
Rumah >Peranti teknologi >AI >A800 dengan ketara mengatasi inferens Llama2 RTX3090 dan 4090, melakukan kependaman dan daya pemprosesan yang sangat baik
A800 dengan ketara mengatasi inferens Llama2 RTX3090 dan 4090, melakukan kependaman dan daya pemprosesan yang sangat baik

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-04 13:05:001349semak imbas
Model bahasa berskala besar (LLM) telah mencapai kemajuan yang luar biasa dalam kedua-dua akademik dan industri. Tetapi latihan dan penggunaan LLM adalah sangat mahal dan memerlukan banyak sumber pengkomputeran dan ingatan, jadi penyelidik telah membangunkan banyak rangka kerja sumber terbuka dan kaedah untuk mempercepatkan pra-latihan, penalaan halus dan inferens LLM. Walau bagaimanapun, prestasi masa jalan bagi susunan perkakasan dan perisian yang berbeza boleh berbeza-beza dengan ketara, menjadikannya sukar untuk memilih konfigurasi terbaik.
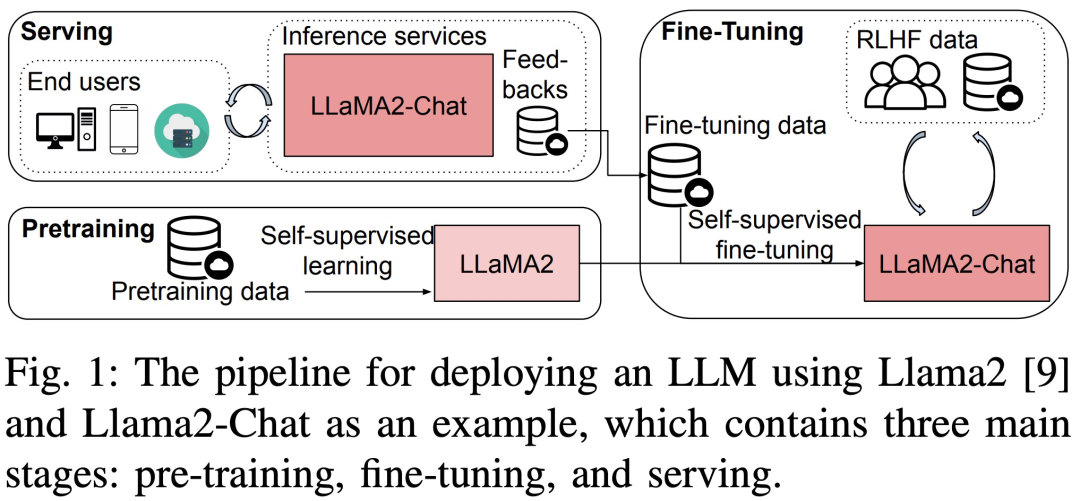
Baru-baru ini, kertas kerja baharu bertajuk "Membedah Prestasi Masa Jalanan Latihan, Penalaan Halus dan Inferens Model Bahasa Besar" menganalisis secara terperinci latihan LLM, penalaan halus dan prestasi inferens Masa Jalan. Sila klik pautan berikut untuk melihat kertas kerja: https://arxiv.org/pdf/2311.03687.pdf , 13B dan 70B parameter) LLM menjalankan ujian penanda aras prestasi penuh tanpa mengubah maksud asal untuk pra-latihan, penalaan halus dan perkhidmatan. Ujian ini meliputi platform dengan dan tanpa teknologi pengoptimuman individu, termasuk ZeRO, Kuantiti, Kira Semula dan FlashAttention. Kajian itu kemudiannya menyediakan analisis masa jalan yang terperinci bagi sub-modul pengiraan dan operator komunikasi dalam LLM
 Pengenalan Kaedah
Pengenalan Kaedah
Tanda aras kajian menggunakan pendekatan atas ke bawah, meliputi Llama2 dalam tiga The end-to-end prestasi masa langkah, prestasi masa peringkat modul dan prestasi masa operator pada platform perkakasan 8-GPU ditunjukkan dalam Rajah 3.
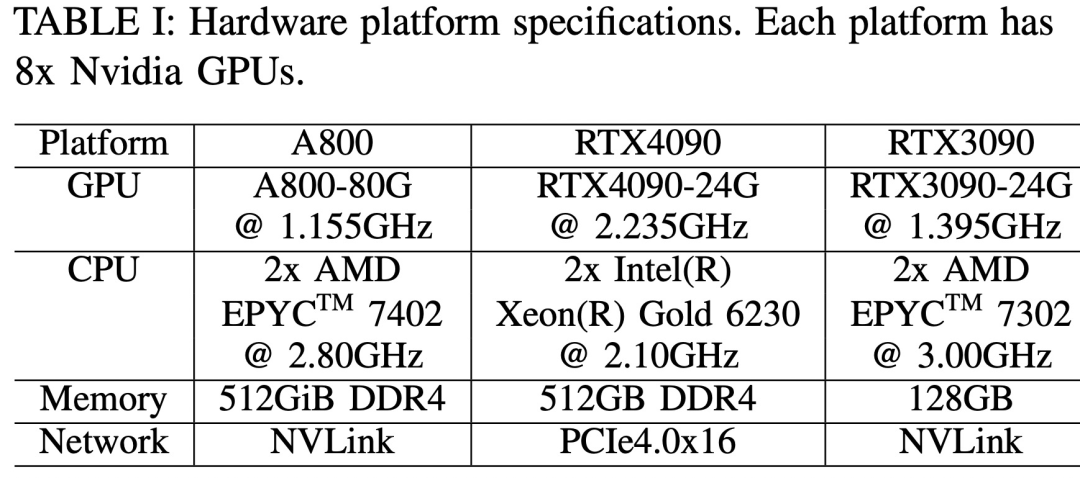
Tiga platform perkakasan ialah RTX4090, RTX3090 dan A800 Spesifikasi khusus ditunjukkan dalam Jadual 1 di bawah.
