Tujuan Penyesuaian Masa Ujian adalah untuk menyesuaikan model domain sumber kepada data ujian dalam fasa inferens, dan telah mencapai keputusan cemerlang dalam menyesuaikan diri dengan medan kerosakan imej yang tidak diketahui. Walau bagaimanapun, banyak kaedah semasa tidak mengambil kira aliran data ujian dalam senario dunia sebenar, contohnya:
- Aliran data ujian hendaklah merupakan pengedaran yang berbeza-beza masa (bukannya pengedaran tetap dalam penyesuaian domain tradisional)
- Aliran data ujian mungkin mempunyai korelasi kelas tempatan (bukannya persampelan bebas sepenuhnya dan teragih sama)
- Strim data ujian masih menunjukkan ketidakseimbangan kelas global untuk masa yang lama
, Universiti Teknologi China Selatan, Pasukan A*STAR dan CUHK-Shenzhen telah membuktikan melalui eksperimen yang meluas bahawa aliran data ujian dalam senario kehidupan sebenar ini akan menimbulkan cabaran besar kepada kaedah sedia ada. Pasukan ini percaya bahawa kegagalan kaedah tercanggih pertama kali disebabkan oleh pelarasan lapisan normalisasi secara sembarangan berdasarkan data ujian yang tidak seimbang.
Untuk tujuan ini, pasukan penyelidik
mencadangkan Lapisan BatchNorm Seimbang yang inovatif untuk menggantikan lapisan normalisasi kelompok konvensional dalam peringkat inferens. Pada masa yang sama, mereka mendapati bahawa bergantung semata-mata pada latihan kendiri (ST) untuk belajar dalam aliran data ujian yang tidak diketahui dengan mudah boleh membawa kepada penyesuaian yang berlebihan (ketidakseimbangan kategori pseudo-label, domain sasaran bukan domain tetap), mengakibatkan kelemahan prestasi dalam domain yang berubah-ubah.
Oleh itu, pasukan mengesyorkan  melaraskan kemas kini model melalui kerugian berlabuh (Anchored Loss)
melaraskan kemas kini model melalui kerugian berlabuh (Anchored Loss)
, dengan itu meningkatkan latihan kendiri di bawah pemindahan domain berterusan dan membantu meningkatkan keteguhan model dengan ketara. Pada akhirnya, model TRIBE secara stabil mencapai prestasi terkini di bawah empat set data dan berbilang tetapan aliran data ujian dunia sebenar, dan dengan ketara mengatasi kaedah lanjutan sedia ada. Kertas penyelidikan telah diterima oleh AAI 2024.
Pautan kertas: https://arxiv.org/abs/2309.14949
Pautan kod: https://github.com/Gorilla-Lab-SCUT/TRIBE
p
Pengenalan
Kejayaan rangkaian saraf bergantung pada generalisasi model terlatih kepada i.i.d andaian dalam domain ujian. Walau bagaimanapun, dalam aplikasi praktikal, keteguhan data ujian luar pengedaran, seperti kerosakan visual yang disebabkan oleh keadaan pencahayaan yang berbeza atau cuaca buruk, adalah kebimbangan. Penyelidikan terkini menunjukkan bahawa kehilangan data ini boleh menjejaskan prestasi model pra-latihan secara serius. Yang penting, rasuah (pengedaran) data ujian selalunya tidak diketahui dan kadangkala tidak dapat diramalkan sebelum digunakan.
Oleh itu, melaraskan model pra-latihan untuk menyesuaikan diri dengan pengedaran data ujian dalam fasa inferens adalah topik baharu yang berharga, iaitu penyesuaian domain masa ujian (TTA). Sebelum ini, TTA dilaksanakan terutamanya melalui penjajaran pengedaran (TTAC++, TTT++), latihan penyeliaan kendiri (AdaContrast) dan latihan kendiri (Conjugate PL), yang telah membawa peningkatan ketara dan mantap dalam pelbagai data ujian kerosakan visual.
