
Rumah >Peranti teknologi >AI >Model besar berbilang modal sumber terbuka Megvii menyokong OCR peringkat dokumen, meliputi bahasa Cina dan Inggeris Adakah ia menandakan tamatnya OCR?
Model besar berbilang modal sumber terbuka Megvii menyokong OCR peringkat dokumen, meliputi bahasa Cina dan Inggeris Adakah ia menandakan tamatnya OCR?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-05 21:23:581191semak imbas
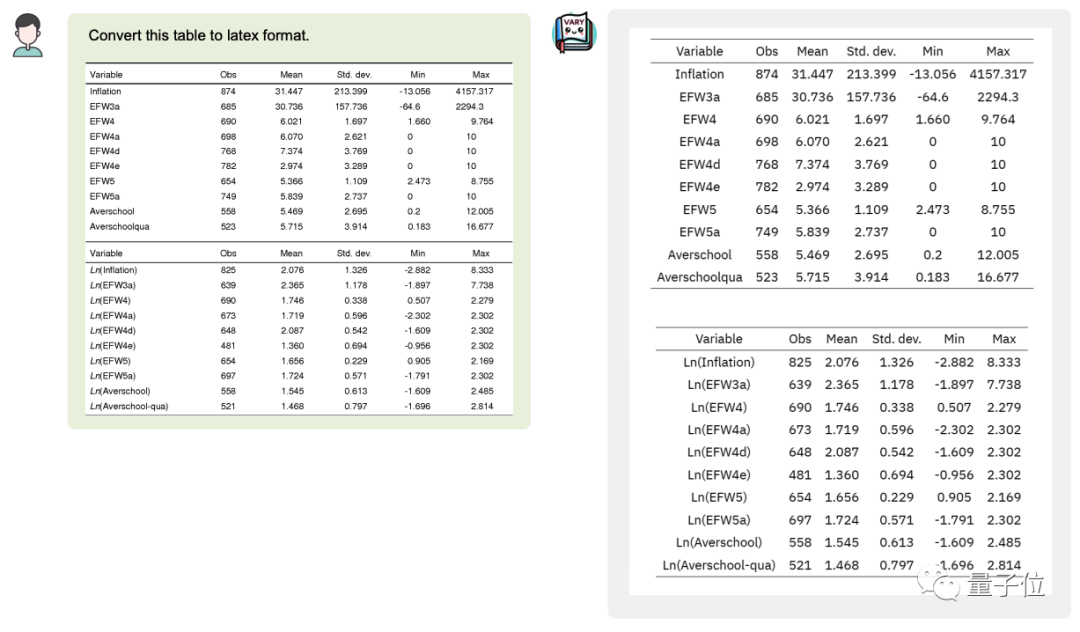
Ingin menukar imej dokumen kepada format Markdown?
Pada masa lalu, tugasan ini memerlukan beberapa langkah seperti pengecaman teks, pengesanan susun atur dan pengisihan, pemprosesan jadual formula, pembersihan teks, dll. -
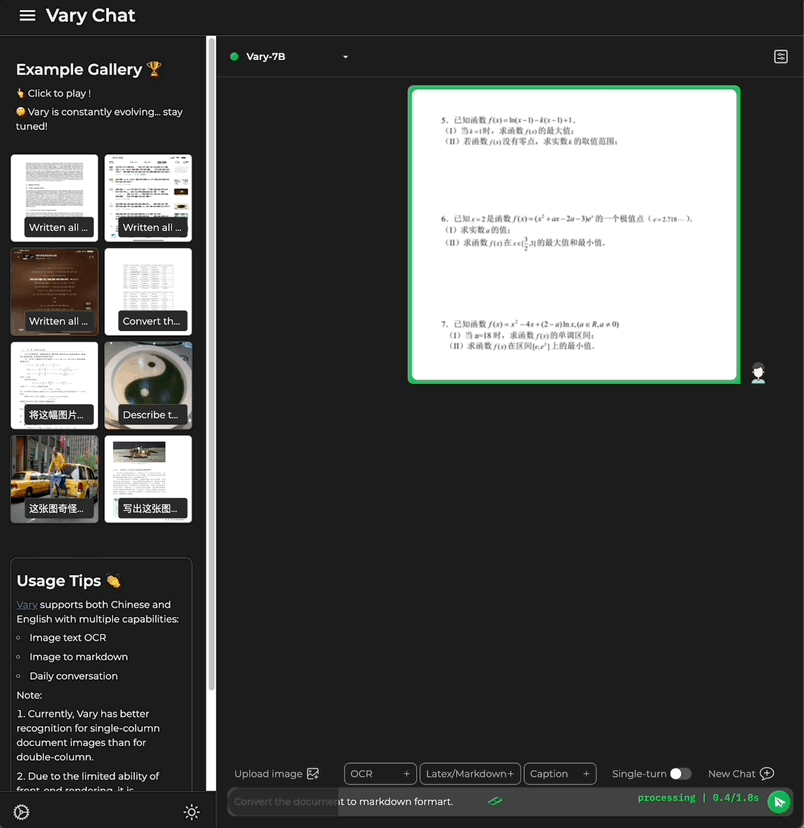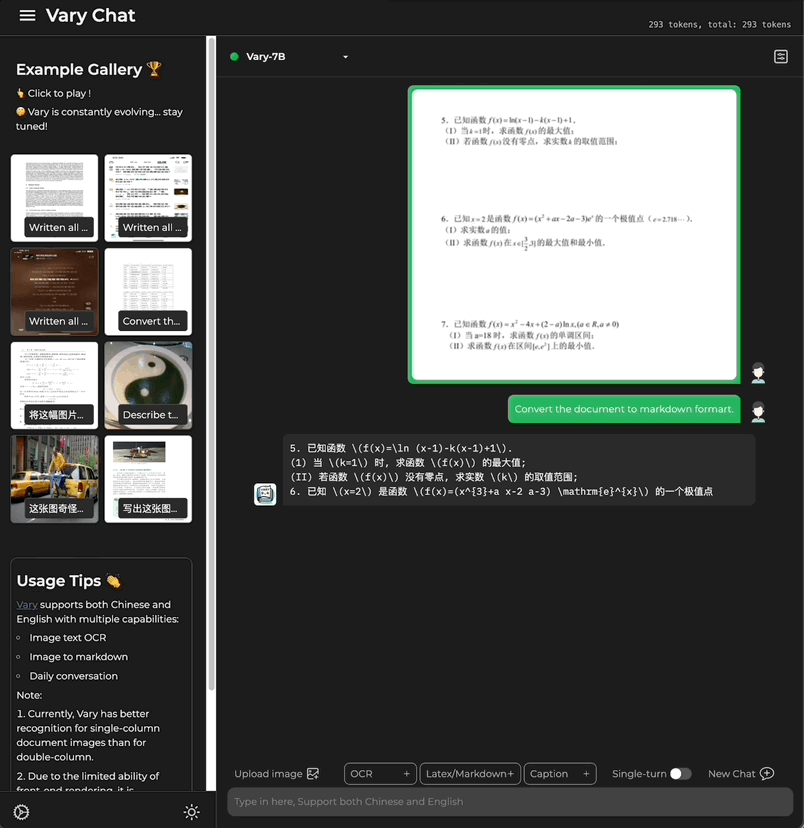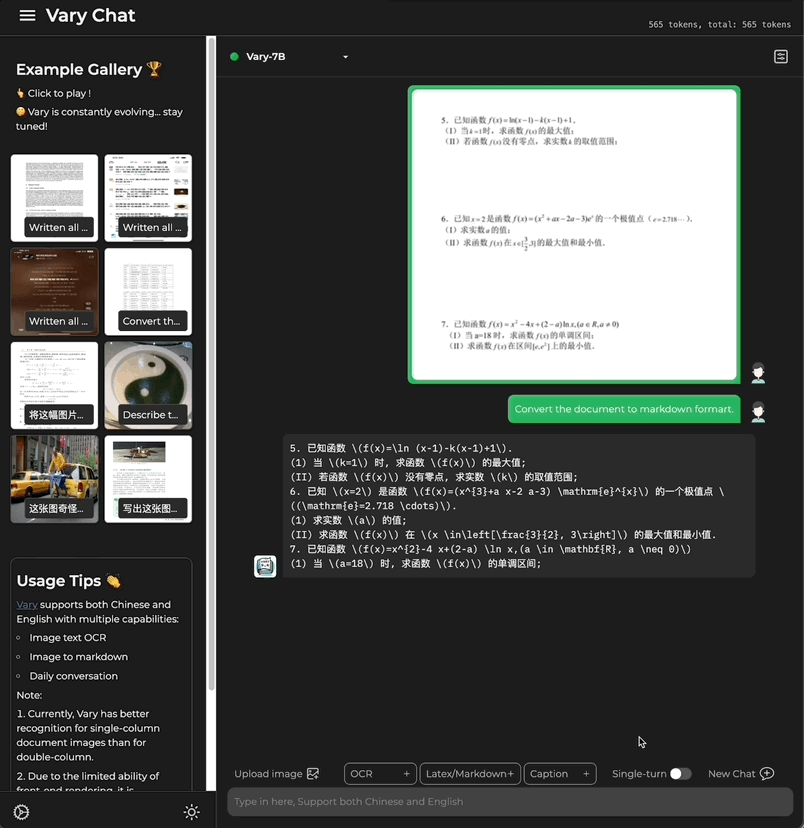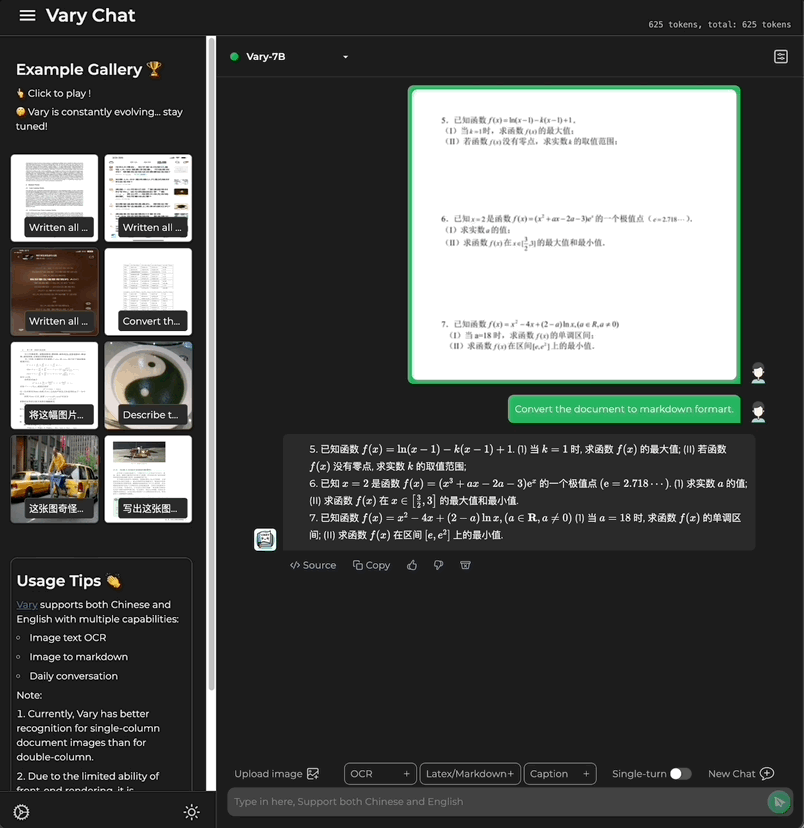
Kali ini, dengan hanya satu ayat perintah, Model besar berbilang modal Vary dihantar terus ke Keputusan output terminal:
 gambar
gambar
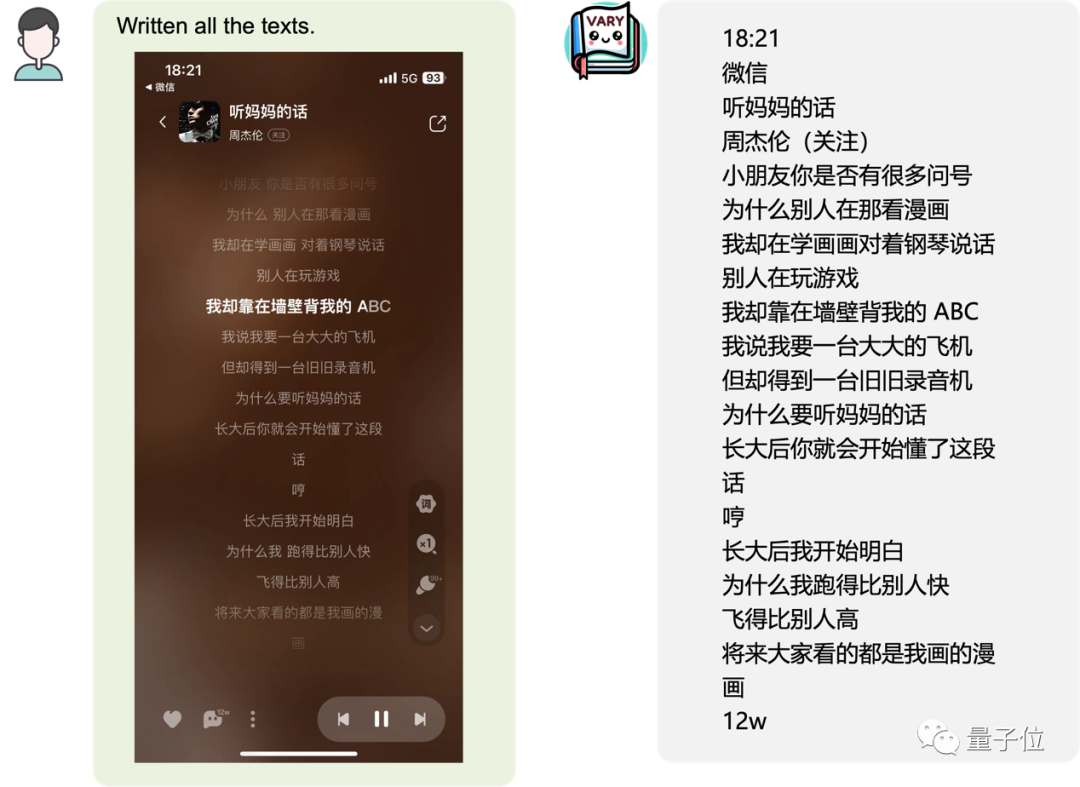
Sama ada teks besar dalam bahasa Cina dan Inggeris:
