
Rumah >Peranti teknologi >AI >Sepuluh penunjuk prestasi model pembelajaran mesin
Sepuluh penunjuk prestasi model pembelajaran mesin

- PHPzke hadapan
- 2024-01-08 08:25:281310semak imbas
Walaupun model besar sangat berkuasa, menyelesaikan masalah praktikal tidak semestinya bergantung sepenuhnya pada model besar. Analogi yang kurang tepat untuk menerangkan fenomena fizikal secara realiti tanpa perlu menggunakan mekanik kuantum. Untuk beberapa masalah yang agak mudah, mungkin taburan statistik sudah memadai. Untuk pembelajaran mesin, pembelajaran mendalam dan rangkaian saraf diperlukan untuk menjelaskan sempadan masalah.
Jadi bagaimana untuk menilai prestasi model pembelajaran mesin apabila menggunakan ML untuk menyelesaikan masalah yang agak mudah? Berikut ialah 10 penunjuk penilaian yang agak biasa digunakan, berharap dapat membantu pelajar industri dan penyelidikan.
1. Ketepatan
Ketepatan ialah indeks penilaian asas dalam bidang pembelajaran mesin dan biasanya digunakan untuk memahami prestasi model dengan cepat. Ketepatan menyediakan cara intuitif untuk mengukur ketepatan model dengan hanya mengira nisbah bilangan kejadian yang diramalkan dengan betul oleh model kepada jumlah bilangan kejadian dalam set data.
 Gambar
Gambar
Walau bagaimanapun, ketepatan, sebagai metrik penilaian, mungkin tidak mencukupi apabila berurusan dengan set data yang tidak seimbang. Set data tidak seimbang merujuk kepada set data di mana bilangan kejadian bagi kategori tertentu dengan ketara melebihi kategori lain. Dalam kes ini, model mungkin cenderung untuk meramalkan bilangan kategori yang lebih besar, menghasilkan ketepatan tinggi palsu.
Selain itu, ketepatan tidak boleh memberikan maklumat tentang positif palsu dan negatif palsu. Positif palsu ialah apabila model tersilap meramalkan contoh negatif sebagai contoh positif, manakala negatif palsu ialah apabila model tersalah meramalkan contoh positif sebagai contoh negatif. Semasa menilai prestasi model, adalah penting untuk membezakan antara positif palsu dan negatif palsu, kerana ia mempunyai kesan yang berbeza terhadap prestasi model.
Ringkasnya, walaupun ketepatan ialah metrik penilaian yang ringkas dan mudah difahami, apabila berurusan dengan set data yang tidak seimbang, kita perlu lebih berhati-hati dalam mentafsir keputusan ketepatan.
2. Ketepatan
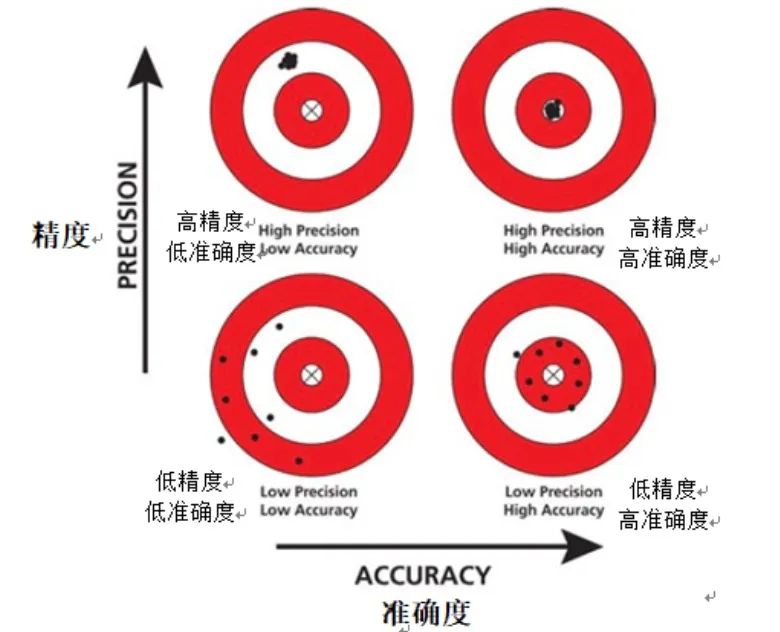
Ketepatan ialah indeks penilaian penting, yang memfokuskan pada mengukur ketepatan ramalan model untuk sampel positif. Tidak seperti ketepatan, ketepatan mengira perkadaran kejadian yang sebenarnya positif antara kejadian yang diramalkan oleh model sebagai positif. Dalam erti kata lain, ketepatan menjawab soalan: "Apabila model meramalkan suatu kejadian adalah positif, apakah kebarangkalian bahawa ramalan ini adalah tepat Model ketepatan tinggi bermakna apabila ia meramalkan suatu kejadian adalah positif, , kejadian ini?" berkemungkinan besar adalah sampel yang positif.
