
Rumah >Tutorial sistem >LINUX >Evolusi sejarah pengaturcaraan Python
Evolusi sejarah pengaturcaraan Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-01 09:31:11585semak imbas
| Pengenalan | Sebaik sahaja anda memulakan pengaturcaraan, jika anda tidak mengetahui masalah pengekodan, ia akan menghantui anda seperti hantu sepanjang kerjaya anda, dan pelbagai peristiwa ghaib akan mengikuti satu demi satu dan berlarutan. Hanya dengan memberikan permainan penuh kepada semangat pengaturcara untuk berjuang hingga ke akhirnya anda boleh menyingkirkan sepenuhnya masalah yang disebabkan oleh masalah pengekodan. |
Kali pertama saya menghadapi masalah pengekodan ialah semasa saya menulis projek berkaitan JavaWeb Rentetan aksara yang tersasar dari penyemak imbas ke dalam kod aplikasi, dan membenamkan dirinya dalam pangkalan data di mana-mana sahaja. Kali kedua saya menghadapi masalah pengekodan ketika saya sedang belajar Python Semasa merangkak data halaman web, masalah pengekodan muncul semula .
Untuk memahami pengekodan aksara, kita perlu bermula dari asal komputer Semua data dalam komputer, sama ada teks, gambar, video atau fail audio, pada asasnya disimpan dalam bentuk digital yang serupa dengan 01010101. Kami bertuah, dan kami juga bernasib baik, zaman telah memberi kami peluang untuk berhubung dengan komputer Malangnya, komputer tidak dicipta oleh rakyat negara kita, jadi standard komputer mesti direka mengikut kebiasaan orang. Empayar Amerika Jadi pada akhirnya Bagaimanakah komputer pertama kali mewakili aksara? Ini bermula dengan sejarah pengekodan komputer.
ASCIISetiap orang baru yang melakukan pembangunan JavaWeb akan menghadapi masalah kod bercelaru, dan setiap orang baru yang melakukan perangkak Python akan menghadapi masalah pengekodan Mengapa masalah pengekodan sangat menyakitkan? Masalah ini bermula apabila Guido van Rossum mencipta bahasa Python pada tahun 1992. Pada masa itu, Guido tidak pernah menjangkakan bahawa bahasa Python akan menjadi begitu popular pada hari ini, dan tidak menjangkakan bahawa kelajuan pembangunan komputer akan menjadi begitu menakjubkan. Guido tidak perlu mengambil berat tentang pengekodan apabila dia mula-mula mereka bentuk bahasa ini, kerana dalam dunia Inggeris, bilangan aksara adalah sangat terhad, 26 huruf (huruf besar dan kecil), 10 nombor, tanda baca, dan aksara kawalan, iaitu. , pada papan kekunci Aksara yang sepadan dengan semua kekunci menambah sehingga lebih seratus aksara. Ini lebih daripada cukup untuk menggunakan satu bait ruang storan untuk mewakili satu aksara dalam komputer, kerana satu bait bersamaan dengan 8 bit, dan 8 bit boleh mewakili 256 simbol. Oleh itu, orang Amerika yang pintar membangunkan satu set piawaian pengekodan aksara yang dipanggil ASCII (Kod Standard Amerika untuk Pertukaran Maklumat Setiap aksara sepadan dengan nombor unik Sebagai contoh, nilai perduaan yang sepadan dengan aksara A ialah 01000001, dan nilai perpuluhan yang sepadan ialah 65 . Pada mulanya, ASCII hanya mentakrifkan 128 kod aksara, termasuk 96 teks dan 32 simbol kawalan, sejumlah 128 aksara Hanya 7 bit satu bait diperlukan untuk mewakili semua aksara, jadi ASCII hanya menggunakan satu bait yang terakhir bit tertinggi semuanya 0.
