
Rumah >Peranti teknologi >AI >NVIDIA menampar AMD di muka: Dengan sokongan perisian, prestasi AI H100 adalah 47% lebih pantas daripada MI300X!
NVIDIA menampar AMD di muka: Dengan sokongan perisian, prestasi AI H100 adalah 47% lebih pantas daripada MI300X!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-12-15 18:15:121392semak imbas

Menurut berita pada 14 Disember, AMD melancarkan cip AI yang paling berkuasa, Instinct MI300X, pada awal bulan ini Prestasi AI pelayan 8-GPUnya adalah 60% lebih tinggi daripada NVIDIA H100 8-GPU. Dalam hal ini, NVIDIA baru-baru ini mengeluarkan satu set data perbandingan prestasi terkini antara H100 dan MI300X, menunjukkan bagaimana H100 boleh menggunakan perisian yang betul untuk memberikan prestasi AI yang lebih pantas daripada MI300X.
Menurut data yang dikeluarkan oleh AMD sebelum ini, prestasi FP8/FP16 MI300X telah mencapai 1.3 kali ganda berbanding NVIDIA H100, dan kelajuan menjalankan model Llama 2 70B dan FlashAttention 2 adalah 20% lebih pantas daripada H100. Dalam pelayan 8v8, apabila menjalankan model Llama 2 70B, MI300X adalah 40% lebih pantas daripada H100 apabila menjalankan model Bloom 176B, MI300X adalah 60% lebih pantas daripada H100;
Namun, perlu diingatkan bahawa apabila AMD membandingkan MI300X dengan NVIDIA H100, AMD menggunakan perpustakaan pengoptimuman dalam suite ROCm 6.0 terkini (yang boleh menyokong format pengkomputeran terkini, seperti FP16, Bf16 dan FP8, termasuk Sparsity, dsb. ), untuk mendapatkan nombor ini. Sebaliknya, NVIDIA H100 tidak diuji tanpa menggunakan perisian pengoptimuman seperti TensorRT-LLM NVIDIA.
Pernyataan tersirat AMD pada ujian NVIDIA H100 menunjukkan bahawa menggunakan perisian inferens vLLM v.02.2.2 dan sistem NVIDIA DGX H100, pertanyaan Llama 2 70B mempunyai panjang jujukan input 2048 dan panjang jujukan output 128
Keputusan ujian terkini yang dikeluarkan oleh NVIDIA untuk DGX H100 (dengan 8 NVIDIA H100 Tensor Core GPU, dengan 80 GB HBM3) menunjukkan bahawa perisian NVIDIA TensorRT LLM awam digunakan, yang mana v0.5.0 digunakan untuk ujian Batch-1, v0 .6.1 untuk ukuran ambang kependaman. Butiran beban kerja ujian adalah sama seperti ujian AMD sebelumnya
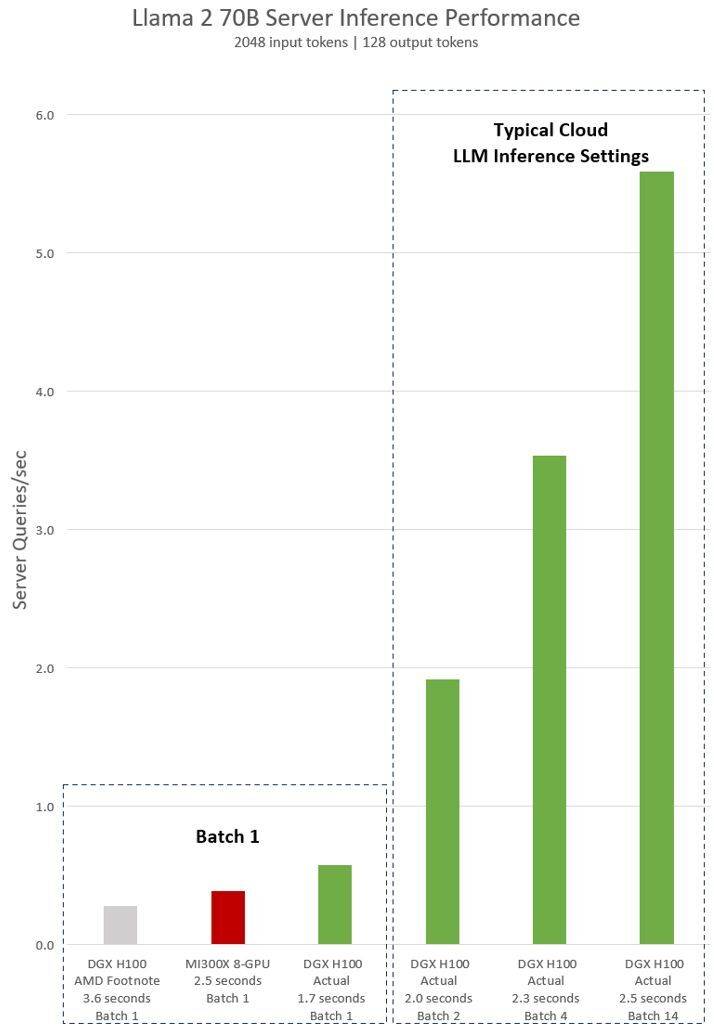
Menurut keputusan, selepas menggunakan perisian yang dioptimumkan, prestasi pelayan NVIDIA DGX H100 telah meningkat lebih daripada 2 kali ganda, dan 47% lebih pantas daripada pelayan MI300X 8-GPU yang ditunjukkan oleh AMD
