
Rumah >Peranti teknologi >AI >Mistral bekerjasama dengan Microsoft untuk membawa revolusi kepada 'model bahasa kecil'. Keupayaan kod bersaiz sederhana Mistral mengatasi GPT-4 dan mengurangkan kos sebanyak 2/3
Mistral bekerjasama dengan Microsoft untuk membawa revolusi kepada 'model bahasa kecil'. Keupayaan kod bersaiz sederhana Mistral mengatasi GPT-4 dan mengurangkan kos sebanyak 2/3

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-12-17 14:15:35708semak imbas
Baru-baru ini, "model bahasa kecil" tiba-tiba menjadi topik hangat
Pada hari Isnin, syarikat permulaan AI Perancis Mistral, yang baru sahaja menyelesaikan pembiayaan AS$415 juta, mengeluarkan model Mixtral 8x7B.
Walaupun model sumber terbuka ini tidak bersaiz besar dan cukup kecil untuk dijalankan pada komputer dengan lebih daripada 100GB memori, ia mampu mengikat dengan GPT-3.5 dalam beberapa ujian penanda aras, jadi ia dengan cepat menjadi popular di kalangan pemaju memenangi banyak pujian.
Sebab mengapa Mixtral 8x7B dipanggil adalah kerana ia menggabungkan pelbagai model yang lebih kecil yang dilatih untuk mengendalikan tugas tertentu, dengan itu meningkatkan kecekapan operasi.
Model "sparse expert mixture" ini bukan mudah untuk dilaksanakan Dikatakan OpenAI terpaksa meninggalkan pembangunan model tersebut awal tahun ini kerana tidak dapat menjadikan model MoE berjalan dengan baik.
Keesokan harinya, Microsoft mengeluarkan versi baharu model kecil Phi-2.

Phi-2 hanya mempunyai 2.7 bilion parameter, yang jauh lebih kecil daripada Mistral dan hanya cukup untuk dijalankan pada telefon bimbit. Sebagai perbandingan, GPT-4 mempunyai saiz parameter sehingga satu trilion
Phi-2 dilatih pada set data yang dipilih dengan teliti, dan kualiti set data cukup tinggi, jadi walaupun kuasa pengkomputeran mudah alih telefon adalah terhad, ia boleh Ini memastikan model menjana hasil yang tepat.
Walaupun tidak jelas cara Microsoft atau pembuat perisian lain akan menggunakan model kecil, faedah yang paling jelas ialah ia mengurangkan kos menjalankan aplikasi AI pada skala dan meluaskan skop aplikasi teknologi AI generatif.
Ini adalah acara penting
Penjanaan kod medium-Mistral sepenuhnya mengalahkan GPT-4
Baru-baru ini, Mistral-medium telah memulakan ujian dalaman
Blogger Mistral-membandingkan kod sumber terbuka keupayaan penjanaan medium dan GPT-4, keputusan menunjukkan bahawa Mistral-medium mempunyai keupayaan penjanaan kod yang lebih kuat daripada GPT-4, tetapi kosnya hanya 30% daripada GPT-4! . 3) Cadangan yang diberikan adalah sangat spesifik
Pertama, tulis kod pengoptimuman cuda untuk menjana set data PyTorch bagi bilangan prima Fibonacci
Kod yang dijana oleh Mistral-Medium adalah serius dan lengkap.
Kod yang dijana oleh GPT-4 hampir tidak okey
Membazirkan banyak token tetapi tidak mengeluarkan sebarang maklumat berguna.