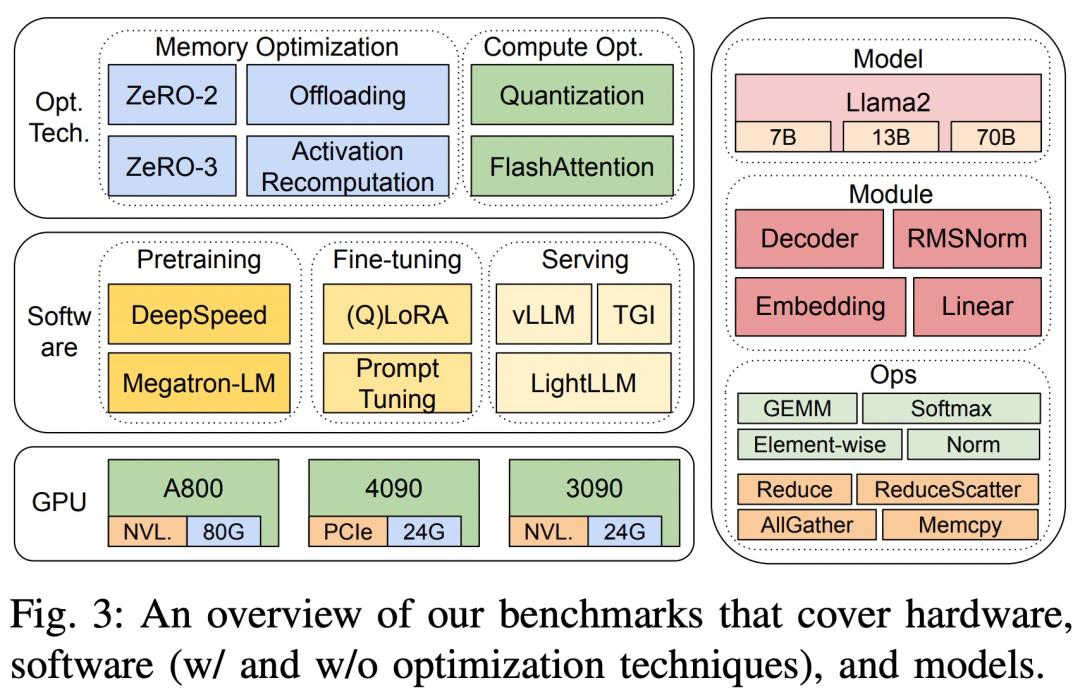
Dari segi perkhidmatan LLM, terdapat tiga sistem yang sangat dioptimumkan, vLLM, LightLLM dan TGI, dan kajian ini membandingkan prestasi mereka (latency dan throughput) pada tiga platform ujian.
 Untuk memastikan ketepatan dan kebolehulangan keputusan, kajian ini mengira purata panjang arahan, input dan output alpaca set data biasa LLM, iaitu, 350 token setiap sampel, dan rentetan yang dijana secara rawak untuk dicapai. 350 panjang urutan.
Untuk memastikan ketepatan dan kebolehulangan keputusan, kajian ini mengira purata panjang arahan, input dan output alpaca set data biasa LLM, iaitu, 350 token setiap sampel, dan rentetan yang dijana secara rawak untuk dicapai. 350 panjang urutan.
Dalam perkhidmatan inferens, untuk menggunakan sumber pengkomputeran secara menyeluruh dan menilai kekukuhan dan kecekapan rangka kerja, semua permintaan dijadualkan dalam mod pecah. Set data eksperimen terdiri daripada 1000 ayat sintetik, setiap ayat mengandungi 512 token input. Kajian ini sentiasa mengekalkan parameter "panjang token terjana maksimum" dalam semua eksperimen pada platform GPU yang sama untuk memastikan ketekalan dan kebolehbandingan hasil. . saiz (7B, 13B dan 70B), untuk mengukur prestasi penuh pada tiga platform ujian tanpa mengubah maksud asal. Tiga sistem penyajian inferens yang digunakan secara meluas: TGI, vLLM dan LightLLM juga dinilai, memfokuskan pada metrik seperti kependaman, daya pemprosesan dan penggunaan memori.
Prestasi Tahap Modul
LLM biasanya terdiri daripada satu siri modul (atau lapisan) yang mungkin mempunyai ciri pengkomputeran dan komunikasi yang unik. Sebagai contoh, modul utama yang membentuk model Llama2 ialah Embedding, LlamaDecoderLayer, Linear, SiLUActivation dan LlamaRMSNorm.
Keputusan pra-latihan
Dalam sesi percubaan pra-latihan, para penyelidik mula-mula menganalisis prestasi pra-latihan (masa lelaran atau pemprosesan, penggunaan memori) model saiz yang berbeza (7B, 13B dan 70B) pada tiga ujian platform. Penanda aras mikro pada tahap modul dan operasi kemudiannya dijalankan.
Tidak perlu menukar maksud asal, prestasi penuh
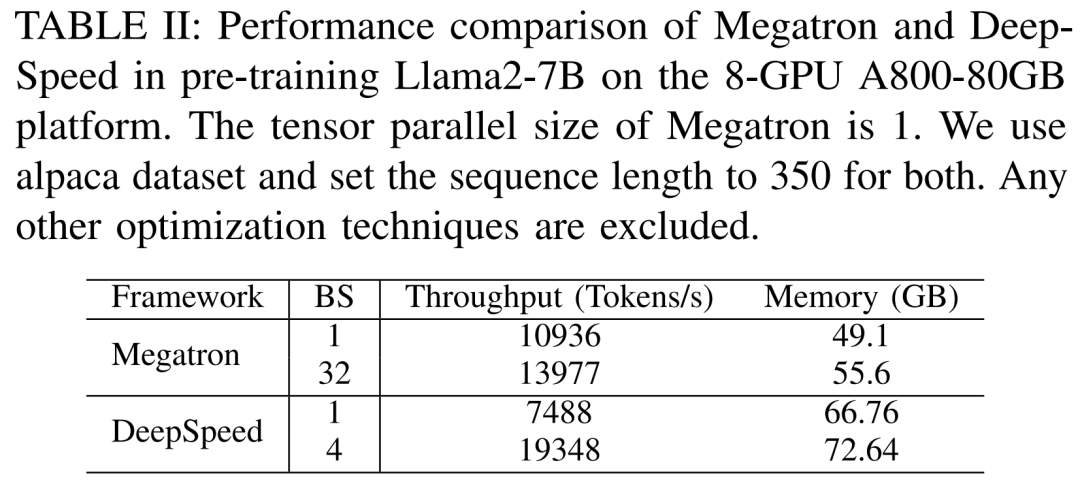
Para penyelidik mula-mula menjalankan eksperimen untuk membandingkan prestasi Megatron-LM dan DeepSpeed, yang tidak digunakan semasa pra-latihan Llama2-7B pelayan A800-80GB Sebarang teknologi pengoptimuman memori (seperti ZeRO).
Mereka menggunakan panjang jujukan 350 dan menyediakan dua set saiz kelompok untuk Megatron-LM dan DeepSpeed, daripada 1 hingga saiz kumpulan maksimum. Keputusan ditunjukkan dalam Jadual II di bawah, ditanda aras terhadap daya pemprosesan latihan (token/saat) dan memori GPU gred pengguna (dalam GB).
Hasilnya menunjukkan bahawa apabila saiz batch kedua-duanya 1, Megatron-LM lebih laju sedikit daripada DeepSpeed. Walau bagaimanapun, DeepSpeed adalah yang terpantas dalam kelajuan latihan apabila saiz kelompok mencapai maksimum. Apabila saiz kelompok adalah sama, DeepSpeed menggunakan lebih banyak memori GPU daripada Megatron-LM berasaskan selari tensor. Walaupun dengan saiz kelompok kecil, kedua-dua sistem menggunakan sejumlah besar memori GPU, menyebabkan limpahan memori pada pelayan GPU RTX4090 atau RTX3090.
