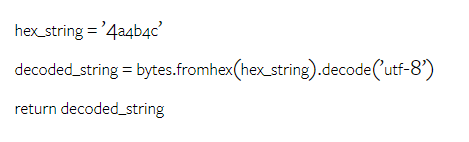
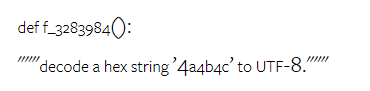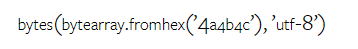Berapakah berat Gemini Google? Bagaimanakah ia dibandingkan dengan model GPT OpenAI? Kertas CMU ini mempunyai hasil pengukuran yang jelas
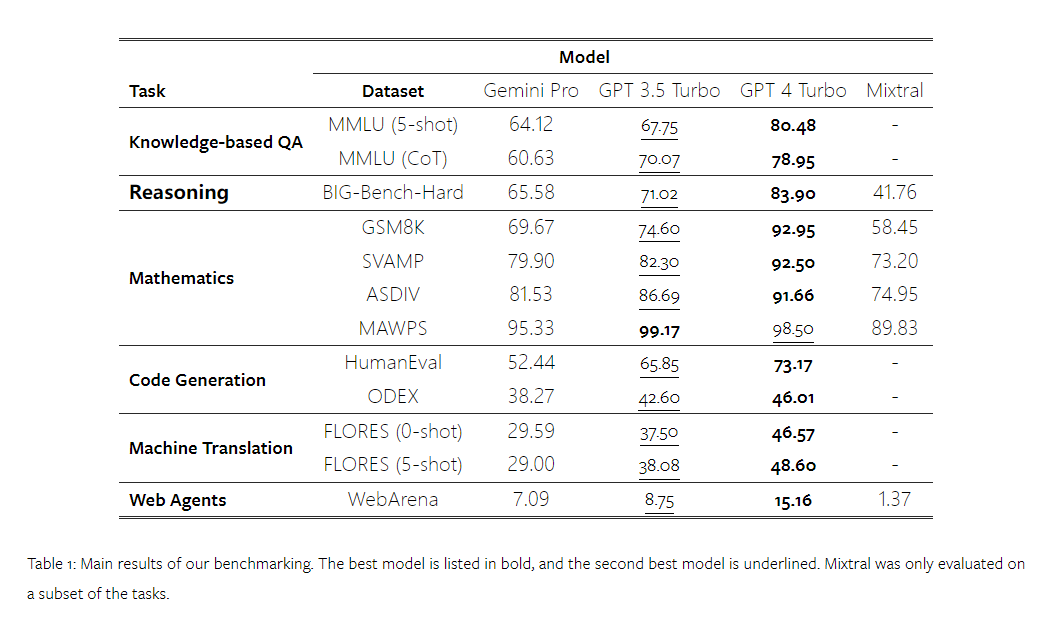
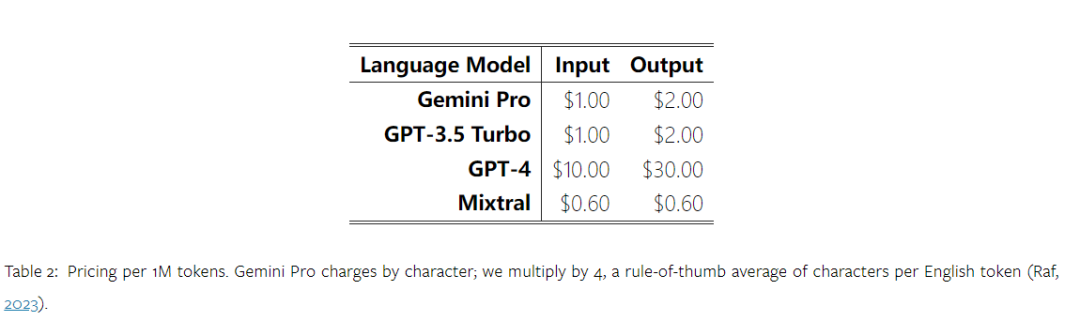
Beberapa masa lalu, Google mengeluarkan pesaing kepada model OpenAI GPT - Gemini. Model besar ini didatangkan dalam tiga versi - Ultra (yang paling berkebolehan), Pro dan Nano. Keputusan ujian yang diterbitkan oleh pasukan penyelidik menunjukkan bahawa versi Ultra mengatasi GPT4 dalam banyak tugas, manakala versi Pro adalah setanding dengan GPT-3.5. Walaupun keputusan perbandingan ini sangat penting untuk penyelidikan model bahasa berskala besar, memandangkan butiran penilaian dan ramalan model yang tepat masih belum didedahkan kepada umum, ini mengehadkan pengeluaran semula dan pengesanan keputusan ujian, menjadikannya sukar untuk menganalisis butiran tersiratnya. Untuk memahami kekuatan sebenar Gemini, penyelidik dari Carnegie Mellon University dan BerriAI menjalankan penerokaan mendalam tentang pemahaman bahasa model dan keupayaan penjanaan. Mereka menguji pemahaman teks dan keupayaan penjanaan Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo dan Mixtral pada sepuluh set data. Secara khusus, mereka menguji keupayaan model untuk menjawab soalan berasaskan pengetahuan tentang MMLU, keupayaan penaakulan model pada BigBenchHard, keupayaan model untuk menjawab soalan matematik dalam set data seperti GSM8K, dan keupayaan model untuk menjawab soalan matematik dalam set data seperti FLORES. Keupayaan penterjemahan model; keupayaan penjanaan kod model telah diuji dalam set data seperti HumanEval. Jadual 1 di bawah menunjukkan keputusan utama perbandingan. Secara keseluruhan, setakat tarikh penerbitan kertas kerja, Gemini Pro hampir dengan OpenAI GPT 3.5 Turbo dalam ketepatan merentas semua tugasan, tetapi masih rendah sedikit. Selain itu, mereka juga mendapati Gemini dan GPT berprestasi lebih baik daripada model pesaing sumber terbuka Mixtral. Dalam kertas kerja, penulis memberikan penerangan dan analisis yang mendalam bagi setiap tugasan. Semua keputusan dan kod boleh dihasilkan boleh didapati di: https://github.com/neulab/gemini-benchmarkPautan kertas: https://arxiv.org/pdf/2312.11444.pdfPengarang memilih empat model: Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo dan Mixtral sebagai objek ujian.
Disebabkan perbezaan dalam tetapan percubaan semasa penilaian dalam kajian terdahulu, untuk memastikan ujian yang adil, pengarang menjalankan semula percubaan menggunakan perkataan segera dan protokol penilaian yang sama. Dalam kebanyakan penilaian, mereka menggunakan perkataan dan rubrik segera daripada repositori standard. Sumber ujian ini datang daripada set data yang disertakan dengan keluaran model dan alat penilaian Eleuther dan sebagainya. Antaranya, kata-kata gesaan biasanya termasuk pertanyaan, input, sebilangan kecil contoh, penaakulan rantai pemikiran, dll. Dalam beberapa penilaian khas, penulis mendapati bahawa pelarasan kecil kepada amalan standard adalah perlu. Pelarasan bias telah dilakukan dalam repositori kod yang sepadan, sila rujuk kertas asal. .
2. Kaji keputusan penilaian secara mendalam dan analisa dalam bidang mana kedua-dua model berprestasi lebih menonjol.
QA berasaskan pengetahuan
Pengarang memilih 57 tugasan soal jawab aneka pilihan berasaskan pengetahuan daripada set data MMLU, meliputi STEM, kemanusiaan dan sains sosial, dsb. MMLU mempunyai sejumlah 14,042 sampel ujian dan telah digunakan secara meluas untuk memberikan penilaian keseluruhan tentang keupayaan pengetahuan model bahasa besar.
Pengarang membandingkan dan menganalisis prestasi keseluruhan empat objek ujian pada MMLU (seperti yang ditunjukkan dalam rajah di bawah), prestasi subtugas dan kesan panjang output ke atas prestasi. Rajah 1: Ketepatan keseluruhan setiap model pada MMLU menggunakan 5 gesaan sampel dan gesaan rantaian pemikiran.
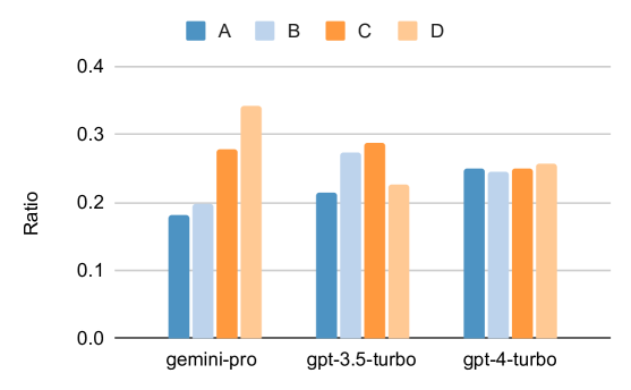
 Seperti yang anda lihat daripada rajah, ketepatan Gemini Pro adalah lebih rendah daripada GPT 3.5 Turbo, dan jauh lebih rendah daripada GPT 4 Turbo.Apabila menggunakan gesaan rantaian pemikiran, terdapat sedikit perbezaan dalam prestasi setiap model. Penulis membuat spekulasi bahawa ini disebabkan oleh fakta bahawa MMLU terutamanya menangkap tugasan soalan dan jawapan berasaskan pengetahuan, yang mungkin tidak mendapat manfaat dengan ketara daripada gesaan berorientasikan penaakulan yang lebih kuat. Perlu diingat bahawa semua soalan dalam MMLU ialah soalan aneka pilihan dengan empat kemungkinan jawapan A hingga D disusun mengikut urutan. Graf di bawah menunjukkan perkadaran setiap pilihan jawapan yang dipilih oleh setiap model. Anda boleh lihat daripada rajah bahawa taburan jawapan Gemini sangat condong ke arah memilih pilihan terakhir D. Ini berbeza dengan hasil yang lebih seimbang yang diberikan oleh versi GPT. Ini mungkin menunjukkan bahawa Gemini tidak menerima pelarasan arahan yang meluas yang dikaitkan dengan soalan aneka pilihan, mengakibatkan berat sebelah dalam kedudukan jawapan model. Rajah 2: Perkadaran jawapan kepada soalan aneka pilihan yang diramalkan oleh model yang diuji.
