

 Peranti teknologiAIMicrosoft menjadikan GPT-4 sebagai pakar perubatan dengan hanya 'Prompt Project'! Lebih daripada sedozen model yang sangat halus, ketepatan ujian profesional melebihi 90% untuk kali pertama
Peranti teknologiAIMicrosoft menjadikan GPT-4 sebagai pakar perubatan dengan hanya 'Prompt Project'! Lebih daripada sedozen model yang sangat halus, ketepatan ujian profesional melebihi 90% untuk kali pertama
Penyelidikan terkini Microsoft sekali lagi membuktikan kuasa Prompt Engineering -
Tidak perlu penalaan halus tambahan atau perancangan pakar, GPT-4 boleh menjadi "pakar" dengan hanya gesaan.
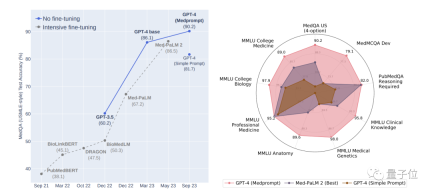
Menggunakan strategi segera terbaru mereka Medprompt, dalam bidang profesional perubatan, GPT-4 mencapai keputusan terbaik dalam sembilan set ujian MultiMed QA.
Pada set data MedQA (soalan Peperiksaan Pelesenan Perubatan Amerika Syarikat), Medprompt membuat ketepatan GPT-4 melebihi 90% buat kali pertama, melepasi BioGPT dan Med-PaLM dan kaedah penalaan halus yang lain.
Para penyelidik juga menyatakan bahawa kaedah Medprompt adalah universal dan bukan sahaja terpakai untuk perubatan, tetapi juga boleh diperluaskan kepada kejuruteraan elektrik, pembelajaran mesin, undang-undang dan jurusan lain.
Sebaik kajian ini dikongsikan di X (sebelum ini Twitter), ia menarik perhatian ramai netizen.

Profesor Wharton School Ethan Mollick, pengarang Artificial Intuition Carlos E. Perez, dsb. telah memajukan dan berkongsinya.
Carlos E. Perez secara langsung berkata bahawa "strategi dorongan yang sangat baik boleh mengambil banyak penalaan halus":

Sesetengah netizen berkata bahawa mereka telah mempunyai firasat ini untuk masa yang lama, dan ia benar-benar keren untuk dilihat hasilnya sekarang!

Sesetengah netizen menganggap ini benar-benar "radikal"
Ensemble shuffling pilihanGPT-4 ialah teknologi yang boleh mengubah industri, dan kami jauh daripada menyentuh had gesaan, kami juga tidak mencapai had penalaan halus . . -dijana rantaian pemikiran yang dijana sendiri

- Pemilihan beberapa pukulan dinamik
- Pembelajaran yang kurang pantas adalah cara yang berkesan untuk menjadikan model untuk mempelajari konteks. Ringkasnya, masukkan beberapa contoh, biarkan model cepat menyesuaikan diri dengan domain tertentu dan belajar mengikut format tugasan.
- Contoh beberapa contoh yang digunakan untuk gesaan tugas tertentu biasanya
- ditetapkan , jadi terdapat keperluan yang tinggi untuk keterwakilan dan keluasan contoh.
Kaedah sebelumnya adalah membenarkan pakar domain
membuat contoh secara manual, tetapi walaupun begitu, tidak ada jaminan bahawa beberapa contoh tetap yang dipilih susun oleh pakar adalah mewakili setiap tugas. 
Berbanding dengan kaedah penalaan halus, pemilihan beberapa pukulan dinamik menggunakan data latihan, tetapi tidak tidak memerlukan Parameter Model menjalani kemas kini yang meluas.
Rantai pemikiran janaan sendiriKaedah rantaian pemikiran (CoT) ialah kaedah yang membolehkan model berfikir langkah demi langkah dan menjana satu siri langkah penaakulan perantaraan
Kaedah sebelumnya bergantung kepada pakar untuk menulis beberapa contoh secara manual dengan digesa rantai pemikiran
Di sini, penyelidik mendapati bahawa GPT-4 hanya boleh diminta untuk menjana rantaian pemikiran untuk contoh latihan menggunakan gesaan berikut:

Tetapi para penyelidik juga menegaskan bahawa rantaian pemikiran yang dijana secara automatik ini mungkin mengandungi penaakulan yang salah langkah, jadi teg pengesahan ditetapkan sebagai penapis, yang boleh mengurangkan ralat dengan berkesan.
Berbanding dengan contoh rantai pemikiran yang dibuat oleh pakar dalam model Med-PaLM 2, prinsip asas rantaian pemikiran yang dijana oleh GPT-4 adalah lebih panjang, dan logik penaakulan langkah demi langkah adalah lebih terperinci. . .
Untuk Untuk menyelesaikan masalah ini, penyelidik memutuskan untuk menyusun semula susunan pilihan asal untuk mengurangkan kesan. Contohnya, susunan pilihan asal ialah ABCD, yang boleh ditukar kepada BCDA, CDAB, dsb. Kemudian biarkan GPT-4 melakukan berbilang pusingan ramalan, menggunakan susunan pilihan yang berbeza dalam setiap pusingan. Ini "memaksa" GPT-4 untuk mempertimbangkan kandungan pilihan. Akhir sekali, undi pada keputusan berbilang pusingan ramalan dan pilih pilihan yang paling konsisten dan betul. Gabungan strategi segera di atas ialah Medprompt. Mari kita lihat keputusan ujian. Optimum dalam pelbagai ujianDalam ujian, penyelidik menggunakan penanda aras penilaian MultiMed QA.GPT-4, yang menggunakan strategi dorongan Medprompt, mencapai markah tertinggi dalam kesemua sembilan set data penanda aras MultiMedQA, mengatasi prestasi Flan-PaLM 540B dan Med-PaLM 2.
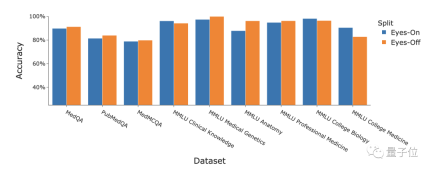
Selain itu, penyelidik juga membincangkan prestasi strategi Medprompt pada data "Eyes-Off". Data yang dipanggil "Eyes-Off" merujuk kepada data yang tidak pernah dilihat oleh model semasa latihan atau proses pengoptimuman Ia digunakan untuk menguji sama ada model itu terlalu sesuai dengan data latihan