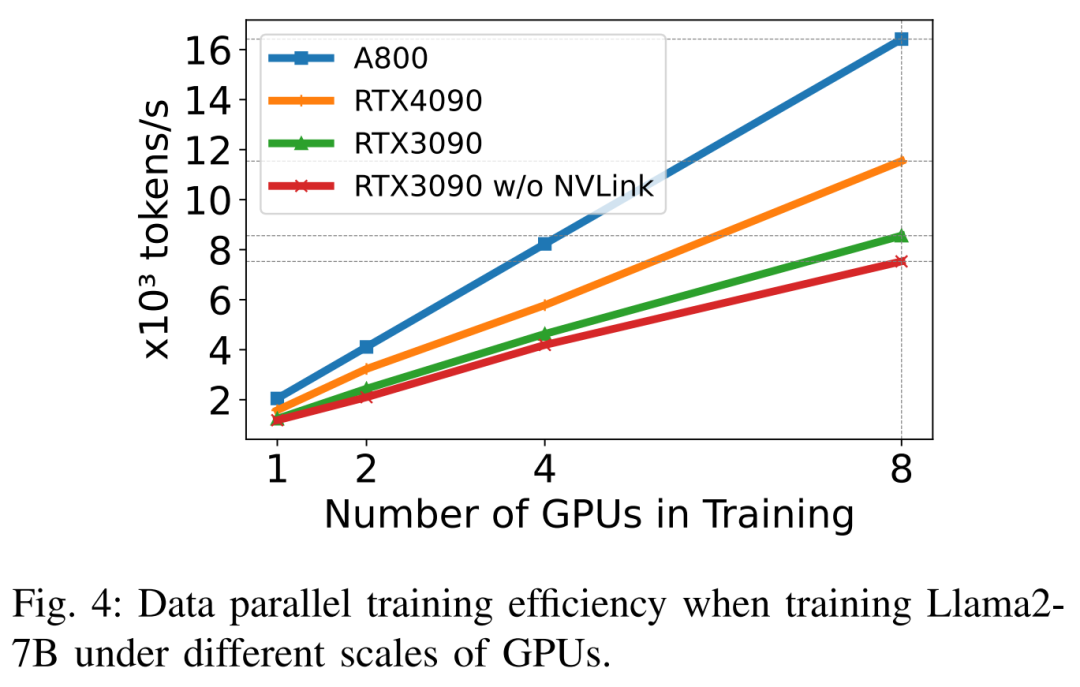
Apabila melatih Llama2-7B (panjang urutan 350, saiz kelompok 2), para penyelidik menggunakan DeepSpeed dengan pengkuantitian untuk mengkaji kecekapan penskalaan pada platform perkakasan yang berbeza. Hasilnya ditunjukkan dalam Rajah 4 di bawah skala A800 hampir secara linear, dan kecekapan penskalaan RTX4090 dan RTX3090 adalah lebih rendah sedikit, masing-masing pada 90.8% dan 85.9%. Pada platform RTX3090, sambungan NVLink adalah 10% lebih cekap berbanding tanpa NVLink.
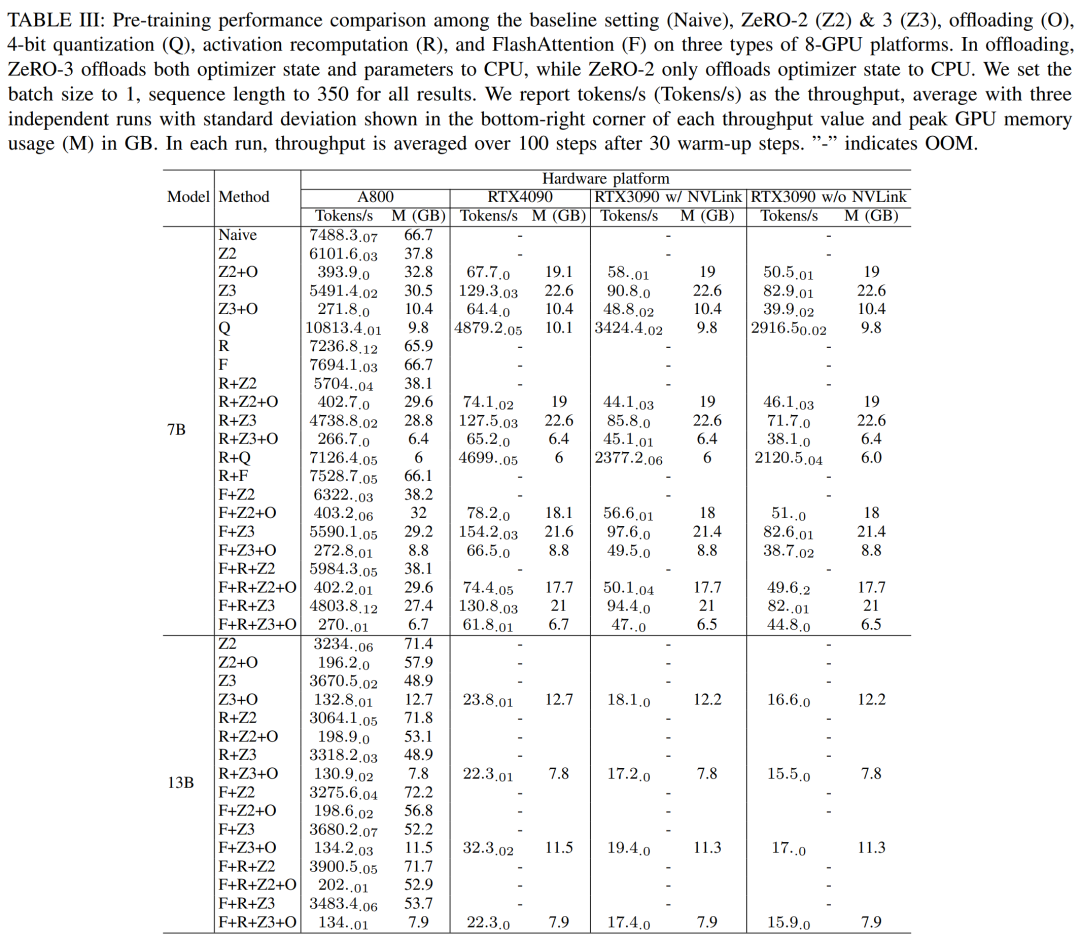
Penyelidik menggunakan DeepSpeed untuk menilai prestasi latihan di bawah memori yang berbeza dan kaedah yang cekap dari segi pengiraan. Untuk keadilan, semua penilaian ditetapkan kepada panjang jujukan 350, saiz kelompok 1 dan berat model dimuatkan lalai sebanyak bf16.