Seperti yang anda lihat daripada rajah, ketepatan Gemini Pro adalah lebih rendah daripada GPT 3.5 Turbo, dan jauh lebih rendah daripada GPT 4 Turbo.Apabila menggunakan gesaan rantaian pemikiran, terdapat sedikit perbezaan dalam prestasi setiap model. Penulis membuat spekulasi bahawa ini disebabkan oleh fakta bahawa MMLU terutamanya menangkap tugasan soalan dan jawapan berasaskan pengetahuan, yang mungkin tidak mendapat manfaat dengan ketara daripada gesaan berorientasikan penaakulan yang lebih kuat. Perlu diingat bahawa semua soalan dalam MMLU ialah soalan aneka pilihan dengan empat kemungkinan jawapan A hingga D disusun mengikut urutan. Graf di bawah menunjukkan perkadaran setiap pilihan jawapan yang dipilih oleh setiap model. Anda boleh lihat daripada rajah bahawa taburan jawapan Gemini sangat condong ke arah memilih pilihan terakhir D. Ini berbeza dengan hasil yang lebih seimbang yang diberikan oleh versi GPT. Ini mungkin menunjukkan bahawa Gemini tidak menerima pelarasan arahan yang meluas yang dikaitkan dengan soalan aneka pilihan, mengakibatkan berat sebelah dalam kedudukan jawapan model. Rajah 2: Perkadaran jawapan kepada soalan aneka pilihan yang diramalkan oleh model yang diuji.
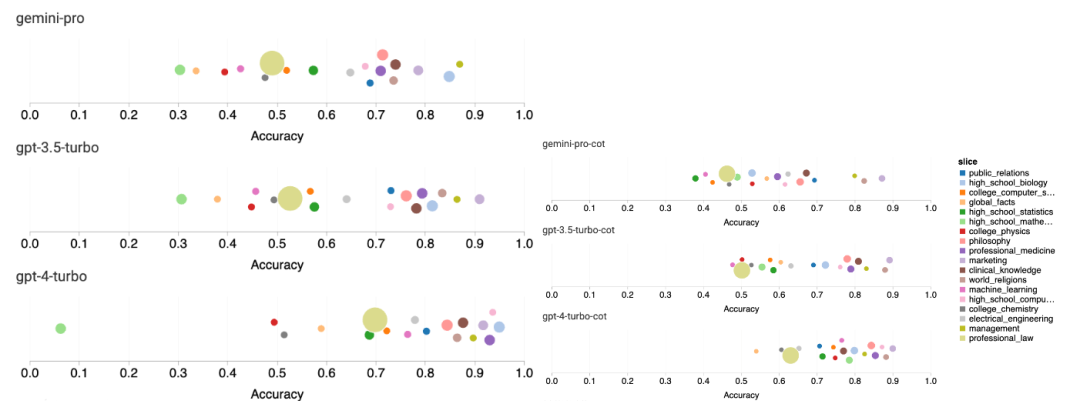
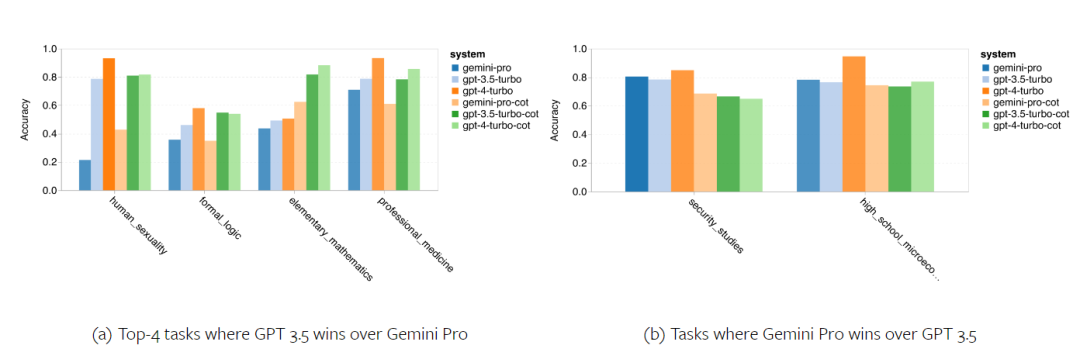
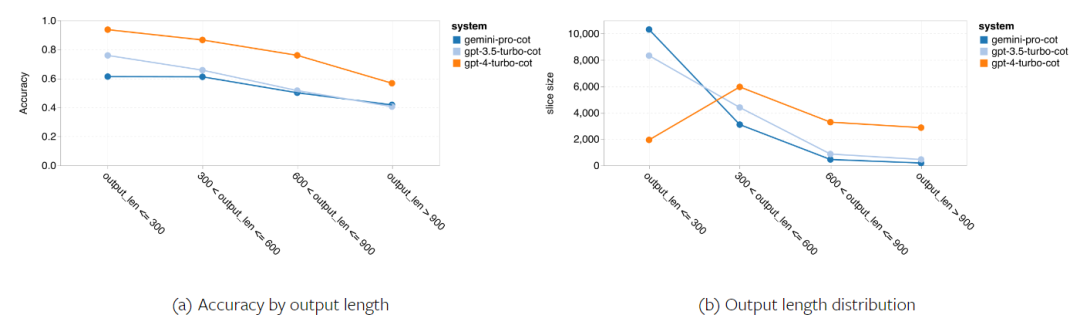
Rajah berikut menunjukkan prestasi model yang diuji pada sub-tugas set ujian MMLU. Gemini Pro berprestasi lemah pada kebanyakan tugas berbanding GPT 3.5. Gesaan rantaian pemikiran mengurangkan varians antara subtugas. Rajah 3: Ketepatan model yang diuji pada setiap sub-tugas. Pengarang melihat secara mendalam tentang kekuatan dan kelemahan Gemini Pro. Seperti yang dapat diperhatikan dalam Rajah 4, Gemini Pro ketinggalan di belakang GPT 3.5 dalam tugasan Jantina Manusia (Sains Sosial), Logik Formal (Kemanusiaan), Matematik Asas (STEM), dan Perubatan Profesional (Bidang Profesional). Penerajunya juga tipis dalam dua tugas yang lebih baik dilakukan oleh Gemini Pro. Rajah 4: Kelebihan Gemini Pro dan GPT 3.5 pada tugas MMLU. Prestasi lemah Gemini Pro pada tugas tertentu boleh dikaitkan dengan dua sebab. Pertama, terdapat situasi di mana Gemini tidak dapat membalas jawapan. Dalam kebanyakan subtugas MMLU, kadar tindak balas API melebihi 95%, tetapi kadar yang sepadan jauh lebih rendah dalam dua tugas moral (kadar tindak balas 85%) dan jantina manusia (kadar tindak balas 28%). Ini menunjukkan bahawa prestasi Gemini yang lebih rendah pada beberapa tugas mungkin disebabkan oleh penapis kandungan input. Kedua, Gemini Pro berprestasi sedikit lebih teruk pada penaakulan asas matematik yang diperlukan untuk menyelesaikan logik formal dan tugasan matematik asas. Pengarang juga menganalisis bagaimana panjang output dalam gesaan rantai pemikiran mempengaruhi prestasi model, seperti yang ditunjukkan dalam Rajah 5. Secara umum, model yang lebih berkuasa cenderung untuk melakukan penaakulan yang lebih kompleks dan oleh itu menghasilkan jawapan yang lebih panjang. Gemini Pro mempunyai kelebihan yang patut diberi perhatian berbanding "lawan"nya: ketepatannya kurang dipengaruhi oleh panjang output. Gemini Pro malah mengatasi GPT 3.5 apabila panjang output melebihi 900. Walau bagaimanapun, berbanding GPT 4 Turbo, Gemini Pro dan GPT 3.5 Turbo jarang mengeluarkan rantai inferens panjang. Rajah 5: Analisis panjang output model yang diuji pada MMLU. . BIG-Bench Hard mengandungi 27 tugas penaakulan yang berbeza seperti penaakulan aritmetik, simbolik dan berbilang bahasa, pemahaman pengetahuan fakta dan banyak lagi. Kebanyakan tugasan terdiri daripada 250 pasangan soalan-jawapan, dengan beberapa tugasan mempunyai sedikit soalan.
Rajah 6 menunjukkan ketepatan keseluruhan model yang diuji. Ia boleh dilihat bahawa ketepatan Gemini Pro adalah lebih rendah sedikit daripada GPT 3.5 Turbo dan jauh lebih rendah daripada GPT 4 Turbo. Sebagai perbandingan, ketepatan model Mixtral jauh lebih rendah.
Rajah 6: Ketepatan keseluruhan model yang diuji pada BIG-Bench-Hard.