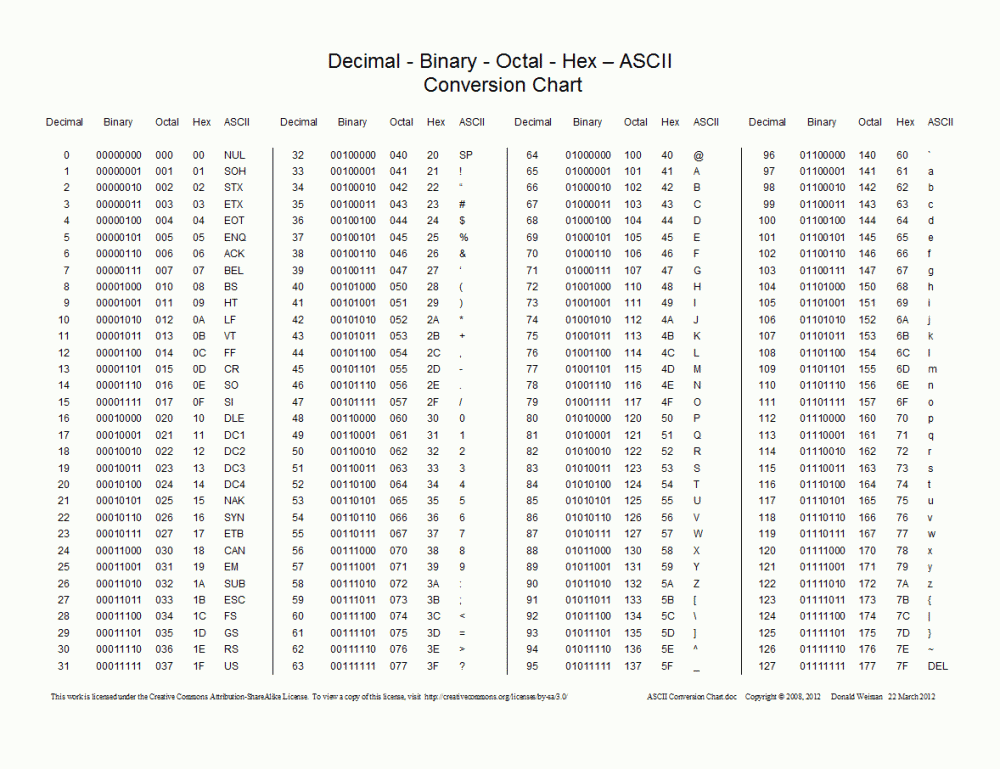
Walau bagaimanapun, apabila komputer perlahan-lahan merebak ke kawasan Eropah Barat yang lain, mereka mendapati bahawa terdapat banyak aksara unik untuk Eropah Barat yang tidak terdapat dalam jadual pengekodan ASCII, jadi ASCII yang boleh diperluaskan yang dipanggil EASCII kemudiannya muncul Seperti namanya, ia berdasarkan pada ASCII Dilanjutkan daripada 7 bit kepada 8 bit, ia serasi sepenuhnya dengan ASCII Simbol lanjutan termasuk simbol jadual, simbol pengiraan, huruf Yunani dan simbol Latin khas. Walau bagaimanapun, era EASCII adalah era yang huru-hara Tidak ada piawaian bersatu Mereka masing-masing menggunakan piawaian pengekodan watak mereka sendiri mengikut piawaian mereka sendiri digunakan dalam sistem Windows, seperti yang ditunjukkan di bawah:
Satu lagi EASCII yang digunakan secara meluas ialah  ISO/8859-1 (Latin-1)
ISO/8859-1 (Latin-1)
, iaitu satu siri piawaian set aksara 8-bit yang dibangunkan bersama oleh International Organization for Standardization (ISO) dan International Electrotechnical Commission (IEC), ISO /8859-1 hanya mewarisi aksara antara 128-159 pengekodan aksara CP437, jadi ia ditakrifkan bermula dari 160. Malangnya, banyak set aksara lanjutan ASCII ini tidak serasi antara satu sama lain.