Kaedah penyesuaian domain masa ujian (TTA) sedia ada biasanya berdasarkan beberapa andaian data ujian yang ketat, seperti pengedaran kelas yang stabil, sampel mematuhi pensampelan bebas dan teragih sama, dan mengimbangi domain tetap. Andaian ini telah memberi inspirasi kepada ramai penyelidik untuk meneroka aliran data ujian dunia sebenar, seperti CoTTA, NOTE, SAR dan RoTTA.
Baru-baru ini, penyelidikan TTA dunia sebenar, seperti SAR (ICLR 2023) dan RoTTA (CVPR 2023), tertumpu terutamanya pada cabaran yang ditimbulkan oleh ketidakseimbangan kelas tempatan dan peralihan domain yang berterusan kepada TTA. Ketidakseimbangan kelas tempatan biasanya berpunca daripada fakta bahawa data ujian tidak disampel secara bebas dan diedarkan secara identik. Penyesuaian domain tanpa pandang bulu secara langsung akan membawa kepada anggaran pengedaran yang berat sebelah.
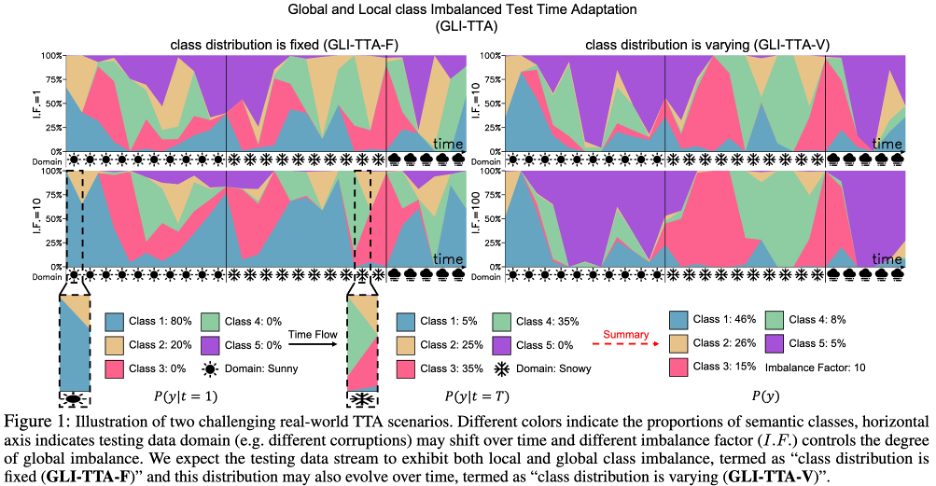 Penyelidikan terkini telah mencadangkan statistik ternormal kelompok (RoTTA) yang dikemas kini secara eksponen atau statistik ternormal kelompok yang dikemas kini secara diskriminatif (NOTA) untuk menyelesaikan cabaran ini. Matlamat penyelidikan adalah untuk mengatasi cabaran ketidakseimbangan kelas tempatan, memandangkan pengagihan keseluruhan data ujian boleh menjadi sangat tidak seimbang dan pengagihan kelas juga boleh berubah dari semasa ke semasa. Gambar rajah senario yang lebih mencabar boleh dilihat dalam Rajah 1 di bawah.
Penyelidikan terkini telah mencadangkan statistik ternormal kelompok (RoTTA) yang dikemas kini secara eksponen atau statistik ternormal kelompok yang dikemas kini secara diskriminatif (NOTA) untuk menyelesaikan cabaran ini. Matlamat penyelidikan adalah untuk mengatasi cabaran ketidakseimbangan kelas tempatan, memandangkan pengagihan keseluruhan data ujian boleh menjadi sangat tidak seimbang dan pengagihan kelas juga boleh berubah dari semasa ke semasa. Gambar rajah senario yang lebih mencabar boleh dilihat dalam Rajah 1 di bawah.
