
Rumah >Peranti teknologi >AI >Memperkenalkan rangka kerja GIF baharu: Mengikuti contoh manusia, paradigma baharu penguatan set data telah tiba
Memperkenalkan rangka kerja GIF baharu: Mengikuti contoh manusia, paradigma baharu penguatan set data telah tiba

- PHPzke hadapan
- 2023-12-14 21:49:271315semak imbas

- Pautan kertas: https://browse.arxiv.org/pdf/2211.13976.pdf
- GitHub: https://github.com/Vanintpan🜎
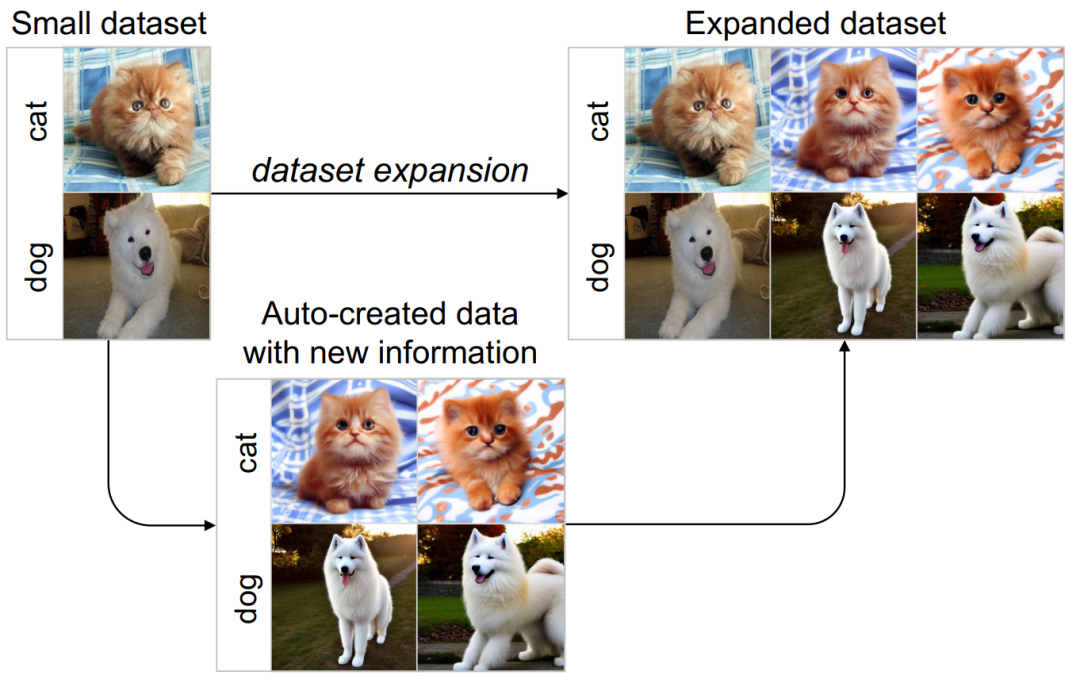
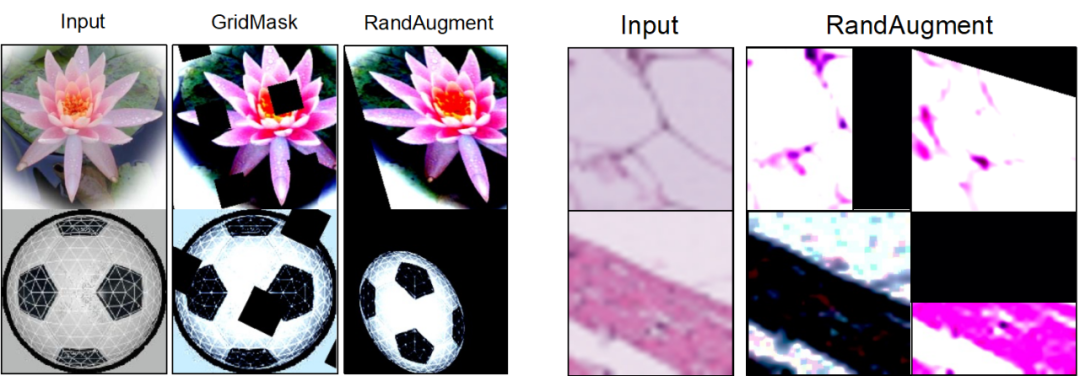
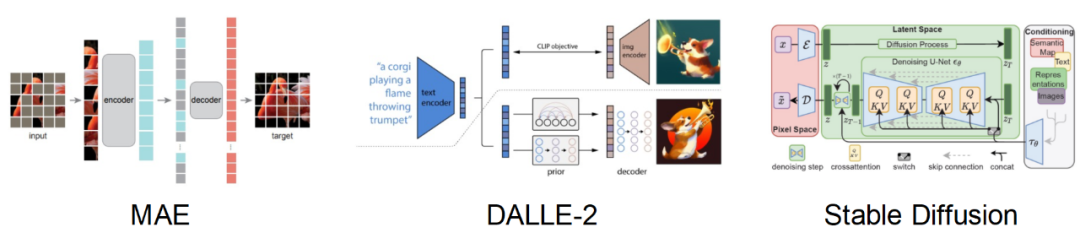
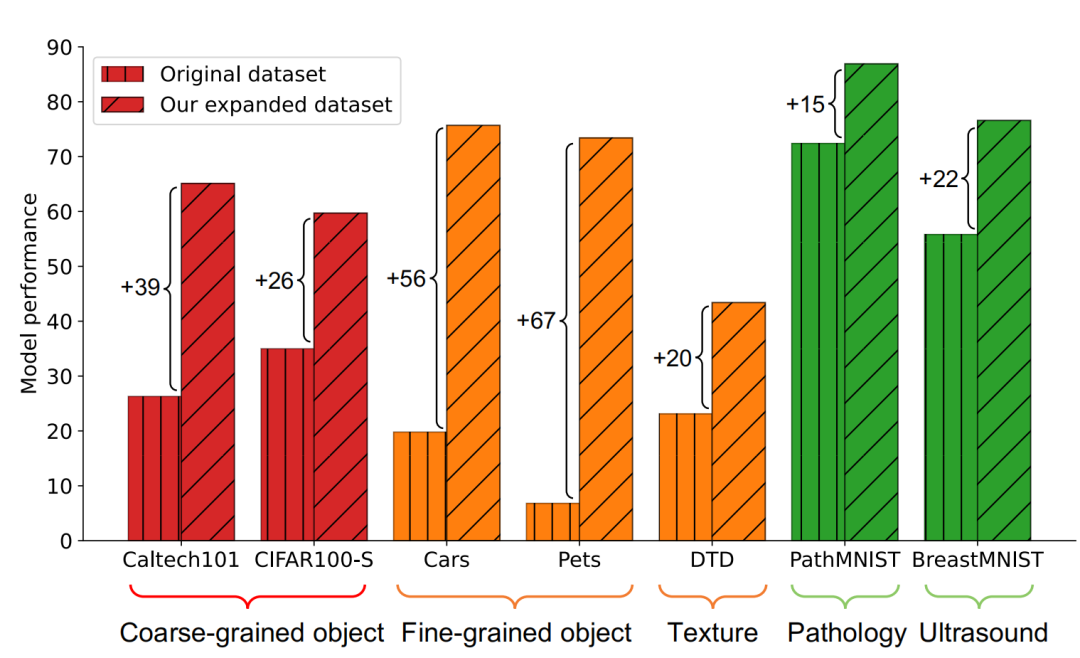
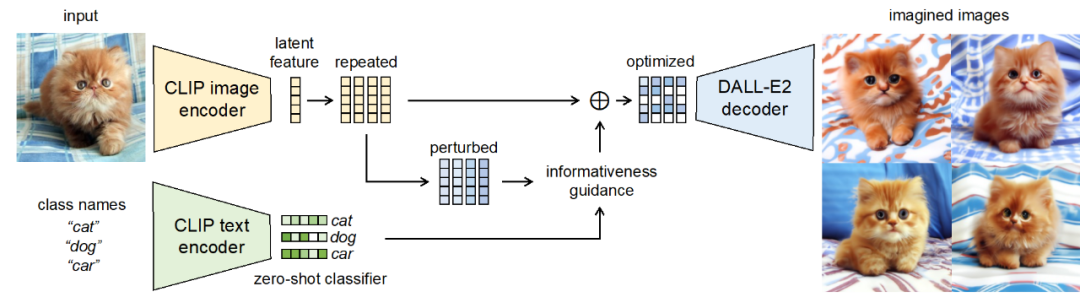
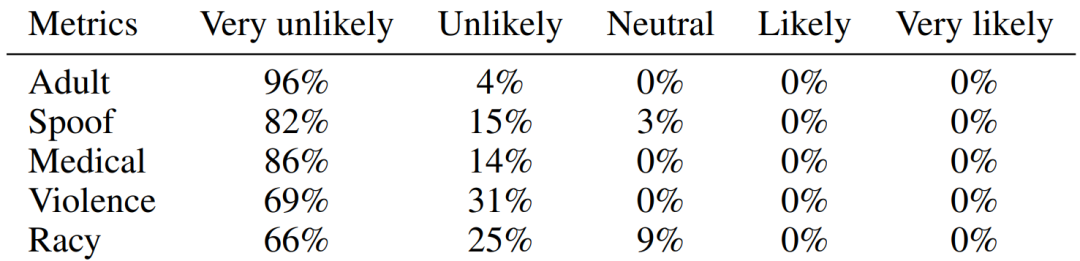
Cabaran dan piawaian panduan untuk penguatan set data Terdapat dua cabaran utama dalam mereka bentuk kaedah penguatan set data: (1) Bagaimana untuk menjadikan sampel yang dihasilkan mempunyai label kategori yang betul? (2) Bagaimana untuk memastikan sampel yang dihasilkan mengandungi maklumat baharu untuk mempromosikan latihan model? Untuk menangani dua cabaran ini, kerja ini menemui dua kriteria panduan