
Rumah >Peranti teknologi >AI >Sebarang teks, visual, penjanaan campuran audio, berbilang modal dengan enjin asas CoDi-2 yang berkuasa
Sebarang teks, visual, penjanaan campuran audio, berbilang modal dengan enjin asas CoDi-2 yang berkuasa

- PHPzke hadapan
- 2023-12-04 12:39:58986semak imbas
Para penyelidik menegaskan bahawa CoDi-2 menandakan kejayaan besar dalam bidang membangunkan model asas pelbagai mod yang komprehensif
Pada bulan Mei tahun ini, Universiti North Carolina di Chapel Hill dan Microsoft mencadangkan Composable Diffusion (Composable). Model Penyebaran (dirujuk sebagai CoDi) membolehkan satu model menyatukan pelbagai modaliti. CoDi bukan sahaja menyokong penjanaan modal tunggal kepada modal tunggal, tetapi juga boleh menerima berbilang input bersyarat dan penjanaan bersama pelbagai mod.
Baru-baru ini, ramai penyelidik dari UC Berkeley, Microsoft Azure AI, Zoom, dan University of North Carolina di Chapel Hill telah menaik taraf sistem CoDi kepada versi CoDi-2

Alamat kertas: https:// arxiv.org/pdf/2311.18775.pdf
Alamat projek: https://codi-2.github.io/

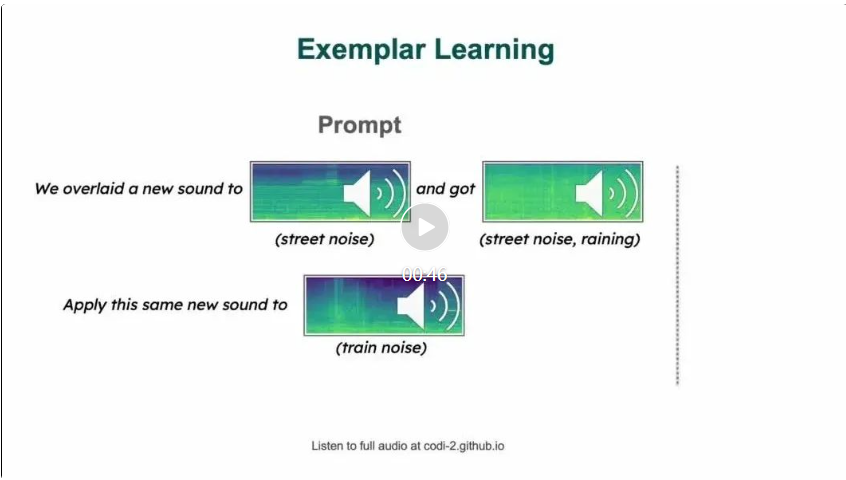
Menulis semula kandungan tanpa perlu mengubah kandungan asal ditulis semula ke dalam bahasa Cina , ayat asal tidak perlu muncul
Menurut kertas kerja Zineng Tang, CoDi-2 mengikuti arahan kontekstual bersilang berbilang modal yang kompleks untuk menghasilkan sebarang modaliti (teks, visual dan audio) dengan tangkapan sifar atau interaksi beberapa pukulan

Pautan ini adalah sumber imej: https://twitter.com/ZinengTang/status/1730658941414371820
Boleh dikatakan serba boleh dan besar sebagai bahasa interaktif model (MLLM), CoDi-2 boleh melaksanakan pembelajaran kontekstual, penaakulan, berbual, menyunting dan tugas-tugas lain dalam paradigma modal input-output sebarang-ke-mana-mana. Dengan menyelaraskan modaliti dan bahasa semasa pengekodan dan penjanaan, CoDi-2 membolehkan LLM bukan sahaja memahami arahan interleaving modal yang kompleks dan contoh kontekstual, tetapi juga untuk menjana keluaran berbilang modal yang munasabah dan koheren dalam ruang ciri yang berterusan.
Untuk melatih CoDi-2, para penyelidik membina set data generatif berskala besar yang mengandungi arahan multimodal kontekstual merentas teks, visual dan audio. CoDi-2 menunjukkan julat keupayaan sifar pukulan untuk penjanaan berbilang modal, seperti pembelajaran kontekstual, penaakulan dan kombinasi penjanaan mana-mana kepada mana-mana modal melalui berbilang pusingan dialog interaktif. Antaranya, ia mengatasi model khusus domain sebelumnya dalam tugas seperti penjanaan imej dipacu topik, transformasi visual dan penyuntingan audio.