GBK
Dengan kemajuan zaman, komputer telah mula merebak ke beribu-ribu isi rumah, Bill Gates menjadikan impian semua orang mempunyai komputer pada desktop mereka menjadi kenyataan. Walau bagaimanapun, satu masalah yang perlu dihadapi oleh komputer apabila memasuki China ialah pengekodan aksara Walaupun aksara Cina di negara kita adalah aksara yang paling kerap digunakan oleh manusia, aksara Cina adalah luas dan mendalam, dan terdapat berpuluh-puluh ribu aksara Cina yang biasa. jauh melebihi apa yang boleh diwakili oleh pengekodan ASCII, malah EASCII kelihatan seperti penurunan dalam baldi, jadi orang Cina pintar membuat set kod mereka sendiri yang dipanggil GB2312, juga dikenali sebagai GB0, yang dikeluarkan oleh Pentadbiran Standard Negeri. China pada tahun 1981. Pengekodan GB2312 mengandungi sejumlah 6763 aksara Cina, dan ia juga serasi dengan ASCII. Kemunculan GB2312 pada asasnya memenuhi keperluan pemprosesan komputer bagi aksara Cina. Walau bagaimanapun, GB2312 masih tidak dapat memenuhi keperluan aksara Cina 100% GB2312 tidak dapat mengendalikan beberapa aksara jarang dan aksara tradisional Kemudian, kod yang dipanggil GBK telah dibuat berdasarkan GB2312. GBK bukan sahaja mengandungi 27,484 aksara Cina, tetapi juga bahasa etnik minoriti utama seperti Tibet, Mongolia, dan Uyghur. Begitu juga, GBK juga serasi dengan pengekodan ASCII aksara Inggeris diwakili oleh 1 bait, dan aksara Cina diwakili oleh dua bait.
UnicodeKami boleh menyediakan puncak gunung yang berasingan untuk menangani aksara Cina dan membangunkan satu set piawaian pengekodan mengikut keperluan kami sendiri Walau bagaimanapun, komputer bukan sahaja digunakan oleh orang Amerika dan Cina, tetapi juga menggunakan aksara dari negara lain di Eropah dan Asia. seperti bahasa Jepun, Dianggarkan terdapat ratusan ribu aksara Korea dari seluruh dunia, yang jauh melebihi julat yang boleh diwakili oleh kod ASCII atau GBK Selain itu, mengapa orang menggunakan standard GBK anda? Bagaimana untuk menyatakan perpustakaan watak yang begitu besar? Jadi United Alliance International Organization mencadangkan pengekodan Unicode Nama saintifik Unicode ialah "Set Aksara Berkod Berbilang Oktet", dirujuk sebagai UCS.

Unicode mempunyai dua format: UCS-2 dan UCS-4. UCS-2 menggunakan dua bait untuk mengekod, dengan jumlah 16 bit Secara teori, ia boleh mewakili sehingga 65536 aksara Walau bagaimanapun, untuk mewakili semua aksara di dunia, 65536 nombor jelas tidak mencukupi, kerana terdapat hampir 65536. aksara dalam aksara Cina sahaja.
Unicode secara teorinya boleh merangkumi simbol yang digunakan dalam semua bahasa. Mana-mana aksara di dunia boleh diwakili oleh pengekodan Unikod Setelah pengekodan Unikod aksara ditentukan, ia tidak akan berubah. Walau bagaimanapun, Unicode mempunyai had tertentu Apabila aksara Unicode dihantar pada rangkaian atau akhirnya disimpan, ia tidak semestinya memerlukan dua bait untuk setiap aksara Contohnya, satu aksara "A" boleh diwakili oleh satu bait dua bait, yang jelas membazir ruang. Masalah kedua ialah apabila aksara Unicode disimpan dalam komputer, ia adalah rentetan nombor 01 Jadi bagaimanakah komputer mengetahui sama ada aksara Unicode 2-bait mewakili aksara 2-bait atau dua aksara 1-bait? jika anda tidak memberitahu komputer terlebih dahulu, komputer juga akan keliru. Unicode hanya menetapkan cara mengekod, tetapi tidak menyatakan cara menghantar atau menyimpan pengekodan ini. Contohnya, pengekodan Unikod bagi aksara "汉" ialah 6C49 Saya boleh menggunakan 4 nombor ASCII untuk menghantar dan menyimpan pengekodan ini Saya juga boleh menggunakan 3 bait E6 B1 89 yang dikodkan dalam UTF-8 untuk mewakilinya. Perkara utama ialah kedua-dua pihak dalam komunikasi mesti bersetuju. Oleh itu, pengekodan Unicode mempunyai kaedah pelaksanaan yang berbeza, seperti: UTF-8, UTF-16, dsb. Unicode di sini sama seperti Bahasa Inggeris Ia adalah standard universal untuk komunikasi antara negara Setiap negara mempunyai bahasa sendiri Mereka menterjemah dokumen bahasa Inggeris ke dalam teks negara mereka sendiri.