DGX H100 boleh mengendalikan satu tugas inferens dalam 1.7 saat. Untuk mengoptimumkan masa tindak balas dan daya pemprosesan pusat data, perkhidmatan awan menetapkan masa tindak balas tetap untuk perkhidmatan tertentu. Ini membolehkan mereka menggabungkan berbilang permintaan inferens ke dalam "kelompok" yang lebih besar, sekali gus meningkatkan bilangan keseluruhan inferens pelayan sesaat. Penanda aras standard industri seperti MLPerf juga menggunakan metrik masa tindak balas tetap ini untuk mengukur prestasi
Pertukaran sedikit dalam masa tindak balas boleh mewujudkan ketidakpastian dalam bilangan permintaan inferens yang boleh dikendalikan oleh pelayan dalam masa nyata. Menggunakan belanjawan masa tindak balas 2.5 saat tetap, pelayan NVIDIA DGX H100 boleh mengendalikan lebih daripada 5 inferens Llama 2 70B sesaat, manakala Batch-1 mengendalikan kurang daripada satu sesaat.
Jelas sekali, agak adil untuk Nvidia menggunakan penanda aras baharu ini Lagipun, AMD juga menggunakan perisian yang dioptimumkan untuk menilai prestasi GPUnya, jadi mengapa tidak melakukan perkara yang sama semasa menguji Nvidia H100?
Anda mesti tahu bahawa susunan perisian NVIDIA berkisar pada ekosistem CUDA dan mempunyai kedudukan yang sangat kukuh dalam pasaran kecerdasan buatan selepas bertahun-tahun bekerja keras dan pembangunan, manakala ROCm 6.0 AMD adalah baharu dan belum lagi diuji dalam senario dunia sebenar.
Menurut maklumat yang didedahkan oleh AMD sebelum ini, ia telah mencapai sebahagian besar perjanjian dengan syarikat utama seperti Microsoft dan Meta, yang menganggap GPU MI300Xnya sebagai pengganti penyelesaian H100 Nvidia.
Instinct MI300X terbaru AMD dijangka dihantar dalam kuantiti yang banyak pada separuh pertama tahun 2024. Walau bagaimanapun, GPU H200 NVIDIA yang lebih kukuh juga akan dihantar pada masa itu, dan NVIDIA juga akan melancarkan generasi baharu Blackwell B100 pada separuh kedua 2024 . Selain itu, Intel juga akan melancarkan cip AI generasi baharunya Gaudi 3. Seterusnya, persaingan dalam bidang kecerdasan buatan nampaknya semakin sengit.
Editor: Pedang Xinzixun-Ruruuni
Atas ialah kandungan terperinci NVIDIA menampar AMD di muka: Dengan sokongan perisian, prestasi AI H100 adalah 47% lebih pantas daripada MI300X!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 5+ CPU terbaik untuk Windows 11, pemproses [AMD/Intel] yang manakah patut anda pilih?
- Apple Mac Pro dikuasakan oleh GPU AMD Radeon Pro W6600X, dilengkapi dengan pemproses strim 2048 dan memori 8GB
- Betulkan: Ralat pemacu grafik AMD tidak dipasang dalam Windows 11
- AMD merancang untuk melancarkan pemproses siri Ryzen 8000 baharu pada 2024, peningkatan besar yang diterajui oleh seni bina Zen5