🎜🎜🎜
Memandangkan kelaziman kelas dalam data ujian tidak diketahui sebelum peringkat inferens, dan model mungkin berat sebelah terhadap kelas majoriti melalui pelarasan masa ujian buta, ini menjadikan kaedah TTA sedia ada tidak berkesan. Berdasarkan pemerhatian empirikal, masalah ini menjadi sangat ketara untuk kaedah yang bergantung pada kumpulan data semasa untuk menganggarkan statistik global untuk mengemas kini lapisan normalisasi (BN, PL, TENT, CoTTA, dll.). Ini terutamanya disebabkan oleh: 1 Kumpulan data semasa akan dipengaruhi oleh ketidakseimbangan kelas tempatan, mengakibatkan anggaran pengedaran yang berat sebelah 2 Tanpa satu pengedaran global, pengedaran global dengan mudah boleh berat sebelah ke arah kelas majoriti, yang membawa kepada anjakan kovariat dalaman. Untuk mengelakkan normalisasi kelompok berat sebelah (BN), pasukan mencadangkan lapisan normalisasi kelompok seimbang (Lapisan Normalisasi Kelompok Seimbang), yang memodelkan pengedaran setiap kategori individu dan mengekstrak pengedaran global daripada pengedaran kelas. Lapisan penormalan kelompok seimbang membolehkan mendapatkan anggaran seimbang kelas bagi pengagihan di bawah aliran data ujian tidak seimbang kelas tempatan dan global. Peralihan domain kerap berlaku dalam data ujian dunia sebenar dari semasa ke semasa, seperti perubahan beransur-ansur dalam keadaan pencahayaan/cuaca. Ini membawa satu lagi cabaran kepada kaedah TTA sedia ada, model TTA mungkin menjadi tidak konsisten apabila beralih daripada domain A ke domain B disebabkan penyesuaian yang berlebihan kepada domain A.
Untuk mengurangkan penyesuaian berlebihan kepada domain jangka pendek tertentu, CoTTA memulihkan parameter secara rawak dan EATA menggunakan maklumat fisher untuk mengatur parameter. Namun begitu, kaedah ini masih tidak menangani secara jelas cabaran yang timbul dalam bidang data ujian.
Artikel ini memperkenalkan rangkaian anchor (Anchor Network) untuk membentuk model latihan kendiri tiga rangkaian (Tri-Net Self-Training) berdasarkan seni bina latihan kendiri dua cabang. Rangkaian sauh ialah model sumber beku tetapi membenarkan statistik penalaan dan bukannya parameter dalam lapisan normalisasi kelompok melalui sampel ujian. Dan kerugian berlabuh dicadangkan untuk menggunakan output rangkaian sauh untuk menyelaraskan output model guru untuk mengelakkan rangkaian daripada terlalu menyesuaikan diri dengan pengedaran tempatan.
Model akhir menggabungkan model latihan kendiri tiga bersih dan lapisan normalisasi kelompok seimbang (latihan kendiri TRI-net dengan normalisasi BalancEd, TRIBE) untuk menunjukkan prestasi unggul yang konsisten dalam julat kadar pembelajaran boleh laras yang lebih luas. Ia menunjukkan peningkatan prestasi yang ketara di bawah empat set data dan berbilang aliran data dunia nyata, menunjukkan kestabilan dan keteguhan yang unik.
Kaedah kertas terbahagi kepada tiga bahagian:
- Pengenalan kepada protokol TTA
penormalan - ;
Tiga rangkaian automatik Latih model.
