
Rumah >Peranti teknologi >AI >Model berskala besar sudah boleh menganotasi imej dengan hanya perbualan mudah! Hasil penyelidikan daripada Tsinghua & NUS
Model berskala besar sudah boleh menganotasi imej dengan hanya perbualan mudah! Hasil penyelidikan daripada Tsinghua & NUS

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-05 12:56:09721semak imbas
Selepas model besar berbilang modal menyepadukan modul pengesanan dan pembahagian, potongan imej menjadi lebih mudah!
Model kami boleh melabel objek yang anda cari dengan cepat melalui penerangan bahasa semula jadi dan memberikan penjelasan teks untuk membantu anda menyelesaikan tugas dengan mudah.
Model besar berbilang modal baharu yang dibangunkan oleh makmal NExT++ Universiti Nasional Singapura dan pasukan Liu Zhiyuan di Universiti Tsinghua memberikan kami sokongan padu. Model ini telah direka dengan teliti untuk memberikan pemain bantuan dan bimbingan yang komprehensif semasa proses penyelesaian teka-teki. Ia menggabungkan maklumat daripada pelbagai modaliti untuk memberikan pemain kaedah dan strategi penyelesaian teka-teki baharu. Penerapan model ini akan memberi manfaat kepada pemain

Dengan pelancaran GPT-4v, medan berbilang modal telah membawa kepada siri model baharu, seperti LLaVA, BLIP-2 dan sebagainya. Kemunculan model-model ini telah memberi sumbangan yang besar dalam meningkatkan prestasi dan keberkesanan tugas pelbagai modal.
Untuk meningkatkan lagi keupayaan pemahaman serantau bagi model besar berbilang modal, pasukan penyelidik membangunkan model berbilang modal yang dipanggil NExT-Chat. Model ini mempunyai keupayaan untuk menjalankan dialog, pengesanan dan segmentasi secara serentak.
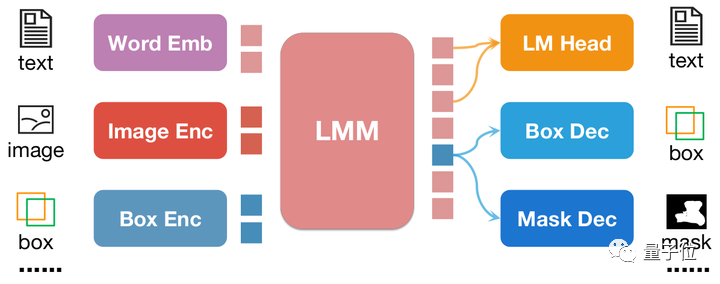
Sorotan terbesar NExT-Chat ialah keupayaan untuk memperkenalkan input dan output kedudukan ke dalam model berbilang modalnya. Ciri ini membolehkan NExT-Chat memahami dengan lebih tepat dan bertindak balas terhadap keperluan pengguna semasa interaksi. Melalui input lokasi, NExT-Chat boleh memberikan maklumat dan cadangan yang berkaitan berdasarkan lokasi geografi pengguna, dengan itu meningkatkan pengalaman pengguna. Melalui output lokasi, NExT-Chat boleh menyampaikan maklumat yang berkaitan tentang lokasi geografi tertentu kepada pengguna untuk membantu mereka dengan lebih baik
Antaranya, keupayaan input lokasi merujuk kepada menjawab soalan berdasarkan kawasan yang ditentukan, manakala keupayaan output lokasi merujuk kepada lokasi- dialog tertentu objek yang dinyatakan. Kedua-dua kebolehan ini sangat penting dalam permainan teka-teki.