 Gambar
Gambar
Dalam sesetengah aplikasi, seperti diagnosis perubatan atau pengesanan penipuan, ketepatan model amat penting. Dalam senario ini, akibat positif palsu (iaitu meramalkan sampel negatif sebagai sampel positif secara salah) boleh menjadi sangat serius. Sebagai contoh, dalam diagnosis perubatan, diagnosis positif palsu boleh membawa kepada rawatan atau pemeriksaan yang tidak perlu, menyebabkan tekanan psikologi dan fizikal yang tidak perlu kepada pesakit. Dalam pengesanan penipuan, positif palsu boleh menyebabkan pengguna yang tidak bersalah dilabel secara salah sebagai pelaku penipuan, yang memberi kesan kepada pengalaman pengguna dan reputasi syarikat.
Oleh itu, dalam aplikasi ini, adalah penting untuk memastikan model mempunyai ketepatan yang tinggi. Hanya dengan mempertingkatkan ketepatan kita boleh mengurangkan risiko positif palsu dan dengan itu kesan negatif salah penilaian.
3. Kadar ingat semula
Kadar ingat semula ialah indeks penilaian yang penting, digunakan untuk mengukur keupayaan model untuk meramal dengan betul semua sampel positif sebenar. Secara khusus, ingat semula dikira sebagai nisbah kejadian yang diramalkan oleh model sebagai positif sebenar kepada jumlah bilangan contoh positif sebenar. Metrik ini menjawab soalan: "Berapa banyak contoh positif sebenar yang diramalkan oleh model dengan betul
Tidak seperti ketepatan, ingat kembali memfokuskan pada keupayaan model untuk mengingati contoh positif sebenar. Walaupun model mempunyai kebarangkalian ramalan yang rendah untuk sampel positif tertentu, selagi sampel itu sebenarnya adalah sampel positif dan diramalkan dengan betul sebagai sampel positif oleh model, maka ramalan ini akan dimasukkan dalam pengiraan kadar penarikan balik. . Oleh itu, ingatan lebih mementingkan sama ada model itu dapat mencari seberapa banyak sampel positif yang mungkin, bukan hanya mereka yang mempunyai kebarangkalian ramalan yang lebih tinggi.
 Gambar
Gambar
Dalam sesetengah senario aplikasi, kepentingan kadar panggil semula amat menonjol. Sebagai contoh, dalam pengesanan penyakit, jika model terlepas pesakit sebenar yang sakit, ia boleh menyebabkan kelewatan dan kemerosotan penyakit, dan membawa akibat yang serius kepada pesakit. Untuk contoh lain, dalam ramalan churn pelanggan, jika model tidak mengenal pasti pelanggan yang mungkin churn dengan betul, syarikat mungkin kehilangan peluang untuk mengambil langkah pengekalan, seterusnya kehilangan pelanggan penting.
Oleh itu, dalam senario ini, ingat kembali menjadi metrik yang penting. Model yang mempunyai daya ingat yang tinggi lebih berupaya mencari sampel positif sebenar, mengurangkan risiko peninggalan dan dengan itu mengelakkan kemungkinan akibat yang serius.
4. Skor F1
Skor F1 ialah indeks penilaian komprehensif yang bertujuan untuk mencari keseimbangan antara ketepatan dan ingatan semula. Ia sebenarnya adalah min harmonik bagi ketepatan dan ingat, menggabungkan kedua-dua metrik ini menjadi satu skor, sekali gus menyediakan cara penilaian yang mengambil kira kedua-dua positif palsu dan negatif palsu.
 Gambar
Gambar
Dalam banyak aplikasi praktikal, kita selalunya perlu membuat pertukaran antara ketepatan dan ingatan semula. Ketepatan memfokuskan pada ketepatan ramalan model, manakala ingat kembali memfokuskan pada sama ada model dapat mencari semua sampel positif sebenar. Walau bagaimanapun, terlalu menekankan satu metrik selalunya boleh menjejaskan prestasi yang lain. Sebagai contoh, untuk menambah baik ingat semula, model boleh meningkatkan ramalan untuk sampel positif, tetapi ini juga boleh meningkatkan bilangan positif palsu, sekali gus mengurangkan ketepatan.