Protokol TTA di dunia nyata
Pengarang menggunakan model kebarangkalian matematik dan kebarangkalian kelas dunia yang tidak seimbang dalam aliran data dunia dan tempatan pengedaran mengikut masa dimodelkan. Seperti yang ditunjukkan dalam Rajah 2 di bawah. 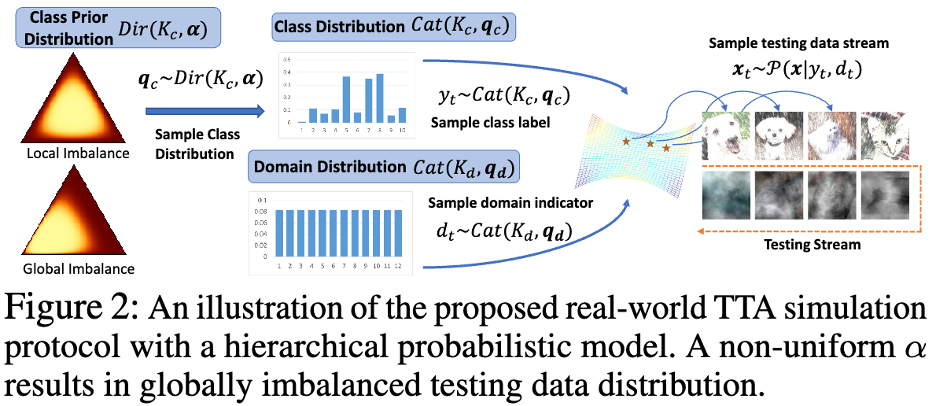
Balanced Batch Normalization
Untuk membetulkan anggaran bias yang dihasilkan oleh data ujian tidak seimbang pada statistik BN, penulis mencadangkan pengekalan kumpulan normalisasi lapisan seimbang bagi setiap lapisan semantik semantik masing-masing, diwakili sebagai: 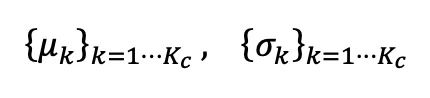 Untuk mengemas kini statistik kategori, pengarang menggunakan kaedah kemas kini berulang yang cekap dengan bantuan ramalan pseudo-label, seperti ditunjukkan di bawah:
Untuk mengemas kini statistik kategori, pengarang menggunakan kaedah kemas kini berulang yang cekap dengan bantuan ramalan pseudo-label, seperti ditunjukkan di bawah:
Titik pensampelan setiap kategori data dikira secara berasingan melalui label pseudo, dan statistik pengedaran keseluruhan di bawah imbangan kategori diperoleh semula melalui formula berikut, untuk menjajarkan ruang ciri yang dipelajari dengan data sumber seimbang kategori . 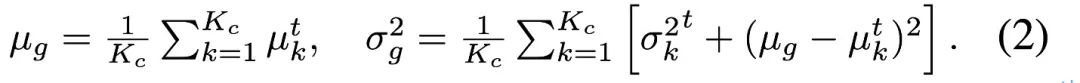 Dalam beberapa kes khas, penulis mendapati bahawa apabila bilangan kategori adalah besar
Dalam beberapa kes khas, penulis mendapati bahawa apabila bilangan kategori adalah besar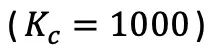 atau ketepatan pseudo-label adalah rendah (ketepatan
atau ketepatan pseudo-label adalah rendah (ketepatan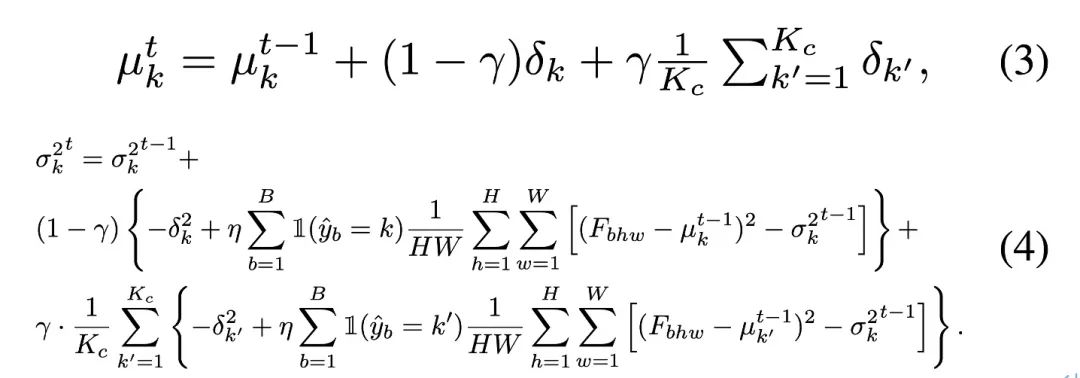