 gambar termasuk rumusan
gambar termasuk rumusan
 . model, mengekalkan keupayaan sejagat adalah penting. Gambar
. model, mengekalkan keupayaan sejagat adalah penting. Gambar
 Vary menunjukkan potensi besar dan had atas yang sangat tinggi tidak lagi memerlukan talian paip yang panjang, secara langsung mengeluarkan hujung ke hujung, dan boleh mengeluarkan format yang berbeza seperti lateks. mengikut gesaan pengguna , perkataan, penurunan harga. Dengan pendahuluan bahasa yang kuat, seni bina ini boleh mengelakkan perkataan yang mudah menaip dalam OCR, seperti "leverage" dan "dupole", dsb. Untuk dokumen kabur, dengan bantuan bahasa dahulu, ia juga dijangka mencapai kesan OCR yang lebih kukuh
Vary menunjukkan potensi besar dan had atas yang sangat tinggi tidak lagi memerlukan talian paip yang panjang, secara langsung mengeluarkan hujung ke hujung, dan boleh mengeluarkan format yang berbeza seperti lateks. mengikut gesaan pengguna , perkataan, penurunan harga. Dengan pendahuluan bahasa yang kuat, seni bina ini boleh mengelakkan perkataan yang mudah menaip dalam OCR, seperti "leverage" dan "dupole", dsb. Untuk dokumen kabur, dengan bantuan bahasa dahulu, ia juga dijangka mencapai kesan OCR yang lebih kukuh