Berbilang pusingan dialog antara manusia dan CoDi-2 menyediakan arahan pelbagai mod kontekstual untuk penyuntingan imej.
Apa yang perlu ditulis semula ialah: seni bina model
CoDi-2 direka untuk mengendalikan input berbilang modal seperti teks, imej dan audio dalam konteks, menggunakan arahan khusus untuk menggalakkan pembelajaran kontekstual dan menjana Teks yang sepadan , imej dan output audio. Apa yang perlu ditulis semula untuk CoDi-2 ialah: Gambar rajah seni bina model adalah seperti berikut. . contoh), dan berinteraksi dengan peresap berbilang modal Prasyarat untuk mencapai semua ini ialah enjin asas yang berkuasa. Para penyelidik mencadangkan MLLM sebagai enjin ini, yang dibina untuk memberikan persepsi multimodal untuk LLM teks sahaja.
Menggunakan pemetaan pengekod berbilang mod yang dijajarkan, penyelidik boleh menyedarkan LLM dengan lancar tentang jujukan input berjalin secara mod. Khususnya, apabila memproses jujukan input berbilang modal, mereka mula-mula menggunakan pengekod berbilang modal untuk memetakan data berbilang mod kepada jujukan ciri, dan kemudian token khas ditambahkan sebelum dan selepas jujukan ciri, seperti "〈audio〉 [ciri audio jujukan" ] 〈/audio〉”. . Semasa proses ini, arahan dan gesaan bersilang berbilang mod terperinci telah diikuti. Objektif latihan model resapan adalah seperti berikut: 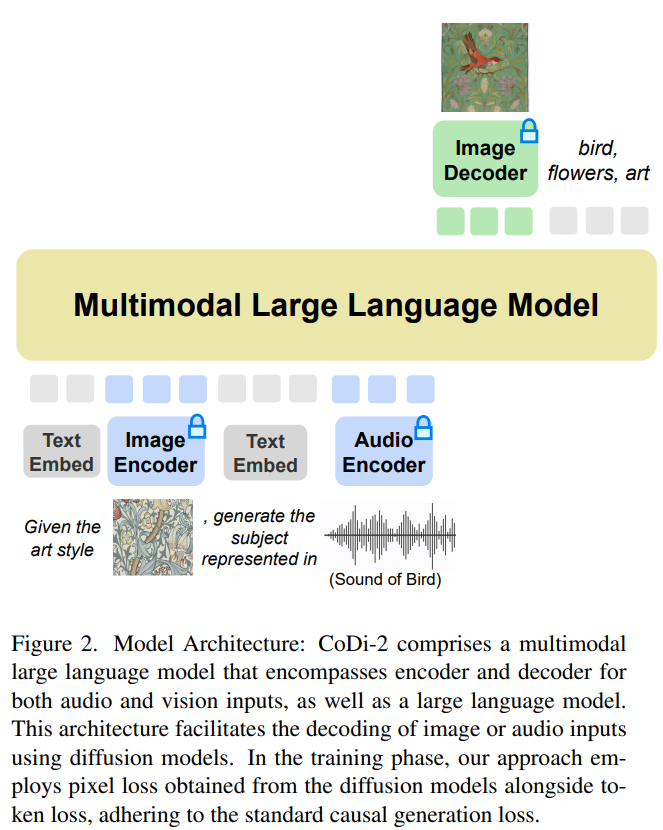
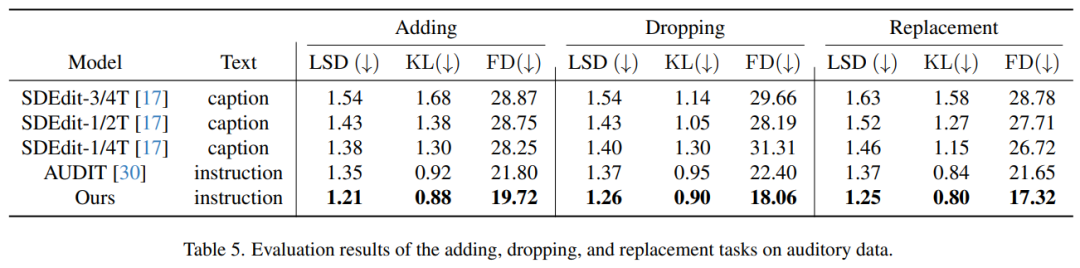
Mereka kemudiannya mencadangkan latihan MLLM untuk menjana ciri bersyarat c = C_y (y), yang dimasukkan ke dalam model resapan untuk mensintesis keluaran sasaran x. Dengan cara ini, kehilangan generatif model resapan digunakan untuk melatih MLLM. Jenis Tugasan Model menunjukkan keupayaan kukuh dalam contoh jenis tugasan berikut, yang menyediakan pendekatan unik yang menggesa model menjana atau mengubah kandungan berbilang mod dalam konteks, termasuk teks, imej, Audio, video dan gabungan Kandungan yang ditulis semula ialah: 1. Inferens sampel sifar. Tugasan inferens sifar memerlukan model untuk menaakul dan menjana kandungan baharu tanpa sebarang contoh sebelumnya 2. Satu atau beberapa contoh gesaan memberikan model satu atau beberapa contoh untuk dipelajari sebelum melaksanakan tugas yang serupa. Pendekatan ini jelas dalam tugasan di mana model menggunakan konsep yang dipelajari dari satu imej ke imej lain, atau mencipta karya seni baharu dengan memahami gaya yang diterangkan dalam contoh yang disediakan. Eksperimen dan keputusan Tetapan model Pelaksanaan model dalam artikel ini adalah berdasarkan Llama2, terutamanya Llama-2-7b-chat-hf. Para penyelidik menggunakan ImageBind, yang telah menjajarkan imej, video, audio, teks, kedalaman, terma dan pengekod mod IMU. Kami menggunakan