
Rumah >Tutorial sistem >LINUX >Rangkaian Neural Pilihan untuk Aplikasi kepada Data Siri Masa
Rangkaian Neural Pilihan untuk Aplikasi kepada Data Siri Masa

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-01 15:50:07890semak imbas
| Pengenalan | Artikel ini memperkenalkan secara ringkas proses pembangunan rangkaian saraf berulang RNN, dan menganalisis algoritma penurunan kecerunan, perambatan belakang dan proses LSTM. |
Dengan perkembangan sains dan teknologi serta peningkatan ketara dalam keupayaan pengkomputeran perkakasan, kecerdasan buatan tiba-tiba muncul di mata orang ramai selepas berdekad-dekad kerja di belakang tabir. Tulang belakang kecerdasan buatan datang daripada sokongan data besar, perkakasan berprestasi tinggi dan algoritma yang sangat baik. Pada tahun 2016, pembelajaran mendalam telah menjadi perkataan hangat dalam carian Google Dengan AlphaGo mengalahkan juara dunia dalam pertempuran manusia-mesin Go dalam satu atau dua tahun yang lalu, orang ramai merasakan bahawa mereka tidak dapat menahan kemajuan pesat AI. Pada tahun 2017, AI telah membuat penemuan dan produk berkaitan juga telah muncul dalam kehidupan orang ramai, seperti robot pintar, kereta tanpa pemandu dan carian suara. Baru-baru ini, Persidangan Perisikan Dunia telah berjaya diadakan di Tianjin Pada persidangan itu, ramai pakar industri dan usahawan menyatakan pandangan mereka tentang masa depan contoh, Baidu akan Semua kekayaannya adalah pada kecerdasan buatan, tidak kira sama ada dia menjadi terkenal atau gagal, selagi dia tidak mendapat apa-apa. Mengapa pembelajaran mendalam tiba-tiba memberi kesan dan kegilaan yang begitu besar? Ini kerana teknologi mengubah kehidupan, dan banyak profesion mungkin perlahan-lahan digantikan oleh kecerdasan buatan pada masa hadapan. Semua orang bercakap tentang kecerdasan buatan dan pembelajaran mendalam, malah Yann LeCun merasai populariti kecerdasan buatan di China
Berbalik kepada subjek, di sebalik kecerdasan buatan adalah data besar, algoritma yang sangat baik dan sokongan perkakasan dengan keupayaan pengkomputeran yang berkuasa. Sebagai contoh, NVIDIA menduduki tempat pertama dalam kalangan lima puluh syarikat paling pintar di dunia dengan keupayaan penyelidikan dan pembangunan perkakasan yang kukuh serta sokongan untuk rangka kerja pembelajaran mendalam. Di samping itu, terdapat banyak algoritma pembelajaran mendalam yang sangat baik, dan algoritma baharu akan muncul dari semasa ke semasa, yang benar-benar mempesonakan. Tetapi kebanyakannya diperbaiki berdasarkan algoritma klasik, seperti rangkaian neural convolutional (CNN), rangkaian kepercayaan mendalam (DBN), rangkaian saraf berulang (RNN), dll.
Artikel ini akan memperkenalkan rangkaian klasik Recurrent Neural Network (RNN), yang juga merupakan rangkaian pilihan untuk data siri masa. Apabila ia berkaitan dengan tugas pembelajaran mesin berjujukan tertentu, RNN boleh mencapai ketepatan yang sangat tinggi yang tidak dapat bersaing dengan algoritma lain. Ini kerana rangkaian neural tradisional hanya mempunyai ingatan jangka pendek, manakala RNN mempunyai kelebihan ingatan jangka pendek yang terhad. Walau bagaimanapun, rangkaian RNN generasi pertama tidak menarik banyak perhatian Ini kerana penyelidik mengalami masalah kehilangan kecerunan yang serius apabila menggunakan algoritma perambatan belakang dan turunan kecerunan, yang menghalang pembangunan RNN selama beberapa dekad. Akhirnya, satu kejayaan besar berlaku pada akhir 1990-an, membawa kepada generasi baharu RNN yang lebih tepat. Hampir dua dekad selepas membina kejayaan itu, pembangun menyempurnakan dan mengoptimumkan generasi baharu RNN, sehingga apl seperti Carian Suara Google dan Apple Siri mula merampas proses utamanya. Hari ini, rangkaian RNN tersebar di setiap bidang penyelidikan dan membantu mencetuskan kebangkitan dalam kecerdasan buatan.
