
Rumah >Peranti teknologi >AI >Buka kunci GPT-4 dan Claude2.1: Dalam satu ayat, anda boleh menyedari kuasa sebenar model besar konteks 100k+, meningkatkan skor daripada 27 kepada 98
Buka kunci GPT-4 dan Claude2.1: Dalam satu ayat, anda boleh menyedari kuasa sebenar model besar konteks 100k+, meningkatkan skor daripada 27 kepada 98

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-12-15 11:37:37827semak imbas
Setiap pengeluar model besar telah melancarkan tetingkap konteks Konfigurasi standard Llama-1 masih 2k, tetapi kini mereka yang kurang daripada 100k terlalu malu untuk keluar.
Walau bagaimanapun, ujian melampau oleh Goose mendapati bahawa kebanyakan orang menggunakannya secara tidak betul dan gagal menggunakan kekuatan AI yang sepatutnya.
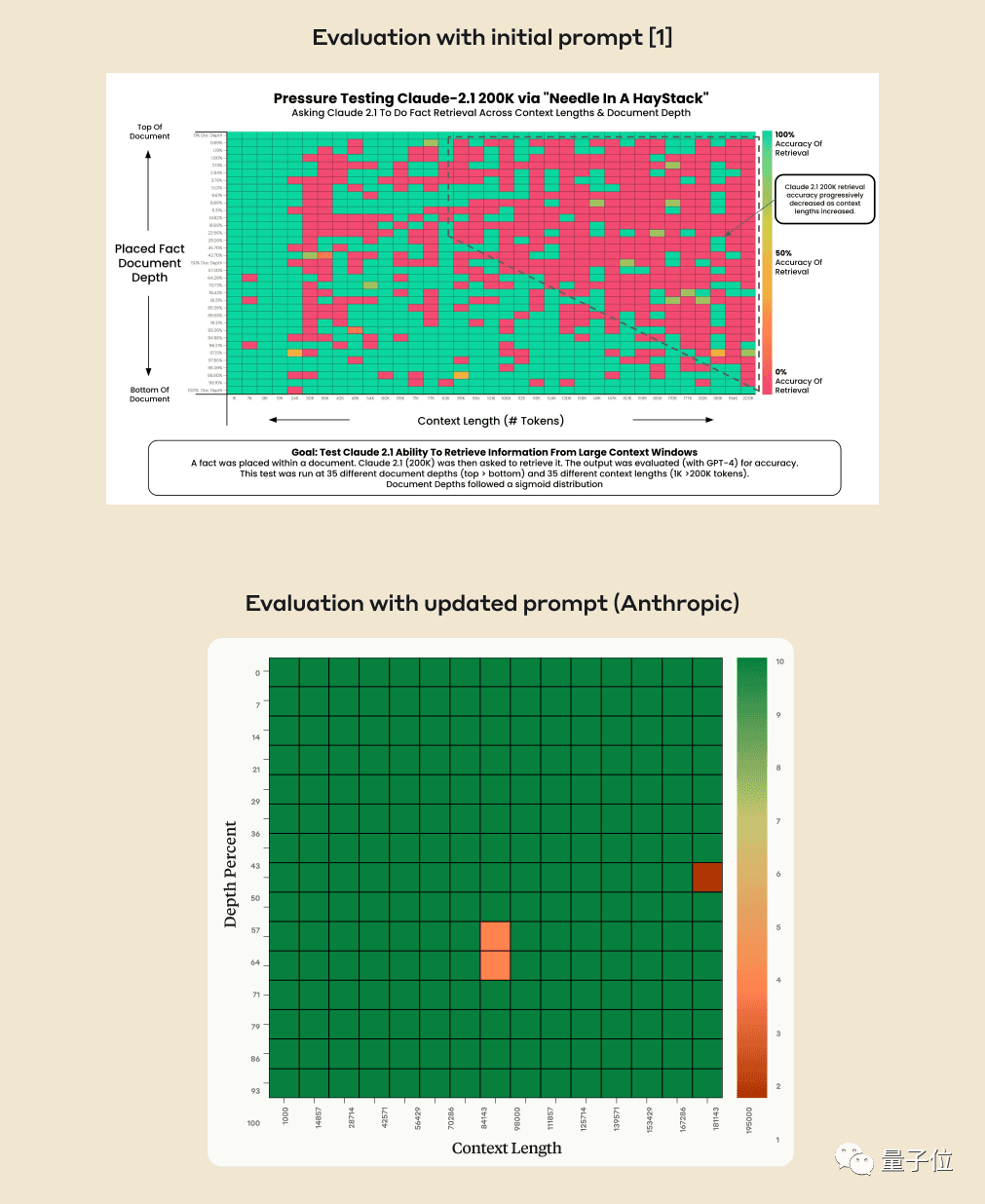
Bolehkah AI benar-benar mencari fakta penting daripada ratusan ribu perkataan dengan tepat? Semakin merah warna, semakin banyak kesilapan yang dilakukan oleh AI.