penguatan melalui eksperimen yang meluas: (1) peningkatan maklumat konsisten kategori; (2) peningkatan kepelbagaian sampel; Rangka Kerja Kaedah Berdasarkan piawaian panduan amplifikasi yang ditemui, karya ini mencadangkan Rangka Kerja Pembesaran Imaginasi Berpandu (GIF). Untuk setiap sampel benih input x, GIF mula-mula mengekstrak ciri sampel f menggunakan pengekstrak ciri model generatif terdahulu dan melakukan gangguan hingar pada ciri: Piawaian panduan amplifikasi yang digunakan dilaksanakan seperti berikut. Indeks kuantiti maklumat konsisten kelas: Kesahan Penguatan GIF mempunyai kesahihan penguatan yang lebih kukuh: GIF-SD meningkatkan ketepatan klasifikasi dengan purata 36.9% pada 3 set data set data semula jadi dan pada purata ketepatan set data perubatan 6 kelas bertambah baik sebanyak 13.5%. Kecekapan amplifikasi GIF mempunyai kecekapan amplifikasi yang lebih kuat: pada set data Kereta dan DTD, kesan penggunaan GIF-SD untuk penguatan 5 kali ganda malah melebihi kesan penggunaan penambahan data rawak 20 -penguatan lipatan. Hasil visualisasi