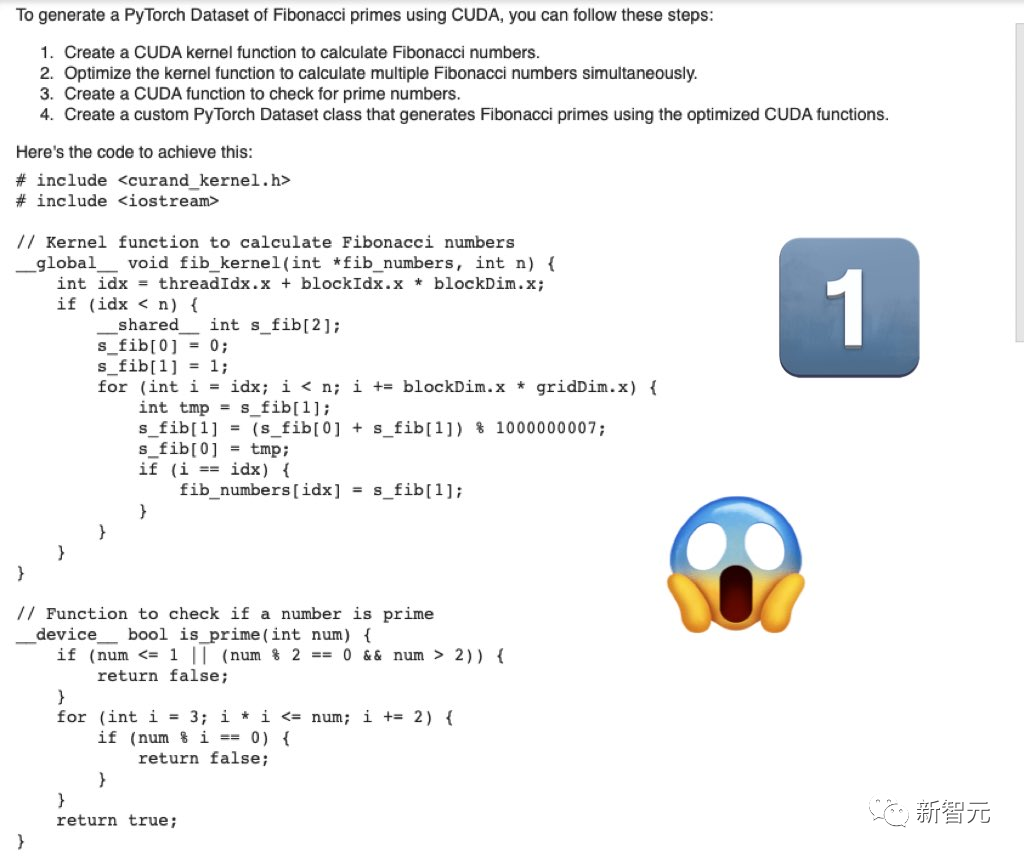 Kemudian, GPT-4 hanya memberikan kod rangka dan tiada kod berkaitan khusus.
Kemudian, GPT-4 hanya memberikan kod rangka dan tiada kod berkaitan khusus.
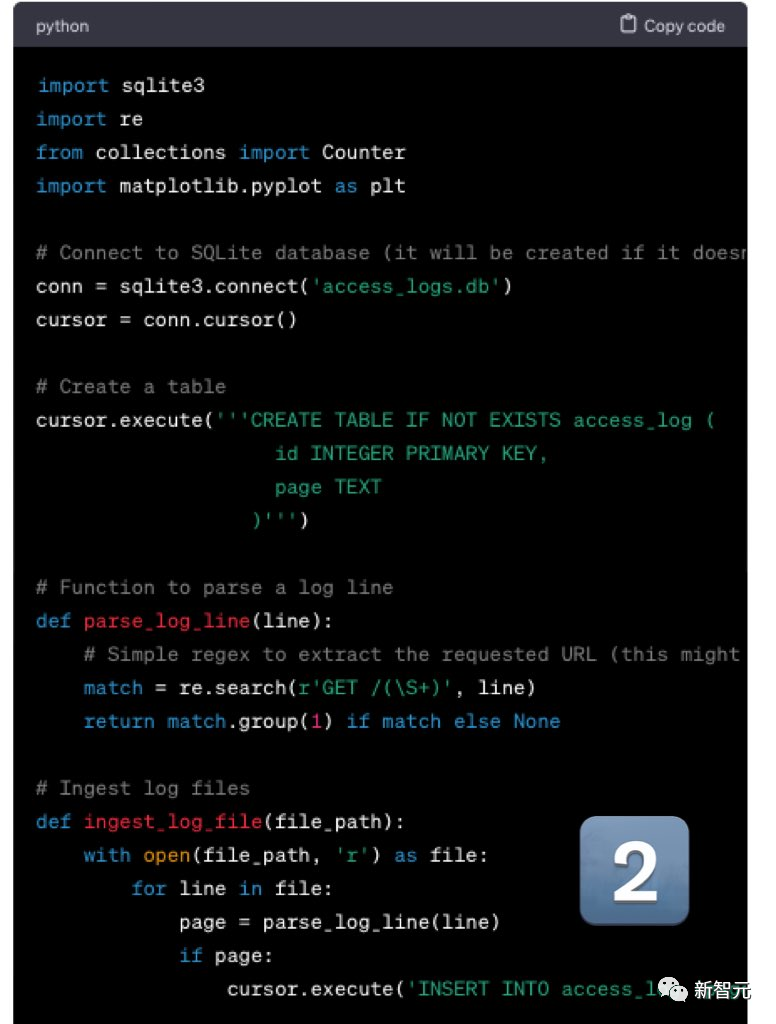
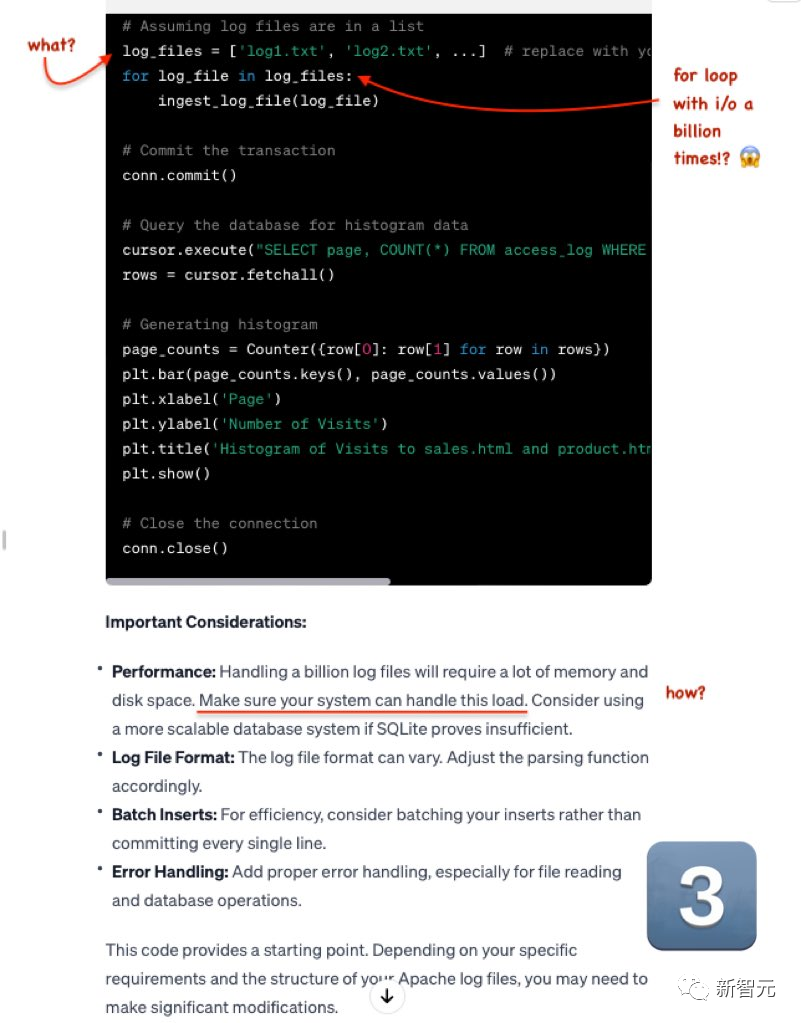
Soalan kedua ialah: Tulis kod Python yang cekap untuk mengimport kira-kira 1 bilion fail akses HTTP Apache yang besar ke dalam pangkalan data SqlLite, dan kemudian gunakannya untuk menjana histogram akses kepada sales.html dan product.html
Mistral Outputnya ialah sangat baik. Walaupun fail log tidak dalam format CSV, ia adalah sangat mudah untuk diubah suai GPT-4.
