
Rumah >Peranti teknologi >AI >Penjana 4090: Berbanding dengan platform A100, kelajuan penjanaan token hanya kurang daripada 18%, dan penyerahan kepada enjin inferens telah memenangi perbincangan hangat
Penjana 4090: Berbanding dengan platform A100, kelajuan penjanaan token hanya kurang daripada 18%, dan penyerahan kepada enjin inferens telah memenangi perbincangan hangat

- 王林ke hadapan
- 2023-12-21 15:25:411998semak imbas
PowerInfer meningkatkan kecekapan menjalankan AI pada perkakasan gred pengguna
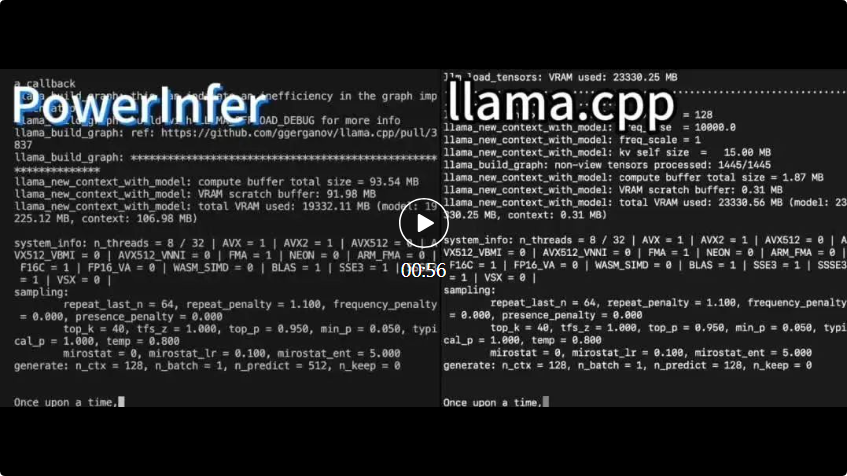 cpp kedua-duanya berjalan pada perkakasan yang sama dan memanfaatkan sepenuhnya VRAM pada RTX 4090.
cpp kedua-duanya berjalan pada perkakasan yang sama dan memanfaatkan sepenuhnya VRAM pada RTX 4090. PowerInfer Berbanding dengan rangka kerja inferens LLM lanjutan tempatan llama.cpp, melaksanakan model Falcon (ReLU)-40B-FP16 pada satu RTX 4090 (24G) bukan sahaja mencapai lebih daripada 11 kali pecutan, tetapi juga mengekalkan Ketepatan model
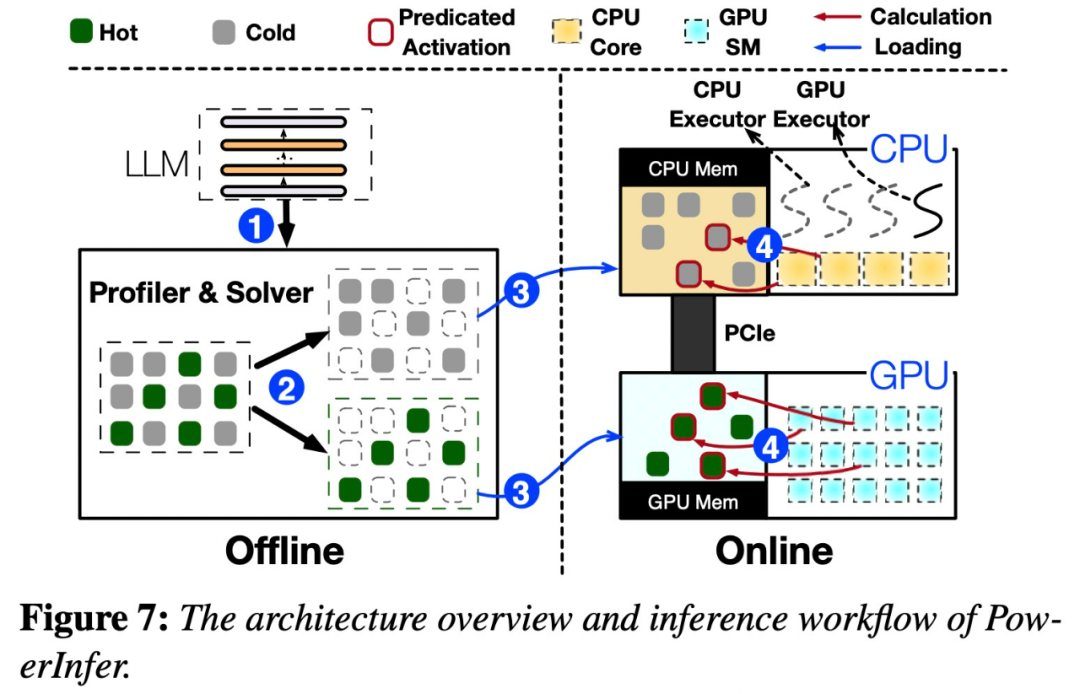
PowerInfer ialah enjin inferens berkelajuan tinggi yang direka untuk penggunaan LLM di premis. Tidak seperti sistem berbilang pakar (MoE), PowerInfer dengan bijak mereka bentuk enjin inferens hibrid GPU-CPU yang mengeksploitasi sepenuhnya lokaliti tinggi inferens LLM