Melalui analisis dan pemerhatian lanjut, penulis mendapati bahawa apabila γ=1, keseluruhan kemas kini strategi merosot kepada RoTTA Strategi kemas kini RobustBN dalam , apabila γ=0, adalah strategi kemas kini bebas kategori semata-mata Oleh itu, apabila γ mengambil nilai 0 hingga 1, ia boleh disesuaikan dengan pelbagai situasi. Model latihan kendiri tiga rangkaianBerdasarkan model pelajar-guru sedia ada, penulis menambah cawangan rangkaian penambat dan memperkenalkan rangkaian pengagihan penambat untuk meramalkan kehilangan guru. Reka bentuk ini diinspirasikan oleh TTAC++. TTAC++ menunjukkan bahawa bergantung semata-mata pada latihan kendiri pada aliran data ujian dengan mudah akan membawa kepada pengumpulan bias pengesahan Masalah ini lebih serius pada aliran data ujian dunia dalam artikel ini. TTAC++ menggunakan maklumat statistik yang dikumpul daripada domain sumber untuk melaksanakan penyelarasan penjajaran domain, tetapi untuk tetapan TTA Penuh, maklumat domain sumber ini tidak boleh dikumpulkan. Pada masa yang sama, penulis juga mendapat satu lagi pendedahan Kejayaan penjajaran domain tanpa pengawasan adalah berdasarkan andaian bahawa kedua-dua pengagihan domain mempunyai kadar pertindihan yang agak tinggi. Oleh itu, penulis hanya melaraskan model domain sumber beku bagi statistik BN untuk menyelaraskan model guru bagi mengelakkan pengedaran ramalan model guru menyimpang terlalu jauh daripada pengedaran ramalan model sumber (ini memusnahkan pengalaman kadar kebetulan yang tinggi sebelum ini antara kedua-dua pengedaran) pemerhatian). Sebilangan besar eksperimen membuktikan bahawa penemuan dan inovasi dalam artikel ini adalah betul dan kukuh. Berikut ialah ungkapan kehilangan berlabuh: 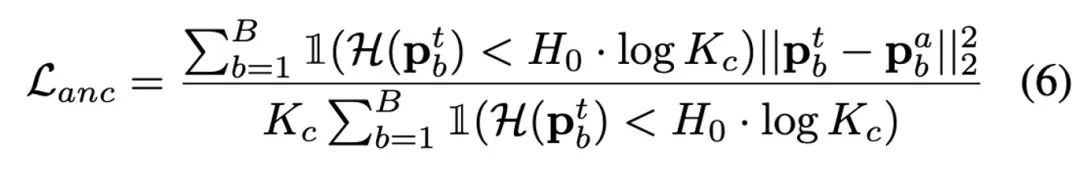
Rajah berikut menunjukkan gambar rajah bingkai rangkaian TRIBE:
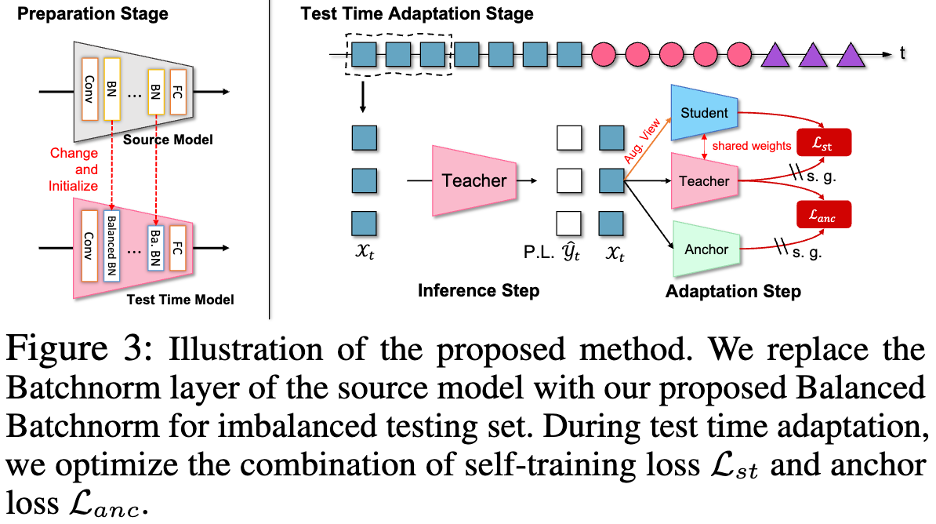
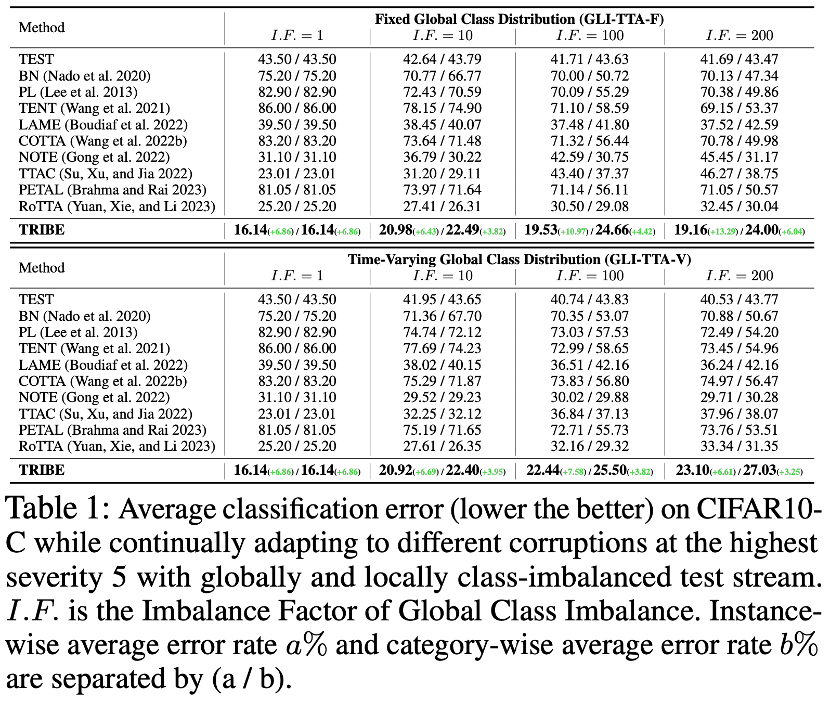