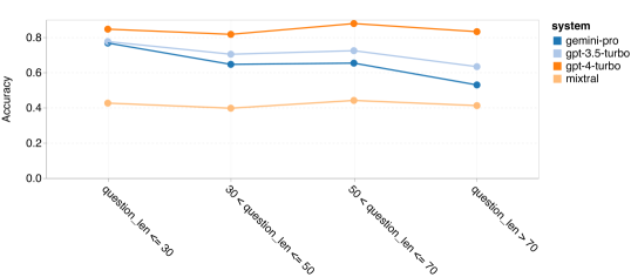
Pengarang mendalami sebab inferens am Gemini berprestasi buruk secara keseluruhan. Pertama, mereka meneliti ketepatan mengikut panjang soalan. Seperti yang ditunjukkan dalam Rajah 7, Gemini Pro berprestasi buruk pada masalah yang lebih panjang dan lebih kompleks. Dan model GPT, terutamanya GPT 4 Turbo, walaupun dalam masalah yang sangat lama, regresi GPT 4 Turbo adalah sangat kecil. Ini menunjukkan bahawa ia teguh dan mampu memahami soalan dan pertanyaan yang lebih panjang dan kompleks. Kekukuhan GPT 3.5 Turbo adalah sederhana. Mixtral menunjukkan prestasi yang stabil dari segi panjang soalan, tetapi mempunyai ketepatan keseluruhan yang lebih rendah.Rajah 7: Ketepatan model yang diuji pada BIG-Bench-Hard mengikut panjang soalan.
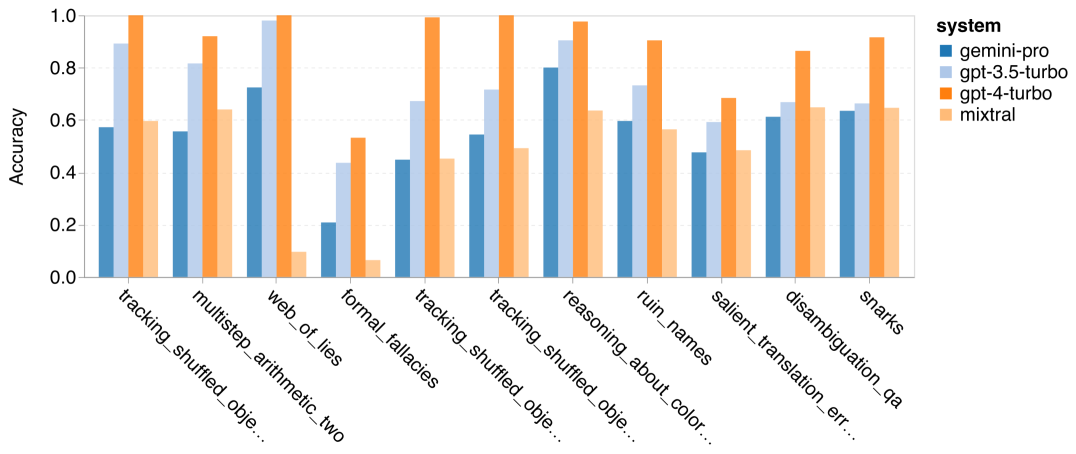
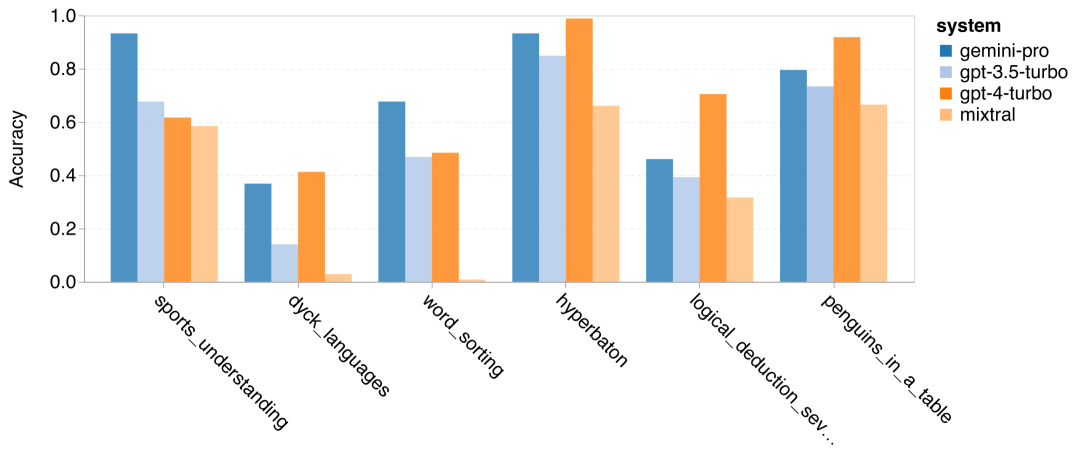
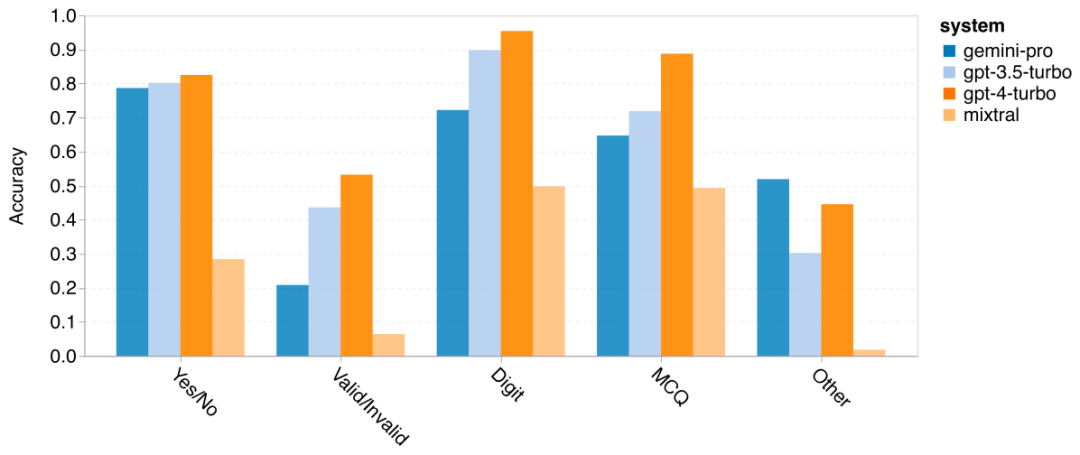
Pengarang menganalisis sama ada terdapat perbezaan dalam ketepatan model yang diuji dalam tugas BIG-Bench-Hard khusus. Rajah 8 menunjukkan tugas yang GPT 3.5 Turbo berprestasi lebih baik daripada Gemini Pro. Dalam tugas "menjejaki kedudukan objek berubah", Gemini Pro menunjukkan prestasi yang sangat teruk. Tugasan ini melibatkan orang yang bertukar-tukar barang dan menjejak siapa yang memiliki sesuatu, tetapi Gemini Pro sering bergelut untuk memastikan pesanan itu betul. Rajah 8: GPT 3.5 Turbo mengatasi Gemini Pro pada subtugasan BIG-Bench-Hard. Gemini Pro lebih rendah daripada Mixtral dalam tugasan seperti masalah aritmetik yang memerlukan penyelesaian pelbagai langkah, mencari kesilapan dalam terjemahan, dsb. Terdapat juga tugas di mana Gemini Pro lebih baik daripada GPT 3.5 Turbo. Rajah 9 menunjukkan enam tugasan di mana Gemini Pro mengetuai GPT 3.5 Turbo dengan margin terbesar. Tugas-tugas adalah heterogen dan termasuk yang memerlukan pengetahuan dunia (pemahaman_sukan), memanipulasi timbunan simbol (dyck_languages), menyusun perkataan mengikut abjad (word_sorting), dan menghurai jadual (penguin_in_a_table). Rajah 9: Gemini Pro mengatasi GPT 3.5 pada subtugasan BIG-Bench-Hard. Pengarang menganalisis lagi keteguhan model yang diuji dalam jenis jawapan yang berbeza, seperti yang ditunjukkan dalam Rajah 10. Gemini Pro menunjukkan prestasi paling teruk dalam jenis jawapan "Sah/Tidak Sah", yang tergolong dalam tugas formal_fallacies. Menariknya, 68.4% daripada soalan dalam tugasan ini tidak mempunyai jawapan. Walau bagaimanapun, dalam jenis jawapan lain (terdiri daripada tugasan word_sorting dan dyck_language), Gemini Pro mengatasi semua model GPT dan Mixtral. Iaitu, Gemini Pro sangat mahir dalam menyusun semula perkataan dan menjana simbol dalam susunan yang betul. Selain itu, untuk jawapan MCQ, 4.39% daripada soalan telah disekat daripada menjawab oleh Gemini Pro. Model GPT cemerlang dalam bidang ini, dan Gemini Pro bergelut untuk bersaing dengan mereka. Rajah 10: Ketepatan model yang diuji mengikut jenis jawapan pada BIG-Bench-Hard.
Ringkasnya, tiada model nampaknya mendahului tugas tertentu. Oleh itu, apabila melaksanakan tugas inferens tujuan umum, adalah wajar mencuba kedua-dua model Gemini dan GPT sebelum memutuskan model yang hendak digunakan. Untuk menilai keupayaan penaakulan matematik model yang diuji, penulis memilih empat set penanda aras masalah matematik: sekolah rendah penanda aras ;
(2) SVAMP: Semak keupayaan penaakulan yang mantap dengan menjana soalan dengan menukar susunan perkataan
(3) ASDIV: Dengan mod bahasa dan jenis soalan yang berbeza
(4) MAWPS: Mengandungi masalah perkataan aritmetik dan algebra.
Pengarang membandingkan ketepatan Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo dan Mixtral pada empat set ujian masalah matematik, menyemak prestasi keseluruhannya, prestasi di bawah kerumitan masalah yang berbeza dan rantaian pemikiran yang berbeza Prestasi secara mendalam.