memuat pramuat neuron yang kerap diaktifkan (iaitu pengaktifan panas) ke GPU Untuk akses pantas, neuron yang diaktifkan jarang (iaitu, pengaktifan sejuk) dikira pada CPU. Begini cara ia berfungsi
Kaedah ini boleh mengurangkan keperluan memori GPU dengan ketara dan jumlah pemindahan data antara CPU dan GPU

Pautan projek: https://github.com/SJTU-IPADS/ PowerInfer
-
Pautan kertas: https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
PowerInfer boleh menjalankan LLM pada kelajuan tinggi pada PC yang dilengkapi dengan GPU gred pengguna tunggal. Pengguna kini boleh menggunakan PowerInfer dengan Llama 2 dan Faclon 40B, dengan sokongan untuk Mistral-7B akan datang tidak lama lagi.
Dalam satu hari, PowerInfer berjaya memperoleh 2K bintang
Selepas melihat penyelidikan ini, netizen menyatakan keterujaan mereka: kini satu kad 4090 boleh menjalankan model besar 175B, bukan lagi sekadar What a dream
Seni Bina PowerInfer
Kunci kepada reka bentuk PowerInfer adalah untuk mengeksploitasi tahap lokaliti tinggi yang wujud dalam inferens LLM, yang dicirikan olehpengagihan undang-undang kuasa dalam pengaktifan neuron. Taburan ini menunjukkan bahawa subset kecil neuron, dipanggil neuron panas, mengaktifkan secara konsisten merentas input, manakala majoriti neuron sejuk berbeza-beza bergantung pada input tertentu. PowerInfer memanfaatkan mekanisme ini untuk mereka bentuk enjin inferens hibrid GPU-CPU.