ImageBind untuk mengekodkan ciri imej dan audio dan menayangkannya melalui perceptron berbilang lapisan (MLP) kepada dimensi input LLM (Llama-2-7b-chat-hf). MLP terdiri daripada pemetaan linear, pengaktifan, normalisasi dan satu lagi pemetaan linear. Apabila LLM menjana ciri imej atau audio, mereka menayangkannya semula ke dalam dimensi ciri ImageBind melalui MLP lain. Model resapan imej dalam artikel ini adalah berdasarkan StableDiffusion2.1 (stabilityai/stable-diffusion-2-1-unclip), AudioLDM2 dan zeroscope v2. Untuk mendapatkan imej atau audio input asal yang lebih tinggi, penyelidik memasukkannya ke dalam model resapan dan menjana ciri dengan menggabungkan bunyi resapan. Kaedah ini sangat berkesan, ia dapat mengekalkan ciri-ciri persepsi kandungan input ke tahap yang paling besar, dan dapat menambah kandungan baru atau mengubah gaya dan penyuntingan arahan lain Kandungan yang perlu ditulis semula ialah: Penjanaan imej penilaian Angka berikut menunjukkan hasil Penilaian penjanaan imej dipacu topik pada skor Dreambench dan FID pada MSCOCO. Kaedah dalam kertas ini mencapai prestasi sifar pukulan yang sangat kompetitif, menunjukkan keupayaan generalisasinya kepada tugasan baharu yang tidak diketahui. Penilaian Penjanaan Audio Jadual 5 menunjukkan hasil penilaian pada tugas pemprosesan audio, iaitu menambah, memadam dan menggantikan elemen dalam trek audio. Jelas daripada jadual bahawa kaedah kami menunjukkan prestasi yang sangat baik berbanding dengan kaedah sebelumnya. Terutamanya, ia mencapai markah terendah merentas ketiga-tiga tugas penyuntingan pada semua metrik - Jarak Spektrum Log (LSD), Perbezaan Kullback-Leibler (KL) dan Jarak Fréchet (FD) Baca artikel asal untuk mendapatkan butiran lanjut teknikal. 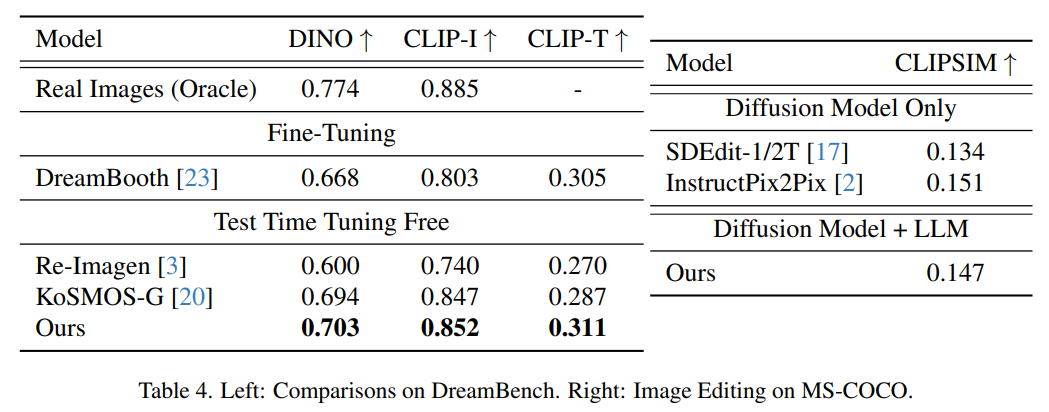
Atas ialah kandungan terperinci Sebarang teks, visual, penjanaan campuran audio, berbilang modal dengan enjin asas CoDi-2 yang berkuasa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Memperkasakan industri fesyen dengan teknologi untuk membantu Daerah Futian membina 'Pusat Ibu Pejabat Fesyen Bay Area'
- Luxshare Precision: Ia mempunyai keupayaan matang dan asas perniagaan untuk memasuki industri baru muncul seperti robot humanoid
- Kementerian Perindustrian dan Teknologi Maklumat mengumumkan: Mempercepatkan pembangunan industri antara muka otak-komputer
- Skala industri pengkomputeran negara saya mencecah 2.6 trilion yuan, dengan lebih daripada 20.91 juta pelayan tujuan am dan 820,000 pelayan AI dihantar dalam tempoh enam tahun yang lalu.
- Persidangan Pengkomputeran Kecerdasan Buatan 2023 AICC telah diadakan di Beijing, memfokuskan pada perbincangan hangat industri mengenai model berskala besar dan kuasa pengkomputeran pintar