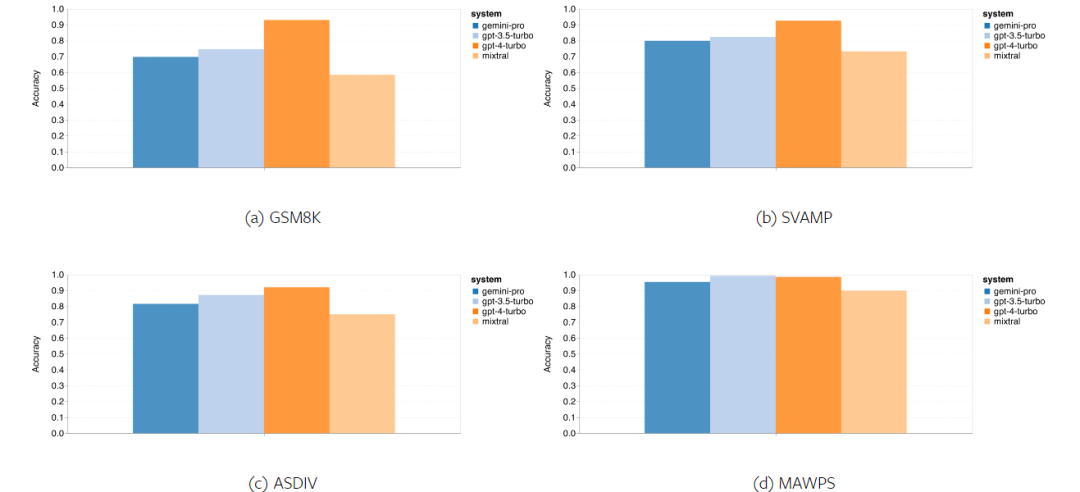
Rajah 11 membentangkan hasil keseluruhan, ketepatan Gemini Pro adalah lebih rendah sedikit daripada GPT 3.5 Turbo dan jauh lebih rendah daripada GPT 4 Turbo dalam tugas termasuk GSM8K, SVAMP dan ASDIV dengan mod bahasa yang berbeza. Untuk tugasan dalam MAWPS, Gemini Pro masih lebih rendah sedikit daripada model GPT, walaupun semua model yang diuji mencapai ketepatan lebih 90%. Dalam tugasan ini, GPT 3.5 Turbo hampir mengatasi prestasi GPT 4 Turbo. Sebagai perbandingan, ketepatan model Mixtral jauh lebih rendah daripada model lain.
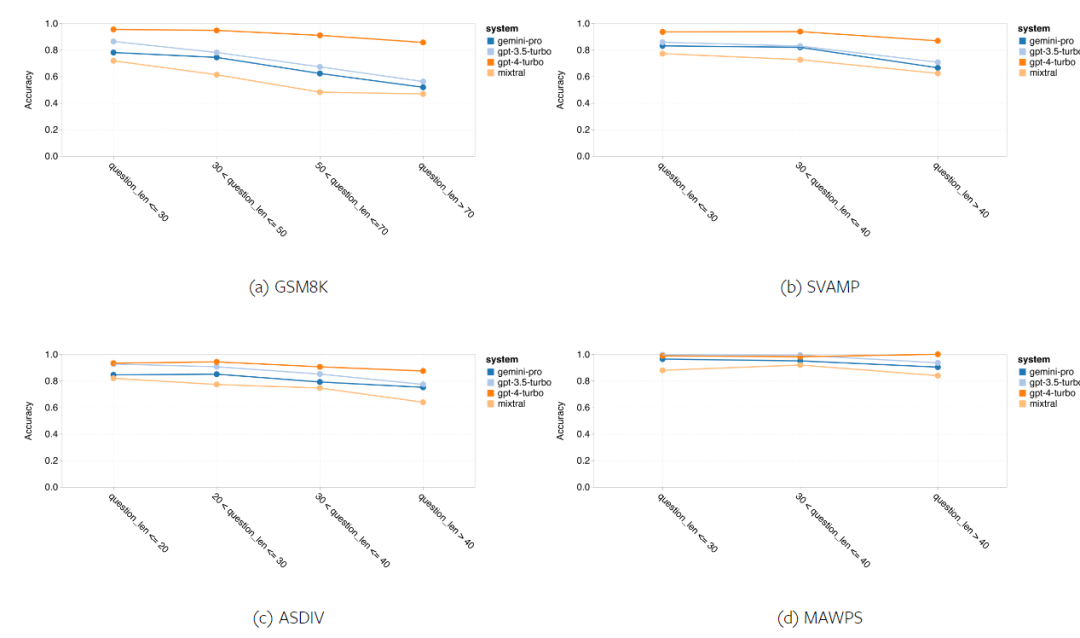
Rajah 11: Ketepatan keseluruhan model yang diuji dalam empat tugasan set ujian penaakulan matematik. Keteguhan setiap model kepada panjang masalah ditunjukkan dalam Rajah 12. Sama seperti tugas inferens dalam BIG-Bench Hard, model yang diuji menunjukkan ketepatan yang berkurangan apabila menjawab soalan yang lebih panjang.GPT 3.5 Turbo berprestasi lebih baik daripada Gemini Pro pada soalan yang lebih pendek, tetapi mundur lebih cepat, dan Gemini Pro serupa dengan GPT 3.5 Turbo dalam ketepatan pada soalan yang lebih panjang, tetapi masih ketinggalan sedikit.
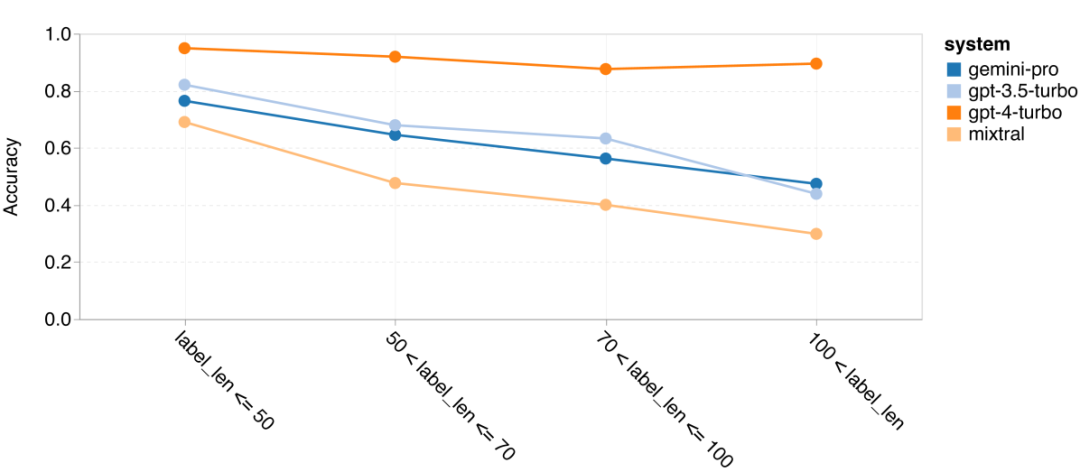
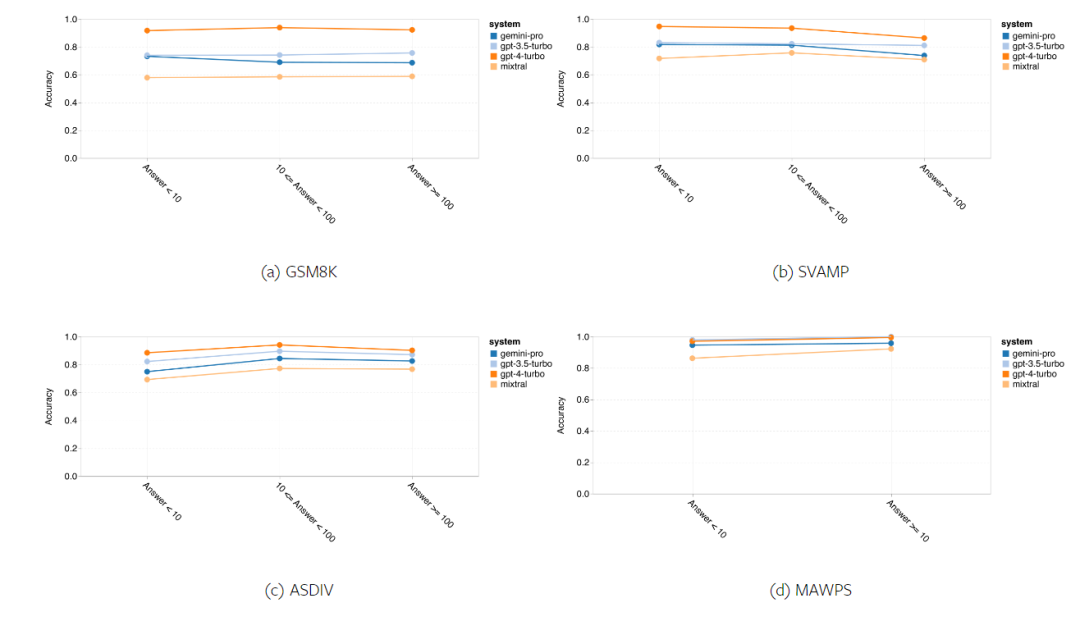
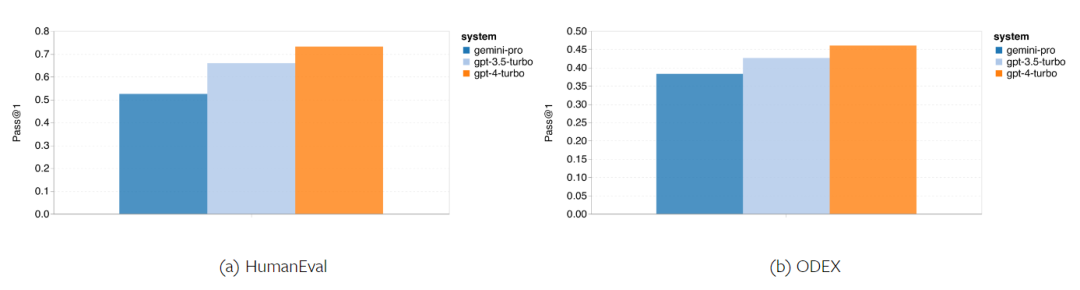
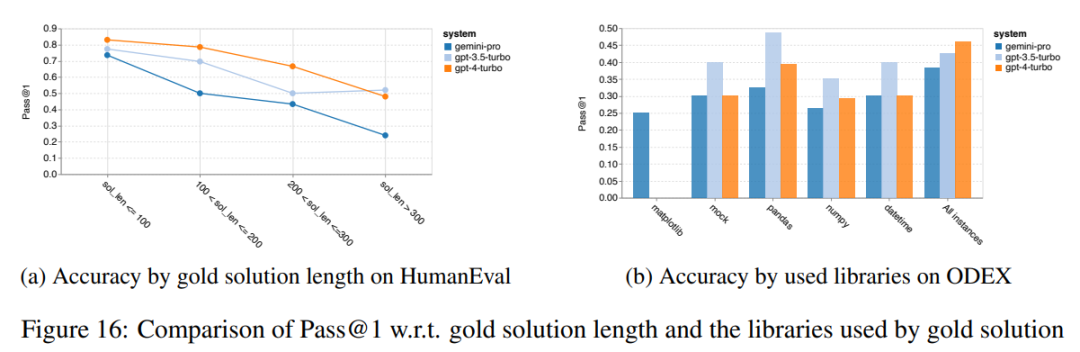
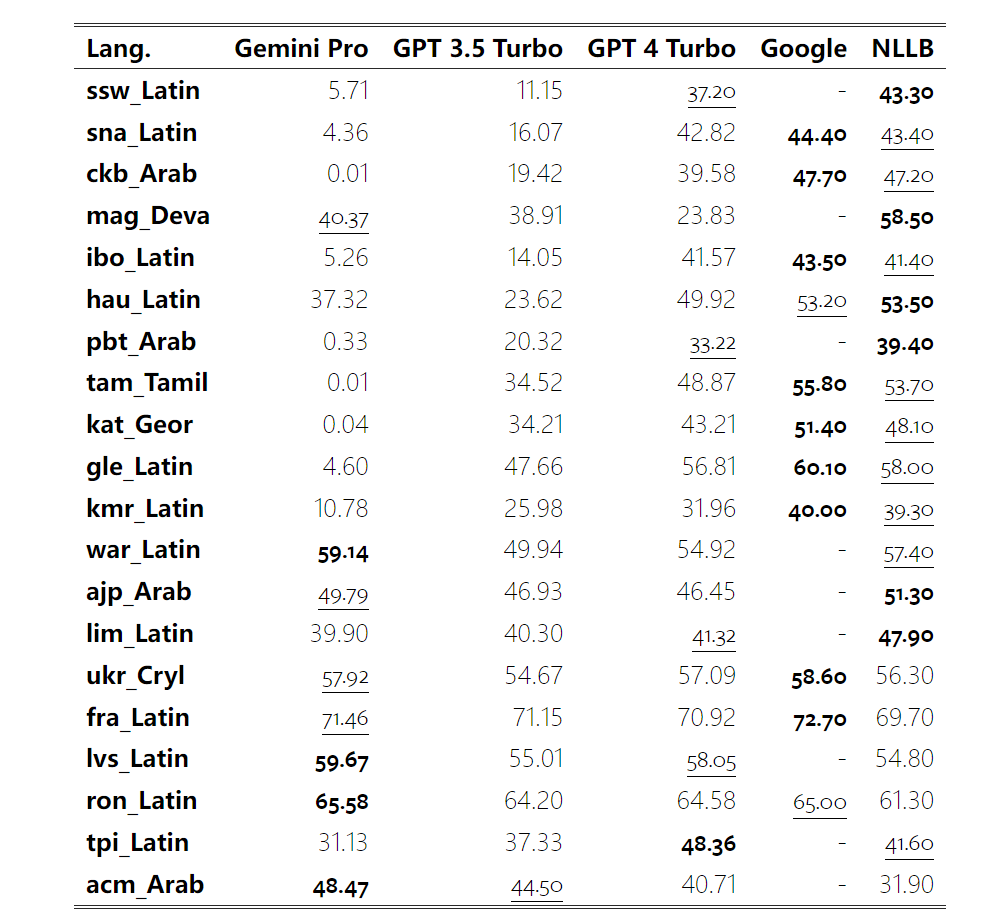
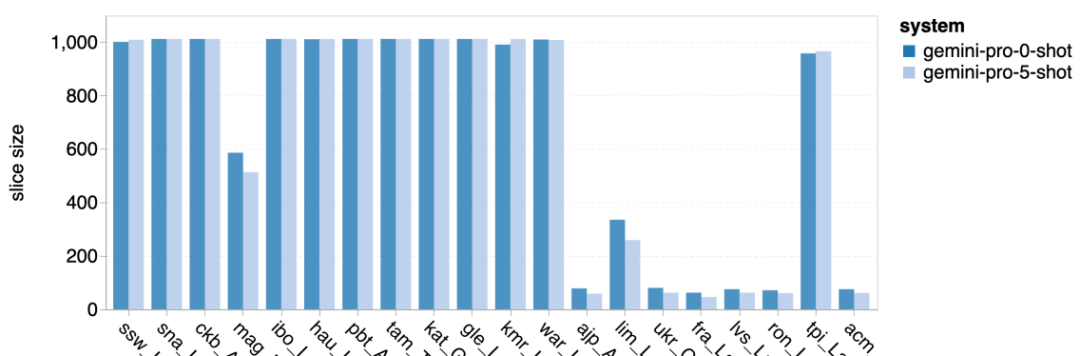
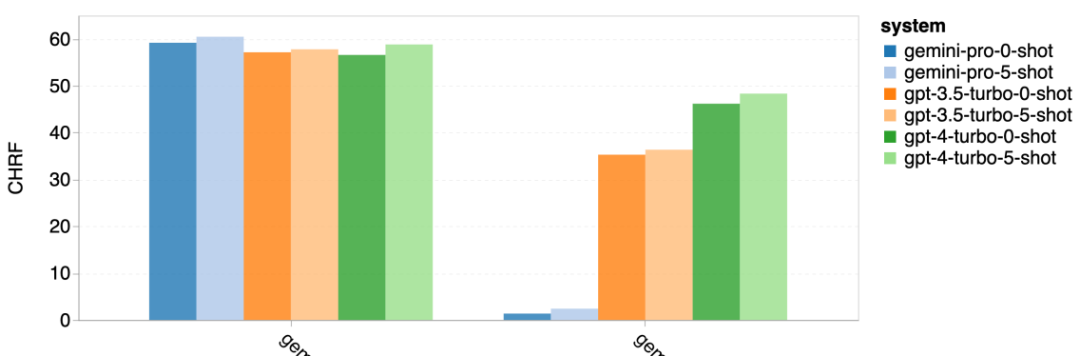
Rajah 12: Ketepatan model yang diuji dalam menjana jawapan untuk panjang soalan yang berbeza dalam empat tugasan set ujian penaakulan matematik. Selain itu, pengarang memerhatikan perbezaan ketepatan model yang diuji apabila jawapannya memerlukan rantaian pemikiran yang lebih panjang. Seperti yang ditunjukkan dalam Rajah 13, GPT 4 Turbo sangat teguh walaupun menggunakan rantai inferens yang panjang, manakala GPT 3.5 Turbo, Gemini Pro dan Mixtral menunjukkan had apabila panjang COT meningkat. Melalui analisis, penulis juga mendapati Gemini Pro mengatasi GPT 3.5 Turbo dalam contoh kompleks dengan panjang COT melebihi 100, tetapi berprestasi buruk dalam contoh yang lebih pendek. Rajah 13: Ketepatan setiap model pada GSM8K di bawah panjang rantaian pemikiran yang berbeza. Rajah 14 menunjukkan ketepatan model yang diuji dalam menjana jawapan untuk nombor digit yang berbeza. Pengarang mencipta tiga "baldi" berdasarkan sama ada jawapan mengandungi 1, 2, atau 3 atau lebih digit (kecuali tugas MAWPS, yang tidak mempunyai jawapan dengan lebih daripada dua digit). Seperti yang ditunjukkan dalam rajah, GPT 3.5 Turbo nampaknya lebih mantap kepada masalah matematik berbilang digit, manakala Gemini Pro merendahkan masalah dengan nombor yang lebih tinggi. Rajah 14: Ketepatan setiap model dalam empat tugasan set ujian penaakulan matematik apabila bilangan digit jawapan berbeza. Dalam bahagian ini, penulis menggunakan dua set data penjanaan kod - HumanEval dan ODEX - untuk menguji keupayaan pengekodan model. Yang pertama menguji pemahaman kod asas model tentang set fungsi terhad dalam perpustakaan standard Python, dan yang terakhir menguji keupayaan model untuk menggunakan set perpustakaan yang lebih luas merentas ekosistem Python. Input untuk kedua-dua masalah ialah arahan tugasan yang ditulis dalam bahasa Inggeris (biasanya dengan kes ujian). Soalan-soalan ini digunakan untuk menilai pemahaman bahasa model, pemahaman algoritma, dan keupayaan matematik asas. Secara keseluruhan, HumanEval mempunyai 164 sampel ujian dan ODEX mempunyai 439 sampel ujian. Pertama sekali, daripada keputusan keseluruhan yang ditunjukkan dalam Rajah 15, kita dapat melihat bahawa markah Pass@1 Gemini Pro pada kedua-dua tugas adalah lebih rendah daripada GPT 3.5 Turbo dan jauh lebih rendah daripada GPT 4 Turbo. Keputusan ini menunjukkan bahawa keupayaan penjanaan kod Gemini memberi ruang untuk penambahbaikan. Rajah 15: Ketepatan keseluruhan setiap model dalam tugas penjanaan kod. Kedua, penulis menganalisis hubungan antara panjang larutan emas dan prestasi model dalam Rajah 16 (a). Panjang penyelesaian boleh, pada tahap tertentu, menunjukkan kesukaran tugas penjanaan kod yang sepadan. Penulis mendapati Gemini Pro mencapai markah Pass@1 yang setanding dengan GPT 3.5 apabila panjang penyelesaian adalah di bawah 100 (seperti dalam kes yang lebih mudah), tetapi ia ketinggalan dengan ketara apabila panjang penyelesaian semakin panjang. Ini adalah kontras yang menarik dengan hasil bahagian sebelumnya, di mana pengarang mendapati bahawa Gemini Pro secara amnya teguh kepada input dan output yang lebih panjang dalam tugasan Bahasa Inggeris. Pengarang juga menganalisis kesan perpustakaan yang diperlukan untuk setiap penyelesaian terhadap prestasi model dalam Rajah 16(b). Dalam kebanyakan kes penggunaan perpustakaan, seperti olok-olok, panda, numpy dan datetime, Gemini Pro berprestasi lebih teruk daripada GPT 3.5. Walau bagaimanapun, dalam kes penggunaan matplotlib, ia mengatasi GPT 3.5 dan GPT 4, menunjukkan keupayaannya yang lebih besar untuk melaksanakan visualisasi plot melalui kod. Akhir sekali, pengarang menunjukkan beberapa kes kegagalan tertentu di mana Gemini Pro berprestasi lebih teruk daripada GPT 3.5 dalam penjanaan kod. Mula-mula, mereka perasan bahawa Gemini agak lemah dalam memilih fungsi dan parameter dengan betul dalam API Python.Contohnya, diberikan gesaan berikut: Gemini Pro menjana kod berikut, yang mengakibatkan ralat tidak padan jenis: Sebaliknya, GPT 3.5 Turbo menggunakan kod berikut, yang mencapai kesan yang diingini: Selain itu, Gemini Pro mempunyai peratusan ralat yang lebih tinggi, di mana kod yang dilaksanakan adalah betul dari segi sintaksis tetapi tidak sepadan dengan betul dengan niat yang lebih kompleks. Contohnya, mengenai petua berikut: Gemini Pro telah mencipta pelaksanaan yang hanya mengekstrak nombor unik tanpa mengalih