Pemarkahan F1 direka untuk menyelesaikan masalah ini. Ia memerlukan ketepatan dan mengingat kembali, mengelakkan situasi di mana kita mengorbankan satu metrik demi mengoptimumkan yang lain. Dengan mengira min harmonik ketepatan dan ingat semula, skor F1 mencapai keseimbangan antara kedua-duanya, membolehkan kami menilai prestasi model tanpa memihak.
Jadi, skor F1 ialah alat yang sangat berguna apabila anda memerlukan metrik yang menggabungkan ketepatan dan ingatan semula, dan tidak mahu mengutamakan satu metrik berbanding yang lain. Ia menyediakan skor tunggal yang memudahkan proses menilai prestasi model dan membantu kami lebih memahami prestasi model dalam aplikasi dunia sebenar.
5. ROC-AUC
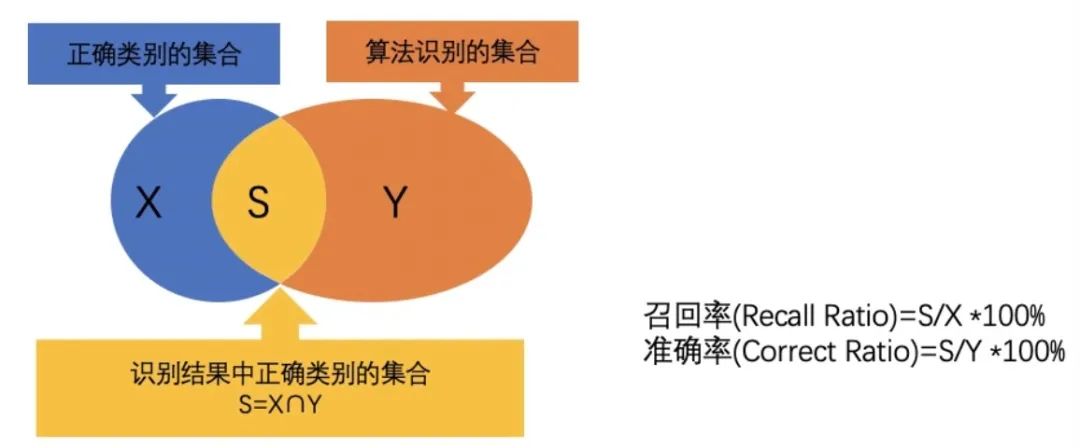
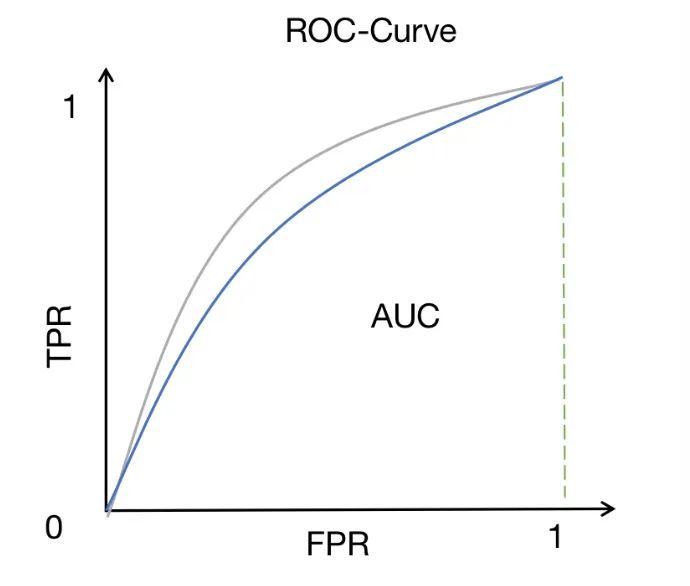
ROC-AUC ialah kaedah pengukuran prestasi yang digunakan secara meluas dalam masalah klasifikasi binari. Ia mengukur kawasan di bawah lengkung ROC, yang menggambarkan hubungan antara kadar positif sebenar (juga dipanggil sensitiviti atau ingat semula) dan kadar positif palsu pada ambang yang berbeza.