Untuk ZeRO-2 dan ZeRO-3 dengan keupayaan pemunggahan, mereka masing-masing memunggah keadaan pengoptimum dan keadaan pengoptimum + model ke RAM CPU. Untuk kuantisasi, mereka menggunakan konfigurasi 4bits dengan kuantisasi dwi. Turut dilaporkan ialah prestasi RTX3090 apabila NVLink dilumpuhkan (iaitu semua data dipindahkan melalui bas PCIe). Keputusan ditunjukkan dalam Jadual III di bawah.
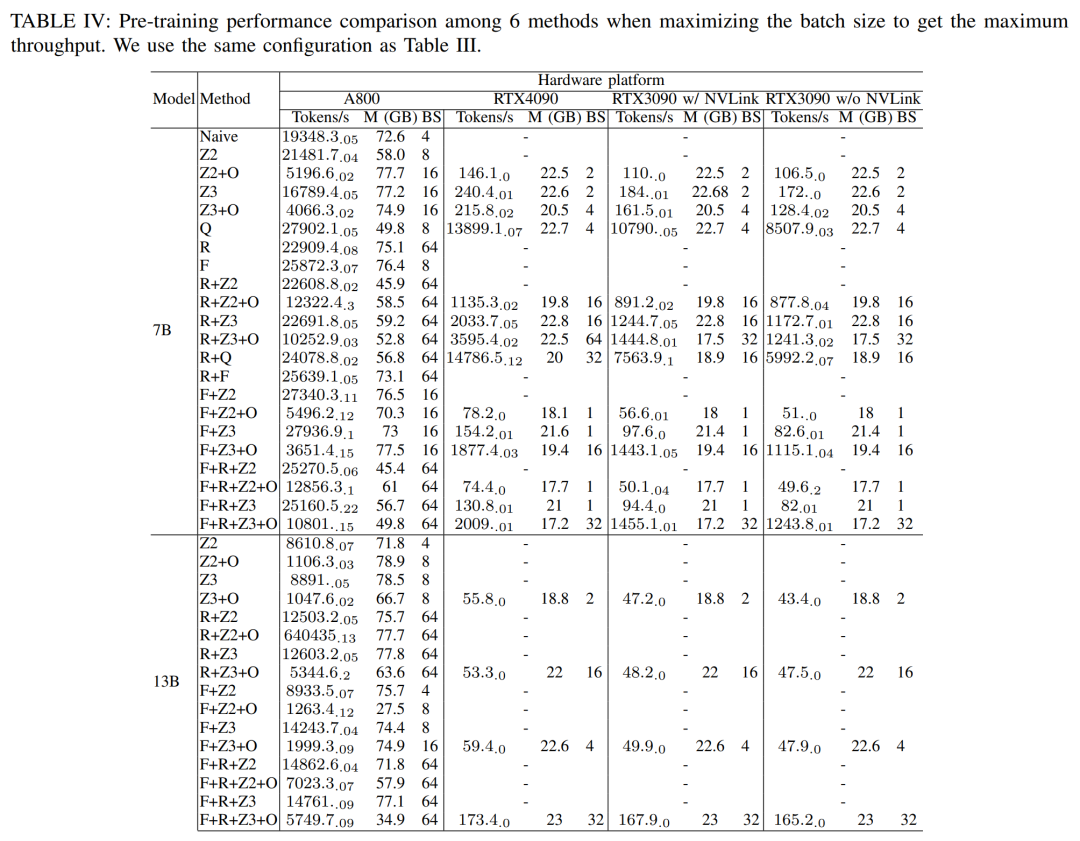
Untuk mendapatkan daya pemprosesan maksimum, para penyelidik terus menggunakan kuasa pengkomputeran pelayan GPU yang berbeza dengan memaksimumkan saiz kelompok setiap kaedah. Keputusan ditunjukkan dalam Jadual IV, menunjukkan bahawa meningkatkan saiz kelompok boleh meningkatkan proses latihan dengan mudah. Oleh itu, pelayan GPU dengan lebar jalur yang tinggi dan memori yang besar lebih sesuai untuk latihan ketepatan campuran parameter penuh daripada pelayan GPU gred pengguna keseluruhan dan kos masa teras pengiraan untuk melatih model Llama2-7B ke hadapan, ke belakang dan pengoptimuman. Untuk fasa ke belakang, memandangkan jumlah masa termasuk masa tidak bertindih, masa teras pengiraan adalah jauh lebih kecil daripada fasa ke hadapan dan pengoptimum. Jika masa tidak bertindih dikeluarkan daripada fasa ke belakang, nilainya menjadi 94.8.
need untuk mengira semula dan menilai semula kesan filleattention
Techniques untuk mempercepatkan pra-latihan boleh dibahagikan kepada dua kategori: menyimpan memori, meningkatkan saiz batch, dan mempercepatkan pengkomputeran teras. Seperti yang ditunjukkan dalam Rajah 5 di bawah, GPU menghabiskan 5-10% daripada masa melahu semasa fasa ke hadapan, ke belakang dan pengoptimuman.