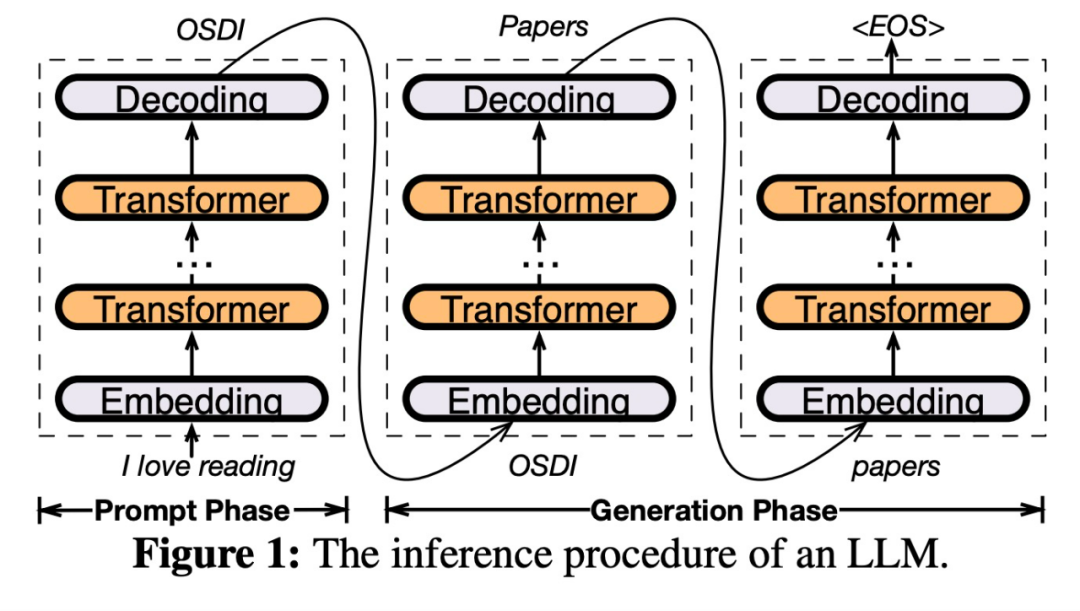
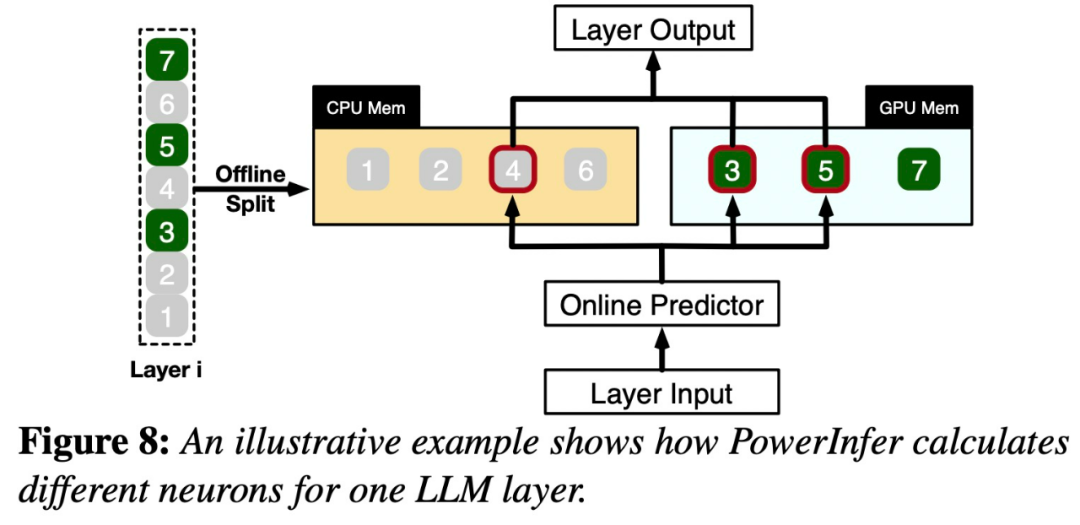
Setelah input diterima, peramal akan mengenal pasti neuron dalam lapisan semasa yang mungkin akan diaktifkan. Perlu diingatkan bahawa neuron diaktifkan secara termal yang dikenal pasti melalui analisis statistik luar talian mungkin tidak konsisten dengan tingkah laku pengaktifan sebenar semasa runtime. Sebagai contoh, walaupun neuron 7 dilabel sebagai diaktifkan secara terma, ia sebenarnya tidak begitu. CPU dan GPU kemudian memproses neuron yang telah diaktifkan dan mengabaikan yang tidak. GPU bertanggungjawab untuk mengira neuron 3 dan 5, manakala CPU mengendalikan neuron 4. Apabila pengiraan neuron 4 selesai, outputnya akan dihantar ke GPU untuk penyepaduan hasil
Untuk menulis semula kandungan tanpa mengubah maksud asal, bahasa itu perlu ditulis semula ke dalam bahasa Cina. Tidak perlu ayat asal muncul
Kajian dilakukan menggunakan model OPT dengan parameter yang berbeza Untuk menulis semula kandungan tanpa mengubah maksud asal, bahasa perlu ditulis semula ke dalam bahasa Cina. Anda tidak perlu mengemukakan ayat asal, julat parameter daripada 6.7B hingga 175B, dan model Falcon (ReLU)-40B dan LLaMA (ReGLU)-70B turut disertakan. Perlu diingat bahawa saiz model parameter 175B adalah setanding dengan model GPT-3.
