi tinggi dan model berbilang modal.
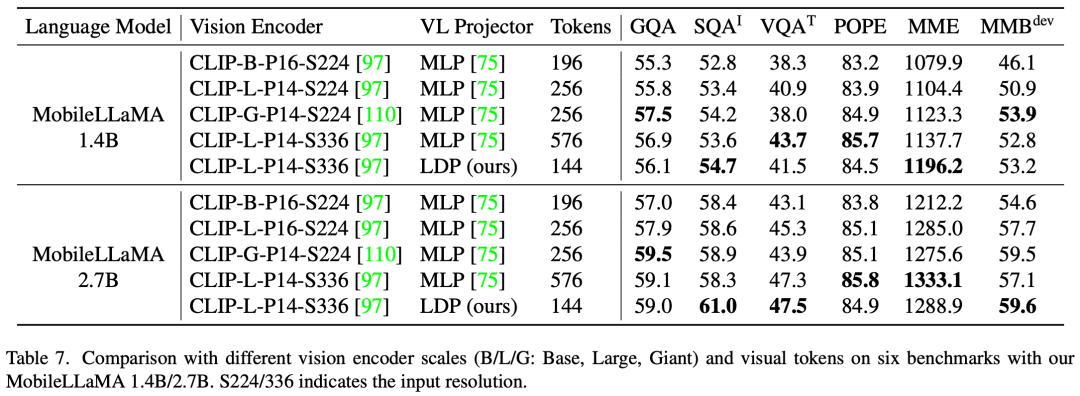
- Makalah ini menjalankan eksperimen ablasi yang meluas mengenai reka bentuk pengekod visual dan menilai secara sistematik kepekaan prestasi VLM kepada pelbagai paradigma latihan, resolusi input dan saiz model.
- Artikel ini mereka bentuk rangkaian pemetaan yang cekap antara ciri visual dan ciri teks, yang boleh menjajarkan ciri berbilang modal dengan lebih baik sambil mengurangkan penggunaan penaakulan.
- Model yang direka dalam artikel ini boleh berjalan dengan cekap pada peranti mudah alih berkuasa rendah, dengan kelajuan terukur 21.5 token/s pada CPU mudah alih Qualcomm dan pemproses 65.5 inci.
- MobileVLM dan sebilangan besar model besar berbilang modal berprestasi sama baik pada penanda aras, membuktikan potensi aplikasinya dalam banyak tugas praktikal. Walaupun artikel ini memfokuskan pada senario kelebihan, MobileVLM mengatasi banyak VLM tercanggih yang hanya boleh disokong oleh GPU berkuasa dalam awan. Reka bentuk seni bina keseluruhan LMoBilevlmo
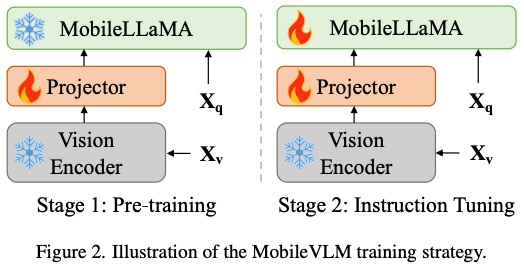
Memandangkan matlamat utama untuk mencapai persepsi visual yang cekap dan penaakulan untuk peralatan marginal dengan sumber terhad, penyelidik telah mereka Mobilevlm Seni bina keseluruhan, seperti yang ditunjukkan dalam Rajah 1, model ini mengandungi tiga komponen: 1 ) pengekod visual, 2) peranti tepi LLM tersuai (MobileLLaMA), dan 3) rangkaian pemetaan yang cekap (dirujuk dalam kertas sebagai "pemetaan pensampelan rendah ringan" ”, LDP) untuk menjajarkan ruang visual dan teks. Ambil imej sebagai input, dan pengekod visual F_enc mengekstrak pembenaman visual daripadanya untuk persepsi imej, di mana N_v = HW/P^2 mewakili bilangan tampalan imej dan D_v mewakili saiz lapisan tersembunyi bagi pembenaman visual. Untuk mengurangkan masalah kecekapan memproses token imej, para penyelidik mereka bentuk rangkaian pemetaan ringan P untuk pemampatan ciri visual dan penjajaran modal teks visual. Ia mengubah f menjadi ruang pembenaman perkataan dan menyediakan dimensi input yang sesuai untuk model bahasa berikutnya, seperti berikut:
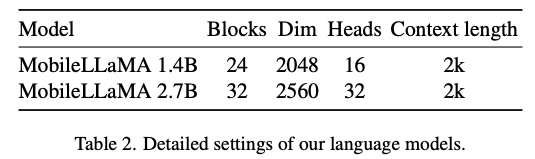
Dengan cara ini, kita mendapat token imej dan token teks, di mana N_t mewakili teks Bilangan token, D_t mewakili saiz ruang benam perkataan. Dalam paradigma reka bentuk MLLM semasa, LLM mempunyai jumlah pengiraan dan penggunaan memori yang paling besar Memandangkan perkara ini, artikel ini menyesuaikan satu siri LLM mesra inferens untuk aplikasi mudah alih, yang mempunyai banyak kelebihan dalam kelajuan dan boleh melakukan kaedah autoregresif input berbilang modal , dengan L mewakili panjang token output. Proses ini boleh dinyatakan sebagai . Menurut analisis empirikal dalam Bahagian 5.1 artikel asal, penyelidik menggunakan resolusi pra-latihan 3x3L/CLIP 3x3 pengekod visual F_enc . Pengubah Visual (ViT) membahagikan imej kepada blok imej bersaiz seragam dan melakukan pembenaman linear pada setiap blok imej. Selepas penyepaduan seterusnya dengan pengekodan kedudukan, jujukan vektor yang terhasil dimasukkan ke dalam pengekod transformasi biasa. Biasanya, token yang digunakan untuk pengelasan akan ditambahkan pada urutan untuk tugas pengelasan berikutnya. Untuk model bahasa, artikel ini mengurangkan saiz LLaMA untuk memudahkan penggunaan, iaitu