Malah masalah kedudukan yang kompleks boleh diselesaikan dengan mudah:

Selain kedudukan objek, NExT-Chat juga boleh menerangkan imej atau bahagian tertentu daripadanya:
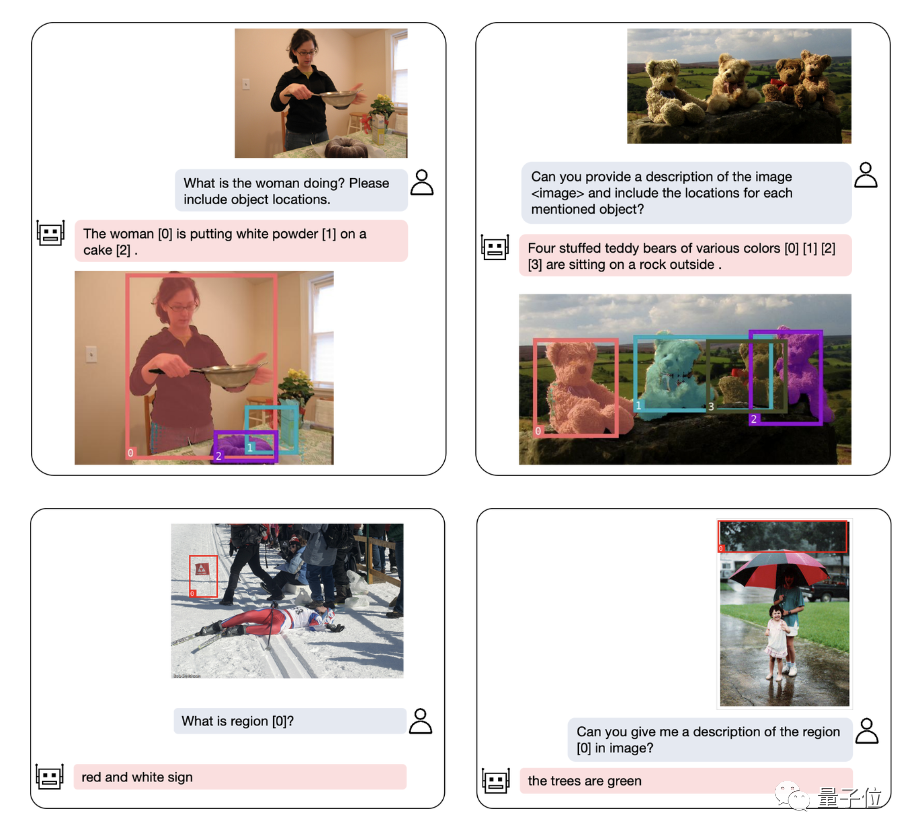 menganalisis kandungan imej Selepas itu, NExT-Chat boleh menggunakan maklumat yang diperolehi untuk melakukan inferens:
menganalisis kandungan imej Selepas itu, NExT-Chat boleh menggunakan maklumat yang diperolehi untuk melakukan inferens:

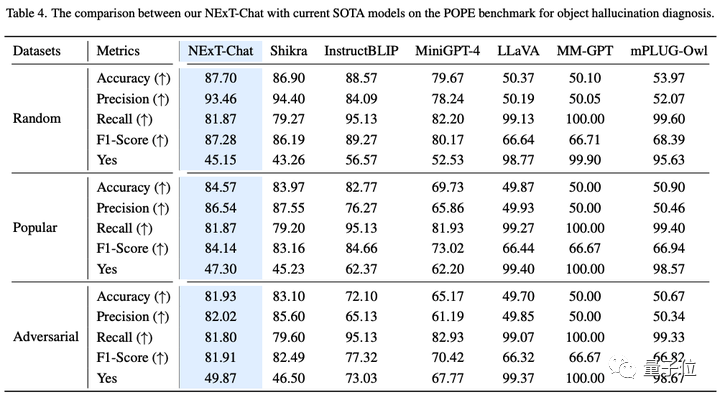
△NExT-Chat hasil pada set data POPE
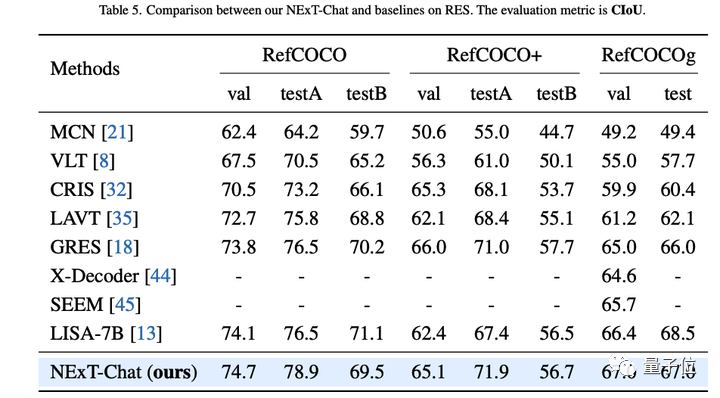
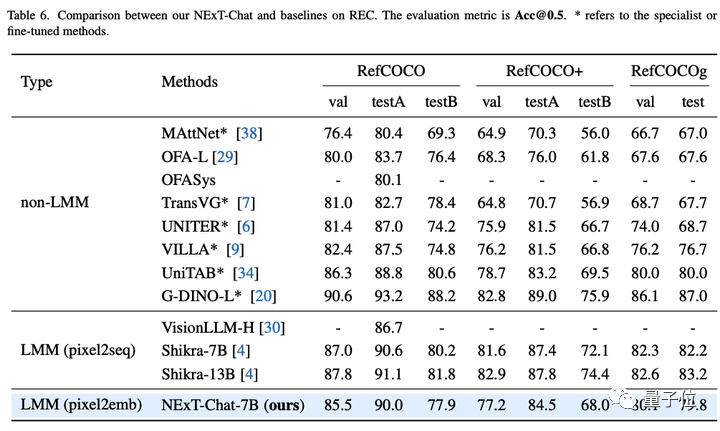
Dalam tugas penerangan kawasan, NExT-Chat juga boleh mencapai prestasi CIDEr terbaik, dan mengalahkan Kosmos-2 dalam kes 4-shot dalam penunjuk ini.