UTF-8 (Format Transformasi Unikod), sebagai pelaksanaan Unicode, digunakan secara meluas di Internet Ia adalah pengekodan aksara panjang boleh ubah yang boleh menggunakan 1-4 bait untuk mewakili aksara bergantung pada situasi tertentu. Sebagai contoh, aksara Inggeris yang pada asalnya boleh dinyatakan dalam kod ASCII hanya memerlukan satu bait ruang apabila dinyatakan dalam UTF-8, yang sama dengan ASCII. Untuk aksara berbilang bait (n bait), n bit pertama bait pertama ditetapkan kepada 1, n+1 bit ditetapkan kepada 0 dan dua bit pertama bait berikut ditetapkan kepada 10. Digit perduaan yang tinggal diisi dengan kod UNICODE aksara.
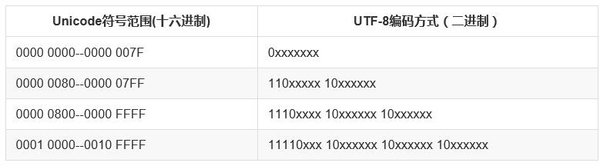
Ambil aksara Cina "好" sebagai contoh Unicode yang sepadan dengan "好" ialah 597D, dan selang yang sepadan ialah 0000 0800 -- 0000 FFFF Oleh itu, apabila ia dinyatakan dalam UTF-8, ia memerlukan 3 bait untuk disimpan . 597D dinyatakan dalam perduaan. : 0101100101111101, isikan kepada 1110xxxx 10xxxxxx 10xxxxxx untuk mendapatkan 11100101 10100101 10111101, ditukarkan kepada "United"5BD8 yang sepadan, jadi kod UTF58 yang sepadan: "E5A5BD".
unicode 0101 100101 111101
Peraturan pengekodan 1110xxxx 10xxxxxx 10xxxxxx
--------------------------
utf-8 11100101 10100101 10111101
--------------------------
Perenambelasan utf-8 e 5 a 5 b d Pengekodan aksara Python
Sekarang saya akhirnya menyelesaikan teori. Mari kita bincangkan tentang isu pengekodan dalam Python. Python dilahirkan lebih awal daripada Unicode, dan pengekodan lalai Python ialah ASCII.
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
Oleh itu, jika anda tidak menyatakan pengekodan secara eksplisit dalam fail kod sumber Python, ralat sintaks akan berlaku
#test.py
cetak "Hello"
Di atas ialah skrip test.py, jalankan
python test.py
Ralat berikut akan disertakan:
File “test.py”, line 1 yntaxError: Non-ASCII character ‘/xe4′ in file test.py on line 1, but no encoding declared;
Untuk menyokong aksara bukan ASCII dalam kod sumber, format pengekodan mesti dinyatakan secara eksplisit pada baris pertama atau kedua fail sumber:
# coding=utf-8
atau:
#!/usr/bin/python # -*- coding: utf-8 -*-
Jenis data yang berkaitan dengan rentetan dalam Python ialah str dan unicode kedua-duanya adalah subkelas basestring Ia boleh dilihat bahawa str dan unicode ialah dua jenis objek rentetan.
basestring
/ /
/ /
str unicode
Untuk aksara Cina yang sama "好", apabila dinyatakan dalam str, ia sepadan dengan pengekodan UTF-8 '/xe5/xa5/xbd', dan apabila dinyatakan dalam Unicode, simbol sepadannya ialah u'/u597d' , bersamaan dengan anda "baik". Perlu ditambahkan bahawa format pengekodan khusus bagi aksara jenis str ialah UTF-8, GBK atau format lain, bergantung pada sistem pengendalian. Contohnya, dalam sistem Windows, baris arahan cmd memaparkan:
# windows终端 >>> a = '好' >>> type(a) <type 'str'> >>> a '/xba/xc3'
Dan apa yang dipaparkan dalam baris arahan sistem Linux ialah:
# linux终端 >>> a='好' >>> type(a) <type 'str'> >>> a '/xe5/xa5/xbd' >>> b=u'好' >>> type(b) <type 'unicode'> >>> b u'/u597d'
Sama ada Python3x, Java atau bahasa pengaturcaraan lain, pengekodan Unicode telah menjadi format pengekodan lalai bahasa tersebut Apabila data akhirnya disimpan ke media, media yang berbeza boleh menggunakan kaedah yang berbeza. dan beberapa Tidak mengapa jika orang suka menggunakan GBK, selagi platform itu mempunyai standard pengekodan bersatu, tidak kira bagaimana ia dilaksanakan.