Artikel ini juga membandingkan PowerInfer dengan llama.cpp, rangka kerja inferens LLM asli yang terkini. Untuk memudahkan perbandingan, kajian ini turut memanjangkan llama.cpp untuk menyokong model OPT
Memandangkan fokus artikel ini adalah pada tetapan kependaman rendah, metrik penilaian menggunakan kelajuan penjanaan hujung ke hujung dari segi bilangan token yang dijana sesaat (token/s ) untuk kuantifikasi
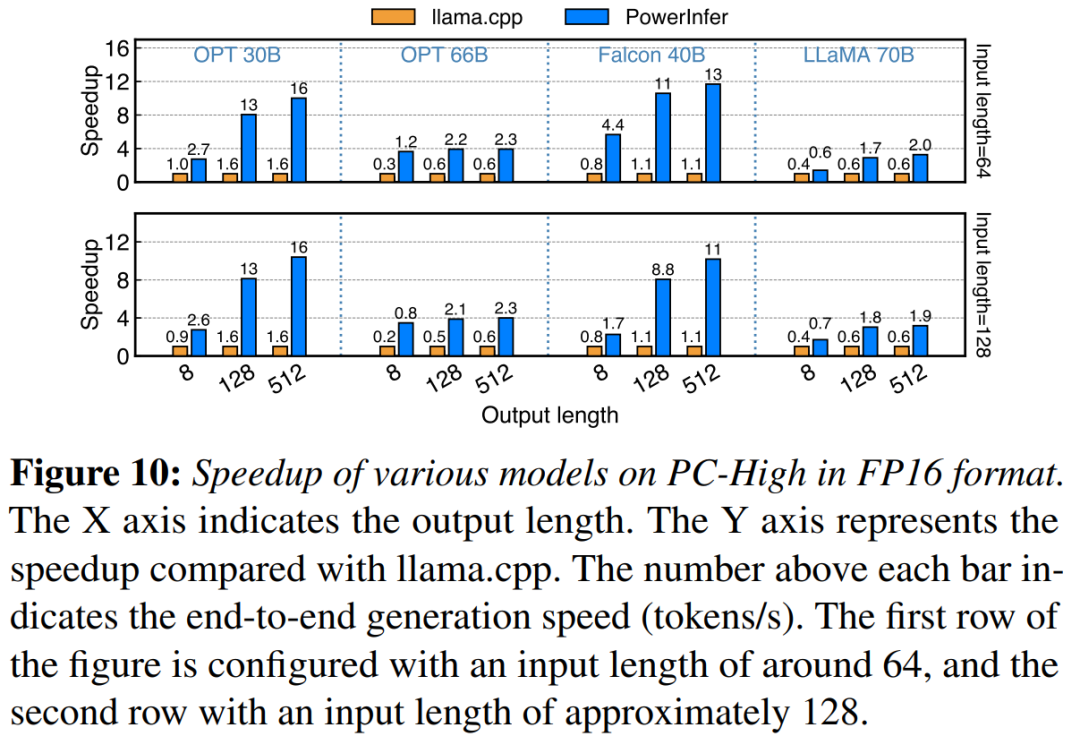
Kajian ini terlebih dahulu membandingkan prestasi inferens hujung ke hujung PowerInfer dan llama.cpp dengan saiz kelompok 1
Pada PC-High dengan NVIDIA RTX 4090, Rajah 10 menunjukkan pelbagai model dan kelajuan penjanaan konfigurasi input dan output. Secara purata, PowerInfer mencapai kelajuan penjanaan 8.32 token/s, dengan maksimum 16.06 token/s, yang jauh lebih baik daripada llama.cpp, 7.23 kali lebih tinggi daripada llama.cpp dan 11.69 kali lebih tinggi daripada Falcon-40B
Seterusnya Apabila bilangan token keluaran meningkat, kelebihan prestasi PowerInfer menjadi lebih jelas, kerana fasa penjanaan memainkan peranan yang lebih penting dalam masa inferens keseluruhan. Pada peringkat ini, sebilangan kecil neuron diaktifkan pada kedua-dua CPU