Rangkaian Neural Berkaitan Lepas (RNN)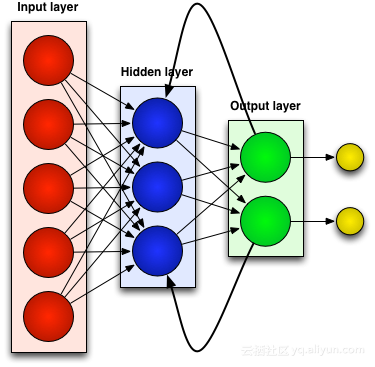
Kebanyakan rangkaian saraf tiruan, seperti rangkaian neural suapan, tidak mengingati input yang baru diterimanya. Sebagai contoh, jika rangkaian neural suapan diberi makan aksara "HIKMAH", apabila ia mencapai aksara "D", ia terlupa bahawa ia hanya membaca aksara "S", yang merupakan masalah besar. Tidak kira betapa gigihnya rangkaian itu dilatih, sukar untuk meneka watak "O" seterusnya yang paling mungkin. Ini menjadikannya calon yang agak tidak berguna untuk tugasan tertentu, seperti pengecaman pertuturan, di mana kualiti pengecaman sebahagian besarnya mendapat manfaat daripada keupayaan untuk meramal watak seterusnya. Rangkaian RNN, sebaliknya, mengingati input sebelumnya, tetapi pada tahap yang sangat canggih.
Kami memasukkan "HIKMAH" sekali lagi dan menerapkannya pada rangkaian berulang. Unit atau neuron buatan dalam rangkaian RNN apabila ia menerima "D" juga mempunyai sebagai inputnya aksara "S" yang diterimanya sebelum ini. Dalam erti kata lain, ia menggunakan peristiwa lalu digabungkan dengan peristiwa sekarang sebagai input untuk meramalkan apa yang akan berlaku seterusnya, yang memberikan kelebihan ingatan jangka pendek yang terhad. Apabila latihan, diberikan konteks yang mencukupi, boleh diagak bahawa watak seterusnya berkemungkinan besar ialah "O".
Laraskan dan Laraskan SemulaSeperti semua rangkaian saraf tiruan, unit RNN menetapkan matriks berat kepada berbilang inputnya. Pemberat ini mewakili bahagian setiap input dalam lapisan rangkaian kemudian fungsi digunakan pada pemberat ini untuk menentukan satu output secara amnya dipanggil fungsi kerugian (fungsi kos) dan mengehadkan ralat antara output sebenar dan output sasaran. Walau bagaimanapun, RNN bukan sahaja memberikan pemberat kepada input semasa, tetapi juga kepada input dari detik-detik lalu. Kemudian, pemberat yang diberikan kepada input semasa dan input masa lalu dilaraskan secara dinamik dengan meminimumkan fungsi kehilangan Proses ini melibatkan dua konsep utama: keturunan kecerunan dan perambatan belakang (BPTT).
Keturunan KecerunanSalah satu algoritma yang paling terkenal dalam pembelajaran mesin ialah algoritma penurunan kecerunan. Kelebihan utamanya ialah ia mengelakkan "kutukan dimensi" dengan ketara. Apakah "kutukan dimensi"? Ini bermakna dalam masalah pengiraan yang melibatkan vektor, apabila bilangan dimensi bertambah, jumlah pengiraan akan meningkat secara eksponen. Masalah ini melanda banyak sistem rangkaian saraf kerana terlalu banyak pembolehubah perlu dikira untuk mencapai fungsi kehilangan minimum. Walau bagaimanapun, algoritma penurunan kecerunan memecahkan kutukan dimensi dengan menguatkan ralat multidimensi atau minima setempat bagi fungsi kos. Ini membantu sistem melaraskan nilai berat yang diberikan kepada unit individu supaya rangkaian menjadi lebih tepat.
Rambatan belakang melalui masaRNN melatih unitnya dengan memperhalusi pemberatnya melalui inferens ke belakang. Ringkasnya, berdasarkan ralat antara jumlah keluaran yang dikira oleh unit dan keluaran sasaran, regresi lapisan demi lapisan terbalik dilakukan dari hujung keluaran akhir rangkaian, dan terbitan separa bagi fungsi kehilangan digunakan untuk melaraskan berat setiap unit. Ini adalah algoritma BP yang terkenal Untuk maklumat tentang algoritma BP, anda boleh membaca blog berkaitan blogger ini sebelum ini. Rangkaian RNN menggunakan versi serupa yang dipanggil backpropagation through time (BPTT). Versi ini memanjangkan proses penalaan untuk memasukkan pemberat yang bertanggungjawab untuk memori setiap unit yang sepadan dengan nilai input pada masa sebelumnya (T-1).