model yang dicadangkan dalam artikel ini boleh menyokong hampir semua rangka kerja inferens popular dengan lancar. Di samping itu, penyelidik juga menilai kependaman model pada peranti tepi untuk memilih seni bina model yang sesuai. Carian Seni Bina Neural (NAS) ialah pilihan yang baik, tetapi pada masa ini penyelidik tidak segera menggunakannya pada model semasa. Jadual 2 menunjukkan tetapan terperinci seni bina kertas ini. Secara khusus, artikel ini menggunakan tokenizer potongan ayat dalam LLaMA2 dengan saiz perbendaharaan kata 32000 dan melatih lapisan embedding dari awal. Ini akan memudahkan penyulingan seterusnya. Disebabkan oleh sumber yang terhad, panjang konteks yang digunakan oleh semua model dalam peringkat pra-latihan ialah 2k. Walau bagaimanapun, seperti yang diterangkan dalam "Memperluas tetingkap konteks model bahasa besar melalui interpolasi kedudukan", tetingkap konteks semasa inferens boleh dilanjutkan lagi kepada 8k. Tetapan terperinci untuk komponen lain adalah seperti berikut.
- Sapukan RoPE untuk menyuntik maklumat lokasi.
- Gunakan pra-penormalan untuk menstabilkan latihan. Secara khusus, kertas ini menggunakan RMSNorm dan bukannya normalisasi lapisan, dan nisbah pengembangan MLP menggunakan 8/3 dan bukannya 4.
- Gunakan fungsi pengaktifan SwiGLU dan bukannya GELU.
Rangkaian pemetaan yang cekapRangkaian pemetaan antara pengekod visual dan model bahasa adalah penting untuk menjajarkan ciri berbilang modal. Terdapat dua mod sedia ada: Q-Former dan unjuran MLP. Q-Former secara eksplisit mengawal bilangan token visual yang disertakan dalam setiap pertanyaan untuk memaksa pengekstrakan maklumat visual yang paling berkaitan. Walau bagaimanapun, kaedah ini tidak dapat dielakkan kehilangan maklumat lokasi spatial token dan mempunyai kelajuan penumpuan yang perlahan. Selain itu, ia tidak cekap untuk inferens pada peranti tepi. Sebaliknya, MLP mengekalkan maklumat spatial tetapi selalunya mengandungi token yang tidak berguna seperti latar belakang. Untuk imej dengan saiz tampung P, N_v = HW/P^2 token visual perlu disuntik ke dalam LLM, yang sangat mengurangkan kelajuan inferens keseluruhan. Diilhamkan oleh algoritma pengekodan kedudukan bersyarat ViT CPVT, penyelidik menggunakan konvolusi untuk meningkatkan maklumat kedudukan dan menggalakkan interaksi tempatan pengekod visual. Secara khusus, kami menyiasat operasi mesra mudah alih berdasarkan lilitan mendalam (bentuk PEG yang paling mudah) yang cekap dan disokong dengan baik oleh pelbagai peranti tepi. Untuk mengekalkan maklumat spatial dan meminimumkan kos pengiraan, artikel ini menggunakan konvolusi dengan langkah 2, dengan itu mengurangkan bilangan token visual sebanyak 75%. Reka bentuk ini sangat meningkatkan kelajuan inferens keseluruhan. Walau bagaimanapun, keputusan percubaan menunjukkan bahawa mengurangkan bilangan sampel token akan mengurangkan prestasi tugas hiliran seperti OCR secara serius. Untuk mengurangkan kesan ini, para penyelidik mereka bentuk rangkaian yang lebih berkuasa untuk menggantikan satu PEG. Seni bina terperinci rangkaian pemetaan yang cekap, dipanggil Lightweight Downsampling Mapping (LDP), ditunjukkan dalam Rajah 2. Terutamanya, rangkaian pemetaan ini mengandungi kurang daripada 20 juta parameter dan berjalan kira-kira 81 kali lebih pantas daripada pengekod visual.