Para penyelidik percaya bahawa masa terbiar ini disebabkan oleh saiz kelompok yang lebih kecil, jadi mereka menguji semua teknik dengan saiz kelompok terbesar yang tersedia. Akhirnya, mereka menggunakan pengiraan semula untuk meningkatkan saiz kelompok dan menggunakan FlashAttention untuk mempercepatkan pengiraan analisis teras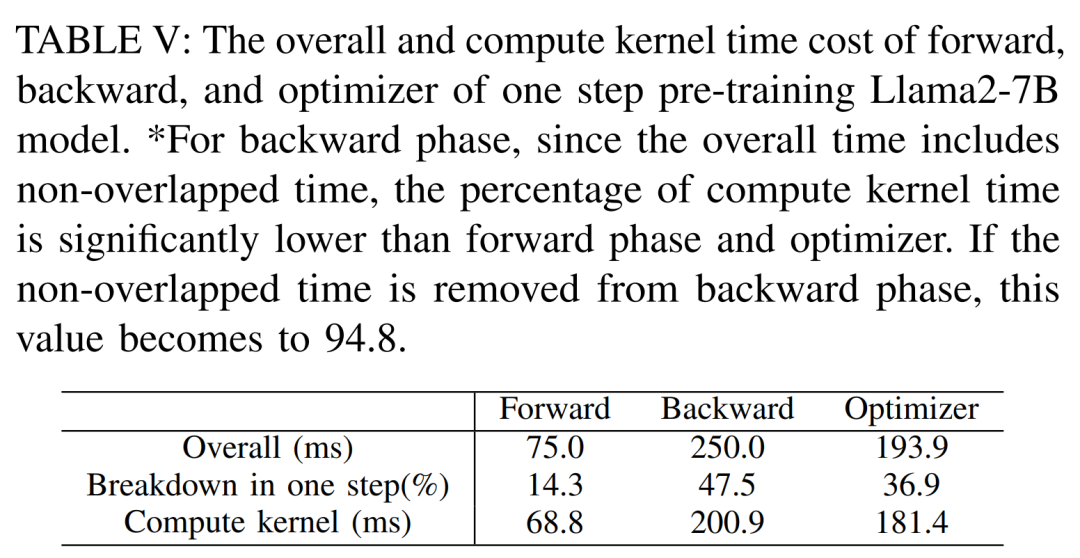
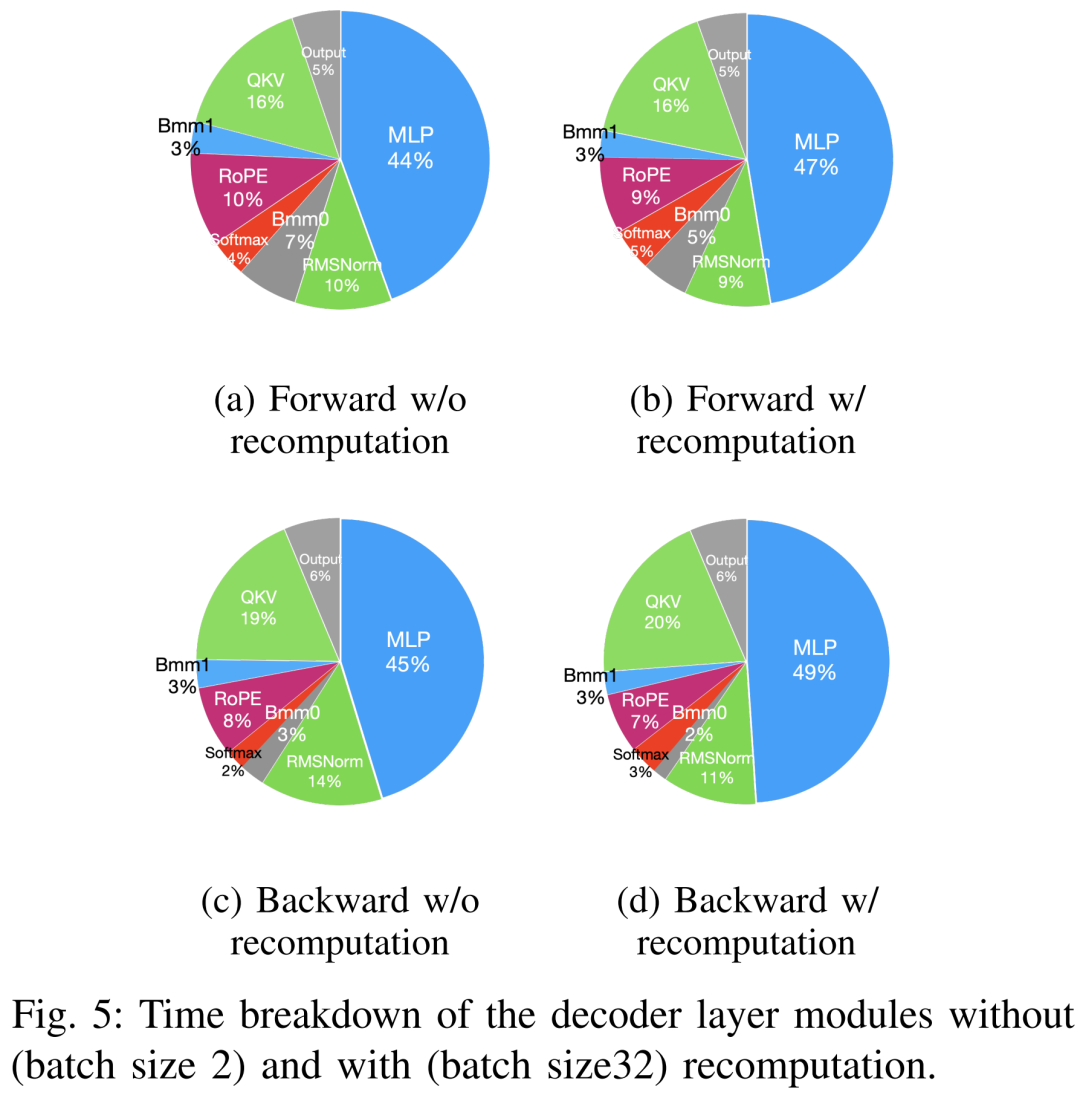
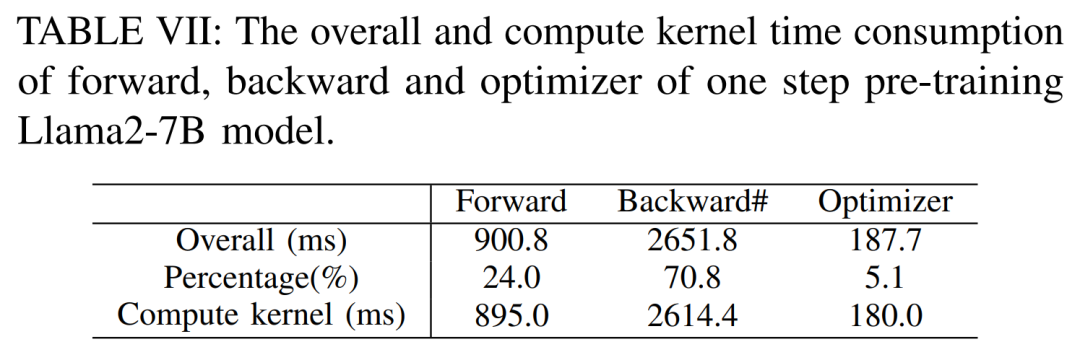
Seperti yang ditunjukkan dalam Jadual VII di bawah, apabila saiz kelompok bertambah, masa fasa ke hadapan dan ke belakang meningkat dengan ketara, menyebabkan hampir tiada masa melahu GPU.
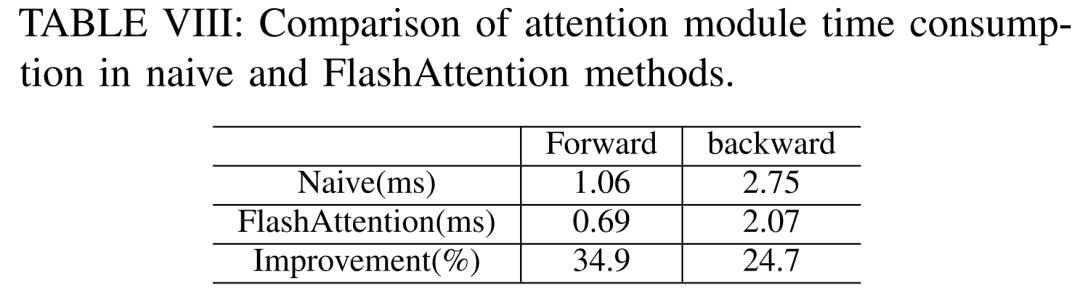
Mengikut Jadual VIII di bawah, FlashAttention boleh mempercepatkan modul perhatian ke hadapan dan ke belakang masing-masing sebanyak 34.9% dan 24.7%
proses penalaan halus , para penyelidik Kaedah penalaan halus cekap parameter (PEFT) dibincangkan terutamanya untuk menunjukkan prestasi penalaan halus LoRA dan QLoRA di bawah pelbagai saiz model dan tetapan perkakasan. Gunakan panjang jujukan 350, saiz kelompok 1, dan muatkan berat model ke dalam bf16 secara lalai.