dan GPU, yang mengurangkan pengiraan yang tidak perlu berbanding llama.cpp. Sebagai contoh, dalam kes OPT-30B, hanya kira-kira 20% daripada neuron diaktifkan setiap token yang dijana, kebanyakannya diproses pada GPU, yang merupakan faedah inferens sedar neuron PowerInfer
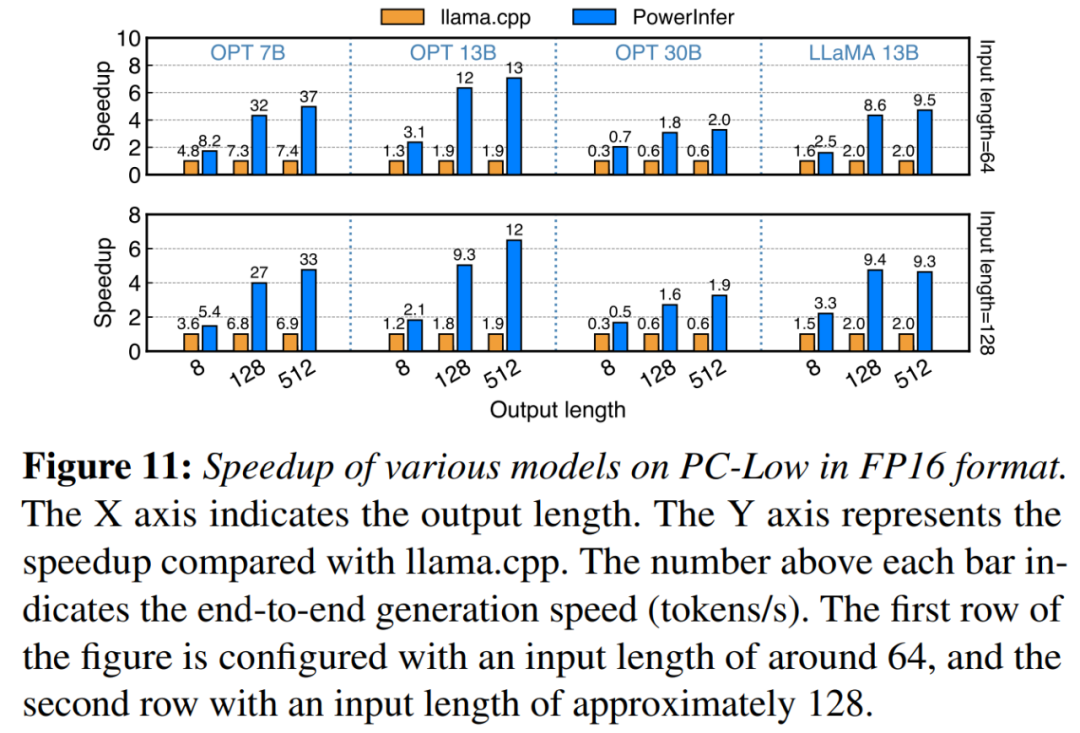
dalam Rajah 11 Seperti yang ditunjukkan dalam rajah, PowerInfer masih mencapai peningkatan prestasi yang besar walaupun dijalankan pada PC-Low, dengan kelajuan purata 5.01x dan kelajuan puncak 7.06x. Walau bagaimanapun, peningkatan ini lebih kecil berbanding dengan PC-High, kebanyakannya disebabkan oleh had memori GPU 11GB PC-Low. Had ini menjejaskan bilangan neuron yang boleh diperuntukkan kepada GPU, terutamanya untuk model dengan sekitar 30B parameter atau lebih, menyebabkan pergantungan yang lebih besar pada CPU untuk mengendalikan sejumlah besar neuron diaktifkan
Rajah 12 menunjukkan PowerInfer dan neuron pengagihan beban antara CPU dan GPU antara llama.cpp. Terutama, pada PC-High, PowerInfer meningkatkan bahagian beban neuron GPU dengan ketara daripada purata 20% kepada 70%. Ini menunjukkan bahawa GPU memproses 70% daripada neuron yang diaktifkan. Walau bagaimanapun, dalam