
Rumah >Peranti teknologi >AI >Nilaikan prestasi penanda aras LLM4VG yang dibangunkan oleh Universiti Tsinghua dalam penentududukan masa video
Nilaikan prestasi penanda aras LLM4VG yang dibangunkan oleh Universiti Tsinghua dalam penentududukan masa video

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-04 22:38:141288semak imbas

Berita pada 29 Disember, capaian model bahasa besar (LLM) telah berkembang daripada pemprosesan bahasa semula jadi yang mudah kepada medan berbilang modal seperti teks, audio, video, dll. Dan salah satu kuncinya ialah penentududukan masa video ( Pembumian Video, VG).
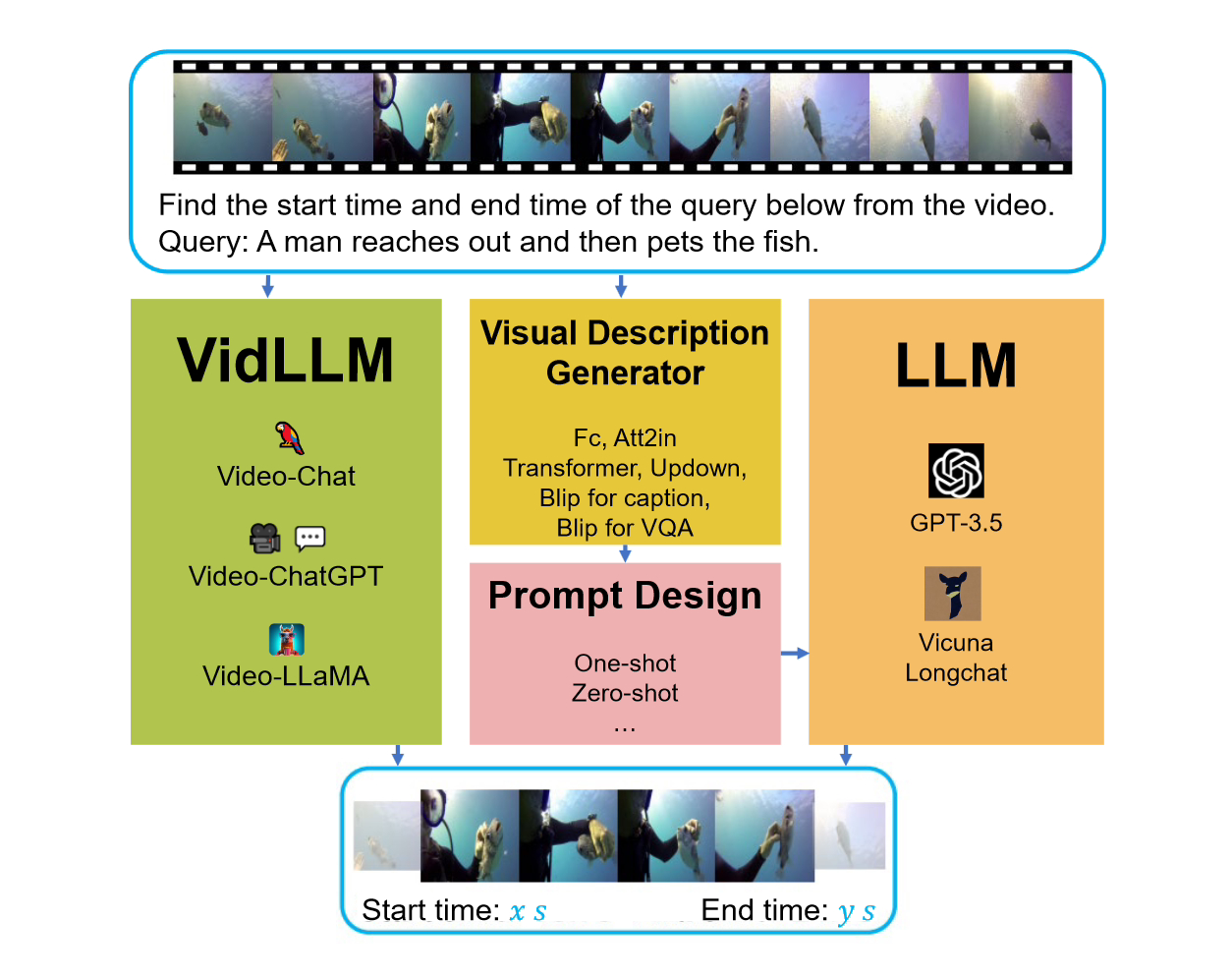
Matlamat tugas VG adalah untuk mencari masa mula dan tamat segmen video sasaran berdasarkan pertanyaan yang diberikan. Cabaran teras tugas ini adalah untuk menentukan sempadan masa dengan tepat.
Pasukan penyelidik Universiti Tsinghua baru-baru ini melancarkan penanda aras "LLM4VG", yang direka khusus untuk menilai prestasi LLM dalam tugasan VG.
Apabila mempertimbangkan penanda aras ini, terdapat dua strategi utama yang dipertimbangkan. Strategi pertama ialah melatih model bahasa video (LLM) secara langsung pada set data video teks (VidLLM). Kaedah ini mempelajari perkaitan antara video dan bahasa dengan melatih set data video berskala besar untuk meningkatkan prestasi model. Strategi kedua ialah menggabungkan model bahasa tradisional (LLM) dengan model penglihatan yang telah dilatih. Kaedah ini adalah berdasarkan model visual pra-latihan yang menggabungkan ciri visual video Dalam satu strategi, model VidLLM secara langsung memproses kandungan video dan arahan tugasan VG, dan meramalkan hubungan teks-video berdasarkan output latihannya. perhubungan.
Strategi kedua adalah lebih kompleks dan melibatkan penggunaan LLM (Model Bahasa dan Penglihatan) dan model penerangan visual. Model ini dapat menjana penerangan teks kandungan video digabungkan dengan arahan tugasan VG (Permainan Video), dan penerangan ini dilaksanakan dengan gesaan yang direka dengan teliti. 
Dan strategi kedua adalah lebih baik daripada VidLLM, menunjukkan hala tuju yang menjanjikan untuk penyelidikan masa depan. Strategi ini dihadkan terutamanya oleh pengehadan model visual dan reka bentuk perkataan kiu, jadi dapat menjana penerangan video yang terperinci dan tepat, model grafik yang lebih halus boleh meningkatkan prestasi VG LLM dengan ketara.

Ringkasnya, kajian ini menyediakan penilaian terobosan penerapan LLM pada tugasan VG, yang menekankan keperluan untuk kaedah yang lebih canggih dalam latihan model dan reka bentuk kiu.
Alamat rujukan kertas kerja dilampirkan pada laman web ini: 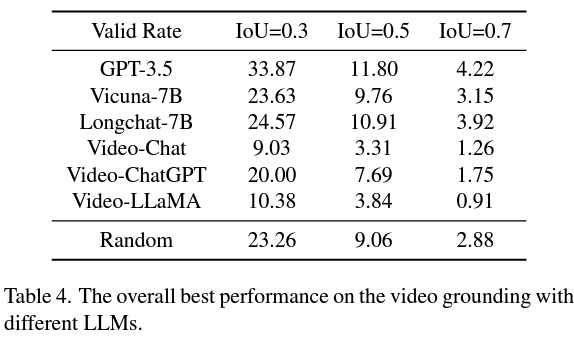
Atas ialah kandungan terperinci Nilaikan prestasi penanda aras LLM4VG yang dibangunkan oleh Universiti Tsinghua dalam penentududukan masa video. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!