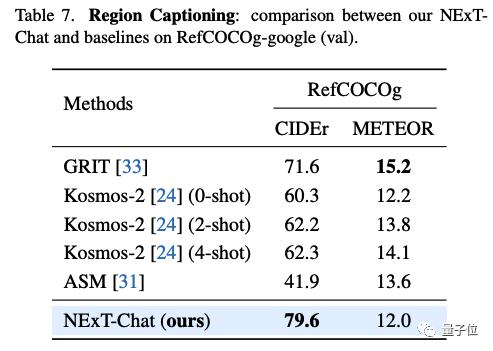
△NExT-Hasil Sembang pada set data RefCOCOg
Jadi, apakah kaedah yang digunakan di sebalik NExT-Chat?
Cadangkan kaedah baharu pengekodan imej
Kecacatan kaedah tradisional
Model tradisional terutamanya melaksanakan pemodelan kedudukan berkaitan LLM melalui pix2seq.
Contohnya, Kosmos-2 membahagikan imej kepada blok 32x32, dan menggunakan id setiap blok untuk mewakili koordinat titik tersebut, Shikra menukar koordinat bingkai objek kepada teks biasa supaya LLM boleh memahami koordinat.
Walau bagaimanapun, output model menggunakan kaedah pix2seq terutamanya terhad kepada format ringkas seperti kotak dan titik, dan sukar untuk digeneralisasikan kepada format perwakilan kedudukan lain yang lebih padat, seperti topeng segmentasi.
Untuk menyelesaikan masalah ini, artikel ini mencadangkan kaedah pemodelan kedudukan berasaskan benam pix2emb yang baharu.
kaedah pix2emb
Berbeza dengan pix2seq, semua maklumat kedudukan pix2emb dikodkan dan dinyahkod melalui pengekod dan penyahkod yang sepadan, dan bukannya bergantung pada pengepala ramalan teks LLM itu sendiri.
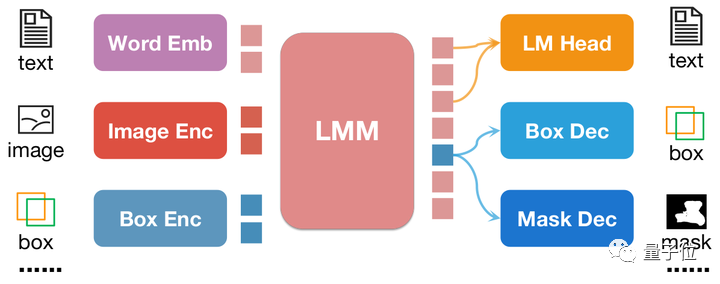
△Contoh mudah kaedah pix2emb
Seperti yang ditunjukkan dalam rajah di atas, input kedudukan dikodkan ke dalam pembenaman kedudukan oleh pengekod yang sepadan, dan pembenaman kedudukan output ditukar menjadi kotak dan topeng melalui Penyahkod Kotak dan Penyahkod Topeng .
Melakukan ini membawa dua faedah:
- Format output model boleh diperluaskan dengan mudah kepada bentuk yang lebih kompleks, seperti topeng segmentasi.
- Model boleh mengesan kaedah praktikal sedia ada dalam tugasan Sebagai contoh, kehilangan pengesanan dalam artikel ini menggunakan Kehilangan L1 dan Kehilangan GIoU (pix2seq hanya boleh menggunakan teks untuk menjana kerugian dalam artikel ini menggunakan yang sedia ada). SAM untuk melakukannya.
Dengan menggabungkan pix2seq dengan pix2emb, penulis melatih model NExT-Chat baharu.