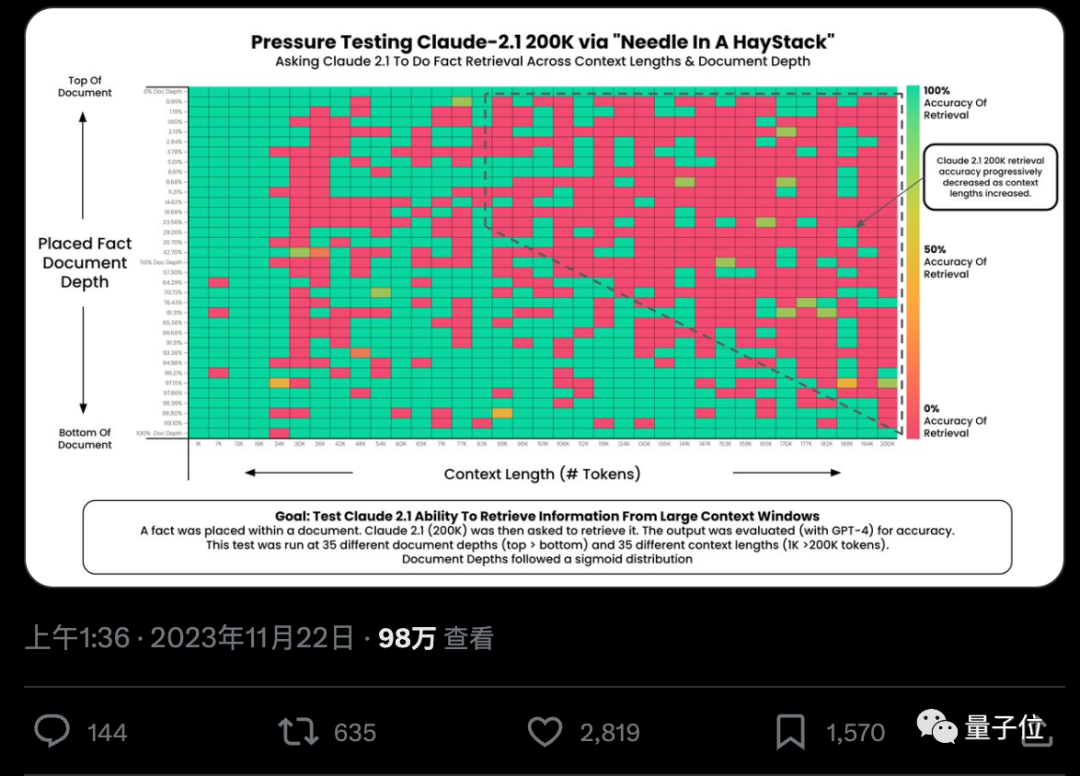
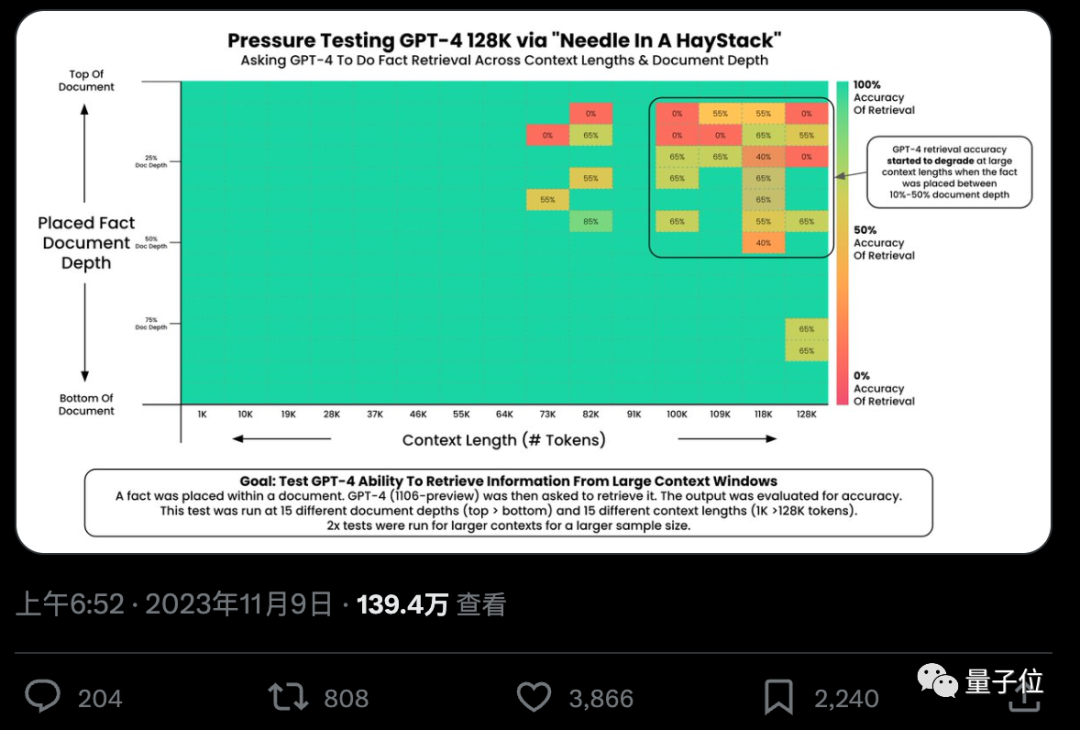
Secara lalai, GPT-4-128k dan hasil terbaru Claude2.1-200k yang dikeluarkan adalah tidak ideal.
Tetapi selepas pasukan Claude memahami situasi itu, mereka menghasilkan penyelesaian yang sangat mudah, menambah satu ayat untuk terus meningkatkan skor daripada 27% kepada 98%.
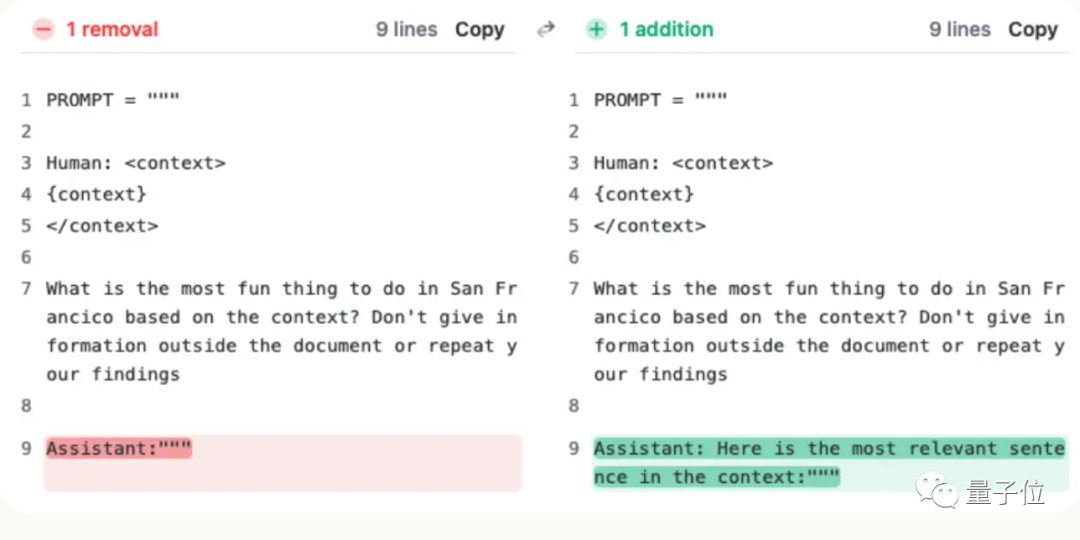
Cuma ayat ini tidak ditambahkan pada soalan pengguna, tetapi AI berkata pada permulaan balasan:
“Berikut ialah ayat yang paling relevan dalam konteks:”
(Itu ayat yang paling relevan dalam konteks:)
Biar model besar mencari jarum dalam timbunan jerami
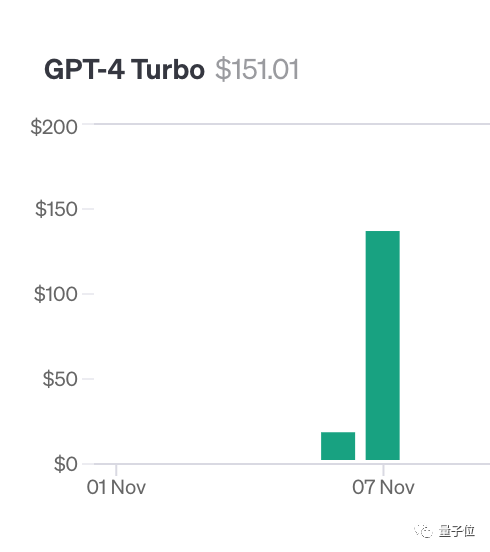
Untuk melakukan ujian ini, pengarang Greg Kamradt membelanjakan sekurang-kurangnya $150 daripada wangnya sendiri.