🎜🎜 data yang digunakan set kepada TRIBE disahkan menggunakan dua protokol TTA dunia sebenar sebagai penanda aras. Dua protokol TTA dunia sebenar ialah GLI-TTA-F di mana pengedaran kelas global adalah tetap dan GLI-TTA-V di mana pengedaran kelas global tidak tetap. 🎜🎜🎜🎜Jadual di atas menunjukkan prestasi dua protokol dalam set data CIFAR10-C di bawah pekali ketidakseimbangan yang berbeza Kesimpulan berikut boleh dibuat: 1 Hanya LAME, TTAC, NOT, RoTTA dan TRIBE yang dicadangkan dalam kertas itu melebihi garis dasar TEST, menunjukkan keperluan kaedah TTA yang lebih mantap, di bawah aliran ujian sebenar. 2. Ketidakseimbangan kelas global telah membawa cabaran besar kepada kaedah TTA sedia ada Contohnya, kaedah SOTA RoTTA sebelum ini menunjukkan kadar ralat sebanyak 25.20% apabila I.F.=1, tetapi kadar ralat meningkat kepada 25.20% apabila I.F.=. 200. 32.45%, sebagai perbandingan, TRIBE boleh menunjukkan prestasi yang lebih baik secara stabil. 3 Konsistensi TRIBE mempunyai kelebihan mutlak, mengatasi semua kaedah sebelumnya, dan mengatasi SOTA (TTAC) sebelumnya sebanyak kira-kira 7% dalam penetapan keseimbangan kelas global (I.F.=1), dan lebih banyak lagi. sukar Di bawah penetapan ketidakseimbangan kelas global (I.F.=200), kira-kira 13% peningkatan prestasi telah dicapai. 4. Dari I.F.=10 hingga I.F.=200, kaedah TTA lain menunjukkan trend penurunan prestasi apabila tahap ketidakseimbangan meningkat. TRIBE boleh mengekalkan prestasi yang agak stabil. Ini disebabkan oleh pengenalan lapisan normalisasi kelompok seimbang yang lebih baik menyumbang kepada ketidakseimbangan kelas yang teruk dan kerugian berlabuh, yang mengelakkan penyesuaian berlebihan merentas domain yang berbeza. Untuk lebih banyak keputusan set data, sila rujuk kertas asal. Selain itu, Jadual 4 menunjukkan ablasi modular terperinci, dengan kesimpulan pemerhatian berikut: 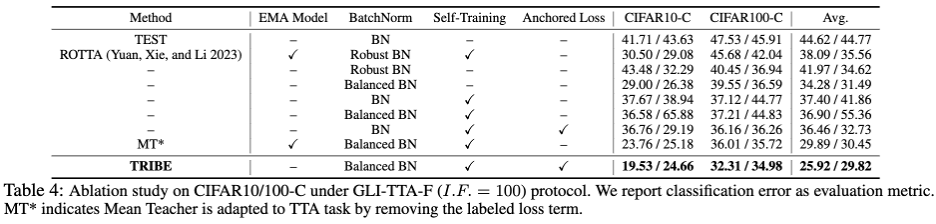