 Gambar
Gambar
Keluk ROC menyediakan cara intuitif untuk memerhati prestasi model di bawah pelbagai tetapan ambang. Dengan menukar ambang, kita boleh melaraskan kadar positif sebenar dan kadar positif palsu model untuk mendapatkan hasil pengelasan yang berbeza. Lebih dekat lengkung ROC ke sudut kiri atas, lebih baik prestasi model dalam membezakan sampel positif dan negatif.
AUC (kawasan di bawah lengkung) menyediakan penunjuk kuantitatif untuk menilai keupayaan diskriminasi model. Nilai AUC adalah antara 0 dan 1. Semakin hampir kepada 1, semakin kuat keupayaan diskriminasi model. Skor AUC yang tinggi bermakna model boleh membezakan antara sampel positif dan sampel negatif dengan baik, iaitu, kebarangkalian ramalan model untuk sampel positif adalah lebih tinggi daripada kebarangkalian ramalan untuk sampel negatif.
Oleh itu, ROC-AUC ialah metrik yang sangat berguna apabila kita ingin menilai keupayaan model untuk membezakan antara kelas. Berbanding dengan penunjuk lain, ROC-AUC mempunyai beberapa kelebihan unik. Ia tidak terjejas oleh pemilihan ambang dan boleh mempertimbangkan secara menyeluruh prestasi model di bawah pelbagai ambang. Di samping itu, ROC-AUC agak teguh kepada masalah ketidakseimbangan kelas dan masih boleh memberikan hasil penilaian yang bermakna walaupun bilangan sampel positif dan negatif tidak seimbang.
ROC-AUC adalah ukuran prestasi yang sangat berharga, terutamanya untuk masalah klasifikasi binari. Dengan memerhati dan membandingkan skor ROC-AUC model yang berbeza, kita boleh memperoleh pemahaman yang lebih komprehensif tentang prestasi model dan memilih model dengan keupayaan diskriminasi yang lebih baik.
6. PR-AUC
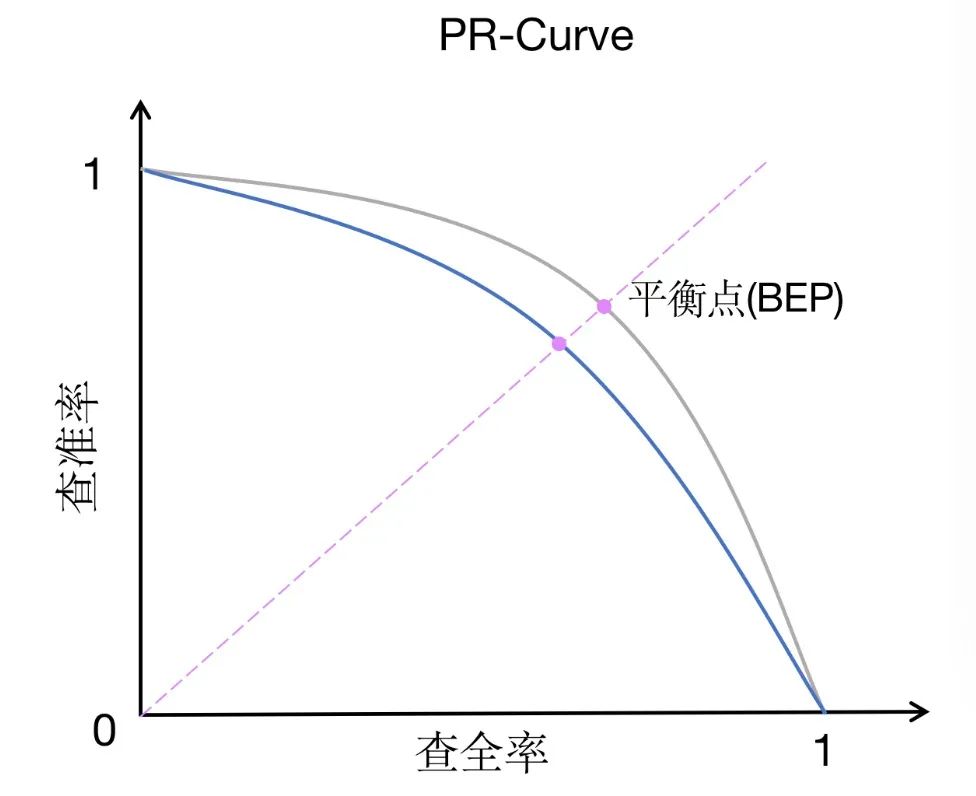
PR-AUC (kawasan di bawah keluk penarikan semula ketepatan) ialah kaedah pengukuran prestasi yang serupa dengan ROC-AUC, tetapi mempunyai fokus yang berbeza sedikit. PR-AUC mengukur kawasan di bawah keluk ingatan-kejituan, yang menggambarkan hubungan antara ketepatan dan penarikan balik pada ambang yang berbeza.