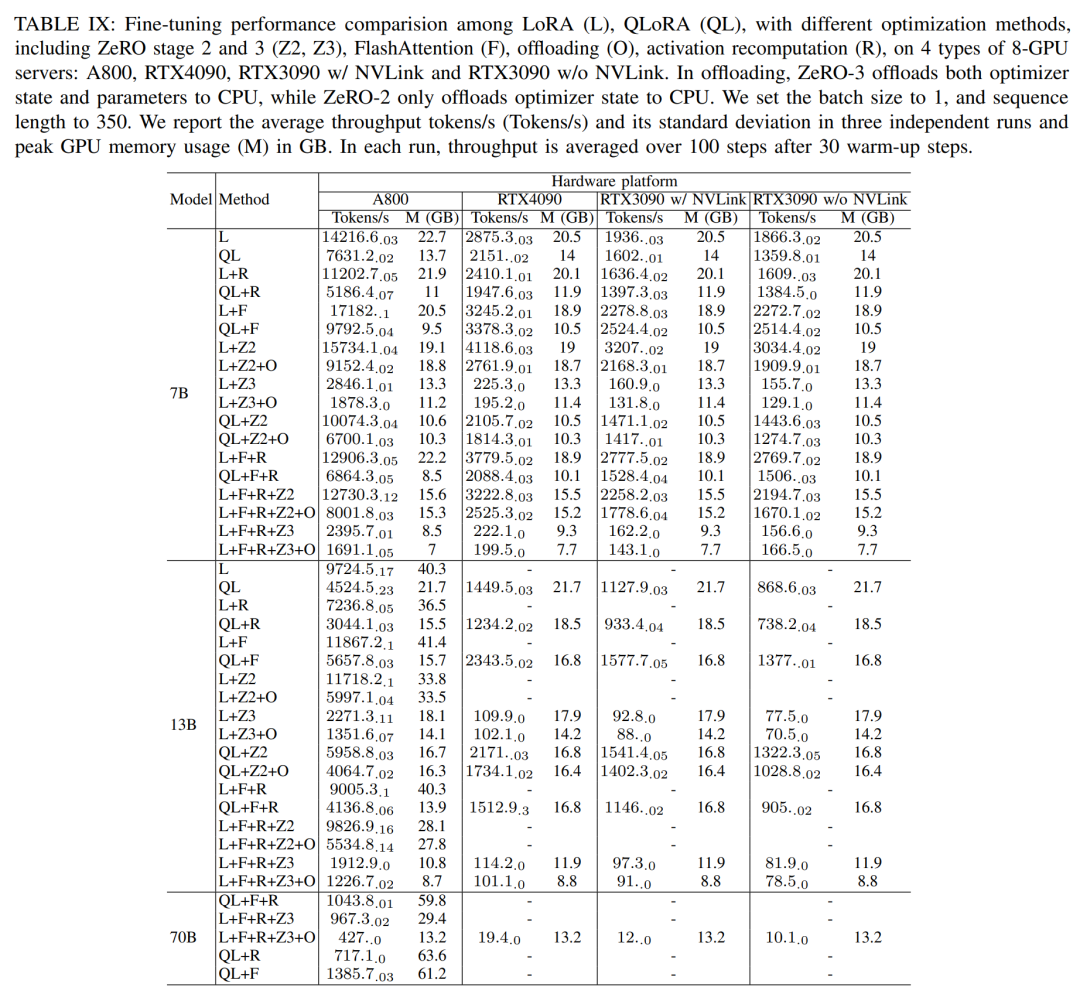 Menurut keputusan dalam Jadual IX di bawah, trend prestasi selepas penalaan halus Llama2-13B menggunakan LoRA dan QLoRA adalah konsisten dengan Llama2-7B. Berbanding dengan Llama2-7B, daya pengeluaran Llama2-13B yang diperhalusi menurun sebanyak kira-kira 30%
Menurut keputusan dalam Jadual IX di bawah, trend prestasi selepas penalaan halus Llama2-13B menggunakan LoRA dan QLoRA adalah konsisten dengan Llama2-7B. Berbanding dengan Llama2-7B, daya pengeluaran Llama2-13B yang diperhalusi menurun sebanyak kira-kira 30%
Namun, apabila semua teknik pengoptimuman digabungkan, malah RTX4090 dan RTX3090 boleh mencapai penalaan halus-200Blama token /saat jumlah hasil.
Keputusan inferensTidak perlu menukar maksud asal, prestasi penuh
Rajah 6 di bawah menunjukkan analisis komprehensif tentang daya pemprosesan dan kerangka kerja Llama77 di bawah pelbagai platform perkakasan data inferens yang berkaitan. Antaranya, rangka kerja TGI menunjukkan daya pemprosesan yang sangat baik, terutamanya pada GPU dengan memori 24GB seperti RTX3090 dan RTX4090. Selain itu, LightLLM dengan ketara mengatasi prestasi TGI dan vLLM pada platform GPU A800, dengan daya pemprosesan hampir dua kali ganda.
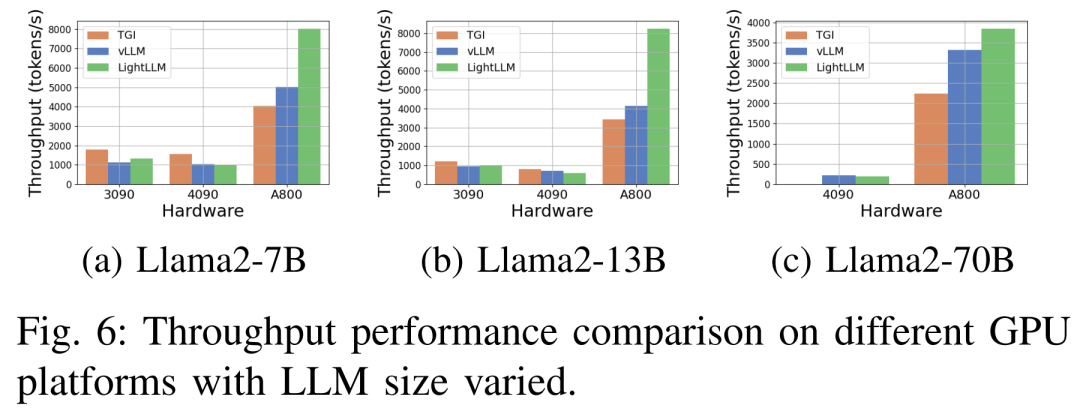 Keputusan percubaan ini menunjukkan bahawa rangka kerja inferens TGI mempunyai prestasi cemerlang pada platform GPU memori 24GB, manakala rangka kerja inferens LightLLM mempamerkan daya pemprosesan tertinggi pada platform GPU A800 80GB. Dapatan ini menunjukkan bahawa LightLLM dioptimumkan khusus untuk siri A800/A100 GPU berprestasi tinggi.
