| Pengenalan |
Baru-baru ini, saya telah melakukan penyegerakan log masa nyata Sebelum pergi ke dalam talian, saya melakukan satu ujian tekanan log dalam talian Tidak ada masalah dengan baris gilir mesej, pelanggan dan mesin tempatan jangkakan selepas log kedua dimuat naik, masalah datang
|
1. Soalan:
Sebuah mesin tertentu di bahagian atas kluster melihat beban yang besar Mesin dalam kluster mempunyai konfigurasi perkakasan yang sama dan perisian yang digunakan yang sama, tetapi mesin yang satu ini mempunyai masalah bebanan pada mulanya mungkin terdapat masalah perkakasan.
Pada masa yang sama, kita juga perlu mengetahui punca beban yang tidak normal, dan kemudian mencari penyelesaian daripada tahap perisian dan perkakasan.

2. Menyelesaikan masalah:
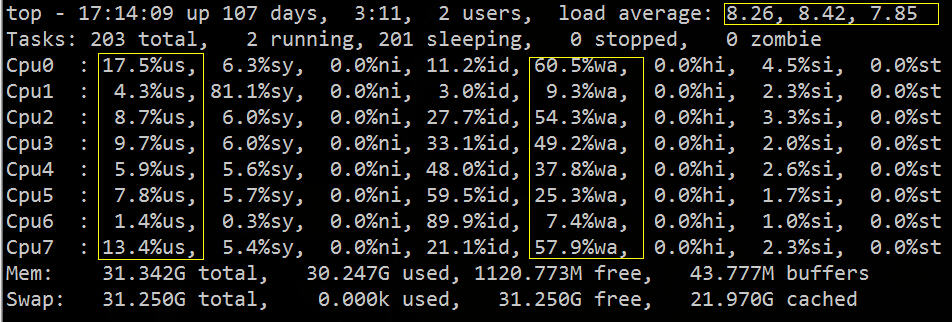
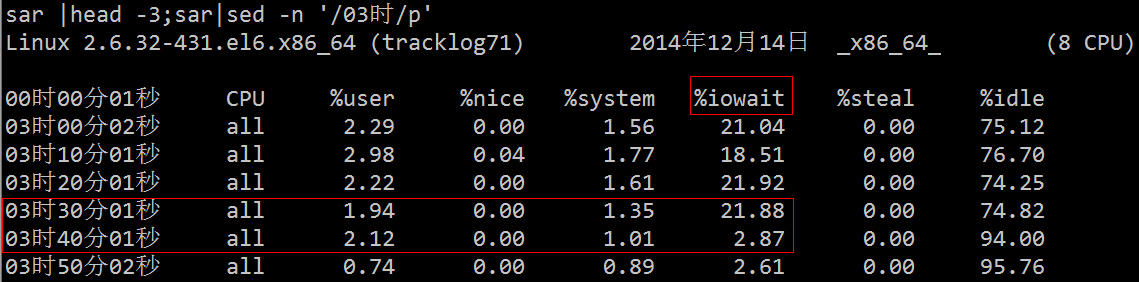
Anda boleh lihat dari atas bahawa purata beban adalah tinggi, %wa adalah tinggi dan %us adalah rendah:
Daripada gambar di atas, kita boleh membuat kesimpulan secara kasar bahawa IO telah menghadapi kesesakan Seterusnya, kita boleh menggunakan alat diagnostik IO yang berkaitan untuk pengesahan dan penyelesaian masalah tertentu.
Kaedah gabungan yang biasa digunakan adalah seperti berikut:
•Gunakan vmstat, sar, iostat untuk mengesan sama ada ia adalah kesesakan CPU
•Gunakan percuma dan vmstat untuk mengesan sama ada terdapat kesesakan memori
•Gunakan iostat dan dmesg untuk mengesan sama ada ia adalah halangan I/O cakera
•Gunakan netstat untuk mengesan sama ada terdapat kesesakan lebar jalur rangkaian
2.1 vmstat
Maksud arahan vmstat adalah untuk memaparkan status memori maya ("Virtual Memor Statics"), tetapi ia boleh melaporkan status pengendalian keseluruhan sistem seperti proses, memori, I/O, dsb.
Bidang berkaitannya diterangkan seperti berikut:
Procs
•r: Bilangan proses dalam baris gilir larian Nilai ini juga boleh digunakan untuk menentukan sama ada CPU perlu ditingkatkan. (jangka panjang melebihi 1)
•b: Bilangan proses menunggu IO, iaitu bilangan proses dalam keadaan tidur tidak terganggu, menunjukkan bilangan tugas yang sedang dilaksanakan dan menunggu sumber CPU. Apabila nilai ini melebihi bilangan CPU, kesesakan CPU akan berlaku
Memori
•swpd: Gunakan saiz memori maya Jika nilai swpd bukan 0, tetapi nilai SI dan SO adalah 0 untuk masa yang lama, keadaan ini tidak akan menjejaskan prestasi sistem.