 Gambar
Gambar
Berbanding dengan ROC-AUC, PR-AUC memberi lebih perhatian kepada pertukaran antara ketepatan dan penarikan balik. Ketepatan mengukur perkadaran kejadian yang diramalkan oleh model sebagai positif yang sebenarnya positif, manakala ingat kembali mengukur perkadaran kejadian yang diramalkan dengan betul oleh model sebagai positif antara semua kejadian yang sebenarnya positif. Pertukaran antara ketepatan dan penarikan balik amat penting dalam set data yang tidak seimbang, atau apabila positif palsu lebih membimbangkan daripada negatif palsu.
Dalam set data yang tidak seimbang, bilangan sampel dalam satu kategori mungkin jauh melebihi bilangan sampel dalam kategori lain. Dalam kes ini, ROC-AUC mungkin tidak menggambarkan prestasi model dengan tepat kerana ia tertumpu terutamanya pada hubungan antara kadar positif sebenar dan kadar positif palsu tanpa mengambil kira ketidakseimbangan kelas secara langsung. Sebaliknya, PR-AUC menilai prestasi model secara lebih komprehensif melalui pertukaran antara ketepatan dan penarikan semula, dan boleh menggambarkan dengan lebih baik kesan model pada set data yang tidak seimbang.
Selain itu, PR-AUC juga merupakan metrik yang lebih sesuai apabila positif palsu lebih membimbangkan daripada negatif palsu. Kerana dalam sesetengah senario aplikasi, salah meramal sampel negatif sebagai sampel positif (positif palsu) boleh membawa kerugian atau kesan negatif yang lebih besar. Contohnya, dalam diagnosis perubatan, salah mendiagnosis orang yang sihat sebagai orang yang berpenyakit boleh menyebabkan rawatan dan kebimbangan yang tidak perlu. Dalam kes ini, kami lebih suka model mempunyai ketepatan yang tinggi untuk mengurangkan bilangan positif palsu.
Untuk meringkaskan, PR-AUC ialah kaedah pengukuran prestasi yang sesuai untuk set data atau senario yang tidak seimbang di mana positif palsu menjadi kebimbangan. Ia boleh membantu kami lebih memahami pertukaran antara ketepatan dan penarikan semula model dan memilih model yang sesuai untuk memenuhi keperluan sebenar.
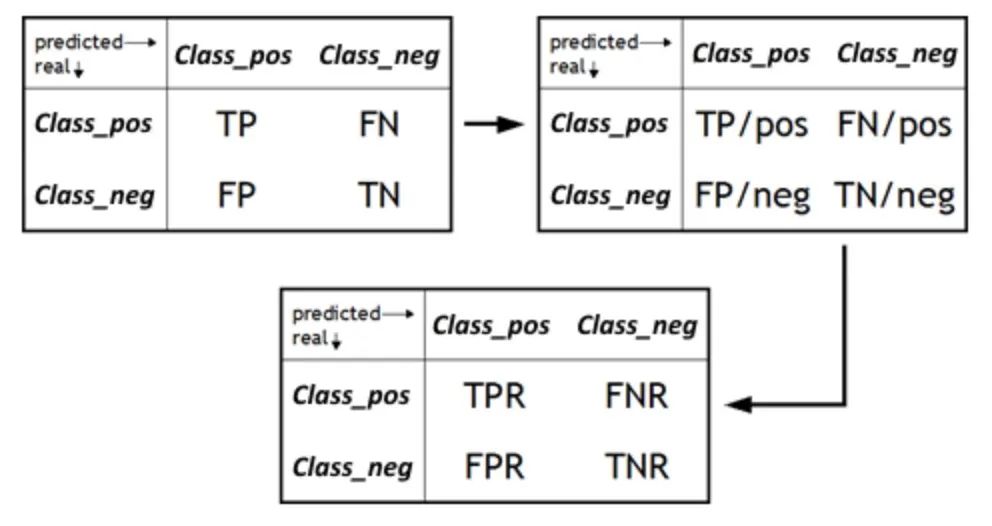
7. FPR/TNR
Kadar Positif Palsu (FPR) ialah metrik penting yang mengukur perkadaran sampel yang model salah ramalkan sebagai positif antara semua sampel negatif sebenar. Ia adalah penunjuk pelengkap kekhususan dan sepadan dengan kadar negatif sebenar (TNR). FPR menjadi elemen utama apabila kita ingin menilai keupayaan model untuk mengelakkan positif palsu. Positif palsu boleh menyebabkan kebimbangan yang tidak perlu atau sumber terbuang, jadi memahami FPR model adalah penting untuk menentukan kebolehpercayaannya dalam aplikasi dunia sebenar. Dengan menurunkan FPR, kami boleh meningkatkan ketepatan dan ketepatan model, memastikan ramalan positif hanya dikeluarkan apabila sampel positif benar-benar wujud.