Hasil GPT-4 digabungkan dengan. strategi Medprompt telah digunakan dalam pelbagai perubatan Ia menunjukkan prestasi yang baik pada set data penanda aras, dengan ketepatan purata 91.3%.
Para penyelidik menjalankan eksperimen ablasi pada dataset MedQA untuk meneroka sumbangan relatif ketiga-tiga komponen kepada prestasi keseluruhan
Antaranya, langkah rantaian pemikiran penjanaan automatik memainkan peranan terbesar dalam meningkatkan prestasi
Skor rantaian pemikiran yang dijana secara automatik oleh GPT-4 adalah lebih tinggi daripada skor yang dipilih susun oleh pakar dalam Med-PaLM 2, dan tiada campur tangan manual diperlukan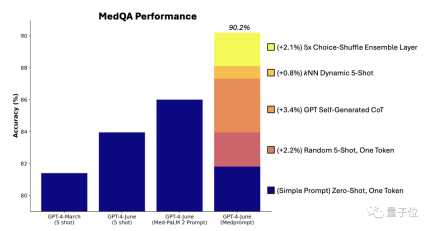
Akhirnya, penyelidik juga meneroka keupayaan generalisasi merentas domain Medprompt, menggunakan Enam set data berbeza dalam penanda aras MMLU disertakan, meliputi masalah dalam kejuruteraan elektrik, pembelajaran mesin, falsafah, perakaunan profesional, undang-undang profesional dan psikologi profesional. 

Sila klik pautan berikut untuk melihat kertas kerja: https://arxiv.org/pdf/2311.16452.pdf
Atas ialah kandungan terperinci Microsoft menjadikan GPT-4 sebagai pakar perubatan dengan hanya 'Prompt Project'! Lebih daripada sedozen model yang sangat halus, ketepatan ujian profesional melebihi 90% untuk kali pertama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AM
Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AMMeneroka kerja -kerja dalam model bahasa dengan skop Gemma Memahami kerumitan model bahasa AI adalah satu cabaran penting. Pelepasan Google Gemma Skop, Toolkit Komprehensif, menawarkan penyelidik cara yang kuat untuk menyelidiki
 Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AM
Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AMMembuka Kejayaan Perniagaan: Panduan untuk Menjadi Penganalisis Perisikan Perniagaan Bayangkan mengubah data mentah ke dalam pandangan yang boleh dilakukan yang mendorong pertumbuhan organisasi. Ini adalah kuasa penganalisis Perniagaan Perniagaan (BI) - peranan penting dalam GU
 Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMPernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AM
Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AMPengenalan Bayangkan pejabat yang sibuk di mana dua profesional bekerjasama dalam projek kritikal. Penganalisis perniagaan memberi tumpuan kepada objektif syarikat, mengenal pasti bidang penambahbaikan, dan memastikan penjajaran strategik dengan trend pasaran. Simu
 Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMPengiraan dan Analisis Data Excel: Penjelasan terperinci mengenai fungsi Count dan Counta Pengiraan dan analisis data yang tepat adalah kritikal dalam Excel, terutamanya apabila bekerja dengan set data yang besar. Excel menyediakan pelbagai fungsi untuk mencapai matlamat ini, dengan fungsi Count dan CountA menjadi alat utama untuk mengira bilangan sel di bawah keadaan yang berbeza. Walaupun kedua -dua fungsi digunakan untuk mengira sel, sasaran reka bentuk mereka disasarkan pada jenis data yang berbeza. Mari menggali butiran khusus fungsi Count dan Counta, menyerlahkan ciri dan perbezaan unik mereka, dan belajar cara menerapkannya dalam analisis data. Gambaran keseluruhan perkara utama Memahami kiraan dan cou
 Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AM
Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AMRevolusi AI Google Chrome: Pengalaman melayari yang diperibadikan dan cekap Kecerdasan Buatan (AI) dengan cepat mengubah kehidupan seharian kita, dan Google Chrome mengetuai pertuduhan di arena pelayaran web. Artikel ini meneroka exciti
 Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AM
Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AMImpak Reimagining: garis bawah empat kali ganda Selama terlalu lama, perbualan telah dikuasai oleh pandangan sempit kesan AI, terutama memberi tumpuan kepada keuntungan bawah. Walau bagaimanapun, pendekatan yang lebih holistik mengiktiraf kesalinghubungan BU
 5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AM
5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AMPerkara bergerak terus ke arah itu. Pelaburan yang dicurahkan ke dalam penyedia perkhidmatan kuantum dan permulaan menunjukkan bahawa industri memahami kepentingannya. Dan semakin banyak kes penggunaan dunia nyata muncul untuk menunjukkan nilainya


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