•percuma: Saiz memori fizikal percuma.
•buff: Saiz memori yang digunakan sebagai penimbal.
•cache: Saiz memori yang digunakan sebagai cache Jika nilai cache adalah besar, ini bermakna terdapat banyak fail dalam cache Jika fail yang kerap diakses boleh dicache, IO bi cakera akan menjadi sangat kecil.
Swap (kawasan pertukaran)
•si: Saiz yang ditulis dari kawasan swap ke memori sesaat, yang dipindahkan ke dalam memori daripada cakera.
•jadi: Saiz memori yang ditulis ke kawasan swap sesaat, dipindahkan dari memori ke cakera.
Nota: Apabila memori mencukupi, kedua-dua nilai ini adalah 0. Jika kedua-dua nilai ini lebih besar daripada 0 untuk masa yang lama, prestasi sistem akan terjejas dan sumber IO dan CPU cakera akan dimakan. Sesetengah rakan berpendapat bahawa ingatan tidak mencukupi apabila mereka melihat bahawa memori bebas (percuma) sangat kecil atau hampir 0. Anda tidak boleh melihat ini, tetapi juga menggabungkan si dan sebagainya. terdapat juga sangat sedikit si dan sebagainya (Kebanyakan masa adalah 0), maka jangan risau, prestasi sistem tidak akan terjejas pada masa ini.
IO (input dan output)
(Saiz blok versi Linux sekarang ialah 1kb)
•bi: Bilangan blok dibaca sesaat
•bo: Bilangan blok yang ditulis sesaat
Nota: Apabila membaca dan menulis cakera rawak, lebih besar kedua-dua nilai ini (seperti melebihi 1024k), lebih besar nilai yang anda boleh lihat bahawa CPU sedang menunggu IO.
sistem
•dalam: Bilangan gangguan sesaat, termasuk gangguan jam.
•cs: Bilangan suis konteks sesaat.
Nota: Lebih besar kedua-dua nilai di atas, lebih besar masa CPU yang digunakan oleh kernel.
CPU
(dinyatakan sebagai peratusan)
•us: Peratusan masa pelaksanaan proses pengguna (masa pengguna). Apabila nilai kita agak tinggi, ini bermakna proses pengguna menggunakan banyak masa CPU, tetapi jika penggunaan melebihi 50% untuk masa yang lama, maka kita harus mempertimbangkan untuk mengoptimumkan algoritma program atau mempercepatkannya.
•sy: Peratusan masa pelaksanaan proses sistem kernel (masa sistem). Apabila nilai sy tinggi, ini bermakna kernel sistem menggunakan banyak sumber CPU Ini bukan prestasi yang baik, dan kita harus menyemak sebabnya.
•wa: Peratusan masa menunggu IO. Apabila nilai wa tinggi, ini bermakna penantian IO adalah serius. Ini mungkin disebabkan oleh bilangan akses rawak yang banyak pada cakera, atau mungkin terdapat kesesakan (operasi blok) pada cakera.
•id: peratusan masa terbiar
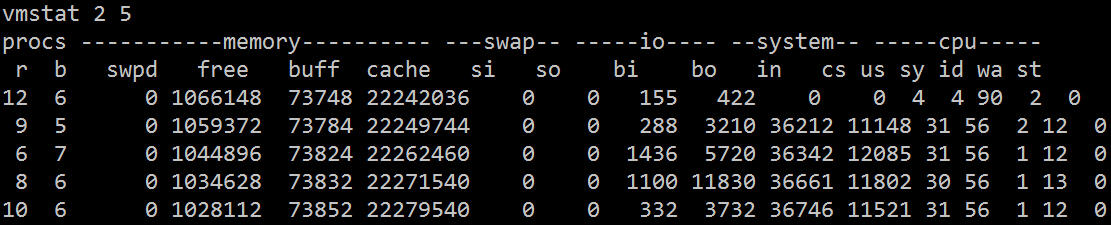
Seperti yang anda lihat dari vmstat, kebanyakan masa CPU terbuang menunggu IO, yang mungkin disebabkan oleh sejumlah besar akses cakera rawak atau lebar jalur cakera Kedua-dua bi dan bo melebihi 1024k, yang sepatutnya menunjukkan kesesakan IO.