Kaedah penambahan data sedia ada tidak boleh menjana kandungan imej baharu, manakala GIF boleh menjana sampel dengan kandungan baharu dengan lebih baik. Kaedah peningkatan sedia ada boleh mengurangkan lokasi lesi dalam imej perubatan, menyebabkan maklumat sampel berkurangan dan penjanaan hingar, manakala GIF boleh mengekalkan semantik kategorinya dengan lebih baik Kepelbagaian data yang diperkuatkanSetelah diperkuat, set data ini boleh digunakan terus untuk melatih pelbagai struktur model rangkaian saraf. Tingkatkan keupayaan generalisasi model GIF membantu meningkatkan prestasi generalisasi luar pengedaran model (pengertian OOD). Melegakan masalah ekor panjang GIF membantu mengurangkan masalah ekor panjang. Semakan Keselamatan Imej yang dijana GIF adalah selamat dan tidak berbahaya. Berdasarkan keputusan eksperimen di atas, kami mempunyai sebab untuk mempercayai bahawa dengan mensimulasikan pembelajaran analogi dan imaginasi manusia, kaedah yang direka dalam kertas ini dapat mengembangkan set data kecil dengan berkesan, dengan itu meningkatkan prestasi rangkaian saraf dalam dalam pelaksanaan senario tugas data kecil dan aplikasi. Kaedah