kes di mana keperluan memori model jauh melebihi kapasiti GPU, seperti menjalankan model 60GB pada GPU 11GB 2080Ti, beban neuron pada GPU dikurangkan kepada 42%. Penurunan ini disebabkan oleh memori GPU yang terhad, yang tidak mencukupi untuk menampung semua neuron yang diaktifkan, justeru memerlukan CPU untuk mengira subset daripadanya

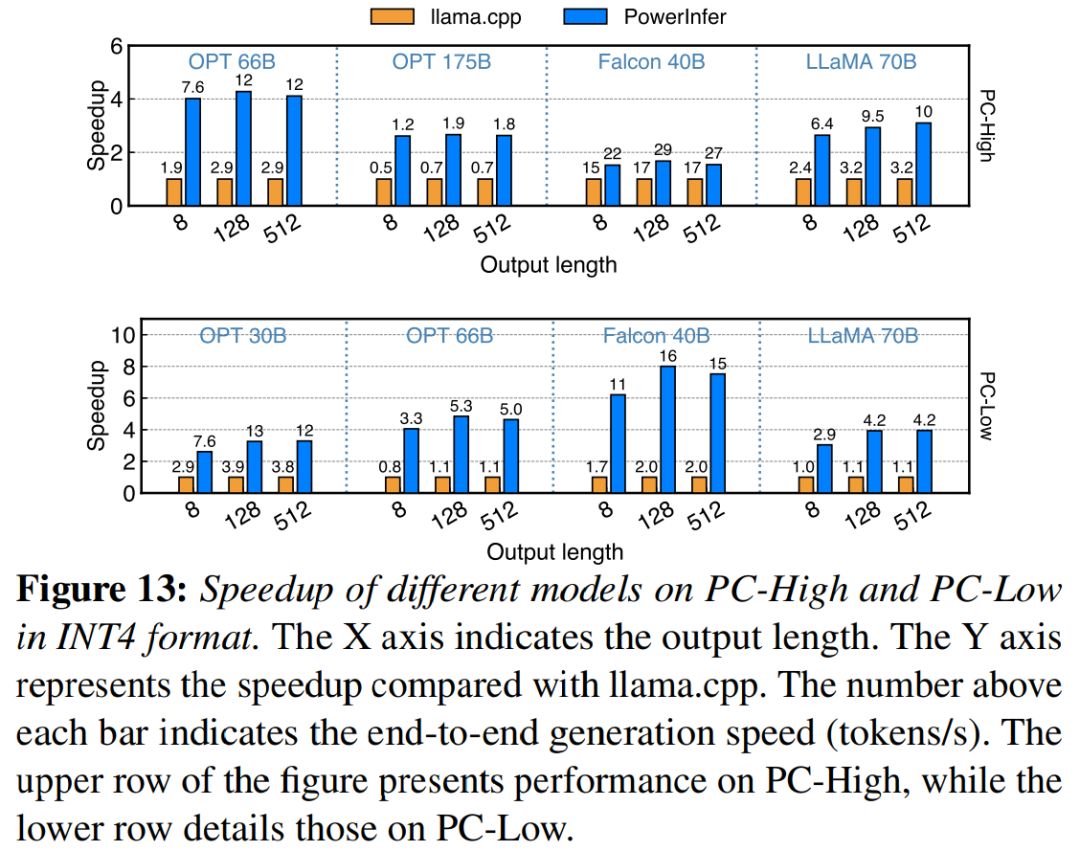
Rajah 13 menggambarkan bahawa PowerInfer menyokong LLM dengan berkesan menggunakan pemampatan kuantisasi INT4. Pada PC-High, PowerInfer mempunyai purata kelajuan tindak balas 13.20 token/s, dengan kelajuan tindak balas puncak 29.08 token/s. Berbanding dengan llama.cpp, kelajuan purata ialah 2.89x dan kelajuan maksimum ialah 4.28x. Pada PC-Low, kelajuan purata ialah 5.01x dan kemuncaknya ialah 8.00x. Keperluan memori yang dikurangkan disebabkan kuantisasi membolehkan PowerInfer mengurus model yang lebih besar dengan lebih cekap. Contohnya, menggunakan model OPT-175B pada PC-High memerlukan penulisan semula bahasa ke dalam bahasa Cina untuk menulis semula kandungan tanpa mengubah maksud asal. Tanpa perlu muncul dalam ayat asal, PowerInfer mencapai hampir dua token sesaat, melebihi llama.cpp dengan faktor 2.66.