Keputusan percubaan ini menunjukkan bahawa rangka kerja inferens TGI mempunyai prestasi cemerlang pada platform GPU memori 24GB, manakala rangka kerja inferens LightLLM mempamerkan daya pemprosesan tertinggi pada platform GPU A800 80GB. Dapatan ini menunjukkan bahawa LightLLM dioptimumkan khusus untuk siri A800/A100 GPU berprestasi tinggi.
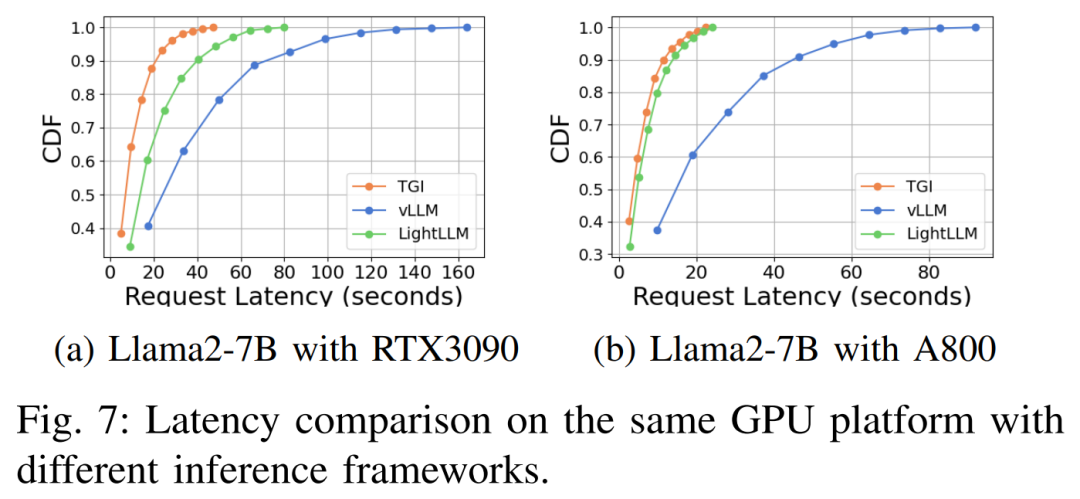 Prestasi kependaman di bawah platform perkakasan dan rangka kerja inferens yang berbeza ditunjukkan dalam Rajah 7, 8, 9 dan 10
Prestasi kependaman di bawah platform perkakasan dan rangka kerja inferens yang berbeza ditunjukkan dalam Rajah 7, 8, 9 dan 10
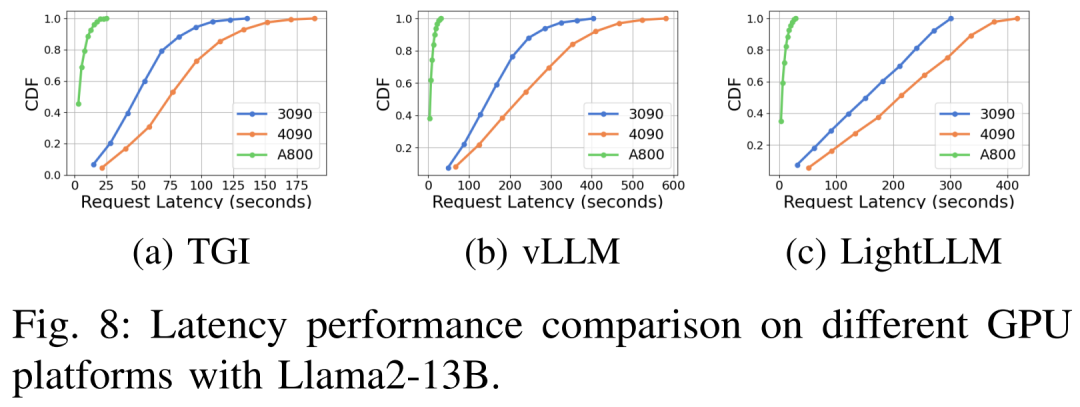
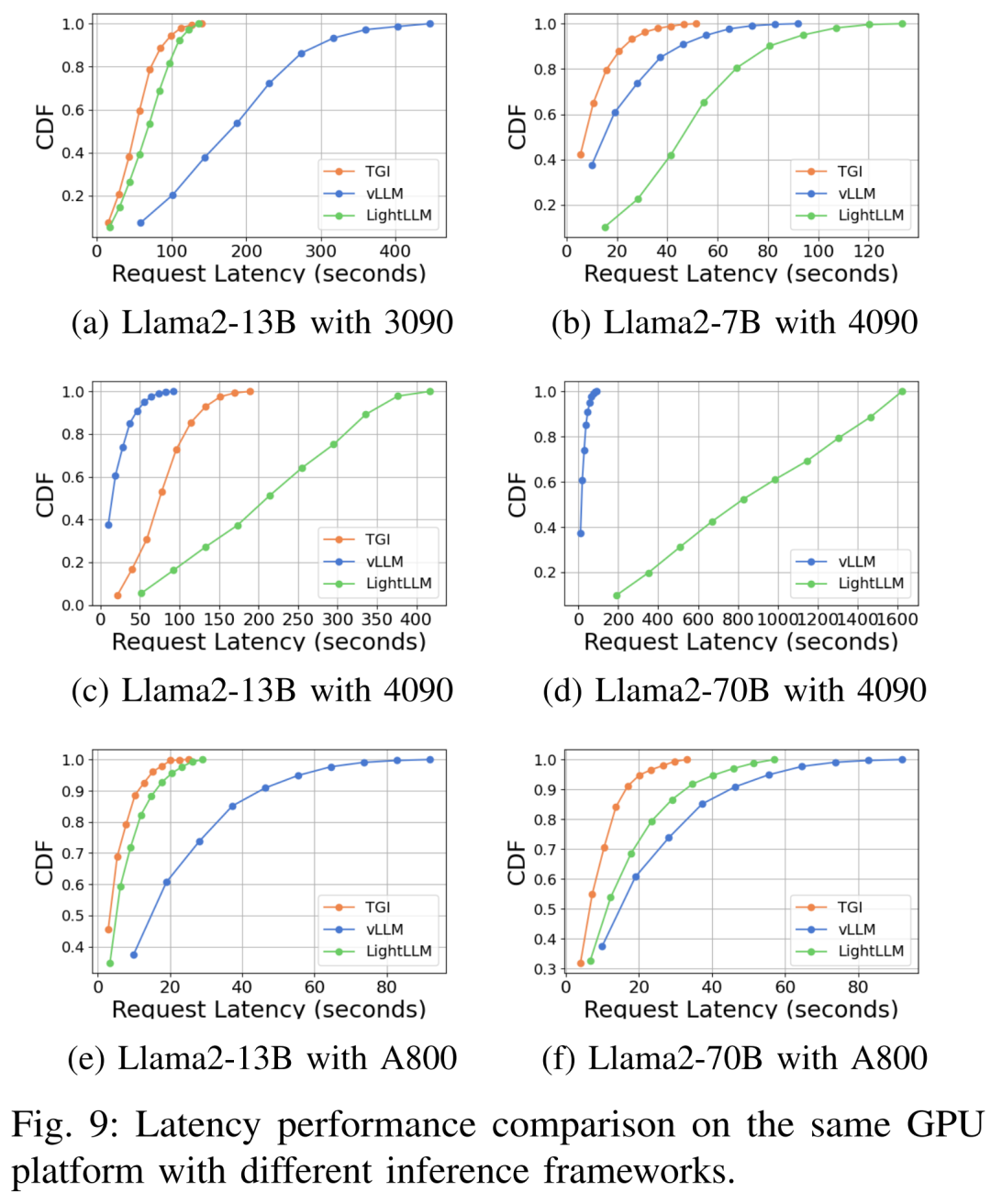
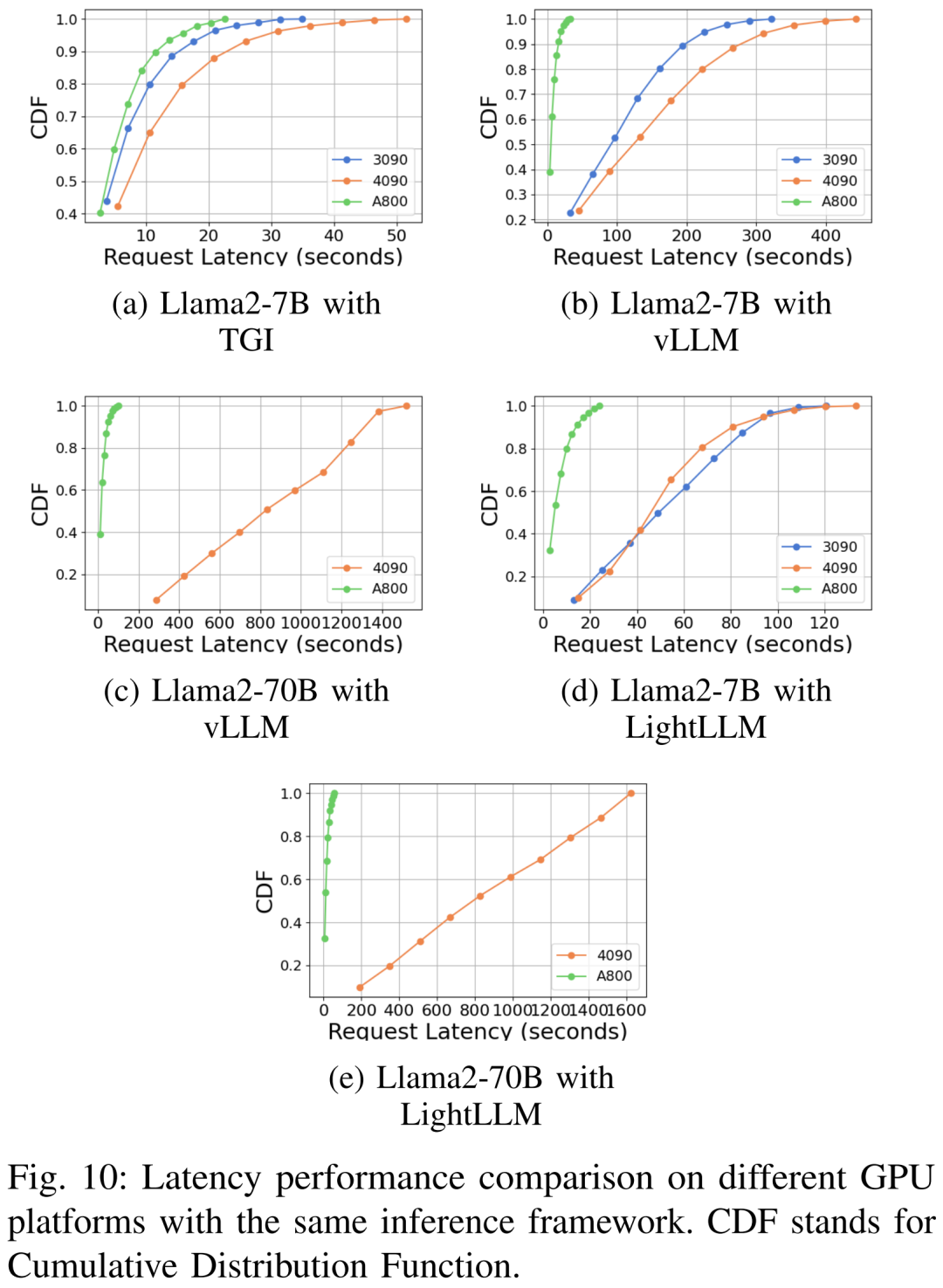
🎜🎜 🎜🎜Komprehensif Seperti yang ditunjukkan di atas, platform A800 jauh lebih baik daripada dua platform pengguna RTX4090 dan RTX3090 dari segi pemprosesan dan kependaman. Dan antara dua platform gred pengguna, RTX3090 mempunyai sedikit kelebihan berbanding RTX4090. Tiga rangka kerja inferens TGI, vLLM dan LightLLM tidak menunjukkan perbezaan besar dalam daya pemprosesan apabila dijalankan pada platform gred pengguna. Sebagai perbandingan, TGI secara konsisten mengatasi dua yang lain dari segi kependaman. Pada platform GPU A800, LightLLM berprestasi terbaik dari segi pemprosesan dan kependamannya juga sangat hampir dengan rangka kerja TGI. 🎜🎜🎜🎜Sila rujuk teks asal untuk lebih banyak hasil percubaan🎜🎜
Atas ialah kandungan terperinci A800 dengan ketara mengatasi inferens Llama2 RTX3090 dan 4090, melakukan kependaman dan daya pemprosesan yang sangat baik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!