 Gambar
Gambar
Sebaliknya, kadar negatif sebenar (TNR), juga dikenali sebagai kekhususan, ialah ukuran sejauh mana model mengenal pasti sampel negatif dengan betul. Ia mengira perkadaran kejadian yang diramalkan oleh model sebagai negatif sebenar kepada jumlah negatif sebenar. Apabila menilai model, kami sering menumpukan pada keupayaan model untuk mengenal pasti sampel positif, tetapi sama pentingnya ialah prestasi model dalam mengenal pasti sampel negatif. TNR yang tinggi bermakna model boleh mengenal pasti sampel negatif dengan tepat, iaitu, antara contoh yang sebenarnya adalah sampel negatif, model meramalkan nisbah sampel negatif yang lebih tinggi. Ini penting untuk mengelakkan positif palsu dan meningkatkan prestasi keseluruhan model.
8. Matthews Correlation Coefficient (MCC)
MCC (Matthews Correlation Coefficient) ialah ukuran yang digunakan dalam masalah klasifikasi binari. Ia memberikan kita pertimbangan menyeluruh tentang positif benar, negatif benar dan salah dinilai. Berbanding dengan kaedah pengukuran lain, kelebihan MCC ialah ia adalah nilai tunggal antara -1 hingga 1, di mana -1 bermakna ramalan model tidak konsisten sepenuhnya dengan keputusan sebenar dan 1 bermakna ramalan model adalah konsisten sepenuhnya. dengan hasil yang sebenarnya.
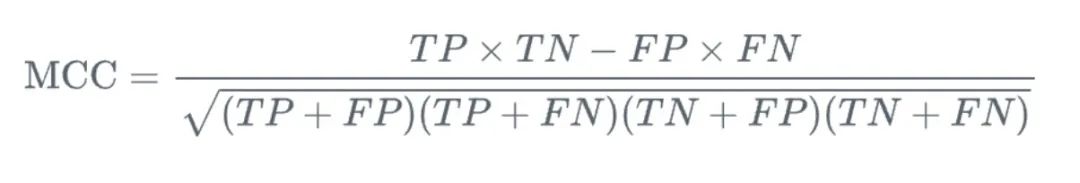 Gambar
Gambar
Lebih penting lagi, MCC menyediakan cara yang seimbang untuk mengukur kualiti pengelasan binari. Dalam masalah klasifikasi binari, kami biasanya menumpukan pada keupayaan model untuk mengenal pasti sampel positif dan negatif, manakala MCC mempertimbangkan kedua-dua aspek. Ia memfokuskan bukan sahaja pada keupayaan model untuk meramalkan sampel positif dengan betul (iaitu, positif benar), tetapi juga pada keupayaan model untuk meramalkan sampel negatif dengan betul (iaitu, negatif benar). Pada masa yang sama, MCC juga mengambil kira positif palsu dan negatif palsu untuk menilai prestasi model secara lebih komprehensif.
Dalam aplikasi praktikal, MCC amat sesuai untuk mengendalikan set data yang tidak seimbang. Oleh kerana dalam set data yang tidak seimbang, bilangan sampel dalam satu kategori adalah jauh lebih besar daripada kategori lain, ini sering menyebabkan model menjadi berat sebelah ke arah meramalkan kategori dengan bilangan yang lebih besar. Walau bagaimanapun, MCC dapat mempertimbangkan keempat-empat metrik (positif benar, negatif benar, positif palsu dan negatif palsu) dengan cara yang seimbang, jadi secara umumnya ia boleh memberikan penilaian prestasi yang lebih tepat dan komprehensif untuk set data yang tidak seimbang.