2.2 iostat
Mari gunakan alat diagnostik IO cakera yang lebih profesional untuk melihat statistik yang berkaitan.
Bidang berkaitannya diterangkan seperti berikut:
•rrqm/s: Bilangan operasi baca gabungan sesaat. Itulah delta(rmerge)/s
•wrqm/s: Bilangan operasi tulis cantuman sesaat. Itulah delta(wmerge)/s
•r/s: Bilangan bacaan daripada peranti I/O selesai sesaat. Itulah delta(rio)/s
•w/s: Bilangan tulis pada peranti I/O yang dilengkapkan sesaat. Itulah delta(wio)/s
•rsec/s: Bilangan sektor dibaca sesaat. Itulah delta(rsect)/s
•wsec/s: Bilangan sektor yang ditulis sesaat. Itulah delta(wsect)/s
•rkB/s: K bait dibaca sesaat. Adalah separuh daripada rsect/s kerana setiap saiz sektor ialah 512 bait. (perlu pengiraan)
•wkB/s: Bilangan K bait yang ditulis sesaat. ialah separuh daripada wsect/s. (perlu pengiraan)
•avgrq-sz: Purata saiz data (sektor) bagi setiap operasi I/O peranti. delta(rsect+wsect)/delta(rio+wio)
•avgqu-sz: Purata panjang baris gilir I/O. Iaitu delta(aveq)/s/1000 (kerana unit aveq ialah milisaat).
•menunggu: purata masa menunggu (milisaat) untuk setiap operasi I/O peranti. Itulah delta(ruse+wuse)/delta(rio+wio)
•svctm: Purata masa perkhidmatan (milisaat) bagi setiap operasi I/O peranti. Itulah delta(use)/delta(rio+wio)
•%util: Berapa peratusan satu saat digunakan untuk operasi I/O, atau berapa banyak satu saat baris gilir I/O tidak kosong. Iaitu delta(use)/s/1000 (kerana unit penggunaan ialah milisaat)
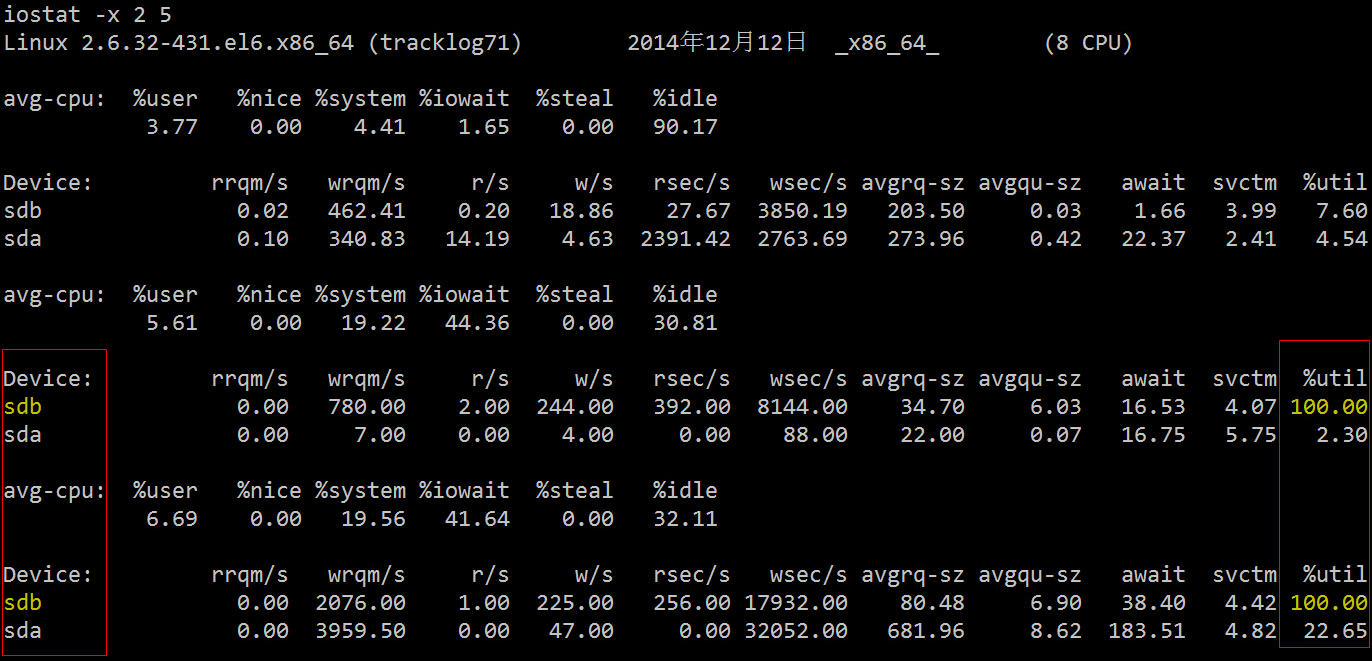
Anda dapat melihat bahawa kadar penggunaan sdb dalam dua cakera keras telah mencapai 100%, dan terdapat kesesakan IO yang serius Langkah seterusnya adalah untuk mengetahui proses membaca dan menulis data ke cakera keras ini.