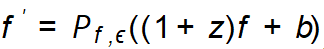 . Cara paling mudah untuk menetapkan hingar (z, b) ialah menggunakan hingar rawak Gaussian, tetapi ia tidak dapat memastikan sampel yang dihasilkan mempunyai label kelas yang betul dan membawa lebih banyak maklumat. Oleh itu, untuk penguatan set data yang cekap, GIF mengoptimumkan gangguan hingar berdasarkan garis panduan penguatan yang ditemui, iaitu
. Cara paling mudah untuk menetapkan hingar (z, b) ialah menggunakan hingar rawak Gaussian, tetapi ia tidak dapat memastikan sampel yang dihasilkan mempunyai label kelas yang betul dan membawa lebih banyak maklumat. Oleh itu, untuk penguatan set data yang cekap, GIF mengoptimumkan gangguan hingar berdasarkan garis panduan penguatan yang ditemui, iaitu 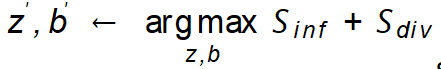 .
. 
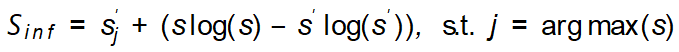 ; indeks kepelbagaian sampel:
; indeks kepelbagaian sampel: 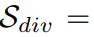