Projek yang menarik perhatian ramai netizen serta-merta membangkitkan perbincangan meluas sebaik sahaja ia dilancarkan. Salah seorang netizen berseru selepas melihatnya, "Ia sangat hebat!"Gambar
 Bagaimana kesan ini dicapai? Diinspirasikan oleh model besar
Bagaimana kesan ini dicapai? Diinspirasikan oleh model besar
Pada masa ini, hampir semua model besar berbilang modal menggunakan CLIP sebagai Vision Encoder atau perbendaharaan kata visual. Sesungguhnya, CLIP yang dilatih pada pasangan teks imej 400M mempunyai keupayaan penjajaran teks visual yang kukuh dan boleh merangkumi pengekodan imej dalam kebanyakan tugas harian.
Tetapi untuk tugas persepsi yang padat dan terperinci, seperti OCR peringkat dokumen dan pemahaman carta, terutamanya dalam senario bukan bahasa Inggeris, CLIP menunjukkan isu  ketidakcekapan pengekodan dan perbendaharaan kata yang jelas.
ketidakcekapan pengekodan dan perbendaharaan kata yang jelas.
 Gambar
Gambar
Berikut ialah ilustrasi kaedah latihan dan struktur model Vary:
GambarDengan Dilatih pada set data awam dan carta dokumen yang diberikan, Vary sangat meningkatkan butiran halus keupayaan persepsi visual.
Sambil mengekalkan keupayaan pelbagai mod vanila, ia memberi inspirasi kepada pemahaman menyeluruh tentang gambar Cina dan Inggeris, tangkapan skrin formula dan carta.
Selain itu, pasukan penyelidik mendapati bahawa kandungan halaman yang mungkin pada asalnya memerlukan beribu-ribu token telah dimasukkan melalui imej dokumen, dan maklumat itu dimampatkan menjadi 256 token imej, yang juga memberikan lebih banyak imaginasi untuk analisis halaman selanjutnya dan ruang ringkasan .
Pada masa ini, kod dan model Vary adalah sumber terbuka, dan demo web juga disediakan untuk semua orang mencuba.
Kawan-kawan yang berminat boleh cuba~
Atas ialah kandungan terperinci Model besar berbilang modal sumber terbuka Megvii menyokong OCR peringkat dokumen, meliputi bahasa Cina dan Inggeris Adakah ia menandakan tamatnya OCR?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!