keluar nombor yang muncul beberapa kali. Set eksperimen ini menggunakan tanda aras terjemahan mesin FLORES-200 untuk menilai keupayaan berbilang bahasa model, khususnya keupayaannya untuk menterjemah antara pelbagai pasangan bahasa. Pengarang memfokuskan pada subset berbeza daripada 20 bahasa yang digunakan dalam analisis Robinson et al. (2023), meliputi pelbagai peringkat ketersediaan sumber dan kesukaran terjemahan. Penulis menilai 1012 ayat dalam set ujian untuk semua pasangan bahasa yang dipilih. Dalam Jadual 4 dan 5, penulis menjalankan analisis perbandingan Gemini Pro, GPT 3.5 Turbo dan GPT 4 Turbo dengan sistem matang seperti Terjemahan Google. Selain itu, mereka menanda aras NLLB-MoE, model terjemahan mesin sumber terbuka terkemuka yang terkenal dengan liputan bahasa yang luas. Hasilnya menunjukkan bahawa Terjemahan Google mengatasi model lain secara keseluruhan, berprestasi baik pada 9 bahasa, diikuti oleh NLLB, yang berprestasi baik pada 6/8 bahasa di bawah tetapan 0/5-shot. Model bahasa tujuan am telah menunjukkan prestasi yang kompetitif tetapi belum lagi mengatasi sistem terjemahan mesin khusus dalam terjemahan ke dalam bahasa bukan bahasa Inggeris. Jadual 4: Prestasi (skor chRF (%) bagi setiap model untuk terjemahan mesin merentas semua bahasa menggunakan petunjuk 0-shot. Skor terbaik ditunjukkan dalam huruf tebal dan skor terbaik seterusnya digariskan.
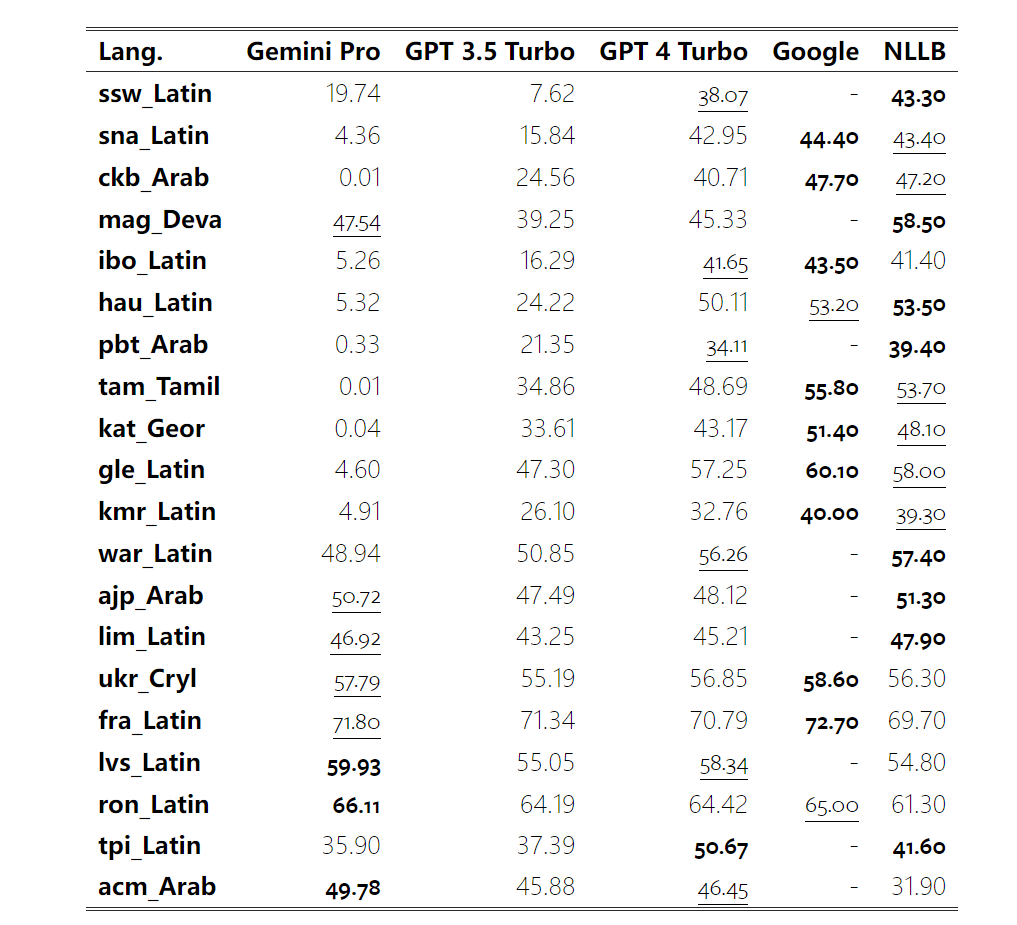
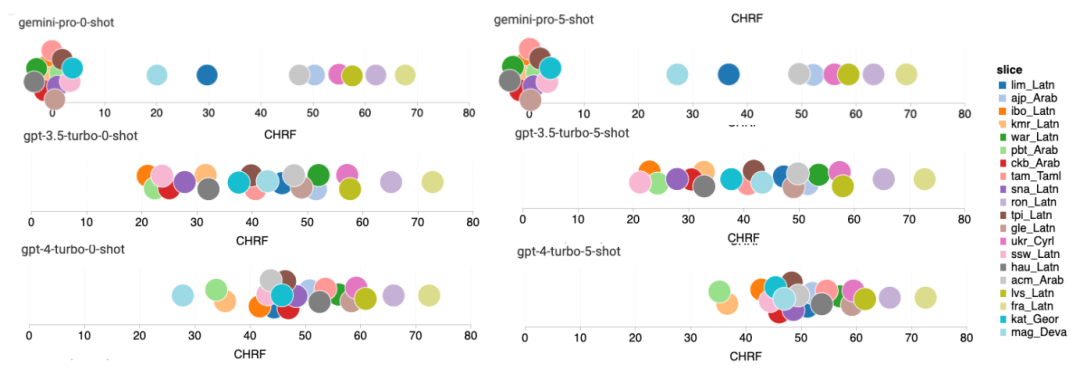
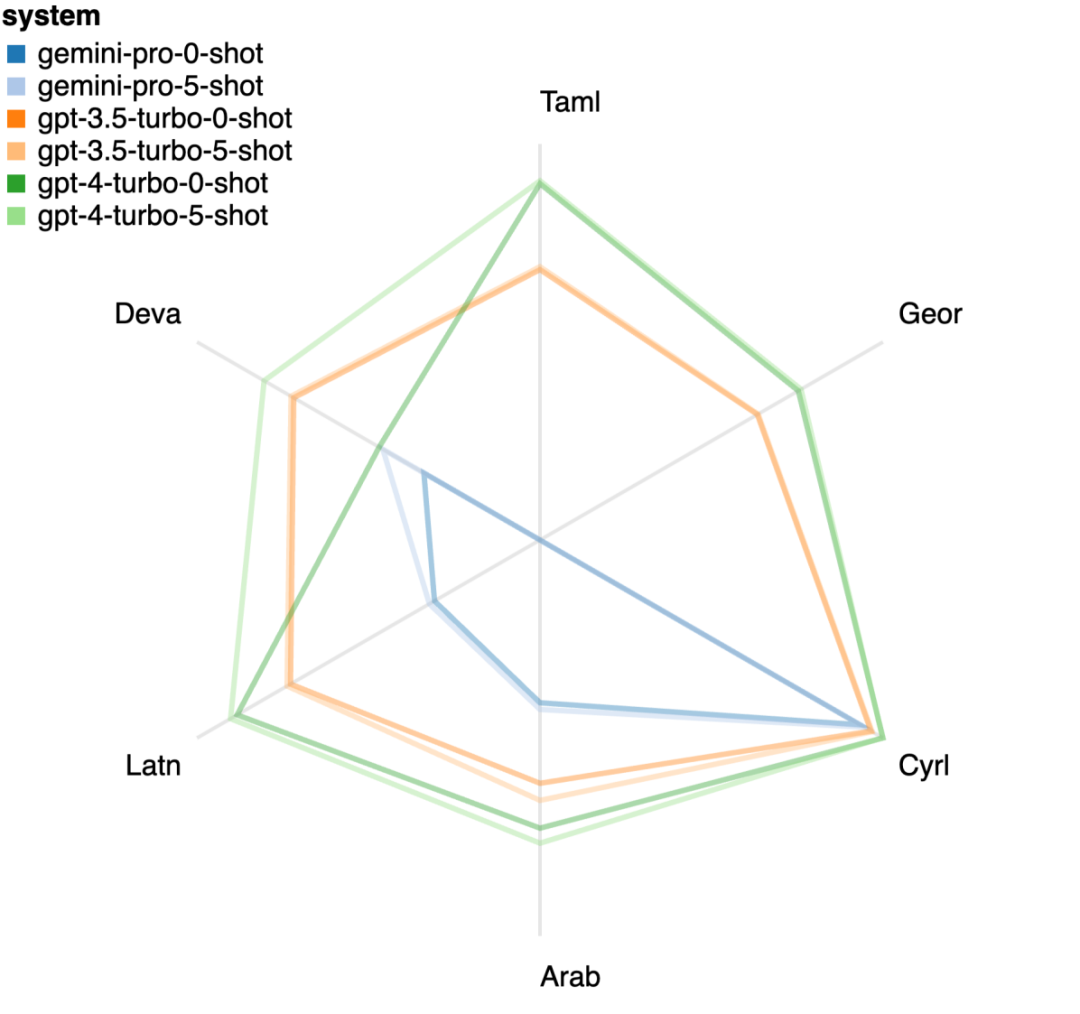
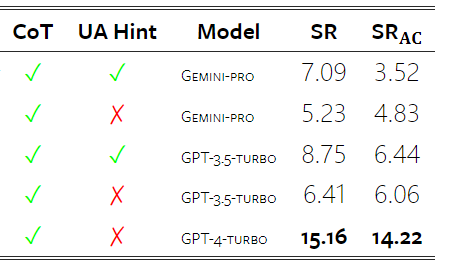
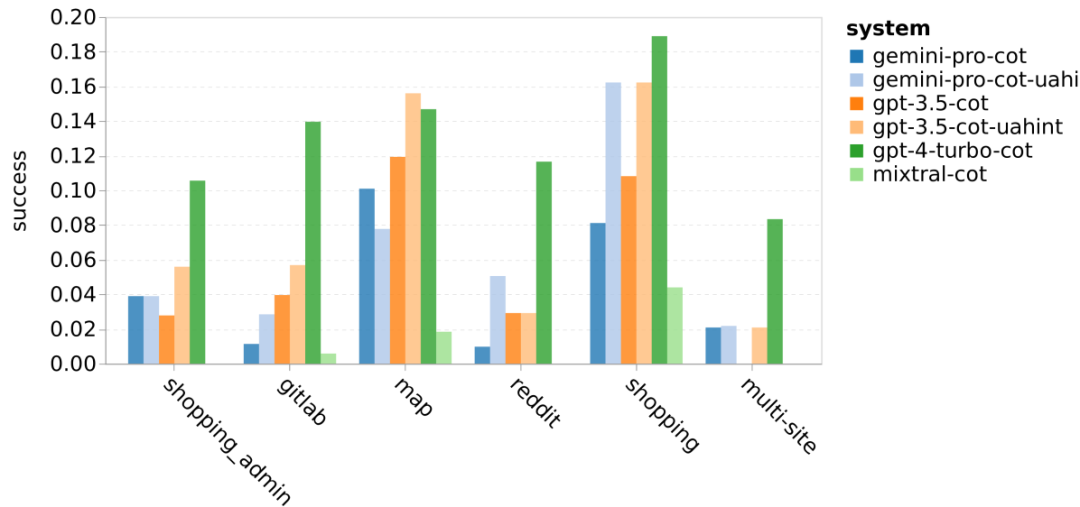
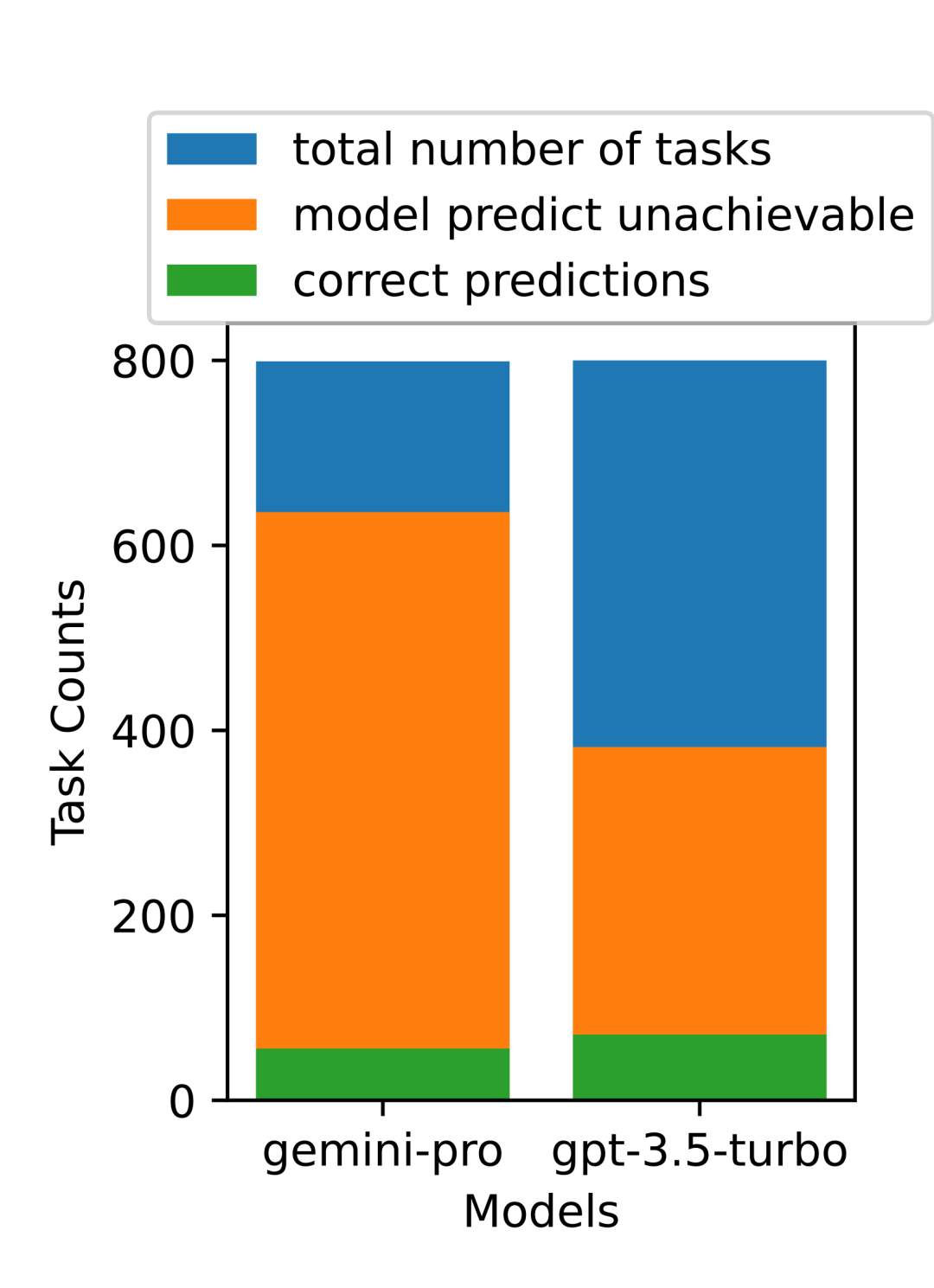
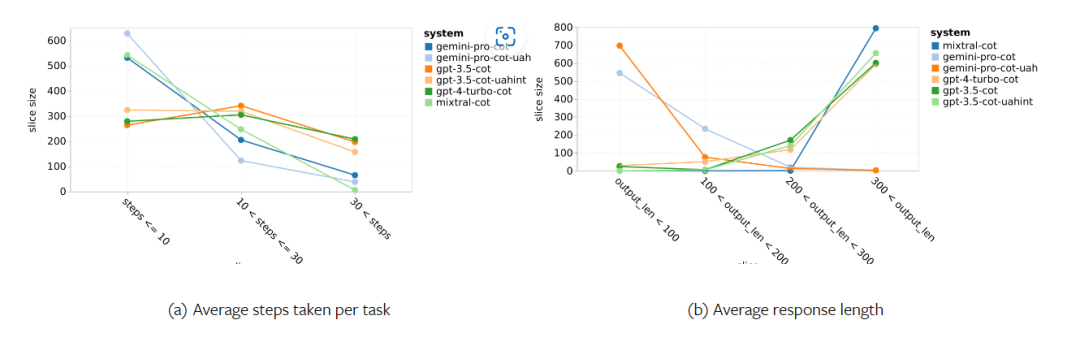
Jadual 5: Prestasi (skor chRF (%) bagi setiap model untuk terjemahan mesin menggunakan petunjuk 5 tangkapan untuk semua bahasa. Skor terbaik ditunjukkan dalam huruf tebal dan skor terbaik seterusnya digariskan. Rajah 17 menunjukkan perbandingan prestasi model bahasa umum merentas pasangan bahasa yang berbeza. GPT 4 Turbo mempamerkan sisihan prestasi yang konsisten dengan NLLB berbanding GPT 3.5 Turbo dan Gemini Pro. GPT 4 Turbo juga mempunyai peningkatan yang lebih besar dalam bahasa sumber rendah, manakala dalam bahasa sumber tinggi, prestasi kedua-dua LLM adalah serupa. Sebagai perbandingan, Gemini Pro mengatasi GPT 3.5 Turbo dan GPT 4 Turbo pada 8 daripada 20 bahasa dan mencapai prestasi terbaik pada 4 bahasa. Walau bagaimanapun, Gemini Pro menunjukkan kecenderungan kuat untuk menyekat respons dalam kira-kira 10 pasangan bahasa. Rajah 17: Prestasi terjemahan mesin (skor chRF (%) mengikut pasangan bahasa. Rajah 18 menunjukkan bahawa Gemini Pro mempunyai prestasi yang lebih rendah dalam bahasa ini kerana ia cenderung untuk menutup respons dalam senario keyakinan yang lebih rendah. Jika Gemini Pro menjana ralat "Respons Tersekat" dalam konfigurasi 0-shot atau 5-shot, respons itu dianggap "disekat." Rajah 18: Bilangan sampel