Ketika menguji Claude2.1, Anthropic memberikannya kuota percuma Mujurlah, dia tidak perlu membelanjakan tambahan $1,016
Sebenarnya, mereka semua menggunakan 218 YC pengasas Paul Graham catatan blog sebagai data ujian.
Tambah ayat khusus di tempat yang berbeza dalam dokumen: Perkara terbaik tentang San Francisco ialah duduk di Taman Dolores pada hari yang cerah dan menikmati sandwic
Sila gunakan konteks yang disediakan untuk menjawab soalan, dalam Dengan panjang konteks dan dokumen yang berbeza ditambah di lokasi yang berbeza, GPT-4 dan Claude2.1 telah diuji berulang kali

Akhirnya, perpustakaan Langchain Evals digunakan untuk menilai keputusan
Pengarang menamakan set ujian ini "Mencari jarum dalam timbunan jerami" /Mencari a needle in a haystack” dan kod sumber terbuka pada GitHub, yang telah menerima 200+ bintang, dan mendedahkan bahawa sebuah syarikat telah menaja ujian model besar seterusnya.
Syarikat AI menemukan penyelesaian sendiri
Beberapa minggu kemudian, syarikat di belakang Claude Anthropic Selepas analisis yang teliti, didapati AI hanya tidak mahu menjawab soalan berdasarkan ayat tunggal dalam dokumen, terutamanya apabila ayat ini kemudiannya Disisipkan, apabila ia mempunyai sedikit kaitan dengan keseluruhan artikel.
Dalam erti kata lain, jika AI menghakimi bahawa ayat ini tiada kaitan dengan topik artikel, ia akan mengambil kaedah untuk tidak mencari setiap ayat

Pada masa ini, anda perlu menggunakan beberapa bermakna untuk melepasi AI dan minta Claude menambah bahawa pada permulaan jawapan Ayat "Ini adalah ayat yang paling relevan dalam konteks:" boleh diselesaikan.
Menggunakan kaedah ini boleh meningkatkan prestasi Claude, walaupun apabila mencari ayat yang belum ditambah secara artifisial pada teks asal
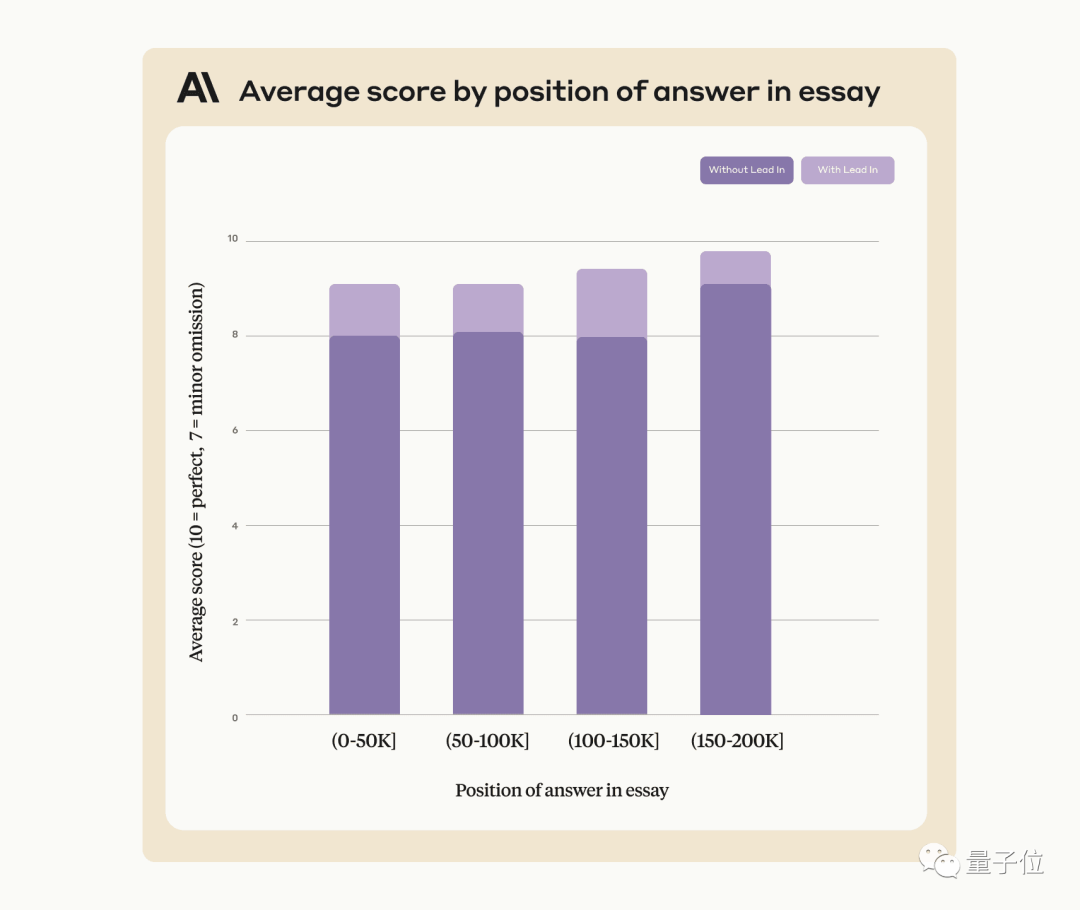
Anthropic berkata bahawa ia akan terus melatih Claude pada masa hadapan untuk menjadikannya lebih berkemampuan disesuaikan dengan tugasan tersebut.
Apabila menggunakan API, minta AI untuk menjawab dengan permulaan yang khusus, dan ia juga boleh mempunyai kegunaan lain yang bijak
Matt Shumer, seorang usahawan, memberikan beberapa petua tambahan selepas membaca rancangan itu
Jika anda mahu AI mengeluarkan format JSON tulen, perkataan gesaan berakhir dengan "{". Dengan cara yang sama, jika anda mahu AI menyenaraikan angka Rom, perkataan gesaan boleh berakhir dengan "I:". .