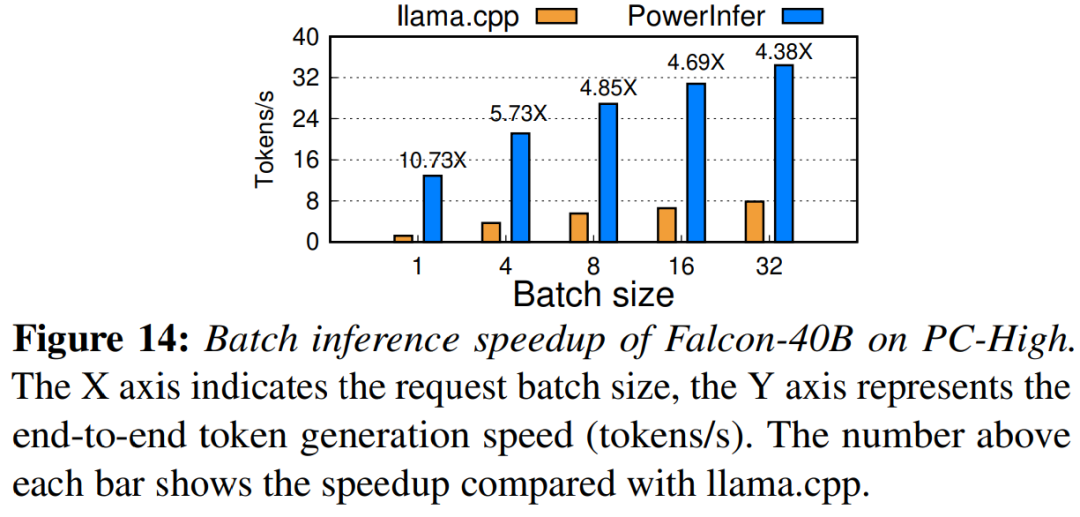
Akhir sekali, kajian ini juga menilai prestasi inferens hujung ke hujung PowerInfer di bawah saiz kelompok yang berbeza. Seperti yang ditunjukkan dalam Rajah 14, apabila saiz kelompok kurang daripada 32, PowerInfer menunjukkan kelebihan yang ketara, dengan peningkatan prestasi purata sebanyak 6.08 kali berbanding llama. Apabila saiz kelompok bertambah, kelajuan yang disediakan oleh PowerInfer berkurangan. Walau bagaimanapun, walaupun saiz kelompok ditetapkan kepada 32, PowerInfer masih mengekalkan kelajuan yang agak besar
Pautan rujukan: https://weibo.com/1727858283/NxZ0Ttdnzsemak kertas asal untuk pelajari
lagi Kandungan
Atas ialah kandungan terperinci Penjana 4090: Berbanding dengan platform A100, kelajuan penjanaan token hanya kurang daripada 18%, dan penyerahan kepada enjin inferens telah memenangi perbincangan hangat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!