1 Hanya gantikan BN dengan lapisan normalisasi kelompok seimbang (BN Seimbang), tanpa mengemas kini Bagi mana-mana parameter model, hanya mengemas kini statistik BN ke hadapan boleh membawa peningkatan prestasi sebanyak 10.24% (44.62 -> 34.28), dan melepasi kadar ralat BN Teguh sebanyak 41.97%. 2. Kerugian Berlabuh digabungkan dengan Latihan Kendiri, sama ada di bawah struktur BN sebelumnya atau struktur BN Seimbang terkini, telah meningkatkan prestasi dan melepasi kesan regularisasi Model EMA. Selebihnya artikel ini dan lampiran 9 muka surat akhirnya membentangkan 17 keputusan jadual terperinci, menunjukkan kestabilan, keteguhan dan keunggulan TRIBE dari pelbagai dimensi. Lampiran juga mengandungi terbitan teori yang lebih terperinci dan penjelasan tentang lapisan normalisasi kelompok seimbang. Untuk menangani banyak cabaran dunia nyata seperti aliran data ujian bukan i.i.d, ketidakseimbangan kelas global dan pemindahan domain secara berterusan untuk meningkatkan ujian Kekukuhan algoritma penyesuaian domain masa. Untuk menyesuaikan diri dengan data ujian yang tidak seimbang, penulis mencadangkan Lapisan Batchnorm Seimbang untuk mencapai anggaran statistik yang tidak berat sebelah, dan kemudian mencadangkan rangkaian yang merangkumi rangkaian pelajar, rangkaian guru dan struktur rangkaian tiga lapisan untuk diseragamkan TTA berdasarkan latihan kendiri. Tetapi artikel ini masih mempunyai kekurangan dan ruang untuk penambahbaikan Memandangkan sebilangan besar percubaan dan titik permulaan adalah berdasarkan tugas klasifikasi dan modul BN, tahap penyesuaian kepada tugas lain dan model berasaskan Transformer masih tidak diketahui. Isu-isu ini memerlukan penyelidikan dan penerokaan lanjut dalam kerja susulan.
Atas ialah kandungan terperinci TRIBE mencapai keteguhan penyesuaian domain dan mencapai AAAII 2024 SOTA dalam pelbagai senario kehidupan sebenar.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