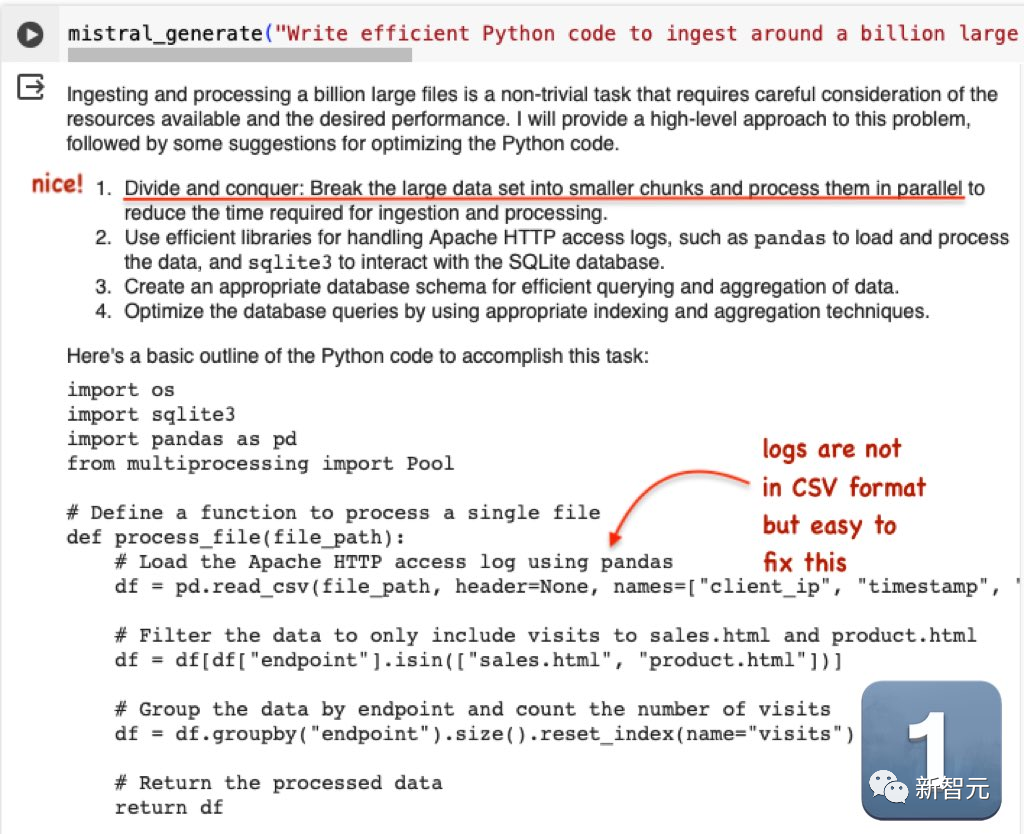


Sebelum ini, blogger ini telah menguji beberapa model penjanaan kod, dan GPT-4 sentiasa menduduki tempat pertama.
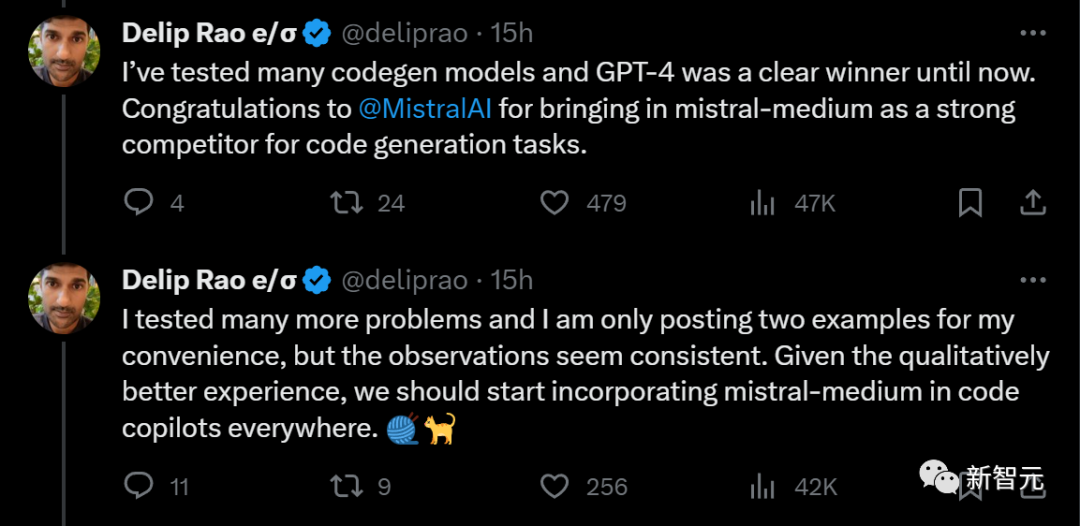
 Pada masa ini, pesaing yang kuat, Mistral-medium, akhirnya muncul dan menolaknya dari takhtanya
Pada masa ini, pesaing yang kuat, Mistral-medium, akhirnya muncul dan menolaknya dari takhtanya
Dia membuat cadangan: Memandangkan Mistral-medium menyediakan pengalaman yang lebih baik dari segi kualiti penjanaan kod, ia harus disepadukan ke dalam pembantu kod di mana-mana sahaja
Seseorang mengira input dan output setiap 1000 kos Mistral-medium didapati dikurangkan secara langsung sebanyak 70% berbanding GPT-4!
Sesungguhnya, penjimatan 70% daripada yuran token adalah masalah besar. Selain itu, melalui output yang ringkas, kos dapat dikurangkan lagi
Atas ialah kandungan terperinci Mistral bekerjasama dengan Microsoft untuk membawa revolusi kepada 'model bahasa kecil'. Keupayaan kod bersaiz sederhana Mistral mengatasi GPT-4 dan mengurangkan kos sebanyak 2/3. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!