Jadi bagaimana untuk menukar antara str dan unicode dalam Python? Penukaran antara dua jenis jenis rentetan ini bergantung pada dua kaedah ini: nyahkod dan mengekod.
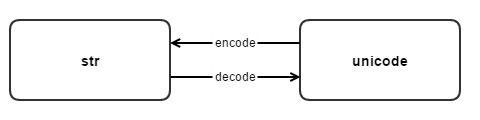
#从str类型转换到unicode
s.decode(encoding) =====> <type 'str'> to <type 'unicode'>
#从unicode转换到str
u.encode(encoding) =====> <type 'unicode'> to <type 'str'>
>>> c = b.encode('utf-8')
>>> type(c)
<type 'str'>
>>> c
'/xe5/xa5/xbd'
>>> d = c.decode('utf-8')
>>> type(d)
<type 'unicode'>
>>> d
u'/u597d'
Ini'/xe5/xa5/xbd' ialah rentetan jenis str yang dikodkan UTF-8 yang dikodkan oleh Unicode u'ha' melalui pengekodan fungsi. Sebaliknya, str jenis c dinyahkodkan ke dalam rentetan Unikod d melalui penyahkodan fungsi.
str(s) lwn. unicode(s)str(s) dan unicode(s) ialah dua kaedah kilang yang masing-masing mengembalikan objek rentetan str dan objek rentetan Unicode ialah singkatan s.encode('ascii'). Eksperimen:
>>> s3 = u"你好" >>> s3 u'/u4f60/u597d' >>> str(s3) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
S3 di atas ialah rentetan jenis Unicode str(s3) bersamaan dengan melaksanakan s3.encode('ascii') Kerana dua aksara Cina "Hello" tidak boleh diwakili oleh kod ASCII, ralat dilaporkan pengekodan. : s3.encode('gbk') atau s3.encode('utf-8') tidak akan menyebabkan masalah ini. Unicode serupa mempunyai ralat yang sama:
>>> s4 = "你好" >>> unicode(s4) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 0: ordinal not in range(128) >>>
unicode(s4) bersamaan dengan s4.decode('ascii')
, jadi untuk penukaran yang betul, anda mesti menyatakan dengan betul pengekodannya s4.decode('gbk') atau s4.decode('utf-8').
Semua sebab aksara bercelaru boleh dikaitkan dengan format pengekodan yang tidak konsisten yang digunakan dalam proses pengekodan aksara selepas pengekodan dan penyahkodan yang berbeza, seperti:
# encoding: utf-8
>>> a='好'
>>> a
'/xe5/xa5/xbd'
>>> b=a.decode("utf-8")
>>> b
u'/u597d'
>>> c=b.encode("gbk")
>>> c
'/xba/xc3'
>>> print c
Katak berkod UTF-8 '好' menduduki 3 bait Selepas penyahkodan ke dalam Unicode, jika anda menggunakan GBK untuk menyahkod, panjangnya hanya 2 bait. Cara terbaik ialah sentiasa menggunakan format pengekodan yang sama untuk mengekod dan menyahkod aksara.

Untuk rentetan dalam bentuk Unicode (jenis str):
s = 'id/u003d215903184/u0026index/u003d0/u0026st/u003d52/u0026sid'
Untuk menukar kepada Unikod sebenar anda perlu menggunakan:
s.decode('unicode-escape')
Ujian:
>>> s = 'id/u003d215903184/u0026index/u003d0/u0026st/u003d52/u0026sid/u003d95000/u0026i'
>>> print(type(s))
<type 'str'>
>>> s = s.decode('unicode-escape')
>>> s
u'id=215903184&index=0&st=52&sid=95000&i'
>>> print(type(s))
<type 'unicode'>
>>>
Kod dan konsep di atas adalah berdasarkan Python2.x.
Atas ialah kandungan terperinci Evolusi sejarah pengaturcaraan Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!