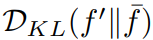 . Dengan memaksimumkan kedua-dua penunjuk ini, GIF boleh mengoptimumkan gangguan bunyi dengan berkesan, dengan itu menghasilkan sampel yang mengekalkan ketekalan kategori dan membawa kandungan maklumat yang lebih besar.
. Dengan memaksimumkan kedua-dua penunjuk ini, GIF boleh mengoptimumkan gangguan bunyi dengan berkesan, dengan itu menghasilkan sampel yang mengekalkan ketekalan kategori dan membawa kandungan maklumat yang lebih besar.
Eksperimen
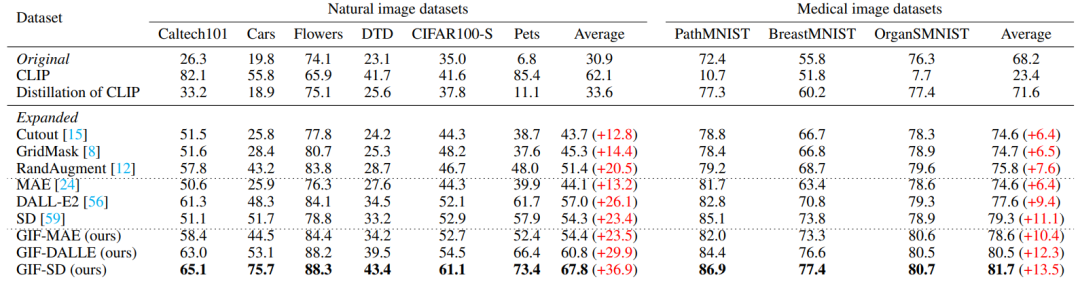
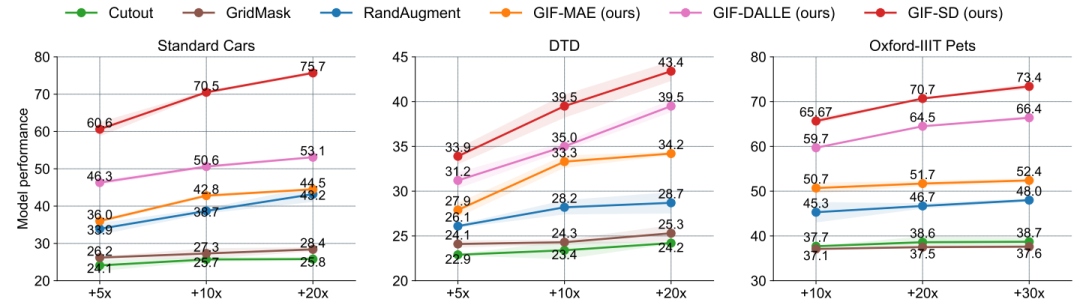
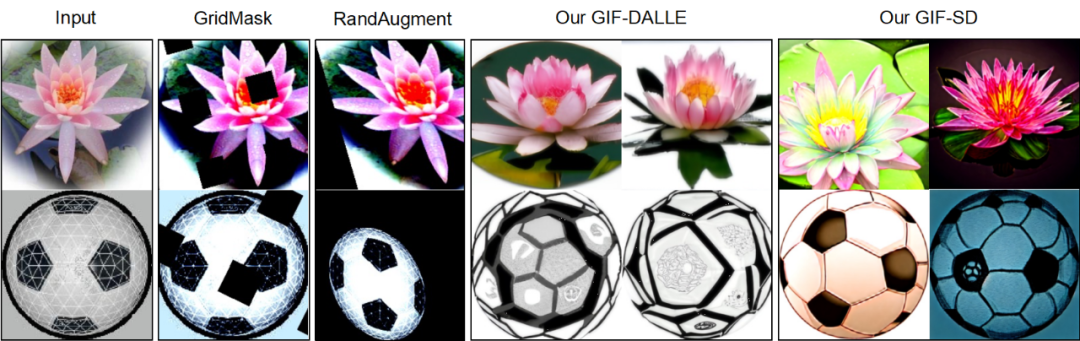
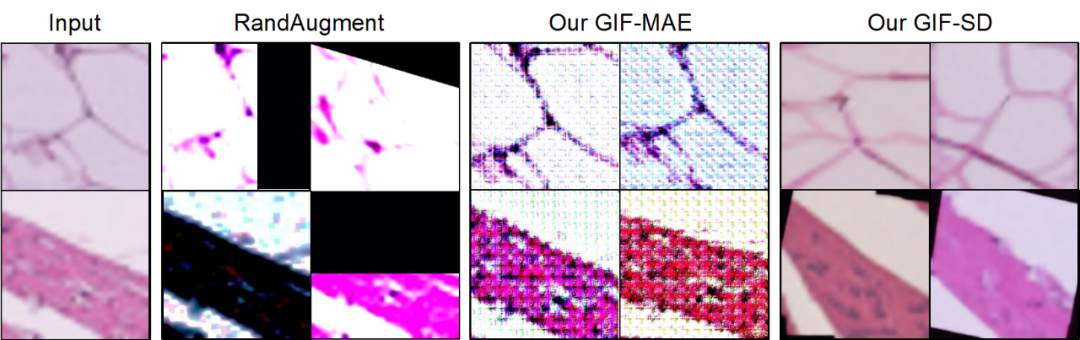 Berbanding dengan pengumpulan dan anotasi data manual, GIF boleh mengurangkan masa dan kos penguatan set data dengan banyak.
Berbanding dengan pengumpulan dan anotasi data manual, GIF boleh mengurangkan masa dan kos penguatan set data dengan banyak. 



Atas ialah kandungan terperinci Memperkenalkan rangka kerja GIF baharu: Mengikuti contoh manusia, paradigma baharu penguatan set data telah tiba. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!