Artikel ini menggunakan "Layer Normalization" dan bukannya "Batch Normalization" supaya latihan tidak terjejas oleh saiz kelompok. Secara rasmi, LDP (ditandakan sebagai P) mengambil sebagai input pembenaman visual dan mengeluarkan token visual yang diekstrak dan diselaraskan dengan cekap . Formulanya adalah seperti berikut:
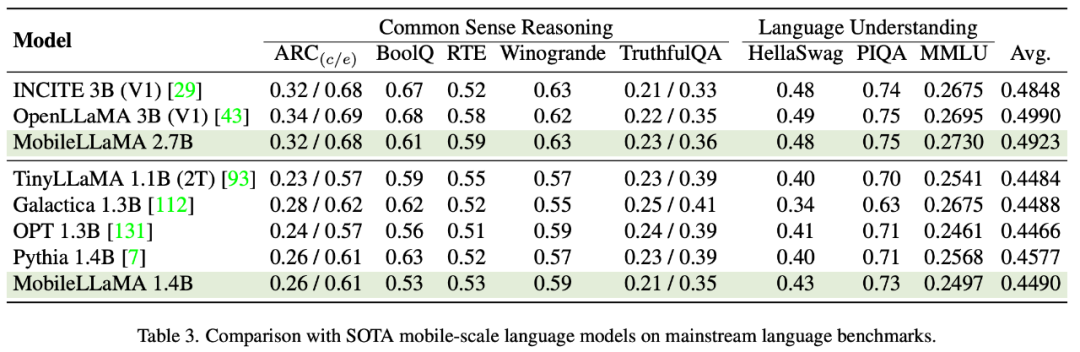
Hasil penilaian MobileLLaMA ers Artikel ini telah disemak pada penanda aras bahasa semula jadi Model yang dicadangkan telah dinilai secara meluas pada dua penanda aras yang menyasarkan pemahaman bahasa dan penaakulan akal. Dalam penilaian yang terdahulu, artikel ini menggunakan Abah-abah Penilaian Model Bahasa. Keputusan eksperimen menunjukkan bahawa MobileLLaMA 1.4B adalah setanding dengan model sumber terbuka terkini seperti TinyLLaMA 1.1B, Galactica 1.3B, OPT 1.3B dan Pythia 1.4B. Perlu diingat bahawa MobileLLaMA 1.4B mengatasi prestasi TinyLLaMA 1.1B, yang dilatih pada token tahap 2T dan dua kali lebih pantas berbanding MobileLLaMA 1.4B. Pada tahap 3B, MobileLLaMA 2.7B juga menunjukkan prestasi yang setanding dengan INCITE 3B (V1) dan OpenLLaMA 3B (V1), seperti yang ditunjukkan dalam Jadual 5. Pada CPU Snapdragon 888, MobileLLaMA 2.7B adalah kira-kira 40% lebih pantas daripada OpenLLaMA 3B. . Selain itu, kertas kerja ini juga menjalankan perbandingan secara menyeluruh menggunakan MMBench. Seperti yang ditunjukkan dalam Jadual 4, MobileVLM mencapai prestasi kompetitif walaupun parameter dikurangkan dan data latihan terhad. Dalam sesetengah kes, metriknya malah mengatasi model bahasa visual pelbagai mod terkini yang terkini.