Secara keseluruhan, MCC ialah alat pengukuran prestasi yang berkuasa dan komprehensif untuk klasifikasi binari. Ia bukan sahaja mengambil kira semua keputusan ramalan yang mungkin, tetapi juga menyediakan nilai berangka yang intuitif dan jelas untuk mengukur ketekalan antara ramalan dan keputusan sebenar. Sama ada pada set data seimbang atau tidak seimbang, MCC ialah metrik berguna yang boleh membantu kami memahami prestasi model dengan lebih mendalam.
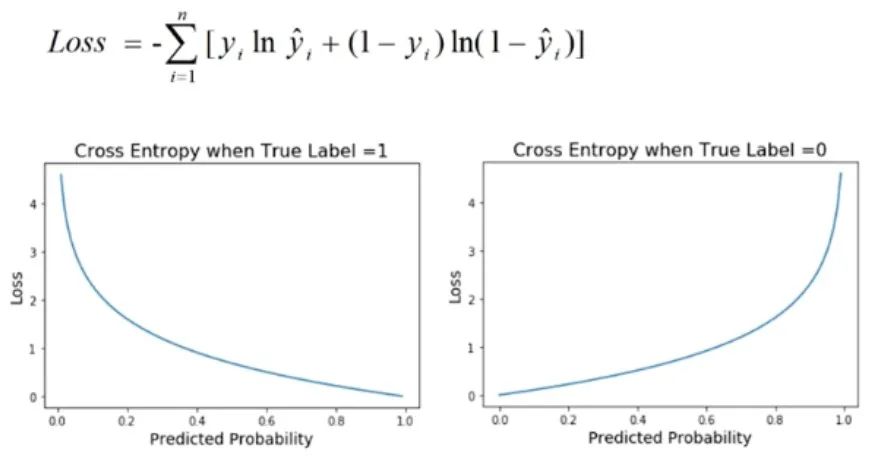
9. Kehilangan entropi silang
Kehilangan entropi silang ialah metrik prestasi yang biasa digunakan dalam masalah pengelasan, terutamanya apabila output model ialah nilai kebarangkalian. Fungsi kehilangan ini digunakan untuk mengukur perbezaan antara taburan kebarangkalian yang diramalkan oleh model dan taburan label sebenar.
 Gambar
Gambar
Dalam masalah pengelasan, matlamat model biasanya untuk meramalkan kebarangkalian sampel tergolong dalam kategori yang berbeza. Kehilangan entropi silang digunakan untuk menilai ketekalan antara model yang diramalkan kebarangkalian dan keputusan binari sebenar. Ia memperoleh nilai kerugian dengan mengambil logaritma kebarangkalian yang diramalkan dan membandingkannya dengan label sebenar. Oleh itu, kehilangan entropi silang juga dipanggil kehilangan logaritma.
Kelebihan kehilangan entropi silang ialah ia merupakan ukuran yang baik bagi ketepatan ramalan model untuk taburan kebarangkalian. Apabila taburan kebarangkalian yang diramalkan bagi model adalah serupa dengan taburan label sebenar, nilai kehilangan entropi silang adalah rendah, sebaliknya, apabila taburan kebarangkalian yang diramalkan adalah berbeza dengan ketara daripada taburan label sebenar, nilai kehilangan entropi silang adalah; tinggi. Oleh itu, nilai kehilangan entropi silang yang lebih rendah bermakna ramalan model adalah lebih tepat, iaitu model mempunyai prestasi penentukuran yang lebih baik.
Dalam aplikasi praktikal, kami biasanya mengejar nilai kehilangan silang entropi yang lebih rendah, kerana ini bermakna ramalan model untuk masalah pengelasan adalah lebih tepat dan boleh dipercayai. Dengan mengoptimumkan kehilangan entropi silang, kami boleh meningkatkan prestasi model dan menjadikannya mempunyai keupayaan generalisasi yang lebih baik dalam aplikasi praktikal. Oleh itu, kehilangan entropi silang adalah salah satu petunjuk penting untuk menilai prestasi model klasifikasi Ia boleh membantu kita memahami dengan lebih lanjut ketepatan ramalan model dan sama ada pengoptimuman selanjutnya bagi parameter dan struktur model itu diperlukan.
10. Pekali kappa Cohen
Pekali kappa Cohen ialah alat statistik yang digunakan untuk mengukur ketekalan antara ramalan model dan label sebenar. Berbanding dengan kaedah pengukuran lain, ia bukan sahaja mengira persetujuan mudah antara ramalan model dan label sebenar, tetapi juga membetulkan perjanjian yang mungkin berlaku secara kebetulan, sekali gus memberikan hasil penilaian yang lebih tepat dan boleh dipercayai.