2.3 iotop
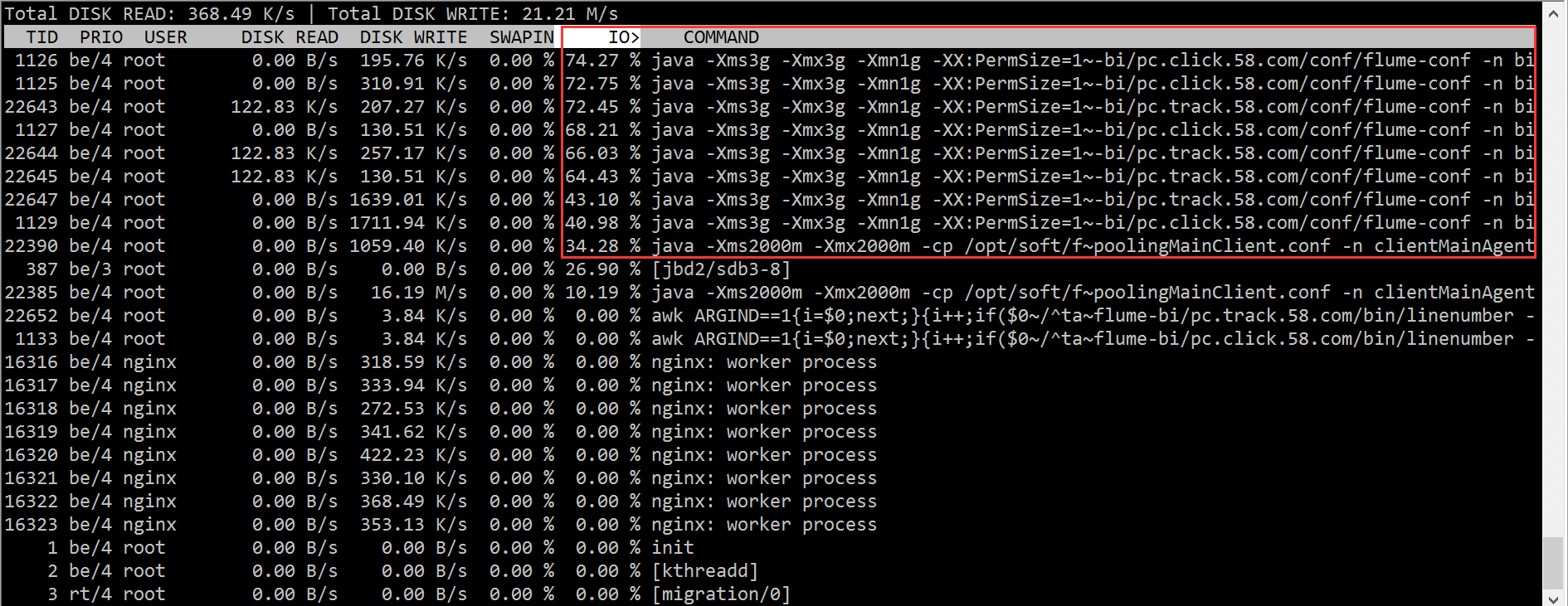
Mengikut keputusan iotop, kami dengan cepat mengesan masalah dengan proses flume, yang menyebabkan sejumlah besar menunggu IO.
Tetapi seperti yang saya katakan pada mulanya, konfigurasi mesin dalam kluster adalah sama, dan program yang digunakan adalah sama seperti yang digunakan oleh rsync. Mungkinkah cakera keras itu rosak?
Ini perlu disahkan oleh pelajar operasi dan penyelenggaraan Kesimpulan akhir ialah:
Sdb ialah serbuan dwi-cakera1, kad serbuan yang digunakan ialah "LSI Logic/Symbios Logic SAS1068E", dan tiada cache. Tekanan hampir 400 IOPS telah mencapai had perkakasan. Kad serbuan yang digunakan oleh mesin lain ialah "LSI Logic / Symbios Logic MegaRAID SAS 1078", yang mempunyai cache 256MB dan belum mencapai kesesakan perkakasan Penyelesaiannya adalah untuk menggantikan mesin dengan IOPS yang lebih besar kepada mesin dengan Mesin PERC6 /i dengan kad pengawal RAID bersepadu. Perlu diingatkan bahawa maklumat RAID disimpan dalam kad RAID dan perisian tegar cakera Maklumat RAID pada cakera dan format maklumat pada kad RAID mesti sepadan diformatkan.