Yikes: masalah kecerunan yang hilang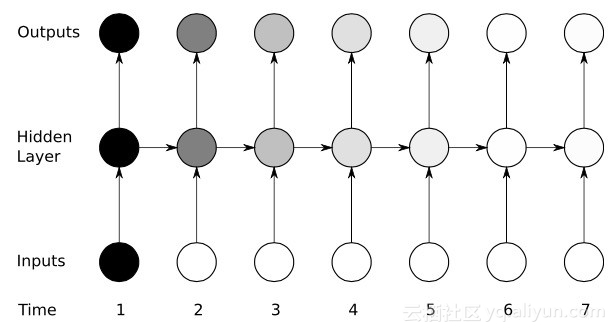
Walaupun menikmati beberapa kejayaan awal dengan bantuan algoritma penurunan kecerunan dan BPTT, banyak rangkaian saraf tiruan (termasuk rangkaian RNN generasi pertama) akhirnya mengalami kemunduran yang serius - masalah kecerunan yang semakin hilang. Apakah masalah kecerunan yang hilang Idea asas sebenarnya sangat mudah. Pertama, mari kita lihat konsep kecerunan, memikirkan kecerunan sebagai cerun. Dalam konteks melatih rangkaian saraf dalam, nilai kecerunan yang lebih besar mewakili cerun yang lebih curam, dan lebih pantas sistem boleh meluncur ke garisan penamat dan melengkapkan latihan. Tetapi di sinilah para penyelidik menghadapi masalah-latihan pantas adalah mustahil apabila cerun terlalu rata. Ini amat kritikal untuk lapisan pertama dalam rangkaian dalam, kerana jika nilai kecerunan lapisan pertama adalah sifar, ini bermakna tiada arah pelarasan dan nilai berat yang berkaitan tidak boleh diselaraskan untuk meminimumkan fungsi kehilangan ini fenomena dipanggil "penghapusan kecerunan". Apabila kecerunan semakin kecil dan semakin kecil, masa latihan akan menjadi lebih lama dan lebih lama, sama dengan gerakan linear dalam fizik, bola akan terus bergerak pada permukaan yang licin.
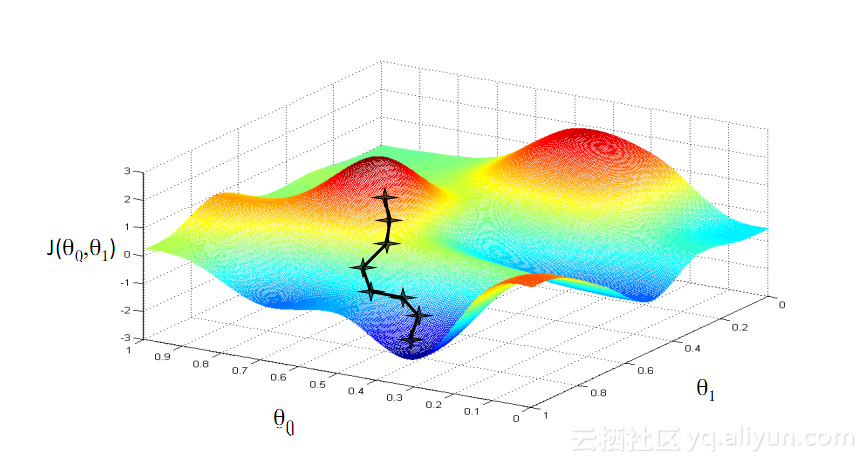
Pada penghujung 1990-an, satu kejayaan besar menyelesaikan masalah kecerunan lenyap yang disebutkan di atas, membawa ledakan penyelidikan kedua kepada pembangunan rangkaian RNN. Idea utama kejayaan besar ini ialah pengenalan unit ingatan jangka pendek panjang (LSTM).