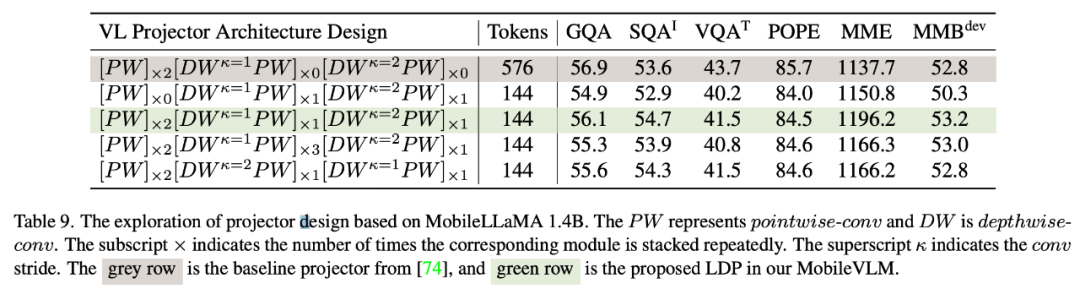
Penyesuaian Peringkat Rendah (LoRA) boleh mencapai prestasi yang sama atau lebih baik daripada LLM yang diperhalusi sepenuhnya dengan parameter boleh dilatih yang lebih sedikit. Kertas kerja ini menjalankan kajian empirikal amalan ini untuk mengesahkan prestasi multimodalnya. Khususnya, semasa fasa pelarasan arahan visual VLM, kertas ini membekukan semua parameter LLM kecuali matriks LoRA. Dalam MobileLLaMA 1.4B dan MobileLLaMA 2.7B, parameter yang dikemas kini hanya 8.87% dan 7.41% daripada LLM penuh. Untuk LoRA, artikel ini menetapkan lora_r kepada 128 dan lora_α kepada 256. Keputusan ditunjukkan dalam Jadual 4. Dapat dilihat bahawa pada 6 penanda aras, MobileVLM dengan LoRA mencapai prestasi yang setanding dengan penalaan halus penuh, yang konsisten dengan keputusan LoRA. Ujian kependaman pada peranti mudah alihPara penyelidik menilai kependaman inferens MobileLLaMA dan MobileVLM pada telefon bimbit Realme GT dan platform NVIDIA Jetson.AGX Telefon ini dikuasakan oleh Snapdragon 888 SoC dan 8GB RAM, yang memberikan 26 TOPS kuasa pengkomputeran. Orin dilengkapi dengan memori 32GB dan memberikan 275 TOPS kuasa pengkomputeran yang menakjubkan. Ia menggunakan CUDA versi 11.4 dan menyokong teknologi pengkomputeran selari terkini untuk prestasi yang lebih baik. . Semua eksperimen menggunakan CLIP ViT sebagai pengekod visual. Memandangkan kedua-dua interaksi ciri dan interaksi token bermanfaat, penyelidik menggunakan konvolusi kedalaman untuk konvolusi yang pertama dan titik untuk yang kedua. Jadual 9 menunjukkan prestasi pelbagai rangkaian dipetakan VL. Baris 1 dalam Jadual 9 ialah modul yang digunakan dalam LLaVA, yang hanya mengubah ruang ciri melalui dua lapisan linear. Baris 2 menambah lilitan DW (mendalam) sebelum setiap PW (mengikut arah) untuk interaksi token, yang menggunakan pensampelan turun 2x dengan langkah 2. Menambah dua lapisan PW bahagian hadapan akan membawa lebih banyak interaksi peringkat ciri, sekali gus menebus kehilangan prestasi yang disebabkan oleh pengurangan token. Baris 4 dan 5 menunjukkan bahawa menambah lebih banyak parameter tidak mencapai kesan yang diingini. Baris 4 dan 6 menunjukkan token pensampelan rendah pada akhir rangkaian pemetaan mempunyai kesan positif. . ) dan menggunakan Lightweight Downsampling Projector (LDP). Analisis kuantitatif SFT
Vicuna yang ditala halus pada LLaMA digunakan secara meluas untuk model berbilang modal yang besar. Jadual 10 membandingkan dua paradigma SFT biasa, Alpaca dan Vicuna. Para penyelidik mendapati bahawa markah SQA, VQA, MME dan MMBench semuanya meningkat dengan ketara. Ini menunjukkan bahawa penalaan halus model bahasa besar menggunakan data daripada ShareGPT dalam mod perbualan Vicuna akhirnya menghasilkan prestasi terbaik. Untuk menyepadukan format segera SFT dengan lebih baik dengan latihan tugasan hiliran, kertas kerja ini mengalih keluar mod perbualan pada MobileVLM dan mendapati bahawa vicunav1 berprestasi terbaik.