IOPS pada dasarnya bergantung pada cakera itu sendiri, tetapi terdapat banyak cara untuk menambah baik IOPS Menambah cache perkakasan dan menggunakan tatasusunan RAID adalah kaedah biasa. Jika ia adalah senario seperti DB dengan IOPS tinggi, kini popular untuk menggunakan SSD untuk menggantikan cakera keras mekanikal tradisional.
Tetapi seperti yang dinyatakan sebelum ini, tujuan kami bermula dari aspek perisian dan perkakasan adalah untuk melihat sama ada kami boleh mencari penyelesaian yang paling murah masing-masing:
Sekarang kita tahu sebab perkakasan, kita boleh cuba mengalihkan operasi baca dan tulis ke cakera lain, dan kemudian lihat kesannya:
3 Kata akhir: Cari jalan lain
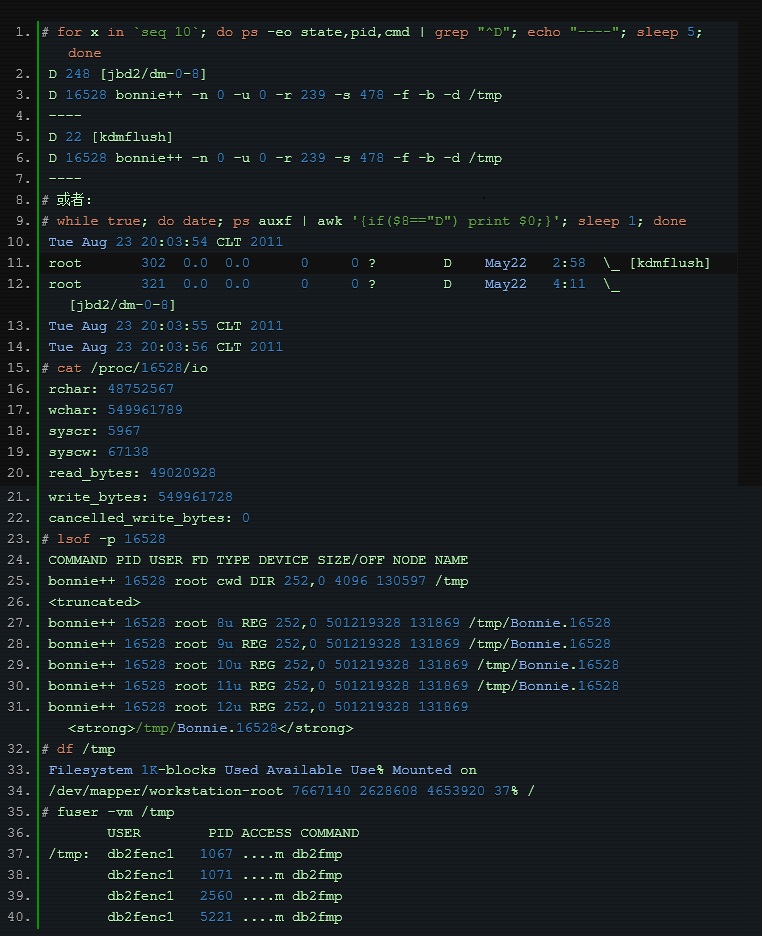
Malah, selain menggunakan alat profesional yang disebutkan di atas untuk mengesan masalah ini, kami boleh terus menggunakan status proses untuk mencari proses yang berkaitan.
Kami tahu bahawa proses tersebut mempunyai keadaan berikut:
•D tidur tanpa gangguan (biasanya IO)
•R running atau runnable (on runnable queue)
•S tidur yang terganggu (menunggu acara selesai)
•T berhenti, sama ada dengan isyarat kawalan kerja atau kerana ia sedang dikesan.
•W paging (tidak sah sejak kernel 2.6.xx)
•X mati (tidak boleh dilihat)
•Proses Z tidak berfungsi ("zombie"), ditamatkan tetapi tidak dituai oleh induknya.
Keadaan D secara amnya dipanggil "tidur tidak terganggu" yang disebabkan oleh menunggu IO Kita boleh bermula dari titik ini dan kemudian mencari masalah langkah demi langkah: