
Rumah >Peranti teknologi >AI >Pemahaman yang lebih mendalam tentang Transformer visual, analisis Transformer visual
Pemahaman yang lebih mendalam tentang Transformer visual, analisis Transformer visual

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-12-15 11:17:371257semak imbas
Artikel ini dicetak semula dengan kebenaran akaun awam Autonomous Driving Heart Sila hubungi sumber semasa mencetak semula
Tulis di hadapan&&Pemahaman peribadi penulis
Pada masa ini, model algoritma berdasarkan struktur Transformer telah digunakan secara meluas. bidang penglihatan komputer (CV) ) telah memberi impak yang besar. Mereka mengatasi model algoritma rangkaian neural convolutional (CNN) sebelumnya pada banyak tugas asas penglihatan komputer. Berikut ialah kedudukan senarai LeaderBoard terkini bagi tugas penglihatan komputer asas yang berbeza yang saya temui Melalui LeaderBoard, kita dapat melihat penguasaan model algoritma Transformer dalam pelbagai tugas penglihatan komputer
- Tugas pengelasan imej
Pertama di ImageNet Leaderboard, dapat dilihat dari senarai bahawa antara lima teratas, setiap model menggunakan struktur Transformer, manakala struktur CNN hanya digunakan sebahagian sahaja, atau digabungkan dengan Transformer.

Leaderboard untuk tugas klasifikasi imej Tugas Pengesanan Tugas
- Seterusnya adalah Leaderboard pada Coco Test-Dev struktur seperti algoritma dilanjutkan.
LeaderBoard untuk tugas pengesanan sasaran
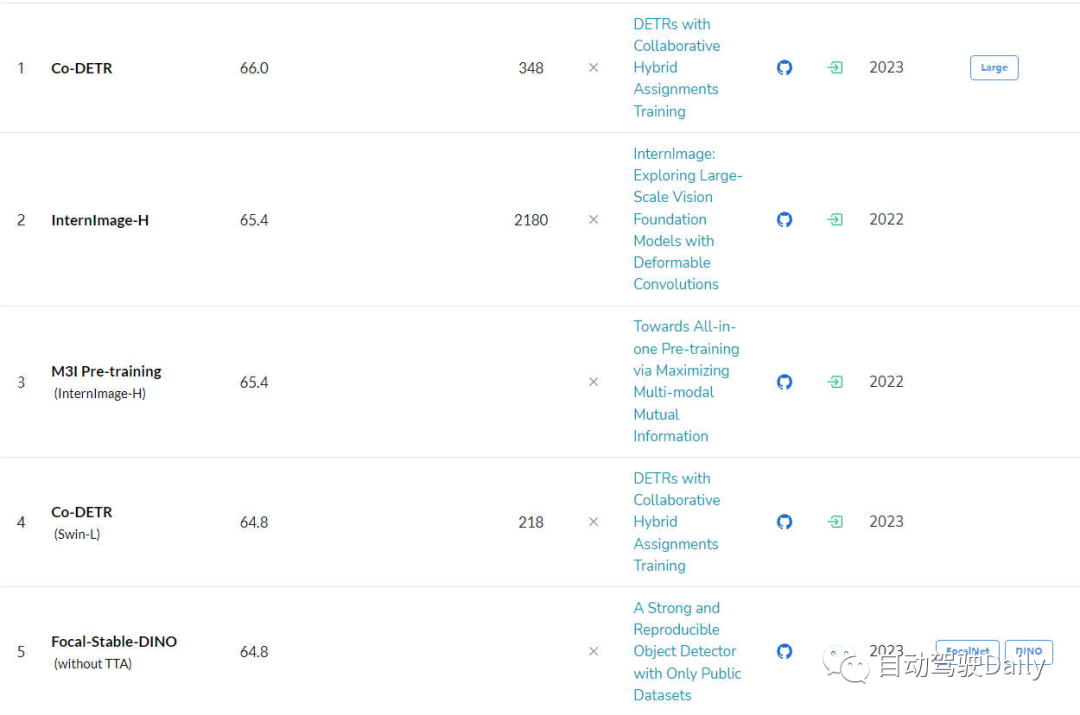 Tugas segmentasi semantik
Tugas segmentasi semantik
- Yang terakhir ialah LeaderBoard pada ADE20K val Ia juga boleh dilihat dari senarai bahawa antara yang teratas dalam senarai, struktur Transformer masih menduduki struktur semasa kedudukan.
Papan Pemimpin untuk tugasan segmentasi semantik
Walaupun Transformer pada masa ini menunjukkan potensi pembangunan yang hebat di China, komuniti penglihatan komputer semasa belum memahami sepenuhnya kerja dalaman Vision Transformer, mahupun membuat keputusan (hasil ramalan output) ), jadi keperluan untuk kebolehtafsirannya secara beransur-ansur muncul. Hanya dengan memahami cara model sedemikian membuat keputusan, kami boleh meningkatkan prestasi mereka dan membina kepercayaan dalam sistem kecerdasan buatan 
Analisis Pengubah Penglihatan
Oleh kerana seperti yang dinyatakan sebentar tadi, struktur Pengubah Penglihatan telah mencapai keputusan yang sangat baik dalam pelbagai tugas asas penglihatan komputer. Begitu banyak kaedah telah muncul dalam komuniti penglihatan komputer untuk meningkatkan kebolehtafsirannya. Dalam artikel ini, kami memberi tumpuan terutamanya pada tugas klasifikasi, dan memilih yang terkini dan terkini daripada lima aspek: Kaedah Atribusi Biasa
,Kaedah Berasaskan Perhatian, Kaedah Berasaskan Pemangkasan, Kaedah Yang Boleh Diterangkan Secara InherenLainnya Tugasan Kerja klasik diperkenalkan. Berikut ialah peta minda yang dipaparkan dalam kertas kerja anda boleh membacanya dengan lebih terperinci berdasarkan perkara yang anda minati~
Peta minda artikel ini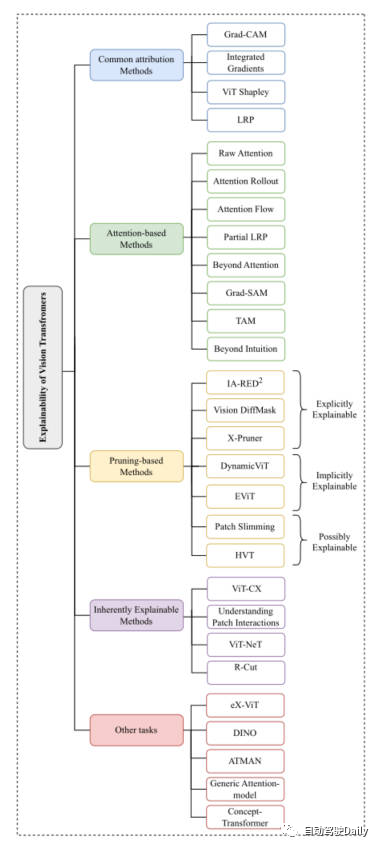
Grad-CAM
danGrad Bersepadu
digunakan secara langsung pada algoritma berdasarkan Transformer visual. Beberapa kaedah lain seperti SHAP danLayer-Wise Relevance Propagation (LRP) telah digunakan untuk meneroka seni bina berasaskan ViT. Walau bagaimanapun, disebabkan kos kaedah pengiraan yang sangat tinggi seperti SHAP, algoritma ViT Shapely baru-baru ini telah direka bentuk untuk menyesuaikan diri dengan penyelidikan aplikasi berkaitan ViT. Kaedah berasaskan perhatianVision Transformer telah memperoleh keupayaan pengekstrakan ciri yang hebat melalui mekanisme perhatiannya. Antara kaedah kebolehtafsiran berasaskan perhatian, memvisualisasikan keputusan berat perhatian adalah kaedah yang sangat berkesan. Artikel ini akan memperkenalkan beberapa teknik visualisasi
- Perhatian Mentah: Seperti namanya, kaedah ini adalah untuk menggambarkan peta berat perhatian yang diperoleh daripada lapisan tengah model rangkaian, untuk menganalisis kesan model.
- Pelancaran Perhatian: Teknologi ini menjejaki pemindahan maklumat daripada token input kepada pembenaman perantaraan dengan mengembangkan pemberat perhatian dalam lapisan rangkaian yang berbeza.
- Aliran Perhatian: Kaedah ini menganggap peta perhatian sebagai rangkaian aliran dan menggunakan algoritma aliran maksimum untuk mengira nilai aliran maksimum daripada pembenaman perantaraan kepada token input.
- partialLRP: Kaedah ini dicadangkan untuk menggambarkan mekanisme perhatian berbilang kepala dalam Pengubah Penglihatan, sambil mempertimbangkan kepentingan setiap kepala perhatian.
- Grad-SAM: Kaedah ini digunakan untuk mengurangkan had bergantung semata-mata pada matriks perhatian asal untuk menerangkan ramalan model, mendorong penyelidik menggunakan kecerunan dalam pemberat perhatian asal.
- Beyond Intuition: Kaedah ini juga merupakan kaedah untuk menerangkan perhatian, termasuk dua peringkat persepsi perhatian dan maklum balas penaakulan.
Akhir sekali, berikut ialah gambarajah visualisasi perhatian bagi kaedah kebolehtafsiran yang berbeza Anda boleh rasa sendiri perbezaan antara kaedah visualisasi yang berbeza.

Perbandingan peta perhatian kaedah visualisasi yang berbeza
Kaedah berasaskan pemangkasan
Pemangkasan adalah kaedah yang sangat berkesan yang digunakan secara meluas untuk mengoptimumkan kecekapan dan kerumitan struktur pengubah. Kaedah pemangkasan mengurangkan bilangan parameter dan kerumitan pengiraan model dengan memadam maklumat yang berlebihan atau tidak berguna. Walaupun algoritma pemangkasan memberi tumpuan kepada meningkatkan kecekapan pengiraan model, jenis algoritma ini masih boleh mencapai kebolehtafsiran model.
Kaedah pemangkasan berdasarkan Vision-Transformer dalam artikel ini boleh dibahagikan secara kasar kepada tiga kategori: boleh diterangkan secara eksplisit (boleh diterangkan secara eksplisit), boleh diterangkan secara tersirat (boleh diterangkan secara tersirat), boleh diterangkan secara jelas.
-
Explicitly Explainable
Antara kaedah berasaskan pemangkasan, terdapat beberapa jenis kaedah yang boleh memberikan model yang lebih ringkas dan boleh dijelaskan.
- IA-RED^2: Matlamat kaedah ini adalah untuk mencapai keseimbangan optimum antara kecekapan pengiraan dan kebolehtafsiran model algoritma. Dan dalam proses ini, fleksibiliti model algoritma ViT asal dikekalkan.
- X-Pruner: Kaedah ini ialah kaedah untuk mencantas unit yang menonjol dengan mencipta topeng persepsi yang boleh ditafsir yang mengukur sumbangan setiap unit yang boleh diramal dalam meramalkan kelas tertentu.
- Vision DiffMask: Kaedah pemangkasan ini termasuk menambah mekanisme gating pada setiap lapisan ViT Melalui mekanisme gating, output model boleh dikekalkan sambil melindungi input. Di luar ini, model algoritmik dengan jelas boleh mencetuskan subset imej yang tinggal, membolehkan pemahaman yang lebih baik tentang ramalan model.
-
Implicitly Explainable
Antara kaedah berasaskan pemangkasan, terdapat juga beberapa kaedah klasik yang boleh dibahagikan kepada kategori model explainability yang tersirat. - Dynamic ViT: Kaedah ini menggunakan modul ramalan ringan untuk menganggar kepentingan setiap token berdasarkan ciri semasa. Modul ringan ini kemudiannya ditambahkan pada lapisan ViT yang berbeza untuk memangkas token berlebihan secara hierarki. Paling penting, kaedah ini meningkatkan kebolehtafsiran dengan mencari secara beransur-ansur bahagian imej utama yang menyumbang paling banyak kepada pengelasan.
- Efficient Vision Transformer (EViT): Idea teras kaedah ini adalah untuk mempercepatkan EViT dengan menyusun semula token. Dengan mengira skor perhatian, EViT mengekalkan token yang paling berkaitan sambil menggabungkan token yang kurang relevan kepada token tambahan. Pada masa yang sama, untuk menilai kebolehtafsiran EViT, pengarang kertas kerja menggambarkan proses pengecaman token pada berbilang imej input.
-
Mungkin Boleh Diterangkan
Walaupun kaedah jenis ini pada asalnya tidak direka untuk meningkatkan kebolehtafsiran ViT, kaedah jenis ini memberikan potensi besar untuk penyelidikan lanjut tentang kebolehtafsiran model.
- Patch Slimming: Mempercepatkan ViT dengan memfokuskan pada tompok berlebihan dalam imej melalui pendekatan atas ke bawah. Algoritma secara selektif mengekalkan keupayaan tampungan utama untuk menyerlahkan ciri visual yang penting, dengan itu meningkatkan kebolehtafsiran.
- Hierarchical Visual Transformer (HVT): Kaedah ini diperkenalkan untuk meningkatkan kebolehskalaan dan prestasi ViT. Apabila kedalaman model meningkat, panjang jujukan secara beransur-ansur berkurangan. Tambahan pula, dengan membahagikan blok ViT kepada beberapa peringkat dan menggunakan operasi pengumpulan pada setiap peringkat, kecekapan pengiraan bertambah baik dengan ketara. Memandangkan penumpuan progresif pada komponen yang paling penting dalam model, terdapat peluang untuk meneroka potensi kesannya terhadap meningkatkan kebolehtafsiran dan kebolehjelasan.
Kaedah yang Boleh Diterangkan Secara Inheren
Di antara kaedah boleh tafsir yang berbeza, terdapat kelas kaedah yang terutamanya membangunkan model algoritmik yang secara intrinsik boleh menerangkannya Namun, model ini sering bergelut untuk mencapai tahap ketepatan yang sama seperti kotak hitam yang lebih kompleks model. Oleh itu, keseimbangan yang teliti mesti dipertimbangkan antara kebolehtafsiran dan prestasi. Seterusnya, beberapa karya klasik diperkenalkan secara ringkas.
- ViT-CX: Kaedah ini ialah kaedah tafsiran berasaskan topeng yang disesuaikan untuk model ViT. Pendekatan ini bergantung pada pembenaman tampalan dan kesannya pada output model, dan bukannya memfokuskan padanya. Kaedah ini terdiri daripada dua peringkat: penjanaan topeng dan pengagregatan topeng, dengan itu menyediakan peta kepentingan yang lebih bermakna.
- ViT-NeT: Kaedah ini ialah penyahkod pokok neural baharu yang menerangkan proses membuat keputusan melalui struktur pokok dan prototaip. Pada masa yang sama, algoritma juga membenarkan tafsiran visual hasil.
- R-Cut: Kaedah ini meningkatkan kebolehtafsiran ViT melalui Relationship Weighted Out and Cut. Kaedah ini merangkumi dua modul iaitu modul Relationship Weighted Out dan Cut. Yang pertama memberi tumpuan kepada mengekstrak kelas maklumat tertentu dari lapisan tengah, menekankan ciri yang berkaitan. Yang terakhir melakukan penguraian ciri berbutir halus. Dengan menyepadukan kedua-dua modul, peta kebolehtafsiran khusus kelas yang padat boleh dihasilkan.
Tugas Lain
Seni bina berasaskan ViT masih perlu dijelaskan untuk tugas penglihatan komputer lain dalam penerokaan. Beberapa kaedah kebolehtafsiran telah dicadangkan khusus untuk tugasan lain, dan kerja terkini dalam bidang berkaitan akan diperkenalkan di bawah
- eX-ViT: Algoritma ini ialah pengubah visual baharu yang boleh ditafsir berdasarkan pembahagian semantik yang diselia dengan lemah. Di samping itu, untuk meningkatkan kebolehtafsiran, modul kehilangan berorientasikan atribut diperkenalkan, yang mengandungi tiga kerugian: kehilangan berorientasikan atribut peringkat global, kehilangan kebolehdiskriminasian atribut peringkat tempatan dan kehilangan kepelbagaian atribut. Yang pertama menggunakan peta perhatian untuk mencipta ciri yang boleh ditafsir, manakala dua yang terakhir meningkatkan pembelajaran atribut.
- DINO: Kaedah ini adalah kaedah penyeliaan sendiri yang mudah dan kaedah penyulingan sendiri tanpa label. Peta perhatian terakhir yang dipelajari boleh mengekalkan kawasan semantik imej dengan berkesan, dengan itu mencapai tujuan yang boleh ditafsirkan.
- Generic Attention-model: Kaedah ini ialah model algoritma untuk ramalan berdasarkan seni bina Transformer. Kaedah ini digunakan untuk tiga seni bina yang paling biasa digunakan, iaitu perhatian kendiri tulen, perhatian kendiri digabungkan dengan perhatian bersama, dan perhatian penyahkod pengekod. Untuk menguji kebolehtafsiran model, pengarang menggunakan tugas menjawab soalan visual, namun, ia juga boleh digunakan untuk tugas CV lain seperti pengesanan objek dan pembahagian imej.
- ATMAN: Ini ialah kaedah gangguan modaliti-agnostik yang menggunakan mekanisme perhatian untuk menjana peta korelasi input berbanding ramalan output. Pendekatan ini cuba memahami ramalan ubah bentuk melalui operasi perhatian yang cekap memori.
- Concept-Transformer: Algoritma ini menjana penjelasan output model dengan menyerlahkan skor perhatian untuk konsep peringkat tinggi yang ditentukan pengguna, memastikan kebolehpercayaan dan kebolehpercayaan.
Tinjauan Masa Depan
Pada masa ini, model algoritma berdasarkan seni bina Transformer telah mencapai hasil yang cemerlang dalam pelbagai tugas penglihatan komputer. Walau bagaimanapun, pada masa ini terdapat kekurangan penyelidikan yang jelas tentang cara menggunakan kaedah kebolehtafsiran untuk mempromosikan penyahpepijatan dan penambahbaikan model, serta meningkatkan kesaksamaan dan kebolehpercayaan model, terutamanya dalam aplikasi ViT
Kertas kerja ini bertujuan untuk menggunakan tugas pengelasan imej untuk meningkatkan kesaksamaan dan kebolehpercayaan. model. Model algoritma kebolehtafsiran Vision Transformer diklasifikasikan dan disusun untuk membantu pembaca memahami dengan lebih baik seni bina model sedemikian. Saya harap ia akan membantu semua orang

Apa yang perlu ditulis semula ialah: Pautan asal: https: // mp.weixin.qq.com/s/URkobeRNB8dEYzrECaC7tQ
Atas ialah kandungan terperinci Pemahaman yang lebih mendalam tentang Transformer visual, analisis Transformer visual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!