NExT-Chat model
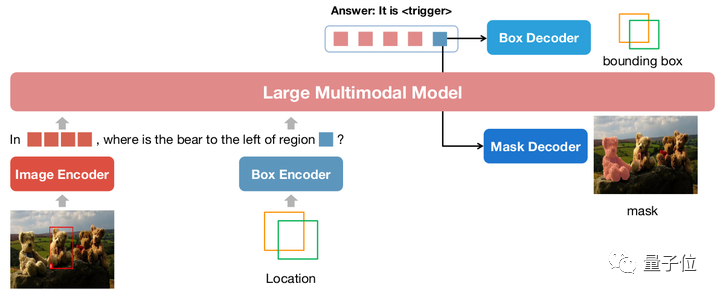
△NExT-Chat model architecture
NExT-Chat mengguna pakai seni bina LLaVA secara keseluruhan, iaitu, maklumat imej dikodkan melalui Image Encoder dan input ke dalam LLM untuk pemahaman, dan mengenai perkara ini asas, surat-menyurat ditambah Pengekod Kotak dan Penyahkod keluaran dua kedudukan.
Untuk menyelesaikan masalah LLM tidak tahu bila menggunakan kepala LM bahasa atau penyahkod kedudukan, NExT-Chat tambahan memperkenalkan jenis token baharu untuk mengenal pasti maklumat kedudukan.
Jika model keluar, pembenaman token akan dihantar ke penyahkod kedudukan yang sepadan untuk penyahkodan dan bukannya penyahkod bahasa.
Selain itu, untuk mengekalkan ketekalan maklumat kedudukan antara peringkat input dan peringkat output, NExT-Chat memperkenalkan kekangan penjajaran tambahan:
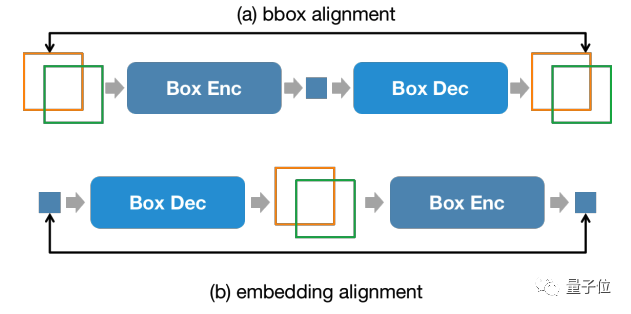
△Kekangan input dan output kedudukan
Seperti yang ditunjukkan dalam rajah di atas, kotak dan pembenaman kedudukan akan Ia digabungkan dengan penyahkod, pengekod atau penyahkod-pengekod masing-masing, dan dikehendaki untuk tidak berubah sebelum dan selepas.
Pengarang mendapati kaedah ini dapat menggalakkan penumpuan keupayaan input kedudukan.
Latihan model NExT-Chat terutamanya merangkumi 3 peringkat:
- Peringkat pertama: melatih model keupayaan input dan output kotak asas. NExT-Chat menggunakan Flickr-30K, RefCOCO, VisualGenome dan set data lain yang mengandungi input dan output kotak untuk pra-latihan. Semasa proses latihan, semua parameter LLM akan dilatih.
- Peringkat kedua: Laraskan arahan LLM mengikut keupayaan. Penalaan halus data melalui beberapa arahan Shikra-RD, LLaVA-instruct dan lain-lain membolehkan model bertindak balas dengan lebih baik kepada keperluan manusia dan menghasilkan hasil yang lebih berperikemanusiaan.
- Peringkat ketiga: Berikan keupayaan segmentasi model NExT-Chat. Melalui dua peringkat latihan di atas, model tersebut sudah mempunyai keupayaan pemodelan kedudukan yang baik. Penulis melanjutkan lagi keupayaan ini untuk menutup output. Percubaan mendapati bahawa dengan menggunakan jumlah data anotasi topeng dan masa latihan yang sangat kecil (kira-kira 3 jam), NExT-Chat boleh mencapai keupayaan pembahagian yang baik dengan cepat.
Kelebihan proses latihan sedemikian ialah data rangka pengesanan adalah kaya dan overhed latihan adalah lebih kecil.
NExT-Chat melatih keupayaan pemodelan kedudukan asas pada data bingkai pengesanan yang banyak, dan kemudian boleh berkembang dengan cepat kepada tugasan pembahagian yang lebih sukar dan mempunyai anotasi yang lebih terhad.
Atas ialah kandungan terperinci Model berskala besar sudah boleh menganotasi imej dengan hanya perbualan mudah! Hasil penyelidikan daripada Tsinghua & NUS. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!