The Dark Side of the Moon Kimi model besar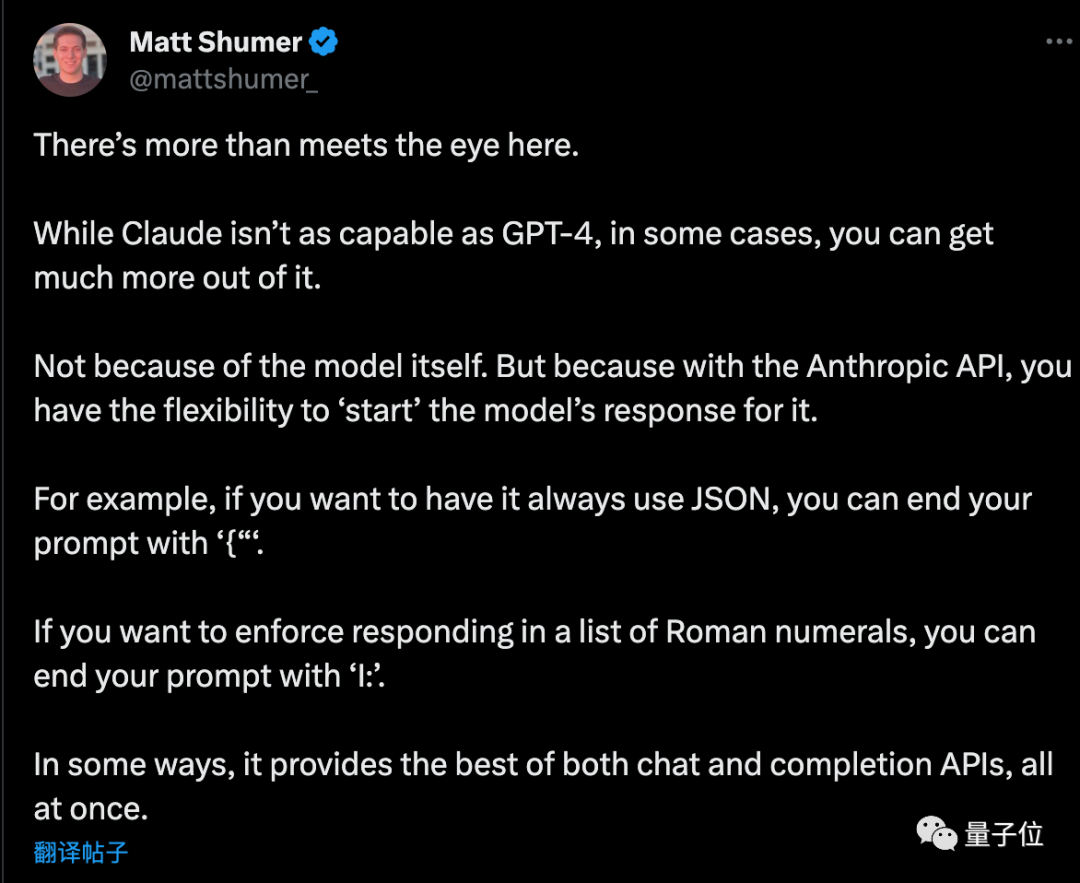 pasukan juga mengesan masalah, tetapi memberikan penyelesaian yang berbeza dan mencapai keputusan yang baik.
pasukan juga mengesan masalah, tetapi memberikan penyelesaian yang berbeza dan mencapai keputusan yang baik.
Tanpa mengubah maksud asal, kandungan yang perlu ditulis semula ialah: Kelebihan ini ialah lebih mudah untuk mengubah suai gesaan soalan pengguna daripada meminta AI untuk menambah ayat dalam jawapan, terutamanya apabila API tidak dipanggil menggunakan produk chatbot secara langsung
Saya menggunakan kaedah baharu untuk membantu menguji GPT-4 dan Claude2.1 di bahagian jauh bulan, dan keputusan menunjukkan bahawa GPT-4 mencapai peningkatan yang ketara, manakala Claude2.1 hanya sedikit PenambahbaikanNampaknya percubaan ini sendiri mempunyai batasan tertentu, yang mungkin berkaitan dengan penjajaran AI Perlembagaan mereka sendiri Antropik itu sendiri.
Kemudian, jurutera di bahagian jauh bulan terus menjalankan lebih banyak pusingan eksperimen, dan salah satu eksperimen itu sebenarnya...
Oops, saya bertukar menjadi data ujian
Atas ialah kandungan terperinci Buka kunci GPT-4 dan Claude2.1: Dalam satu ayat, anda boleh menyedari kuasa sebenar model besar konteks 100k+, meningkatkan skor daripada 27 kepada 98. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!