Kesimpulan
Ringkasnya, MobileVLM ialah satu set model bahasa visual mudah alih yang cekap dan berkuasa tinggi yang disesuaikan untuk peranti mudah alih dan IoT. Kertas ini menetapkan semula model bahasa dan rangkaian pemetaan visual. Para penyelidik menjalankan eksperimen yang meluas untuk memilih rangkaian tulang belakang visual yang sesuai, mereka bentuk rangkaian pemetaan yang cekap, dan meningkatkan keupayaan model melalui penyelesaian latihan seperti model bahasa SFT (strategi latihan dua peringkat termasuk pra-latihan dan pelarasan arahan) dan LoRA halus- penalaan. Penyelidik menilai dengan teliti prestasi MobileVLM pada penanda aras VLM arus perdana. MobileVLM juga menunjukkan kelajuan yang tidak pernah berlaku sebelum ini pada peranti mudah alih dan IoT biasa. Para penyelidik percaya bahawa MobileVLM akan membuka kemungkinan baharu untuk pelbagai aplikasi seperti pembantu pelbagai mod yang digunakan pada peranti mudah alih atau kenderaan autonomi, serta robot kecerdasan buatan yang lebih luas. Atas ialah kandungan terperinci Meituan, Universiti Zhejiang dan lain-lain bekerjasama untuk mencipta model besar MobileVLM pelbagai mod mudah alih proses penuh, yang boleh berjalan dalam masa nyata dan menggunakan pemproses Snapdragon 888. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



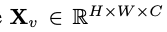 sebagai input, dan pengekod visual F_enc mengekstrak pembenaman visual
sebagai input, dan pengekod visual F_enc mengekstrak pembenaman visual 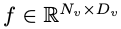 daripadanya untuk persepsi imej, di mana N_v = HW/P^2 mewakili bilangan tampalan imej dan D_v mewakili saiz lapisan tersembunyi bagi pembenaman visual. Untuk mengurangkan masalah kecekapan memproses token imej, para penyelidik mereka bentuk rangkaian pemetaan ringan P untuk pemampatan ciri visual dan penjajaran modal teks visual. Ia mengubah f menjadi ruang pembenaman perkataan dan menyediakan dimensi input yang sesuai untuk model bahasa berikutnya, seperti berikut:
daripadanya untuk persepsi imej, di mana N_v = HW/P^2 mewakili bilangan tampalan imej dan D_v mewakili saiz lapisan tersembunyi bagi pembenaman visual. Untuk mengurangkan masalah kecekapan memproses token imej, para penyelidik mereka bentuk rangkaian pemetaan ringan P untuk pemampatan ciri visual dan penjajaran modal teks visual. Ia mengubah f menjadi ruang pembenaman perkataan dan menyediakan dimensi input yang sesuai untuk model bahasa berikutnya, seperti berikut: 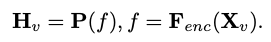
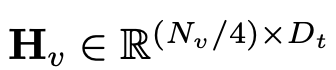 dan token teks
dan token teks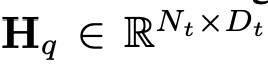 , di mana N_t mewakili teks Bilangan token, D_t mewakili saiz ruang benam perkataan. Dalam paradigma reka bentuk MLLM semasa, LLM mempunyai jumlah pengiraan dan penggunaan memori yang paling besar Memandangkan perkara ini, artikel ini menyesuaikan satu siri LLM mesra inferens untuk aplikasi mudah alih, yang mempunyai banyak kelebihan dalam kelajuan dan boleh melakukan kaedah autoregresif input berbilang modal
, di mana N_t mewakili teks Bilangan token, D_t mewakili saiz ruang benam perkataan. Dalam paradigma reka bentuk MLLM semasa, LLM mempunyai jumlah pengiraan dan penggunaan memori yang paling besar Memandangkan perkara ini, artikel ini menyesuaikan satu siri LLM mesra inferens untuk aplikasi mudah alih, yang mempunyai banyak kelebihan dalam kelajuan dan boleh melakukan kaedah autoregresif input berbilang modal 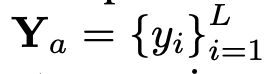 , dengan L mewakili panjang token output. Proses ini boleh dinyatakan sebagai
, dengan L mewakili panjang token output. Proses ini boleh dinyatakan sebagai 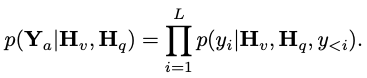 .
. 
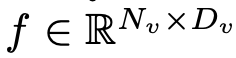 dan mengeluarkan token visual yang diekstrak dan diselaraskan dengan cekap
dan mengeluarkan token visual yang diekstrak dan diselaraskan dengan cekap 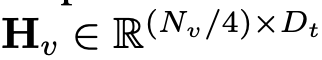 .
.