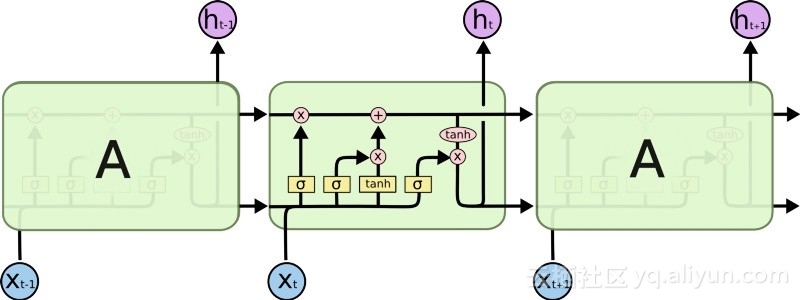
Pengenalan LSTM telah mencipta dunia yang berbeza dalam bidang AI. Ini disebabkan oleh fakta bahawa unit baharu atau neuron tiruan ini (seperti unit memori jangka pendek standard RNN) mengingati inputnya dari awal. Walau bagaimanapun, tidak seperti sel RNN standard, LSTM boleh dipasang pada ingatan mereka, yang mempunyai sifat baca/tulis serupa dengan daftar ingatan dalam komputer biasa. Selain itu, LSTM adalah analog, bukan digital, menjadikan ciri-cirinya boleh dibezakan. Dalam erti kata lain, lengkung mereka adalah berterusan dan kecuraman cerun mereka boleh didapati. Oleh itu, LSTM amat sesuai untuk kalkulus separa yang terlibat dalam perambatan belakang dan keturunan kecerunan.
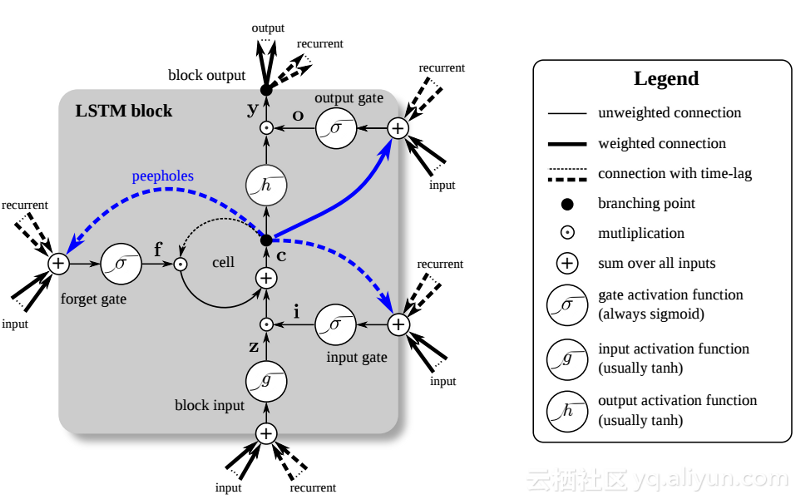
Ringkasnya, LSTM bukan sahaja boleh melaraskan beratnya, tetapi juga mengekalkan, memadam, mengubah dan mengawal aliran masuk dan keluar data yang disimpan berdasarkan kecerunan latihan. Paling penting, LSTM boleh mengekalkan maklumat ralat penting untuk masa yang lama supaya kecerunannya agak curam dan dengan itu masa latihan rangkaian agak singkat. Ini menyelesaikan masalah kecerunan lenyap dan meningkatkan ketepatan rangkaian RNN berasaskan LSTM hari ini. Disebabkan oleh peningkatan ketara dalam seni bina RNN, Google, Apple dan banyak syarikat maju lain kini menggunakan RNN untuk menggerakkan aplikasi di tengah-tengah perniagaan mereka.
RingkasanRangkaian Neural Berulang (RNN) boleh mengingati input terdahulu mereka, memberikan mereka kelebihan yang lebih besar daripada rangkaian saraf tiruan lain apabila ia melibatkan tugas berterusan yang sensitif konteks seperti pengecaman pertuturan.
Mengenai sejarah pembangunan rangkaian RNN: Generasi pertama RNN mencapai keupayaan untuk membetulkan ralat melalui perambatan belakang dan algoritma keturunan kecerunan. Walau bagaimanapun, masalah kecerunan yang lenyap menghalang pembangunan RNN sehingga tahun 1997 barulah kejayaan besar dicapai selepas pengenalan seni bina berasaskan LSTM.
Kaedah baharu ini dengan berkesan menjadikan setiap unit dalam rangkaian RNN menjadi komputer analog, meningkatkan ketepatan rangkaian.
Maklumat pengarang
Jason Roell: Jurutera perisian dengan semangat untuk pembelajaran mendalam dan aplikasinya kepada teknologi transformatif.
Linkedin: http://www.linkedin.com/in/jason-roell-47830817/
Atas ialah kandungan terperinci Rangkaian Neural Pilihan untuk Aplikasi kepada Data Siri Masa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!