yang disekat oleh Gemini Pro. Pemerhatian lebih dekat pada Rajah 19 menunjukkan Gemini Pro sedikit mengatasi prestasi GPT 3.5 Turbo dan GPT 4 Turbo dalam sampel tanpa perisai dengan keyakinan yang lebih tinggi.Khususnya, ia mengatasi GPT 4 Turbo dengan 1.6 chrf dan 2.6 chrf masing-masing pada tetapan 5-shot dan 0-shot, dan mengatasi GPT 3.5 Turbo dengan 2.7 chrf dan 2 chrf. Walau bagaimanapun, analisis awal pengarang terhadap prestasi GPT 4 Turbo dan GPT 3.5 Turbo pada sampel ini menunjukkan bahawa terjemahan sampel ini secara amnya lebih mencabar. Gemini Pro berprestasi buruk pada sampel tertentu ini, dan amat ketara bahawa Gemini Pro 0-shot bertindak balas manakala 5-shot tidak, dan begitu juga sebaliknya. Rajah 19: prestasi chrf (%) untuk sampel bertopeng dan tidak bertopeng. Sepanjang analisis model, penulis memerhatikan bahawa petunjuk beberapa pukulan secara amnya meningkatkan prestasi purata secara sederhana, dengan peningkatan corak varians: GPT 4 Turbo Rajah 20 menunjukkan arah aliran yang jelas mengikut keluarga bahasa atau skrip. Pemerhatian penting ialah Gemini Pro berprestasi secara kompetitif dengan model lain pada skrip Cyrillic, tetapi tidak begitu baik pada skrip lain. GPT-4 berprestasi cemerlang pada pelbagai skrip, mengatasi model lain, antaranya petunjuk beberapa tangkapan amat berkesan. Kesan ini amat ketara dalam bahasa yang menggunakan bahasa Sanskrit. Rajah 20: Prestasi setiap model pada skrip berbeza (chrf (%)). Akhir sekali, penulis meneliti keupayaan setiap model sebagai ejen navigasi rangkaian, tugas yang memerlukan perancangan jangka panjang dan pemahaman data yang kompleks. Mereka menggunakan persekitaran simulasi, WebArena, di mana kejayaan diukur dengan hasil pelaksanaan. Tugas yang diberikan kepada ejen termasuk carian maklumat, navigasi tapak web dan manipulasi kandungan dan konfigurasi. Tugas merangkumi pelbagai tapak web, termasuk platform e-dagang, forum sosial, platform pembangunan perisian kerjasama (seperti gitlab), sistem pengurusan kandungan dan peta dalam talian. Pengarang menguji kadar kejayaan keseluruhan Gemini-Pro, kadar kejayaan pada tugasan yang berbeza, panjang tindak balas, langkah trajektori dan kecenderungan untuk meramal kegagalan tugas. Jadual 6 menyenaraikan prestasi keseluruhan. Prestasi Gemini-Pro hampir dengan, tetapi lebih rendah sedikit daripada, GPT-3.5-Turbo. Sama seperti GPT-3.5-Turbo, Gemini-Pro berprestasi lebih baik apabila pembayang menyebut bahawa tugas itu mungkin tidak selesai (petunjuk UA). Dengan petunjuk UA, Gemini-Pro mempunyai kadar kejayaan keseluruhan 7.09%. Jadual 6: Prestasi setiap model di WebArena. Jika anda membahagikannya mengikut jenis tapak web, seperti yang ditunjukkan dalam Rajah 21, anda dapat melihat bahawa Gemini-Pro berprestasi lebih teruk daripada GPT-3.5-Turbo pada gitlab dan peta, manakala pada pengurusan membeli-belah, reddit dan membeli-belah laman web Prestasinya hampir dengan