Dalam aplikasi praktikal, terutamanya apabila berbilang penilai terlibat dalam mengklasifikasikan set sampel yang sama, pekali kappa Cohen sangat berguna. Dalam kes ini, kita bukan sahaja perlu menumpukan pada ketekalan ramalan model dengan label sebenar, tetapi juga perlu mempertimbangkan ketekalan antara penilai yang berbeza. Kerana jika terdapat ketidakkonsistenan yang ketara antara penilai, keputusan penilaian prestasi model mungkin dipengaruhi oleh subjektiviti penilai, mengakibatkan keputusan penilaian yang tidak tepat.
Dengan menggunakan pekali kappa Cohen, ketekalan yang mungkin berlaku secara kebetulan ini boleh diperbetulkan untuk penilaian prestasi model yang lebih tepat. Secara khusus, ia mengira nilai antara -1 dan 1, di mana 1 mewakili ketekalan sempurna, -1 mewakili ketidakkonsistenan lengkap, dan 0 mewakili ketekalan rawak. Oleh itu, nilai Kappa yang lebih tinggi bermakna persetujuan antara ramalan model dan label sebenar melebihi perjanjian yang dijangka secara kebetulan, yang menunjukkan bahawa model tersebut mempunyai prestasi yang lebih baik.
 Gambar
Gambar
Pekali kappa Cohen boleh membantu kami menilai dengan lebih tepat ketekalan antara ramalan model dan label sebenar dalam tugas pengelasan, sambil membetulkan ketekalan yang mungkin berlaku secara kebetulan. Ia amat penting dalam senario yang melibatkan berbilang penilai, kerana ia boleh memberikan penilaian yang lebih objektif dan tepat.
Ringkasan
Terdapat banyak penunjuk untuk penilaian model pembelajaran mesin Artikel ini memberikan beberapa petunjuk utama:
- Ketepatan (Ketepatan): perkadaran bilangan sampel yang diramalkan dengan betul kepada jumlah sampel.
- Ketepatan: Perkadaran sampel True Positive (TP) kepada semua sampel positif (TP dan FP) yang diramalkan, mencerminkan keupayaan model untuk mengenal pasti sampel positif.
- Ingat: perkadaran sampel True Positive (TP) kepada semua sampel positif benar (TP dan FN), mencerminkan keupayaan model untuk menemui sampel positif.
- Nilai F1: Purata harmonik ketepatan dan ingatan semula, dengan mengambil kira ketepatan dan penarikan balik.
- ROC-AUC: Kawasan di bawah keluk ROC Keluk ROC ialah fungsi kadar positif sebenar (Kadar Positif Benar, TPR) dan kadar positif palsu (Kadar Positif Palsu, FPR). Lebih besar AUC, lebih baik prestasi klasifikasi model.
- PR-AUC: Kawasan di bawah keluk ingatan-kejituan, yang memfokuskan pada pertukaran antara ketepatan dan penarikan balik dan lebih sesuai untuk set data yang tidak seimbang.
- FPR/TNR: FPR mengukur keupayaan model untuk melaporkan positif palsu, dan TNR mengukur keupayaan model untuk mengenal pasti sampel negatif dengan betul.
- Kehilangan entropi silang: digunakan untuk menilai perbezaan antara model yang diramalkan kebarangkalian dan label sebenar. Nilai yang lebih rendah menunjukkan penentukuran dan ketepatan model yang lebih baik.
- Pekali Korelasi Matthews (MCC): Metrik yang mengambil kira perhubungan antara positif benar, negatif benar, positif palsu dan negatif palsu, memberikan ukuran seimbang bagi kualiti pengelasan binari.
- Cohen's kappa: Alat penting untuk menilai prestasi model dalam tugas pengelasan dengan tepat boleh mengukur ketekalan antara ramalan dan label dan membetulkan untuk konsistensi yang tidak disengajakan, terutamanya dalam berbilang senario penilai.
Setiap penunjuk di atas mempunyai ciri-ciri tersendiri dan sesuai untuk senario masalah yang berbeza. Dalam aplikasi praktikal, beberapa penunjuk mungkin perlu digabungkan untuk menilai prestasi model secara menyeluruh.
Atas ialah kandungan terperinci Sepuluh penunjuk prestasi model pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!