GPT-3.5-Turbo. Pada tugasan berbilang tapak, Gemini-Pro mengatasi GPT-3.5-Turbo, yang konsisten dengan keputusan sebelumnya yang menunjukkan Gemini berprestasi lebih baik sedikit pada subtugas yang lebih kompleks merentas pelbagai penanda aras. Rajah 21: Kadar kejayaan ejen web model pada pelbagai jenis tapak web. Seperti yang ditunjukkan dalam Rajah 22, secara amnya, Gemini-Pro meramalkan lebih banyak tugasan sebagai mustahil untuk diselesaikan, terutamanya apabila pembayang UA diberikan. Gemini-Pro meramalkan bahawa lebih daripada 80.6% tugas tidak dapat disiapkan berdasarkan petunjuk UA, manakala GPT-3.5-Turbo hanya meramalkan 47.7%. Adalah penting untuk ambil perhatian bahawa hanya 4.4% daripada tugasan dalam set data sebenarnya tidak boleh dicapai, jadi kedua-duanya terlalu menganggarkan bilangan sebenar tugas yang tidak boleh dicapai. Rajah 22: Nombor ramalan UA. Pada masa yang sama, pengarang memerhatikan Gemini Pro lebih berkemungkinan membalas dengan frasa yang lebih pendek, mengambil lebih sedikit langkah sebelum membuat kesimpulan. Seperti yang ditunjukkan dalam Rajah 23(a), Gemini Pro mempunyai lebih separuh daripada trajektorinya dengan kurang daripada 10 langkah, manakala kebanyakan trajektori GPT 3.5 Turbo dan GPT 4 Turbo adalah antara 10 dan 30 langkah.Begitu juga, kebanyakan balasan Gemini adalah kurang daripada 100 aksara, manakala kebanyakan balasan GPT 3.5 Turbo, GPT 4 Turbo dan Mixtral adalah lebih daripada 300 aksara (Rajah 23(b)). Gemini cenderung untuk meramalkan tindakan secara langsung, manakala model lain membuat alasan terlebih dahulu dan kemudian memberikan ramalan tindakan. Rajah 23: Tingkah laku model di WebArena. Sila rujuk kertas asal untuk butiran lanjut. Atas ialah kandungan terperinci Ulasan penuh Gemini: Dari CMU hingga GPT 3.5 Turbo, Gemini Pro kalah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



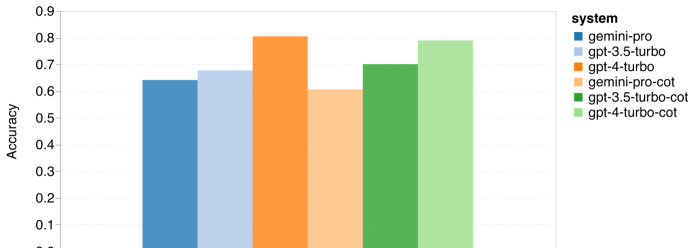 Seperti yang anda lihat daripada rajah, ketepatan Gemini Pro adalah lebih rendah daripada GPT 3.5 Turbo, dan jauh lebih rendah daripada GPT 4 Turbo.Apabila menggunakan gesaan rantaian pemikiran, terdapat sedikit perbezaan dalam prestasi setiap model. Penulis membuat spekulasi bahawa ini disebabkan oleh fakta bahawa MMLU terutamanya menangkap tugasan soalan dan jawapan berasaskan pengetahuan, yang mungkin tidak mendapat manfaat dengan ketara daripada gesaan berorientasikan penaakulan yang lebih kuat.
Seperti yang anda lihat daripada rajah, ketepatan Gemini Pro adalah lebih rendah daripada GPT 3.5 Turbo, dan jauh lebih rendah daripada GPT 4 Turbo.Apabila menggunakan gesaan rantaian pemikiran, terdapat sedikit perbezaan dalam prestasi setiap model. Penulis membuat spekulasi bahawa ini disebabkan oleh fakta bahawa MMLU terutamanya menangkap tugasan soalan dan jawapan berasaskan pengetahuan, yang mungkin tidak mendapat manfaat dengan ketara daripada gesaan berorientasikan penaakulan yang lebih kuat.